
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В основе решения на ЭВМ вероятностных задач лежит моделирование случайных явлений. Различные случайные величины, характеризующие отдельные стороны исследуемого процесса, воспроизводятся на ЭВМ с помощью случайных чисел в соответствии с заданными законами распределения.
Теоретической основой метода моделирования служит закон больших чисел. Следовательно, этот метод основан на самых общих теоремах теории вероятностей и принципиально не содержит никаких ограничений. Он может быть применен для исследования любой системы с известным алгоритмом функционирования, а при достаточно большом числе испытаний от него можно требовать любой точности. Метод моделирования позволяет полнее учесть особенности функционирования исследуемых систем, использовать любые законы распределения исходных случайных величин, имеет наглядную вероятностную трактовку, достаточно простую вычислительную схему и малую чувствительность к случайным сбоям машины в процессе решения. Все это достоинства метода.
Вместе с тем метод моделирования обладает рядом недостатков, наиболее существенными из которых являются большая трудоемкость и частный характер решения. Эффективными путями преодоления этих недостатков являются:
– разработка обобщенных универсальных подходов к построению моделирующих алгоритмов для исследования процессов функционирования систем различных классов;
– создание библиотеки стандартных подалгоритмов и подпрограмм, моделирующих все основные типовые операции, встречающиеся при решении различных задач, и используемых как готовые стандартные блоки (например, моделирование случайных величин с различными законами распределения, оценка точности результатов, построение гистограмм случайных величин и т. п.);
– создание библиотеки стандартных алгоритмов и программ для решения основных типовых задач исследования систем;
– дальнейшее развитие вопросов автоматизации программирования и отладки программ на основе совершенствования существующих и разработки новых эффективных алгоритмических языков;
– синтез метода моделирования с аналитическими методами, позволяющий наилучшим образом использовать положительные стороны каждого из них.
6.2. Формирование случайных величин с различными законами распределения и оценка точности результатов моделирования
Однако большинство универсальных ЭВМ не имеет датчиков случайных чисел, поэтому наибольшее распространение получил программный способ формирования случайных последовательностей, основанный на использовании некоторого рекуррентного соотношения.
При этом в качестве основного механизма генерирования случайных величин используется последовательность равномерно распределенных в интервале (0,1) случайных чисел x, которые подвергаются дальнейшим преобразованиям для получения заданных законов распределения.
Рассмотрим некоторые из алгоритмических способов формирования равномерно распределенных случайных чисел.
Пусть F(х) и f(х) соответственно функция и плотность распределения некоторой случайной величины X, а xi – случайное число с равномерным законом распределения в интервале (0,1). Тогда для получения случайного числа xi из совокупности случайных чисел, имеющих заданную функцию распределения F(х), необходимо решить относительно xi следующее интегральное уравнение:
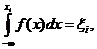 (6.1)
(6.1)
т. е. определить такое значение xi, при котором функция распределения F (х) равна xi.
Для некоторых частных законов распределения уравнение (6.1) удается решить непосредственно. В большинстве же практически важных случаев уравнение (6.1) точно не решается. Тогда используют приближенные способы преобразования случайных чисел, которые можно условно разбить на две группы. К первой группе относятся способы, основанные при приближенном решении уравнения (6.1):
– численное решение уравнения (6.1) в процессе преобразования случайных чисел;
– предварительная аппроксимация подынтегральной функции в уравнении (6.1) полиномами или другими функциями, обеспечивающими простоту решения уравнения;
– использование заранее составленных таблиц, содержащих решения уравнения (6.1).
Таблица 6.1
Наименование и параметры распределения | Плотность распределения | Формула для вычисления случайного числа |
Равномерное в интервале (a, b) |
|
|
Экспоненциальное с параметром l |
|
|
Сдвинутое экспоненциальное с параметрами l и b (параметр сдвига) |
|
|
Логарифмически нормальное с параметрами а и s |
|
де |
Эрланга с параметрами k и b |
|
|
c2 с параметром n (число степеней свободы) |
|
|
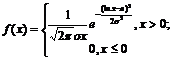
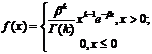
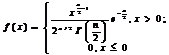
Примечание. 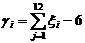
Ко второй группе относятся способы, не связанные с решением уравнения (6.1):
– отбор случайных чисел с заданным законом распределения из исходной совокупности случайных чисел с равномерным распределением в интервале (0,1);
– приближенное моделирование условий предельных теорем теории вероятностей.
В табл. 6.1 для различных непрерывных законов приведены формулы для вычисления случайных чисел xi, полученные с использованием указанных выше способов а также выражения, устанавливающие связи между параметрами каждого распределения и его математическим ожиданием и дисперсией. Эти формулы обычно используются при исследовании влияния различных типов законов распределения исходных случайных величин на результаты моделирования.
Часто при решении задач на ЭЦВМ возникает необходимость моделирования случайных событий с известным распределением вероятностей. Покажем, как это делается. Предположим, что заданы численные значения вероятностей P1 , Р2,, ..., Рп для независимых событий A1, А2 ,..., Аn , составляющих полную группу. Нужно определить в каждом испытании, какое из этих событий произошло.
Разобьем отрезок (0,1) на п отрезков так, чтобы длина i-го отрезка равнялась вероятности Pi. Выбирая из равномерного в интервале (0,1) распределения случайные числа xi, будем определять, на какой участок отрезка попадает число xi. Попадание случайного числа на i-й участок фиксируется как факт свершения события Ai.
Очевидно, что при достаточно большом числе испытаний количество попаданий на i-й участок будет пропорционально его длине (т. е. значению Рi), а это означает, что случайные события Ai воспроизводятся в соответствии с распределением вероятностей Рi.В ЭВМ этот процесс сводится к выбору случайного числа xi и последовательной проверке условия
![]() (6.2)
(6.2)
Для фиксированного xi неравенство (6.2) выполняется лишь при каком-то одном значении k (k = l, 2, ..., п). Это значение k и определяет номер события Ап, которое произошло в данном опыте.
В простейшем случае число возможных исходов равно двум, т. е. задана вероятность Р(А) события А и в каждом испытании требуется определить, произошло это событие или нет. Тогда процедура сводится к однократной проверке неравенства
xi £ (А) (6.3)
Если это неравенство выполняется, то фиксируется факт свершения события А.
Моделирование дискретной случайной величины X фактически сводится к рассмотренной ранее схеме случайных событий, так как каждому из возможных значений случайной величины X ставится в соответствие определенное значение вероятности Р (X = т) того, что случайная величина примет значение, равное m. Алгоритмы для моделирования некоторых дискретных распределений (Пуассона, геометрического и др.) приведены в работе.
Результаты моделирования обладают определенной погрешностью, источниками которой могут быть: упрощение модели, неточность определения исходных данных, ограниченное число реализаций, сбои и т. п. Рассмотрим более подробно погрешность, обусловленную ограниченным числом реализаций, и приведем формулы для ее оценки.
Сточки зрения математической статистики, процесс моделирования сводится к выбору определенного объема из генеральной совокупности. В результате моделирования на основе полученного статистического материала дается количественное описание исследуемых случайных величин, т. е. определяются основные числовые характеристики (математическое ожидание, дисперсия, статистическая функция распределения и т. д.). При этом вследствие ограниченного числа испытаний вместо точных значений показателей мы получаем их приближенные значения, называемые оценками.
К оценкам искомых показателей следует подходить как к обычным случайным величинам. При этом необходимо учитывать, что закон распределения оценки зависит и от распределения самой случайной величины, и от числа опытов. При реализации метода моделирования на ЭВМ число испытаний обычно бывает достаточно большим (от нескольких сотен до десятков тысяч). Это позволяет сделать вывод о нормальном законе распределения оценок математического ожидания, дисперсии, вероятности события, что существенно упрощает анализ точности результатов моделирования.
На практике задача сводится к определению точности результатов по известному числу реализаций[1] пp или наоборот— к выбору такого значения пp, которое обеспечивает получение результатов с заданной точностью e. По существу, это одна задача, решение которой основывается на взаимосвязи трех величин: числа реализаций np, точности e и достоверности a результатов. Под достоверностью понимается доверительная вероятность
a=P{a* - e < a < a* + e}, (6.4)
т. е. вероятность того, что интервал (a* - e , a* + e) со случайными границами (доверительный интервал) накроет неизвестный параметр а.
В практике моделирования широкое применение получил метод автоматического контроля точности результатов моделирования с помощью ЭВМ. Сущность этого метода состоит в следующем: задают первоначальное число реализаций nр* (заведомо заниженное), а затем после каждой последующей реализации с помощью машины проверяется условие
e < eтр, (6.5)
где e, eтр –соответственно текущее и требуемое значение относительной погрешности результатов.
При выполнении условия (6.5) расчет прекращается, и машина выдает результаты моделирования на печать.
Для оценки относительной погрешности e математического ожидания некоторой случайной величины X и вероятности Р события А используются формулы:
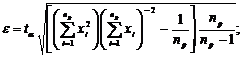 (6.6)
(6.6)
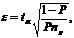 (6.7)
(6.7)
где ![]() ;
; ![]() – ункция, обратная функции Лапласа, т. е. такое значение аргумента, при котором функция Лапласа равна доверительной вероятности a (значения ta. табулированы и приведены в работе).
– ункция, обратная функции Лапласа, т. е. такое значение аргумента, при котором функция Лапласа равна доверительной вероятности a (значения ta. табулированы и приведены в работе).
Для оценки относительной погрешности при вычислении дисперсии случайной величины X используется выражение
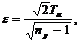 (6.8)
(6.8)
из которого при заданном значении ta нетрудно определить число реализаций nр, обеспечивающее требуемую относительную погрешность е.
Анализ показывает, что рассматриваемые процессы функционирования промышленных АСУ, как правило, обладают свойствами стационарности и эргодичности. Поэтому моделирующие алгоритмы для их исследования построены таким образом, что воспроизводят процессы функционирования систем в течение заданного длительного интервала времени tмод (моделируется одна длинная реализация), обеспечивающего получение статистически устойчивых результатов решения. Обычно длина интервала моделирования tмод задается ориентировочно с таким расчетом, чтобы в течение этого времени каждый из элементов исследуемой системы отказал несколько раз.
6.3. Поток событий. Простейший поток и его свойства
Под потоком событий в теории вероятностей понимается последовательность событий, происходящих одно за другим в какие-то моменты времени. Примерами могут служить потоки отказов аппаратуры.
Поток событий называется регулярным, если события следуют одно за другим через строго определенные промежутки времени. Такой поток сравнительно редко встречается в реальных системах, но представляет интерес как предельный случай. Типичным для системы массового обслуживания является случайный поток заявок.
Поток событий называется стационарным, если вероятность попадания того или иного числа событий на участок времени длиной t зависит только от длины участка и не зависит от того, где именно на оси Ot расположен этот участок.
Поток событий называется потоком без последствий, если для любых неперекрывающихся участков времени число событий, попадающих на один из них, не зависит от числа событий, попадающих на другие.
Поток событий называется ординарным, если вероятность попадания на элементарный участок Dt двух или более событий пренебрежимо мала по сравнению с вероятностью попадания одного события.
Если поток событий обладает всеми тремя свойствами ( т. е. стационарен, ординарен и не имеет последствия), то он называется простейшим потоком.
Простейший поток играет среди потоков событий вообще особую роль, до некоторой степени аналогичную роли нормального закона среди других законов распределения. Мы знаем, что при суммировании большого числа независимых случайных величин, подчиненных практически любым законам распределения, получается величина, приближенно распределенная по нормальному закону. Аналогично можно доказать, что при суммировании (взаимном наложении) большого числа ординарных, стационарных потоков с практически любым последействием получается поток, сколь угодно близкий к простейшему. Условия, которые должны для этого соблюдаться, аналогичны условиям центральной предельной теоремы, а именно – складываемые потоки должны оказывать на сумму приблизительно равномерно малое влияние.
Проиллюстрируем его элементарными рассуждениями. Пусть имеется ряд независимых потоков П1, П2,… Пn (рис.6.1). «Суммирование» потоков состоит в том, что все моменты появления событий сносятся на одну и ту же ось Оt, как показано на рис. 6.1.
Предположим, что потоки П1,П2,… сравнимы по своему влиянию на суммарный поток (т. е. имеют плотности одного порядка), а число их достаточно велико. Предположим, кроме того, что эти потоки стационарны и ординарны, но каждый из них может иметь последействие, и рассмотрим суммарный поток
П = ![]()
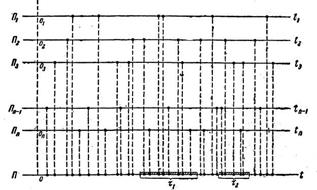
|
На оси Оt (рис.1). Очевидно, что поток П должен быть стационарным и ординарным, так как каждое слагаемое обладает этим свойством и они независимы. Кроме того, достаточно ясно, что при увеличении числа слагаемых последействие в суммарном потоке, даже если оно значительно в отдельных потоках, должно постепенно слабеть. Действительно, рассмотрим на оси Оt два неперекрывающихся отрезка t1 и t2 (рис.1). Каждая из точек, попадающих в эти отрезки, случайным образом может оказаться принадлежащей тому или иному потоку, и по мере увеличения n удельный вес точек, принадлежащих одному и тому же потоку (и, значит, зависимых), должен уменьшаться, а остальные точки принадлежат разным потокам и появляются на отрезках t1 и t 2 независимо друг от друга. Достаточно естественно ожидать, что при увеличении n суммарный поток будет терять последействие и приближаться к простейшему.
На практике оказывается обычно достаточно сложить 4÷5 потоков, чтобы получить поток, с которым можно оперировать как с простейшим.
Простейший поток играет в теории надежности и массового обслуживания особенно важную роль. Во-первых, простейшие и близкие к простейшим потоки заявок часто встречаются на практике (причины этого изложены выше). Во - вторых, даже при потоке заявок, отличающемся от простейшего, часто можно получить удовлетворительные по точности результаты, заменив поток любой структуры простейшим с той же плотностью. Поэтому подробнее простейшим потоком и его свойствами.
Рассмотрим на оси Оt простейший поток событий П (рис. 6.2) как неограниченную последовательность случайных точек.
 Выделим произвольный участок времени длиной t. Из теории вероятностей известно, что при условиях стационарности, отсутствия последействия и ординарности число точек, попадающих на участок t, распределено по закону Пуассона с математическим ожиданием а = λt, где λ - плотность потока (среднее число событий, приходящееся на единицу времени). Вероятность того, что за время t произойдет ровно m событий, равна (закон Пуассона).
Выделим произвольный участок времени длиной t. Из теории вероятностей известно, что при условиях стационарности, отсутствия последействия и ординарности число точек, попадающих на участок t, распределено по закону Пуассона с математическим ожиданием а = λt, где λ - плотность потока (среднее число событий, приходящееся на единицу времени). Вероятность того, что за время t произойдет ровно m событий, равна (закон Пуассона).
Рm(t) = ![]()
В частности, вероятность того, что участок окажется пустым
( не произойдет ни одного события), будет
Р0(t) = e–λτ
Важной характеристикой потока является закон распределения длины промежутка между соседними событиями. Рассмотрим случайную величину Т- промежуток времени между произвольными двумя соседними событиями в простейшем потоке (рис.2.) и найдем ее функцию распределения
F(t) = P(T < t).
Перейдем к вероятности противоположного события
1 – F(t) = P(T ≥ t).
Это есть вероятность того, что на участке времени длиной t, начинающемся в момент tk появления одного из событий потока, не появится ни одного из последующих событий. Так как простейший поток не обладает последействием, то наличие в начале участка (в точке tk) какого-то события никак не влияет на вероятность появления тех или других событий в дальнейшем. Поэтому вероятность P(T ≥ t) можно вычислить по формуле
P0(t) = e–λτ,
откуда
F(t) =1 – e–λτ (t > 0).
Дифференцируя, найдем плотность распределения
f(t) =![]() λ e–λτ (t > 0)
λ e–λτ (t > 0)
Закон распределения с плотностью называется показательным законом, а величина τ- его параметром.
Показательный закон, как мы увидим в дальнейшем, играет большую роль в теории надежности. Поэтому рассмотрим его подробнее.
Найдем математическое ожидание величины T, распределенной по показательному закону:
mt = M[T] =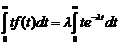
или, интегрируя по частям,
mt = ![]() .
.
Дисперсия величины T равна
Dt = D(T) = 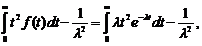
откуда
Dt =![]() σt =
σt =![]() .
.
Докажем одно замечательное свойство показательного закона. Оно состоит в следующем: если промежуток времени, распределенный по показательному закону, уже длился некоторое время х, то это никак не влияет на закон распределения оставшейся части промежутка: он будет таким же, как и закон распределения всего промежутка Т.
Для доказательства рассмотрим случайный промежуток времени Т с функцией распределения
![]() (а)
(а)
и предположим, что этот промежуток уже продолжается некоторое время т, т. е. произошло событие Т>![]() . Найдем при этом предположении условный закон распределения оставшейся части промежутка
. Найдем при этом предположении условный закон распределения оставшейся части промежутка  ; обозначим его F
; обозначим его F![]() (t)
(t)
![]()
Докажем, что условный закон распределения ![]() не зависит от
не зависит от ![]() и равен F(t). Для того чтобы вычислить
и равен F(t). Для того чтобы вычислить ![]() , найдем сначала вероятность произведения двух событий
, найдем сначала вероятность произведения двух событий
![]() и
и ![]()
по теореме умножения вероятностей
![]()
откуда
![]()
Но событие ![]() равносильно событию
равносильно событию ![]() вероятность которого равна
вероятность которого равна
![]()
С другой стороны,
![]() ,
,
следовательно,
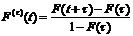
откуда, согласно формуле (а)
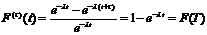
что и требовалось доказать.
Таким образом, мы доказали, что если промежуток времени Т ни пределен по показательному закону» то любые сведения о том, сколько времени уже протекал этот промежуток, не влияют на закон распределения оставшегося времени. Можно доказать, что показательный закон — единственный, обладающий таким свойством. Это свойство показательного закона представляет собой, в сущности, другую формулировку для «отсутствия последействия», которое является основным свойством простейшего потока.
Допущения о пуассоновском характере потока заявок и о показательном распределении времени обслуживания ценны тем, что позволяют применить в теории массового обслуживания аппарат так называемых марковских случайных процессов.
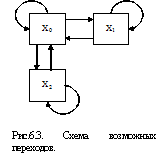
Процесс, протекающий в физической системе, называется марковским (или процессом без последействия), если для каждого момента времени вероятность любого состояния системы в будущем зависит только от состояния системы в настоящий момент (t0) зависит от того, каким образом система пришла в это стояние. Рассмотрим элементарный пример марковского случайного процесса. По оси абсцисс Ох случайным образом перемещается точка X, В момент времени t = 0 точка X находится в начале координат (x=0) и остается там в течение одной секунды. Через секунду бросается монета; если выпал герб — точка X перемещается на одну единицу длины вправо, если цифра — влево. Через секунду снова бросается монета и производится такое же случайное перемещение, и. т. д. Процесс изменения положения точки (или, как говорят «блуждания»), представляет собой случайный процесс с дискретным временем (t = 1, 2,...) и счетным множеством состояний
![]()
![]()
Схема возможных переходов для этого процесса показана на рис. 6.3
Рис.6.3.
Покажем, что этот процесс – марковский. Действительно, представим себе, что в какой-то момент времени t0 система находится, например, в состоянии x1 – на одну единицу правее начала координат. Возможные положения точки через единицу времени будут х0 и х2 с вероятностями 1/2 и 1/2; через две единицы – x-1 ,х1, x3 с вероятностями 1/4, 1/2, 1/4 так далее. Очевидно, всё эти вероятности зависят только от того» где находится точка в данный момент t0, и совершенно не зависят от того, как она пришла туда.
Рассмотрим другой пример. Имеется техническое устройств X, состоящее из элементов (деталей) типов а и b. Эти элементы в случайные моменты времени и независимо друг от друга могут выходить из строя. Исправная работа каждого элемента безусловно необходима для работы устройствав целом.
Время безотказной работы элемента – случайная величина, распределенная по показательному закону; для элементов типа а и b параметры этого закона различны и равны соответственно![]() .В случае отказа устройства немедленно принимаются меры для выявления причин и обнаруженный неисправный элемент немедленно заменяется новым. Время, потребное для восстановления (ремонта) устройства, распределено по показательному закону с параметром
.В случае отказа устройства немедленно принимаются меры для выявления причин и обнаруженный неисправный элемент немедленно заменяется новым. Время, потребное для восстановления (ремонта) устройства, распределено по показательному закону с параметром ![]() .(есливышел из строя элемент типа а) и (
.(есливышел из строя элемент типа а) и (![]() b (если вышел из строя элементтрпа b)
b (если вышел из строя элементтрпа b)
В данное примере случайный процесс, протекающий в системе, есть марковский процесс с непрерывным временем и конечным множеством состояний:
х0 – все элементы исправны, система работает;
х1 - неисправен элемент типа а, система ремонтируется;
x2 – неисправен элемент типа b система ремонтируется. Схема возможных переходов дана на рис.3.
Действительно, процесс обладает марковским свойством. Пусть например, в момент t0 система находится в состоянии х0 (исправна). Так как время безотказной работы каждого элемента — показательное, та момент отказа каждого элемента в будущем не зависит от того, сколько времени он уже работал (когда поставлен). Поэтому вероятность того, что в будущем система останется в состоянии c0 или уйдет из него, не зависит от «предыстории» процесса. Предположим теперь, что в момент t0 система находится в состоянии х1 (неисправен элемент типа а). Так как время ремонта тоже показательное, вероятность окончания ремонта в любое время после t0 не зависит от того, когда начался ремонт, и когда были поставлены остальные (исправные) элементы. Таким образом, процесс является марковским.
Заметим, что показательное распределение времени работы элемента и показательное распределение времени ремонта существенные условия, без которых процесс не был бы марковским. Действительно, предположим, что время исправной работы элемента распределено не по показательному закону, а по какому-нибудь другому — например, по закону равномерной плотности на участке. (t1, t2). Это значит, что каждый элемент с гарантией работает время t1, а на участке от t1 до t2 может выйти из строя в любой момент с одинаковой плотностью вероятности. Предположим, что в какой-то момент времени t0 элемент работает исправно. Очевидно, вероятность того, что элемент выйдет из строя на каком-то участке времени в будущем, зависит от того, насколько давно доставлен элемент, т. е. зависит от предыстории, и процесс не будет марковским.
Аналогично обстоит дело и с временем ремонта Тр; если оно не показательное и элемент в момент /0 ремонтируется, то оставшееся время ремонта зависит от того, когда он начался; процесс снова не будет марковским.
Пусть имеется n-канальная система надежности. Рассмотрим ее как физическую систему Х с конечным множеством состояний:
 Х0 - работоспособны все каналы;
Х0 - работоспособны все каналы;
х1 - один канал вышел из строя ;
хκ - ровно k каналов вышло из строя
хn - вышли из строя все n каналов.,
Поставим задачу: определить вероятности состояний системы pκ(t) (κ= 0, I, ..., n) для любого момента времени t. Задачу будем решать при следующих допущениях:
1. поток заявок — простейший, с плотностью λ;
2. время обслуживания То6 — показательное, с параметром ![]() ,
,
![]() (б)
(б)
![]() Заметим, что параметр
Заметим, что параметр ![]() в формуле (б) полностью аналогичен параметру λ показательного закона распределения промежутка Т между соседними событиями простейшего потока:
в формуле (б) полностью аналогичен параметру λ показательного закона распределения промежутка Т между соседними событиями простейшего потока:
f(t) =![]() λ e-λτ (t > 0)
λ e-λτ (t > 0)
РисПараметр λ имеет смысл «плотности потока заявок». Аналогично, величину ![]() можно истолковать как «плотность потока освобождений» занятого канала. Действительно, представим себе канал, непрерывно занятый (бесперебойно снабжаемый заявками); тогда, очевидно, в этом канале будет идти простейший поток освобождений с плотностью \i.
можно истолковать как «плотность потока освобождений» занятого канала. Действительно, представим себе канал, непрерывно занятый (бесперебойно снабжаемый заявками); тогда, очевидно, в этом канале будет идти простейший поток освобождений с плотностью \i.
Так как оба потока — заявок и освобождений — простейшие, процесс, протекающий в системе, будет марковским.
Рассмотрим возможные состояния системы и их вероятности
p0(t), p1(t), …, pn(t).
Очевидно, для любого момента времени
![]()
Составим дифференциальные уравнения для всех вероятностей начиная с p0(t). Зафиксируем момент времени t и найдем вероятность p0(t+Δt) того, что в момент t+Δt система будет находиться в состоянии х0 (все каналы свободны). Это может произойти двумя способами (рис. 4):
А – в момент t система находилась в состоянии х0, а за время Δt не перешла из нее в х1(не пришло ни одной заявки),
В – в момент t система находилась в состоянии х1, а за время Δt канал освободился, и система перешла в состояние х0.
Возможностью «перескока» системы через состояние (например, из х2 в х0 через х1) за малый промежуток времени можно пренебречь, как величиной высшего порядка малости по сравнению с Р(А) и Р(В). По теореме сложения вероятностей имеем
p0(t+Δt) ≈ Р(А)+ Р(В)
Найдем вероятность события А по теореме умножения. Вероятность того, что в момент t система была в состоянии x0, равна p0(t). Вероятность того, что за время Δt не придет ни одной заявки, равна e-λΔt. С точностью до величин высшего порядка малости
e-λΔt ≈ 1-λΔt
Следовательно, Р(А) ≈ р0 (t)( 1–λΔt)
Найдем Р(В). Вероятность того, что в момент t система была в состоянии x1 равна p1 (t). Вероятность того, что за время Δt канал освободится, равна 1–е -μΔt; с точностью до малых величин высшего порядка
1–е –μΔt ≈ μΔt
Следовательно, Р(В) ≈ р 1μΔt
Отсюда р0 (t + Δt) ≈ р0 (t)( 1–λΔt) + μ р1(t)( Δt)
Перенося р в левую часть, деля на Δt и переходя к пределу при t →0, получим дифференциальное уравнение для p0(t):
![]()
Аналогичные дифференциальные уравнения могут быть составлены и для других вероятностей состояний.
 Возьмем любое k (О <k <n) и найдем вероятность pk(Δt + t) того, что в момент Δt + t система будет в состоянии хк. Эта вероятность вычисляется как вероятность суммы уже не двух, а трех событий (по числу стрелок, направленных в состояние хк.
Возьмем любое k (О <k <n) и найдем вероятность pk(Δt + t) того, что в момент Δt + t система будет в состоянии хк. Эта вероятность вычисляется как вероятность суммы уже не двух, а трех событий (по числу стрелок, направленных в состояние хк.
Рис. 6.6. А – в момент t система была в состоянии xk (занято к каналов), а за время Δt не перешла из него ни в хк+1, ни в хк-1 (ни одна заявка не поступила, ни один канал не освободился);
В – в момент t система была в состоянии хк-1 (занято к –1 каналов), а за время Δt перешла в хк (пришла одна заявка);
С – в момент t система была в состоянии хк+1 (занято k+1 каналов), а за время Δt один из каналов освободился.
Найдем Р(А). Вычислим сначала вероятность того, что за время Δt не придет ни одна заявка и не освободится ни один из каналов:
![]()
Пренебрегая малыми величинами высших порядков, имеем
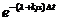 ≈ 1-(λ + kμ)Δt,
≈ 1-(λ + kμ)Δt,
откуда
Р(А) ) ≈ рк (t)[( 1–(λ + kμ) Δt]
Аналогично
Р(В) ≈ рк-1 (t)λΔt,
Р(С) ) ≈ рк+1 (t)(1 + k)μΔt,
и рк (t+Δt)≈ рк (t)[1- (λ+kμ) Δt]+ рк-1 (t)λΔt+ рк+1 (t)(1+k)μΔt.
Отсюда получаем дифференциальное уравнение для pk (t) (О < k <n):

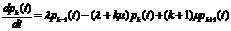
Составим уравнение для последней вероятности pn(t) (рис.6.6).
рис. 6.7
Имеем
![]()
где 1 – nμΔt – вероятность того, что за время Δt. не освободится ни один канал; λΔt – вероятность того, что за время Δt придет одна заявка. Получаем дифференциальное уравнение для pn(t):
![]()
Таким образом, получена система дифференциальных уравнений для вероятностей р1 (t), р2 (t),…, рn(t):
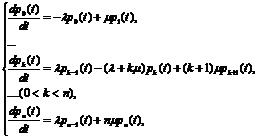 (в)
(в)
Данное уравнение (в) называется уравнением Эрланга. Интегрирование данной системы уравнений при начальных условиях:
p0(0) = 0, p1(0) =…= pn(0) = 0
(в начальный момент все каналы свободны) дает зависимость рk(t) для любого k. Вероятности pk(t) характеризуют среднюю загрузку системы и ее изменение с течением времени. В частности, рk(t) есть вероятность того, что заявка, пришедшая в момент t, застанет все каналы занятыми (получит отказ):
Ротк = рk(t)
Величина q(t) = 1– pn(t) называется относительной пропускной способностью системы. Для данного момента t это есть отношение среднего числа обслуженных за единицу времени заявок к среднему числу поданных.
Система линейных дифференциальных уравнений (в) сравнительно легко может быть проинтегрирована при любом конкретном числе каналов n. Заметим, что при выводе уравнений (в) мы нигде не пользовались допущением о том, что величины λ и μ (плотности потока заявок и «потока освобождений») постоянны. Поэтому уравнения (в) остаются справедливыми и для зависящих от времени λ(t) лишь бы потоки событий, переводящих систему из состояния в состояние, оставались пуассоновскими (без этого процесс не будет марковским).
В начале, сразу после включения системы в работу, протекающий в ней процесс еще не будет стационарным: в системе массового обслуживании (как и в любой динамической системе) возникнет так называемый «переходный», нестационарный процесс. Однако, спустя некоторое время, этот переходный процесс затухнет, и система перейдет на стационарный, так называемый «установившийся»режим, вероятностные характеристики которого уже не будут зависеть от времени.
Во многих задачах практики нас интересуют именно характеристики предельного установившегося режима обслуживания.
Можно доказать, что для любой системы с отказами такой предельный режим существует, т. е, что при t→∞ все вероятности p0(t), p1(t), …, pn(t) стремятся к постоянным пределам р0, р1 ..., рn, а все их производные – к нулю.
Чтобы найти предельные вероятности р0, р1 ..., рn,(вероятности состояний системы в установившемся режиме), заменим в уравнениях Эрланга вероятности pk(t) (0≤k≤n) их пределами pk, а все производные положим равными нулю. Получим систему уже не дифференциальных, а алгебраических уравнений
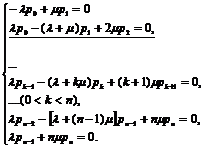
![]() (г)
(г)
к этим уравнениям необходимо добавить условие
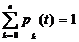
Разрешим систему (г)относительно неизвестных р0, р1 ..., рn,
Из первого уравнения имеем
![]() (д)
(д)
из второго с учетом (д) ,
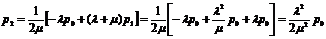 (е)
(е)
аналогично из третьего с учетом (д),(е),
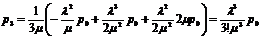
и вообще, для любого k≤n
![]() (ж)
(ж)
введем обозначение ![]() и назовем величину α приведенной плотностью потока заявок. Это есть не что иное, как среднее число заявок, приходящееся на среднее время обслуживания одной заявки. Действительно,
и назовем величину α приведенной плотностью потока заявок. Это есть не что иное, как среднее число заявок, приходящееся на среднее время обслуживания одной заявки. Действительно,
![]() =
=![]()
где ![]() = М
= М![]() – среднее время обслуживания одной заявки.
– среднее время обслуживания одной заявки.
В новых обозначениях формула (ж)примет вид
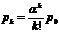
Эта формула выражает вероятности рк через р0 . Чтобы выразить их непосредственно через α и n, воспользуемся условием
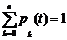 ,
,
тогда ![]()
откуда 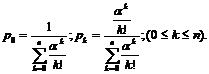 (1*)
(1*)
Эти формулы (1*) называются формулами Эрланга. Они дают предельный закон распределения числа занятых каналов в зависимости от характеристик потока заявок и производительности системы обслуживания. Полагая в формуле (1*) k = n, получим вероятность отказа (вероятность того, что поступившая заявка найдет все каналы занятыми):
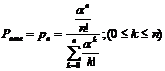 (2*)
(2*)
В частности, для одноканальной системы (n=1)
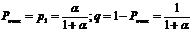
На основании формул Эрланга, могут быть получены показатели надежности для различных случаев резервирования. Kоэффициент готовности при этом, будет равен сумме всех неотказовых состояний.
обслуживания. Однако исследования последних лет показали, что эти формулы остаются справедливыми и при любом законе распределения времени обслуживания, лишь бы входной поток был простейшим.
Пример 1. Автоматическая телефонная станция имеет 4 линии связи На станцию поступает простейший поток заявок с плотностью λ= 3 (вызова в минуту). Вызов, поступивший в момент, когда все линии заняты, получает отказ. Средняя длительность разговора 2 минуты. Найти: а) вероятность отказа; б) среднюю долю времени, в течение которой телефонная станция вообще не загружена.
Решение. Имеем ![]() = 2 (мин);
= 2 (мин);
μ = 0,5 (разг/мин), ![]() =6
=6
а) По формуле (2*) получаем 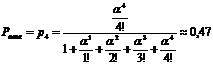
б) По формуле (1*) ![]()
Несмотря на то, что формулы Эрланга в точности Справедливы только при простейшем потоке заявок, ими можно с известным приближением пользоваться и в случае, когда цоток заявок отличается от простейшего (например, является стационарны»? потоком с ограниченным последействием). Расчеты показывают, что замена произволь-4 ного стационарного потока с не очень большим последействием простейшим пйтоком той же плотности А, как правило, мало влияет на характеристики пропускной способности системы.
Наконец, можно заметить, что формулами Эрланга можно приближенно пользоваться и в случае, когда система массового обслуживания допускает ожидание заявки в очереди, но когда срок ожидания мал по сравнению со средним временем обслуживания одной заявки.
Пример 2. Станция наведения истребителей имеет 3 канала. Каждый канал может одновременно наводить один истребитель на одну цель, вреднее время наведения ![]() = 2 мин. Поток целей — простейший, с плотностью λ = 1,5 (самолетов в минуту). Станцию можно считать «системой с отказами», так как цель, по которой наведение не началось в момент, когда она вошла в зону действия истребителей, вообще остается не атакованной. Среднее время наведения истребителя на цель 2 мин. Найти среднюю долю целей, проходи» через зону действия не обстрелянными.
= 2 мин. Поток целей — простейший, с плотностью λ = 1,5 (самолетов в минуту). Станцию можно считать «системой с отказами», так как цель, по которой наведение не началось в момент, когда она вошла в зону действия истребителей, вообще остается не атакованной. Среднее время наведения истребителя на цель 2 мин. Найти среднюю долю целей, проходи» через зону действия не обстрелянными.
Решение.
Имеем μ =![]() = 0,5; λ = 1,5;
= 0,5; λ = 1,5; ![]() =3
=3
По формуле (2*) 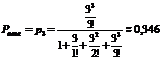
Вероятность отказа ≈0,346; она же выражает среднюю долю необстрелянных целей.
Заметим, что в данном примере плотность потока целей выбрана такой, что при их регулярном следовании одна за другой через определенные интервалы и при точно фиксированном времени наведения Тоб = 2 мин номинальная пропускная способность системы достаточна для того, чтобы обстрелять все без исключения цели. Снижение пропускной способности происходит из-за наличия случайных сгущений и разрежений в потоке целей, которые нельзя предвидеть заранее.
6.4. Основные этапы подготовки и решения задач оценки надежности и эффективности АСУ на ЭВМ
Подготовка и решение задач оценки надежности и эффективности АСУ с помощью ЭВМ — сложный и трудоемкий процесс, требующий совместной работы специалистов различного профиля. Можно условно разбить этот процесс на следующие этапы:
1) постановка задачи и изучение исследуемого процесса;
2) выбор и обоснование показателей качества исследуемого процесса;
3) определение характеристик случайного процесса (исходных данных) и диапазона их изменения;
4) обоснование требуемой точности получения результатов;
5) формализация процесса и выбор способа построения статистической модели;
6) разработка моделирующего алгоритма;
7) составление программы для решения на ЭВМ и ее отладка;
8) решение задачи на ЭВМ в соответствии с таблицей вариантов;
анализ полученных результатов, выводы по задаче и рекомендации
Из анализа перечисленных выше этапов видно, что значительная часть общего времени, необходимого для получения конечных результатов, расходуется на этапах предварительной подготовки. Трудоемкость и сложность этих этапов обусловили необходимость совместной работы инженеров, хорошо представляющих себе физическую сущность исследуемых процессов, и математиков-программистов, определяющих выбор наиболее эффективных методов решения и реализующих их в виде программ.
Таким образом, эффективность применения метода моделирования зависит не только от технических характеристик ЭВМ, а в значительной степени определяется спецификой задачи и трудовыми затратами на этапах предварительной подготовки ее к решению на машине. Поэтому большое нимание уделяется разработке библиотек стандартных алгорит-мов и программ для решения задач надежности и эффективности АСУ. При наличии таких алгоритмов и программ эффективность применения ЭВМ существенно повышается. Общее время получения требуемых результатов определяется при этом лишь временем подготовки таблиц вариантов исследования и «чистым» временем решения на машине, которое может быть сокращено путем максимальной
Вопросы для самоконтроля:
1. В чем заключается идея метода моделирования?
2. Какие существуют достоинства и недостатки метода моделирования на ЭВМ?
3. Какие законы распределения используются в данном методе.
4. Каким образом осуществляется оценка точности результатов моделирования.
5. Перечислите основные этапы подготовки и решения задачи оценки надежности и эффективности АСУ на ЭВМ.
Литература
1. Надежность и эффективность АСУ. , , П и т. д. – Кие: Техника, 1975.
2. . Средства передачи данных в АСУ. Раздел "Методика расчета надежности трактов передачи данных с временной и аппаратурной избыточностями".
3. . Надежность автоматизированных систем. – М.: Энергия,1977.
4. Методы расчета надежности систем автоматики. Учебно-методическое пособие. Г. Фрунзе 1984.
Приложение
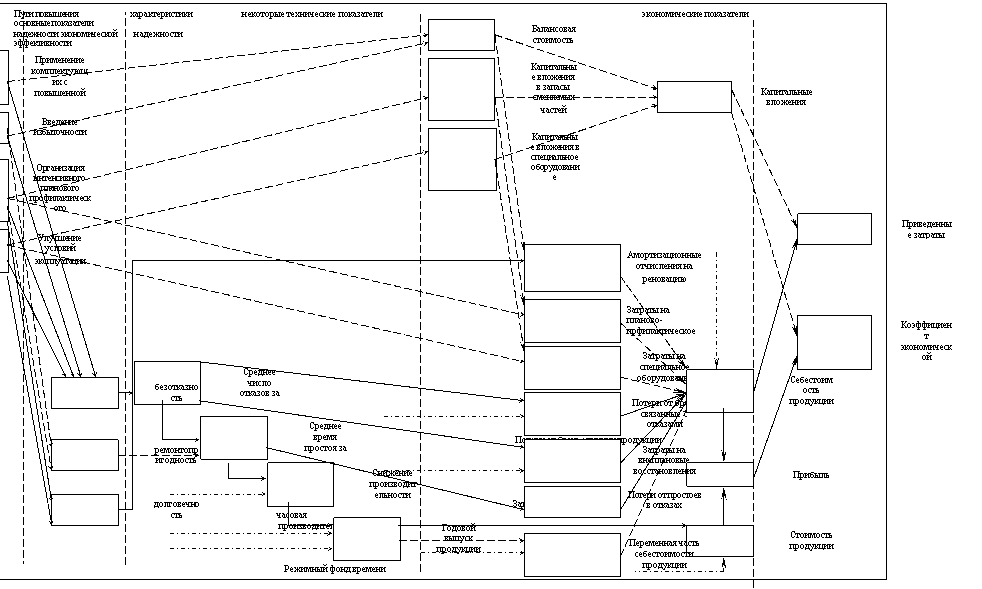 |
Рис.7.1. Схема влияния различных показателей надежности на технические и экономические показатели системы.
 |
[1] Понятие реализации относится к случайному событию, случайной величине или случайной функции. Для случайного события реализацией будет конкретное событие, происходящее в данном опыте, для случайной величины — ее конкретное значение, а для случайной функции — конкретный вид функции. В таком же понимании употребляется понятие реализации и при моделировании АСУ.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
