

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица 7– Бюджет маркетинговых исследований
№ п/п | Направление затрат | Трудоемкость работ, расход | Ставка, руб./день | Общая сумма, руб. |
1.Прямые материальные затраты | ||||
1.1. | Канцтовары - ручки (20 шт.) | 2-50 | 250 | |
1.2. | Приобретение 2 справочников в Госкомстате УР | 50 | 100 | |
1.3. | Распечатка | 350 | 1 | 350 |
1.4. | Ксерокопия | 150 | 1,5 | 225 |
Итого материальных затрат | 925 | |||
Основная заработная плата | ||||
2.1. | Оплата маркетолога | 60 | 350 | 21000 |
2.2. | Оплата экспертов | 3 | 400 | 1200 |
2.3. | Оплата наблюдателей | 50 листов | 15 | 8000 |
2.4. | Оплата интервьюеров: - для массового опроса - для экспертного опроса | 400 15 | 20 20 | 8000 300 |
38500 | ||||
3 | Дополнительная заработная плата | 16 % от Зосн | 6160 | |
Итого основной и дополнительной заработной платы | 44660 | |||
Социальные налоги | 26 % от суммы 2 и 3 статьи | 11611,6 | ||
Итого бюджет | 57136,6 |
2.2 Организация сбора информации
2.2.1 Полнота сбора информации для курсовой работы
Для выполнения курсовой работы, студентом должна быть собрана информация по всем разработанным направлениям и по всем инструментам сбора информации.
Однако, если спроектированы массовые (сплошные или выборочные) опросы и исследуемые совокупности содержат более 100 единиц, допускается ограничиться опросами 50 единиц. Но, при этом, структура исследуемой совокупности должна быть сохранена.
Если в разделе 2.1.4 студентом были разработаны проектные характеристики исследуемой совокупности, то в данном разделе должны быть описаны характеристики фактически исследованной совокупности, а именно:
- размеры;
- структура;
- место исследования;
- время исследования;
- участники исследования.
Здесь же должны быть показаны отклонения от проектируемых величин, недостатки проектных работ, выявленные в процессе сбора информации и причины их возникновения.
Эти недостатки, выявленные самим студентом, не являются основанием для снижения оценки при защите курсовой работы.
2.2.2 Ошибки сбора информации
Ошибки и погрешности, допущенные во время сбора информации и не связанные с выборкой, называют невыборочными ошибками. Они включают:
- выбор неверных элементов выборки для опросов и интервью;
- мнения тех, кто отказался давать интервью или не оказался дома (в этом случае необходима замена респондентов из резерва);
- ложные оценки, даваемые респондентами преднамеренно;
- фальсификацию полученных данных со стороны интервьюеров;
- ошибки, связанные с переписыванием собранной информации из анкет.
Невыборочные ошибки классифицируются на ошибки интервьюеров и ошибки респондентов а, так же, на преднамеренные ошибки и непреднамеренные ошибки.
Преднамеренная ошибка имеет место, когда соответствующее лицо (интервьюер или респондент) сознательно нарушает установленные требования к заполнению анкеты, либо к сбору данных (например, интервьюер сам заполнил анкеты).
Непреднамеренная ошибка главным образом определяется неправильным пониманием со стороны соответствующих лиц, либо усталостью лица, собирающего информацию.
Для исключения возможности преднамеренных ошибок, со стороны исследователя должен быть обеспечен контроль. Он может осуществляться двумя способами:
- путем надзора за работой интервьюеров;
- путем проверки выполненной работы.
В данном разделе, в случае если в исследовании участвовали третьи лица, студент должен описать примененные способы контроля и его результаты.
Для уменьшения ошибки, обусловленной отказами респондентов отвечать, эту ошибку следует прежде всего измерить, а затем скорректировать.
Взвешенная средняя оценка ошибки «отказа» рассчитывается по формуле:
 |
где, ан – величина ошибки
Хп, Хф – взвешенная средняя оценка для фактической и проектной выборки;
Ха, Хв,….Хm – средние оценки для разных подгрупп выборки
Wаф(п), Wвф(п), Wmф(п) – веса отдельных подгрупп (в фактической и проектной выборках) характеризующие долю подгруппы в совокупности
Пример расчета показан в таблице 6.
Таблица 6 – Пример расчета величины ошибки
Характеристика выборки | Фактически ответил | Ответы на вопрос о цене за флакон крема | Средняя оценка | ||||
Мужчины | Женщины | Мужчины | Женщины | Мужчины (в среднем) | Женщины (в среднем) | Мужчины | Женщины |
50% | 50% | 25% | 75% | 60р. | 90р. | 75р. | 82,5р. |
В таком случае выборка должна быть подкорректирована (выполнен ремонт выборки), т. е. дополнительно должны быть опрошены мужчины чтобы соотношение составило 50х50, либо выборка должна быть первоначально взята больших размеров, чем расчетная величина, чтобы можно было выбрать подгруппы, по размерам соответствующие целевой выборке.
Анализ ошибок, методы расчета выборок и их результаты описываются в данном разделе.
2.3 Анализ полученной информации
2.3.1 Особенности маркетинговой информации
При обработке маркетинговой информации следует помнить об ее особенностях, которые накладывают отпечаток на методы обработки:
1. Маркетинговая информация по своей природе и специфике очень разнообразна. Собранная информация по своей структуре, состоит из нескольких видов (экономическая, социально-психологическая, техническая, политическая и т. д.) и нескольких типов (факты, оценки, прогнозы, слухи, обобщенные связи).
2. Часто информация получена при изучении массовых явлений. Человек же, обладает ограниченными возможностями в области хранения, восприятия больших массивов данных. Для компенсации этой ограниченности, им созданы различные символические системы (средние, меры рассеивания и т. д.). Поэтому информация чаще всего представлена, не величинами, а показателями. Отсюда необходимость доказательства ее валидности (обоснованности).
3. Открываемые закономерности не объективны, они всегда несут на себе отпечаток влияния исследователя. Отсюда возможность ошибок и необходимость их оценки.
Таким образом, задача анализа данных всегда двояка: с одной стороны – извлечение из имеющихся данных всей заложенной в них информации; с другой стороны – оценка качества самих данных, определение насколько они значимы и верны.
Анализ, выполняемый в данной курсовой работе, подразделяется на 3 этапа:
1. Статистический анализ.
2. Конъюнктурный анализ.
3. Прикладной анализ
2.3.2 Статистический анализ
Статистический анализ представляет собой анализ по отдельным показателям. Он выполняется как по первичной информации, так и по вторичной с помощью программного продукта SPSS – программы для обработки статистической информации (версия 10,0; 11,0; и т. д.).
Для проведения этого анализа информация предварительно табулируется (формируется в таблицы).
Методики табулирования и работы с программой SPSS давались в дисциплине «Компьютерная обработка маркетинговой информации» и описаны в литературных источниках [2,3].
В работе последовательно выполняются 4 вида статистического анализа:
1) дескриптивный анализ;
2) выводной анализ;
3) анализ гипотез;
4) анализ связей.
Дескриптивный анализ
Как было сказано ранее, человек не в состоянии воспринимать большие массивы данных. В качестве символических систем позволяющих воспринять и переработать такие массивы служат инструменты дескриптивного анализа.
В дескриптивном анализе наиболее широко используются две группы мер:
1. Меры «центральной тенденции»
2. Меры вариации
Меры центральной тенденции, описывающие типичный ответ или типичного респондента, включают в себя среднюю, моду и медиану.
Мода – значение проявляющаяся наиболее часто по сравнению с другими значениями.
Медиана – точка на шкале измеренных значений, выше и ниже которой лежит по половине всех измеренных значений.
Средняя величина – сумма значений деления на их количество (средняя арифметическая величина)
Меры вариации, описывающие степень схожести или несхожести респондентов или ответов с «типичными» респондентами или ответами. К ним относятся: распределение частот, размах вариации, межквартильный размах, дисперсия, среднеквадратическое (стандартное) отклонение и коэффициент вариации.
Распределение частот – число случаев появлений каждого значения измеренной характеристики (приказа) в каждом выбранном диапазоне ее значений. Распределение частот в программе SPSS рассчитывается в частной таблице.
Размах вариации – отражает разброс данных и равен разности между наибольшим и наименьшим значением в выборке.
Межквартильный размах – это разность между 75 и 25 –м процентами или размах вариации распределения, охватывающий центральные 50% всех наблюдений.
Разность между средним значением переменной и любым из ее наблюдаемых значений называют отклонением от среднего.
Дисперсия – среднее из квадратов отклонение переменной от ее средней величины. Она не может быть отрицательной. Если значения данных сгруппированы вокруг среднего она невелика. И наоборот, если данные разбросаны, то мы имеем дело с большой дисперсией.
Среднеквадратическое (стандартное) отклонение – равно квадратному корню из дисперсии.
Коэффициент вариации – отношение стандартного отклонения к среднему арифметическому, выраженное в процентах. Коэффициент вариации – показатель относительной изменчивости переменной. Он вычисляется и имеет смысл только для шкал равных отношений.
В данной курсовой работе дескриптивный анализ начинается с оценки распределения частот. Для этого с помощью программы SPSS строится частотные таблицы (методика их построения дана в работах [2,3]).
Частотная таблица представляет собой таблицу, в которой приведены результаты обработки ответов на вопросы, например, анкеты.
Здесь по каждому вопросу даются частоты каждого варианта ответа в натуральном выражении (число человек) и процентом выражении. (Пример элемента такой таблице дан в Приложении 3).
Каждая строка такой таблицы представляет собой подсчет ответов связанных со значениями одной переменной и дальнейшее выражение их в процентном виде. Таким образом, каждая строка представляет собой вариационный ряд или распределение частот значений переменной.
Относительная частота различных значений переменной выраженная в процентах называется частостью.
Варианты ответов, как уже указывалось в разделе 2.1.2., могут быть представлены различными шкалами, и быть метрическими (числовыми) и неметрическими (выраженными словами и словосочетаниями).
Дальнейший анализ тесно зависит от используемой шкалы и выполняется по строкам частотной таблицы.
Так, в качестве показателя центральной тенденции:
Медиана – рассчитывается для порядковых шкал;
Мода – для номинальных шкал;
Среднее арифметическое – для интервальных шкал и шкал равных отношений.
Расчет выполняется в программе SPSS.
После расчета показателей центральной тенденции рассчитываются показатели вариации (изменчивости).
Эти показатели могут быть вычислены только для интервальных шкал, либо для шкал равных отношений, поэтому расчет ведется только для строк частотной таблицы, которые выражены в этих шкалах.
Для них рассчитываются:
- размах вариации;
- межквартильный размах;
- дисперсия;
- среднеквадратическое (стандартное) отклонение;
- коэффициент вариации.
Выводной анализ
Вывод-вид анализа направленного на получение общих заключений о всей совокупности на основе наблюдения за выборкой.
Он основан на статистическом анализе результатов выборки и направлен на оценку параметров совокупности в целом.
Как уже говорилось выше, задача анализа данных всегда двояка:
С одной стороны - извлечение из имеющихся данных всей заложенной в них информации.
С другой стороны – оценка качества самих данных, их значимости и достоверности.
Выводной анализ дает возможность оценить именно качество данных. Здесь оценивается качество данных в тех видах исследований, которые выполнены не на всей генеральной совокупности, а на ее части. Оценивается качество данных, собранных с помощью таких видов исследования, как
- массовые выборочные опросы;
- наблюдения, выполненные на выборке;
- экспертные опросы.
Массовые выборочные опросы и наблюдения
При расчете выборок для этих видов исследования в расчетных формулах требовалось принять значения таких показателей, как:
- коэффициент доверия (t) (принят = 2);
- выборочная дисперсия (σ 2) (принята = 0,5);
- предельная, заданная ошибка выборки (∆) (принята 5%, или =0,05).
Эти данные были использованы при расчете выборки. Но в ходе сбора информации возможны отклонения от запроектированной выборки, поэтому в данном разделе следует выполнить следующее:
1) Выбрать вопрос анкеты, по результатам обработки которого будут проведены расчеты. Обычно в качестве такого вопроса выбирается вопрос, связанный с расчетом спроса и имеющий только два варианта ответа. Например, вопрос о том собирается ли потребитель покупать данный товар. Шкала ответов на него содержит варианты ответов «да» и «нет». По результатам ответов на него делается, обычно, заключение о коэффициенте перехода от емкости рынка к спросу (коэффициенте спроса).
2) По результатам ответов на данный вопрос рассчитать фактическую выборочную дисперсию, как произведение доли ответивших на этот вопрос «да» на долю ответивших «нет» (p×q).
3) С учетом полученной дисперсии рассчитать ошибку выборки по формуле:
|
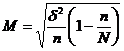
4) Подставив рассчитанные значения дисперсии и ошибки выборки в формулу расчета выборки, вновь рассчитать выборку.
5) Сравнить полученную величину выборки с проектной величиной и фактической величиной. Если проектная или фактическая величина выборки была меньше, чем получилась в этом расчете, исследования придется дополнить.
6) Проверить величину рассчитанной ошибки выборки: считается, что исследования репрезентативны, если ошибка не превышает 5% (0,05).
Внимание студентов!
Поскольку в курсовой работе исследуется не вся выборка, а только разведочная совокупность, расчетная ошибка выборки будет более 5%, что является допустимым для курсовой работы.
Для экспертных опросов выводной анализ отличается следующим:
При проведении экспертных опросов, для проверки качества данных рассчитывается коэффициент конкордации – согласованности мнения экспертов. Коэффициент конкордации вычисляется по формуле
|
где s - сумма квадратов отклонений суммы рангов для каждого объекта от средней суммы рангов:
|
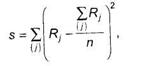
Rj - ранг j-го объекта; к - число рядов рангов (в данном случае это число показателей, по которым ранжировались объекты); п - число ранжируемых объектов.
Анализ гипотез
Поскольку при проектировании маркетингового исследования были выдвинуты гипотезы, в данном разделе необходима их проверка.
Доказательство некоторых гипотез, (например, гипотезы по сегментации рынка) может быть выполнено методами статистической проверки гипотез.
Проверка гипотезы – это статистическая процедура, применяемая для подтверждения или отклонения гипотезы и основанная на выборочных исследованиях.
Такая проверка гипотезы осуществляется на основе выявления согласованности эмпирических данных, с гипотетическими. Если расхождение не выходит за пределы случайных ошибок, гипотезу принимают, при этом не делается ни каких заключений о правильности самой гипотезы.
Проверка может быть выполнена с помощью статистических критериев.
Статистический критерий – это решающее правило, обеспечения принятия истинной и отклонение ложной гипотезы с высокой вероятностью. Обычно это правило содержит метод расчета определенного числа (формула, алгоритм) и нормативное значение данного числа.
Различают параметрические и непарамитрические критерии.
Параметрические критерии в своих формулах содержат такие статистические параметры как среднеквадратическое отклонение, дисперсия. Они применяются в основном для проверки гипотез по вопросам, ответы на которые даны метрическими (числовыми) шкалами (шкала равных отношений, интервальная шкала).
Непараметрические критерии применяются для неметрических (не числовых) шкал.
В данной курсовой работе студент должен провести проверку гипотезы о сегментации рынка с помощью одного или нескольких выбранных непараметрических критериев. В процессе работы должна быть выполнена проверка по следующим направлениям:
- доказана достоверность различий между сегментами;
- доказана незначимость различий внутри сегментов.
Среди непараметрических критериев различают 4 группы критериев:
1. критерии различий - применяются для оценки различий. Например, между 2мя, 3мя сегментами. Показывают есть различия, либо их нет. Это:
· Q – критерий Розенбаума;
· U – критерий Манна-Уитни;
· Н - критерий Крускала-Уоллиса.
2. Критерии изменений – применяются для доказательства того, что в результате каких либо действий произошли изменения (сдвиги) в измеряемых показателях.
· G - критерий знаков;
· Т – критерий Вилкоксона;
· Х2г – критерий Фридмена
· L – критерий тенденций Пейджа.
3. Критерии согласия распределений – применяются для доказательства гипотез по распределению признака
· х2 – критерий Пирсона;
· λ - критерий Колмогорова – Смирнова.
4. Многофункциональные критерии – могут использоваться по отношению к самым разнообразным данным, выборкам и задачам.
· φ* - угловое преобразование Фишера;

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
