
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Автокорреляционная функция характеризует общую зависимость значений процесса в некоторый данный момент времени от значений в другой момент времени (2.9). Автокорреляционная функция – это действительная четная функция с максимумом в точке t = 0. График функции автокорреляции называют автокоррелограммой. Основным приложением автокорреляционной функции физического процесса является исследование того, в какой степени значения процесса в некоторый момент времени влияют на значения процесса в некоторый момент в будущем. Автокорреляционная функция представляет собой средство выявления детерминированных процессов, которые могут маскироваться случайным фоновым шумом.
Спектральная плотность случайного процесса описывает общую частотную структуру процесса через спектральную плотность среднего квадрата его значений. Среднее значение квадрата реализации в интервале частот от f до f + Df можно получить, подавая эту реализацию на вход полосового фильтра с узкой полосой пропускания и осредняя возведенную в квадрат функцию на выходе фильтра:
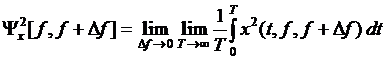 , (2.13)
, (2.13)
где x(t, f, f + Df) – составляющие функции x(t), имеющие частоты в [f, f + Df].
Основным применением спектральной плотности физического процесса является исследование его частотной структуры.
На практике часто возникает необходимость описать некоторые общие или совместные характеристики по двум и более реализациям.
Совместная плотность распределения двух случайных процессов определяет вероятность того, что ординаты процессов в произвольный момент времени будут заключены одновременно в двух определенных интервалах их значений. Основным применением совместной плотности распределения является установление вероятностных законов для явлений, которые описываются двумя и более процессами, связанными между собой.
Взаимная корреляционная функция двух случайных процессов характеризует общую зависимость значений одного процесса от значений другого. На практике данная функция может применяться для решения следующих задач.
1. Определение времени задержки. Предположим, что исследователя интересует, какое время необходимо для того, чтобы сигнал прошел через заданную систему. Если система линейна, то зная взаимную корреляционную функцию, связывающую сигналы на входе и на выходе системы, можно найти время задержки. Сигнал на выходе системы смещен во времени относительно сигнала на входе системы. Взаимная корреляционная функция будет иметь максимум при значении t, равном времени, которое необходимо для прохождения сигнала через данную систему. Однако этот метод на практике зачастую бывает неприменим, т. к. время прохождения сигнала через систему может зависеть от частоты сигнала, тогда четко выраженный пик на коррелограмме отсутствует. В этом случае нужно использовать сведения о взаимной спектральной плотности.
2. Определение тракта сигнала. Рассмотрим линейную систему, через которую сигнал может проходить двумя или более различными путями (трактами) и давать на выходе наблюдаемый сигнал. Пусть необходимо точно определить путь прохождения сигнала. Обычно каждому тракту соответствует определенное время задержки, на взаимной коррелограмме для каждого тракта появляются отдельные пики, которые дают значимый вклад в энергию сигнала на выходе системы. Если вычислить предполагаемое время задержки, а затем сравнить с измеренным значением сдвига, соответствующими положению пиков на взаимной коррелограмме, то можно найти тракты, которые дают наибольший вклад в энергию сигнала на выходе.
3. Обнаружение сигналов в шуме и их восстановление. Если сигнал, который необходимо обнаружить, известен, то вычисляется корреляционная функция сигнала, состоящего из полезного сигнала и шума, с эталонным сигналом.
Взаимная спектральная плотность представляет собой преобразование Фурье взаимной корреляционной функции. Обычно это комплексная величина
![]() , (2.14)
, (2.14)
где Cxy( f ) – действительная часть, называется синфазной составляющей; Qxy( f ) – мнимая часть, называется квадратурной составляющей.
Синфазную составляющую можно представить как среднее произведение функций x(t) и y(t) в узком интервале частот от f до f + Df,
деленное на ширину интервала. Такое же определение можно дать и квадратурной составляющей за исключением того, что либо x(t), либо y(t) сдвинуты во времени таким образом, что составляющие с частотой f
будут сдвинуты по фазе на 90°.
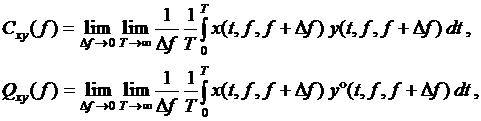 (2.15)
(2.15)
где x(t, f, f + Df ) и y(t, f, f + Df ) – отфильтрованные части процессов x(t) и y(t); y°(t, f, f + Df) – функция сдвинута по фазе на 90° относительно
y(t, f, f + Df ).
Взаимная спектральная плотность применяется для измерения частотной характеристики системы, измерения времени задержки сигнала, а также в задачах прогнозирования и фильтрации.
2.3. Эмпирическая функция распределения
Пусть в полученной выборке значение x1 параметра наблюдалось n1 раз, значение x2 – n2 раз, значение xk – nk раз, n1 + n2 + … + nk = n.
Совокупность значений xi , записанных в порядке их возрастания, называют вариационным рядом, величины ni – частотами, а их отношения к объему выборки ni = ni / n – относительными частотами.
Под распределением понимают соответствие между наблюдаемыми вариантами и их частотами или относительными частотами. Пусть nx – количество наблюдений, при которых случайные значения параметра Х меньше x. Относительная частота данного события равна nx / n. Это отношение является функцией от x и от объема выборки: Fn(x) = nx / n. Величина Fn(x) обладает всеми свойствами функции распределения:
– Fn(x) неубывающая функция, ее значения принадлежат отрезку [0; 1];
– если x1 – наименьшее значение параметра, а xk – наибольшее, то Fn(x) = 0, когда x < x1, и Fn(xk) = 1, когда ![]() .
.
Функция Fn(x) определяется по экспериментальным данным, поэтому ее называют эмпирической функцией распределения. В отличие от эмпирической функции Fn(x) функцию распределения F(x) генеральной совокупности называют теоретической функцией распределения, она характеризует не относительную частоту, а вероятность события X < x. Из теоремы Бернулли вытекает, что относительная частота Fn(x) стремится по вероятности к вероятности F(x) при неограниченном увеличении n. Следовательно, при большом объеме наблюдений теоретическую функцию распределения F(x) можно заменить эмпирической функцией Fn(x).
При большом объеме выборки (будем считать n большим, если n > 40) в целях удобства обработки и хранения сведений прибегают к группированию экспериментальных данных в интервалы. Количество интервалов следует выбрать так, чтобы в необходимой мере отразилось разнообразие значений параметра в совокупности, и в то же время закономерность распределения не искажалась случайными колебаниями частот по отдельным разрядам. Существуют нестрогие рекомендации по выбору количества k и размера h таких интервалов, в частности:
– в каждом интервале должно находиться не менее 5 – 7 элементов, в крайних разрядах допустимо всего два элемента;
– количество интервалов не должно быть очень большим или очень маленьким. Минимальное значение k должно быть не менее 6 – 7. При объеме выборки, не превышающем несколько сотен элементов, величину k задают в пределах от 10 до 20. Для очень большого объема выборки (n > 1000) количество интервалов может превышать указанные значения. Некоторые исследователи рекомендуют пользоваться соотношением y = 1,441 ln(n) + 1;
– при относительно небольшой неравномерности длины интервалов удобно выбирать одинаковыми, равными величине h = (xmax – xmin) / k, где xmax – максимальное; xmin – минимальное значение параметра. При существенной неравномерности закона распределения длины интервалов можно задавать меньшего размера в области быстрого изменения плотности распределения;
– при значительной неравномерности лучше в каждый разряд назначать примерно одинаковое количество элементов выборки. Тогда длина конкретного интервала будет определять крайними значениями элементов выборки, сгруппированными в этот интервал, т. е. будет различна для разных интервалов (в этом случае при построении гистограммы нормировка по длине интервала обязательна – в противном случае высота каждого элемента гистограммы будет одинакова).
Группировка результатов наблюдений по интервалам предусматривает:
– определение размаха изменений параметра х;
– выбор количества интервалов и их величины;
– подсчет для каждого i-го интервала [xi ; xi+1] частоты ni или относительной частоты попадания варианты в интервал.
В результате формируется представление экспериментальных данных в виде интервального или статистического ряда. Графически статистический ряд отображают в виде гистограммы, полигона и ступенчатой линии. Часто гистограмму представляют как фигуру, состоящую из прямоугольников, основаниями которых служат интервалы длиною h, а высоты равны соответствующей относительной частоте. Однако такой подход неточен. Высоту i-го прямоугольника zi следует выбрать равной ni / (nh). Такую гистограмму можно интерпретировать как графическое представление эмпирической функции плотности распределения fn(x), в ней суммарная площадь всех прямоугольников составит единицу. Гистограмма помогает подобрать вид теоретической функции распределения для аппроксимации экспериментальных данных.
Полигоном называют ломаную линию, отрезки которой соединяют точки с координатами по оси абсцисс, равными серединам интервалов, а по оси ординат – соответствующим относительным частотам. Эмпирическая функция распределения отображается ступенчатой ломаной линией: над каждым интервалом проводится отрезок горизонтальной линии на высоте, пропорциональной накопленной относительной частоте в текущем интервале. Накопленная относительная частота равна сумме всех относительных частот, начиная с первого и до данного интервала включительно.
2.4. Наиболее важные функции распределения
Наиболее важной с точки зрения прикладной статистики является нормальное (гауссово) распределение. Широко используются в статистике еще три функции, связанные с нормально распределенными случайными величинами: c2-распределение; t-распределение; F-распределение.
Наиболее важный тип случайной величины, который встречается как в прикладной, так и в теоретической статистике, величина x(k) с плотностью распределения 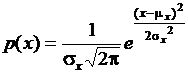 . Данная функция распределения называется нормальным или гауссовым распределением. Нормальное распределение представляют в более удобной форме, используя нормированную величину
. Данная функция распределения называется нормальным или гауссовым распределением. Нормальное распределение представляют в более удобной форме, используя нормированную величину 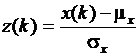 . Величина z(k) имеет математическое ожидание равное нулю и дисперсию равную единице, плотность вероятности
. Величина z(k) имеет математическое ожидание равное нулю и дисперсию равную единице, плотность вероятности 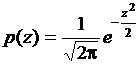 .
.
Обозначим za величину, которая соответствует заданной вероятности ![]()
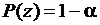 . Тогда
. Тогда 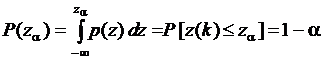 или
или 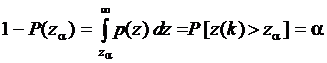 . Величину za, удовлетворяющую этим формулам называют 100a-процентной точкой.
. Величину za, удовлетворяющую этим формулам называют 100a-процентной точкой.
Нормальное распределение имеет важное значение благодаря центральной предельной теореме, согласно которой распределение суммы независимых случайных величин при весьма общих условиях близко к нормальному при произвольном виде распределения отдельных слагаемых. Так как реальные физические явления часто представляют собой результат суммарного воздействия многих величин, то нормальное распределение представляет собой хорошее приближение обычно наблюдаемых распределений.
Рассмотрим n независимых случайных величин z1(k), z2(k), … , zn(k), каждая из которых имеет нормальный закон распределения с mz = 0 и sz = 1. Случайная величина ![]() называется
называется ![]() величиной с n степенями свободы. Функция плотности распределения
величиной с n степенями свободы. Функция плотности распределения ![]() с n степенями свободы
с n степенями свободы
. (2.16)
Математическое ожидание и дисперсия величины ![]() равны n и 2n соответственно.
равны n и 2n соответственно. ![]() -распределение представляет собой частный случай g-распределения, величина, равная корню квадратному из
-распределение представляет собой частный случай g-распределения, величина, равная корню квадратному из ![]() с двумя степенями свободы, подчиняется распределению Рэлея, а величина, равная корню квадратному из
с двумя степенями свободы, подчиняется распределению Рэлея, а величина, равная корню квадратному из ![]() с тремя степенями свободы, подчиняется распределению Максвелла. При увеличении числа степеней свободы
с тремя степенями свободы, подчиняется распределению Максвелла. При увеличении числа степеней свободы ![]() -распределение приближается к нормальному. В частности, при n > 30 величина
-распределение приближается к нормальному. В частности, при n > 30 величина ![]() распределена приблизительно по нормальному закону с математическим ожиданием равным
распределена приблизительно по нормальному закону с математическим ожиданием равным ![]() и дисперсией, равной 1.
и дисперсией, равной 1.
Пусть y(k) и z(k) независимые случайные величины, y(k) подчиняется распределению ![]() , а z(k) – нормальному распределению с математическим ожиданием равным 0 и дисперсией 1. Величина
, а z(k) – нормальному распределению с математическим ожиданием равным 0 и дисперсией 1. Величина 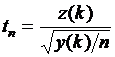 называется коэффициентом Стьюдента с n степенями свободы. Математическое ожидание и дисперсия равны 0 и n / (n–2) соответственно, при n > 2. Распределение Стьюдента (t-распределение) было предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student. По сравнению с нормальным, распределение Стьюдента более пологое, оно имеет меньшую дисперсию. Это отличие заметно при небольших значениях n, что следует учитывать при проверке статистических гипотез (критические значения аргумента распределения Стьюдента превышают аналогичные показатели нормального распределения). Распределение Стьюдента применяется для описания ошибок выборки при n < 30. При n, превышающем 100, данное распределение практически соответствует нормальному, для значений n из
называется коэффициентом Стьюдента с n степенями свободы. Математическое ожидание и дисперсия равны 0 и n / (n–2) соответственно, при n > 2. Распределение Стьюдента (t-распределение) было предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student. По сравнению с нормальным, распределение Стьюдента более пологое, оно имеет меньшую дисперсию. Это отличие заметно при небольших значениях n, что следует учитывать при проверке статистических гипотез (критические значения аргумента распределения Стьюдента превышают аналогичные показатели нормального распределения). Распределение Стьюдента применяется для описания ошибок выборки при n < 30. При n, превышающем 100, данное распределение практически соответствует нормальному, для значений n из
диапазона от 30 до 100 различия между распределением Стьюдента и нормальным распределением составляют несколько процентов. Поэтому относительно оценки ошибок малыми считаются выборки объемом не более 30 единиц, большими – объемом более 100 единиц.
А. Фишера (F-распределению Фишера – Снедекора) подчиняется случайная величина ![]() , равная отношению двух случайных величин у1 и у2, имеющих
, равная отношению двух случайных величин у1 и у2, имеющих ![]() -распределение с n1 и n2 степенями свободы.
-распределение с n1 и n2 степенями свободы.
2.5. Оценки параметров распределения
Значение параметра, вычисленное по ограниченному объему экспериментальных данных, является случайной величиной, т. е. значение такой величины от выборки к выборке может меняться. Следовательно, в результате обработки экспериментальных данных определяется не значение параметра, а только лишь его приближенное значение – статистическая оценка этого параметра. Получить статистическую оценку параметра теоретического распределения означает найти функцию от имеющихся результатов наблюдения, которая и даст приближенное значение искомого параметра.
Различают два вида оценок – точечные и интервальные. Точечными называют такие оценки, которые характеризуются одним числом. При малых объемах выборки точечные оценки могут значительно отличаться от истинных значений параметров, поэтому их применяют при большом объеме выборки. Интервальные оценки задаются двумя числами, определяющими вероятный диапазон возможного значения параметра. Эти оценки применяются для малых и для больших выборок.
Применительно к каждому оцениваемому параметру закона распределения генеральной совокупности существует множество функций, позволяющих вычислить искомые значения. Например, оценку математического ожидания можно вычислить, взяв среднее арифметическое выборочных значений, половину суммы крайних членов вариационного ряда, средний член выборки и т. д. Указанные функции отличаются качеством оценок и трудоемкостью реализации.
Для характеристики эмпирического распределения можно использовать оценки центральных и начальных моментов. Применение находят моменты до четвертого порядка включительно, т. к. точность выборочных моментов резко падает с увеличением их порядка, в частности, дисперсия начальных моментов порядка r зависит от моментов порядка 2r. Она становится значительной для моментов высокого порядка даже при больших объемах выборки. Выборочные значения моментов определяют непосредственно по выборке или по сгруппированным данным.
Выборочные значения центральных моментов случайной величины X вычисляются по выборке с применением с формул:
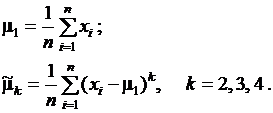 (2.17)
(2.17)
Эти величины являются оценками соответствующих теоретических моментов m1 – m4 и должны рассматриваться как случайные. Вычисления по формулам (2.17) дают состоятельные, но смещенные оценки моментов старше первого. Смещение удается устранить введением поправочных коэффициентов, зависящих от объема выборки. Несмещенными и состоятельными будут оценки, вычисленные по формулам:
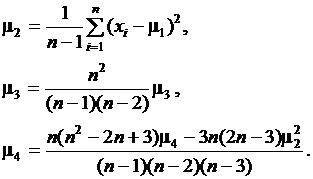 (2.18)
(2.18)
Начальный эмпирический момент порядка r по несгруппированным данным определяется соотношением
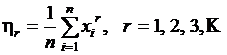 (2.19)
(2.19)
Центральные и начальные оценки моментов связаны между собой следующими зависимостями:
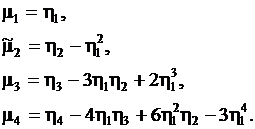 (2.20)
(2.20)
В процессе обработки экспериментальных данных проще сначала определить оценки начальных моментов, потом перейти к смещенным оценкам центральных моментов и затем вычислить несмещенные оценки.
Квантилью, отвечающей уровню вероятности g, называют такое значение варианты xg, при котором функция распределения случайной величины принимает значение g, т. е. квантиль – это значение аргумента xg функции распределения, при котором F(xg) = g. Эмпирическую квантиль находят по заданному значению вероятности g, используя вариационный ряд или ступенчатую ломаную линию.
Для описания распределений применяются и другие характеристики:
– среднеквадратическое отклонение ![]() ;
;
– коэффициент асимметрии 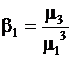 ;
;
– эксцесс 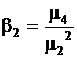 ;
;
– стандартизованные переменные 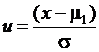 .
.
Коэффициент асимметрии характеризует «скошенность» распределения относительно симметричного нормального.
Коэффициент эксцесса характеризует островершинность распределения относительно нормального.
Стандартизация переменной позволяет упростить расчеты, кроме того, в литературе многие справочные статистические таблицы приводятся именно для стандартизованных переменных. Математическое ожидание стандартизованной переменной равно нулю, а дисперсия равна единице. Величина u называется центрированной и нормированной. Переход от центрированной и нормированной величины к исходной осуществляется простым преобразованием ![]() . Потери информации при стандартизации и обратном преобразовании не происходит.
. Потери информации при стандартизации и обратном преобразовании не происходит.
Каждый элемент экспериментальных данных формируется под влиянием как общих закономерностей, так и особых условий и случайных событий. Следовательно, в обработке экспериментальных данных большой интерес представляют вопросы оценки величин, характеризующих вариацию значений параметра у разных объектов или у одного и того же объекта в разные моменты времени. Вариацией какого-либо параметра (показателя) в совокупности наблюдений называется различие его значений у разных элементов этой совокупности. Именно это свойство является объектом исследования большинства методов обработки экспериментальных данных. Для характеристики вариации нет единого показателя, в этих целях применяются моменты распределения выше первого, производные от них величины, размах выборки, квантили и другие.
2.6. Распределение выборочных характеристик
Рассмотрим случайную величину x(k), имеющую функцию распределения P(x). Пусть x1, x2, … , xn выборка, состоящая из n наблюденных значений величины x(k). Любая величина, вычисленная по этим выборочным значениям, тоже будет случайной. Например, среднее значение выборки ![]() . Если из одной и той же случайной величины x(k) извлекать ряд различных выборок объема N, то средние значения
. Если из одной и той же случайной величины x(k) извлекать ряд различных выборок объема N, то средние значения ![]() , вычисленные по различным выборкам, будут различаться между собой. Следовательно, выборочное среднее представляет собой случайную величину, которая имеет некоторую функцию распределения. Эту функцию называют выборочным распределением выборочного среднего.
, вычисленные по различным выборкам, будут различаться между собой. Следовательно, выборочное среднее представляет собой случайную величину, которая имеет некоторую функцию распределения. Эту функцию называют выборочным распределением выборочного среднего.
Рассмотрим среднее значение выборки объема N независимых наблюдений случайной величины x(k). В случае нормального распределения случайной величины x(k) с математическим ожиданием mx и дисперсией ![]() выборочное среднее
выборочное среднее ![]() будет распределено нормально с
будет распределено нормально с 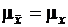 и
и 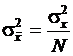 .
.
Выборочное распределение среднего значения выборки можно описать при помощи величины 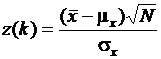 . Отсюда вытекает утверждение
. Отсюда вытекает утверждение  .
.
Пример 2.1.
Пусть необходимо извлечь выборку объема N = 25 независимых наблюдений нормально распределенной случайной величины x(k) с математическим ожиданием mx = 10 и дисперсией ![]() = 4. Определим интервал, в который с вероятностью 95 % будет заключено среднее значение. Выборочное среднее
= 4. Определим интервал, в который с вероятностью 95 % будет заключено среднее значение. Выборочное среднее ![]() представляет собой одно значение, выбранное из нормально распределенных случайных величин с
представляет собой одно значение, выбранное из нормально распределенных случайных величин с 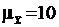 и
и 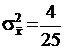 . Используем нормированную величину
. Используем нормированную величину 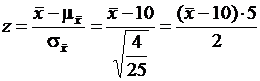 .
.
Для того чтобы найти интервал, в который с вероятностью 95 % заключены значения ![]() , необходимо задать такие границы этого интервала, что вероятность попадания
, необходимо задать такие границы этого интервала, что вероятность попадания ![]() слева от интервала составляет 2,5 % и вероятность попадания
слева от интервала составляет 2,5 % и вероятность попадания ![]() справа от интервала составляет 2,5 %.
справа от интервала составляет 2,5 %. 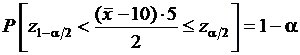 .
. 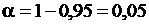 .
.
По таблице находим 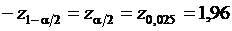 , т. е.
, т. е. 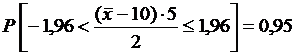 ,
, ![]() , а значит
, а значит ![]() .
.
В случае если случайная величина распределена по закону, отличному от нормального, из следствий центральной предельной теоремы
вытекает, что при увеличении объема выборки N выборочное распределение выборочного среднего значения выборки приближается к нормальному распределению независимо от вида распределения исходной величины x(k).
С точки зрения практики предположение о нормальности выборочного среднего ![]() становится приемлемым во многих случаях при N > 4 и вполне хорошо оправдывается при объемах N > 10. Следовательно, при достаточно больших объемах выборок в качестве выборочного распределения среднего значения выборки
становится приемлемым во многих случаях при N > 4 и вполне хорошо оправдывается при объемах N > 10. Следовательно, при достаточно больших объемах выборок в качестве выборочного распределения среднего значения выборки ![]() для случайной величины можно использовать выражение
для случайной величины можно использовать выражение 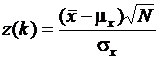 независимо от закона распределения случайной величины.
независимо от закона распределения случайной величины.
Рассмотрим дисперсию S 2 выборки объема N независимых
наблюдений случайной величины x(k). Пусть величина x(k) имеет нормальное распределение со средним значением mx и дисперсией ![]() . Найдем распределение выборочной дисперсии
. Найдем распределение выборочной дисперсии 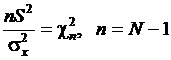 . Величина c2 подчиняется распределению c2 с n = N – 1 степенями свободы.
. Величина c2 подчиняется распределению c2 с n = N – 1 степенями свободы.
Отсюда следует вероятностное утверждение относительно выборочной дисперсии до извлечения выборки 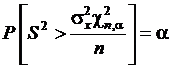 .
.
Для примера 2.1 найдем интервал, в который с вероятностью 95 % будет попадать дисперсия. Этот интервал может быть вычислен по формуле 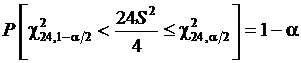 . По статистическим таблицам находим
. По статистическим таблицам находим ![]() ,
, ![]() ,
, 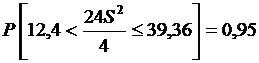 ,
, ![]() .
.
Пусть величина x(k) имеет нормальное распределение со средним значением mx и неизвестной дисперсией. Тогда 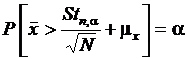 .
.
Пример 2.2.
Пусть необходимо извлечь выборку объема N = 25 независимых наблюдений нормально распределенной случайной величины x(k) с математическим ожиданием mx = 10 и неизвестной дисперсией. Определим интервал, в который с вероятностью 95 % будет заключено выборочное среднее значение. Из формулы 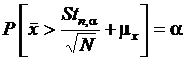 следует, что
следует, что 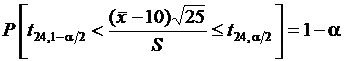 . По статистическим таблицам t24,0.025 = – t24,0.975 = 2,064, тогда
. По статистическим таблицам t24,0.025 = – t24,0.975 = 2,064, тогда 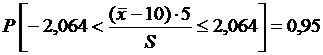 и
и 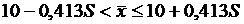 .
.
Рассмотрим дисперсии двух выборок – одной, состоящей из Nx независимых наблюденных значений случайной величины x(k) и другой, состоящей из Ny независимых наблюденных значений случайной величины y(k). Выборочная дисперсия определяется формулой 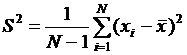 . Пусть величина x(k) подчиняется нормальному закону со средним значением mx и дисперсией
. Пусть величина x(k) подчиняется нормальному закону со средним значением mx и дисперсией ![]() , величина y(k) подчиняется нормальному закону со средним значением my и дисперсией
, величина y(k) подчиняется нормальному закону со средним значением my и дисперсией ![]() . Укажем распределения выборочных значений дисперсий
. Укажем распределения выборочных значений дисперсий ![]() и
и ![]() .
. 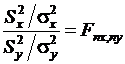 , где nx = Nx – 1, ny = Ny – 1. Величина Fnx,ny имеет
, где nx = Nx – 1, ny = Ny – 1. Величина Fnx,ny имеет
F-распределение с nx и ny степенями свободы. Отсюда вытекает следующее вероятностное утверждение об отношении выборочных дисперсий:
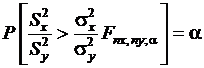 .
.
Если выборки состоят из наблюдений над одной и той же случайной величиной x(k) = y(k), то формула примет вид 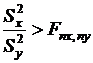 .
.
Пример 2.3.
Пусть производится выборка наблюдений объема Nx = 25 из независимых наблюдений нормально распределенной величины x(k) с математическим ожиданием mx = 10 и дисперсией ![]() = 4 и выборка наблюдений объема Ny = 10 из независимых наблюдений нормально распределенной величины x(k) с математическим ожиданием my = 100 и дисперсией
= 4 и выборка наблюдений объема Ny = 10 из независимых наблюдений нормально распределенной величины x(k) с математическим ожиданием my = 100 и дисперсией ![]() = 8. Определим интервал, в который с вероятностью 95 % будет заключено отношение выборочных дисперсий.
= 8. Определим интервал, в который с вероятностью 95 % будет заключено отношение выборочных дисперсий.
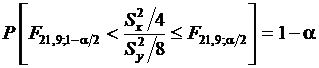 . По статистическим таблицам
. По статистическим таблицам 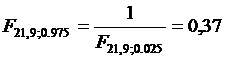 .
. 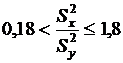 .
.
2.7. Задача точечного оценивания параметров
Точечная оценка предполагает нахождение единственной числовой величины, которая и принимается за значение параметра. Такую оценку целесообразно определять в тех случаях, когда объем экспериментальных данных достаточно велик. Не существует единого понятия о достаточном объеме экспериментальных данных, его значение зависит от вида оцениваемого параметра, предварительно будем считать достаточной выборку, содержащую не менее чем 10 значений. При малом объеме экспериментальных данных точечные оценки могут значительно отличаться от истинных значений параметров, что делает их непригодными для использования.
Задача точечной оценки параметров в типовом варианте постановки состоит в следующем.
Имеется выборка наблюдений (x1, x2, … , xn) за случайной величиной Х. Объем выборки n фиксирован. Известен вид закона распределения величины Х, например в форме плотности распределения f (T, x), где T – неизвестный (в общем случае векторный) параметр распределения. Параметр является неслучайной величиной. Требуется найти оценку q параметра T закона распределения.
Существует несколько методов решения задачи точечной оценки
параметров, наиболее употребительными из них являются методы максимального (наибольшего) правдоподобия, моментов и квантилей.
2.7.1. Метод максимального правдоподобия
Метод предложен Р. Фишером в 1912 г. Метод основан на исследовании вероятности получения выборки наблюдений (x1, x2, … , xn). Эта
вероятность равна f (х1, T) f (х2, T) … f (хп, T) dx1 dx2 … dxn.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
