
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
– сумму квадратов значений регрессии относительно среднего;
– сумму квадратов отклонений относительно линии регрессии (остаточная сумма квадратов).
Сумма квадратов регрессии есть сумма квадратов разности между значениями, найденными на основе регрессии, и средним. Сумма квадратов относительно линии регрессии есть сумма квадратов расстояний между наблюдаемыми точками и точками, полученными на основе регрессии. Если подобранная прямая проходит через все имеющиеся точки, то она является идеальной и сумма квадратов отклонений относительно этой прямой будет равна нулю, а вся вариация значений ![]() объясняется прямой. С другой стороны, если данные не содержат линейного тренда, то сумма квадратов регрессии относительно среднего будет мала и почти вся вариация в изменении
объясняется прямой. С другой стороны, если данные не содержат линейного тренда, то сумма квадратов регрессии относительно среднего будет мала и почти вся вариация в изменении ![]() может быть объяснена как вариация относительно линии регрессии.
может быть объяснена как вариация относительно линии регрессии.
Таблица 4.1
Дисперсионный анализ парной линейной регрессии
Источник вариации | Сумма квадратов | Степень свободы | Средний квадрат |
Регрессия |
| 1 |
|
Остаток |
| n - 1 |
|
Общая |
| n - 2 | - |
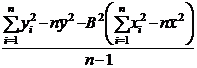
Регрессия будет значимой, если сумма квадратов регрессии относительно среднего будет больше по сравнению с суммой квадратов отклонений относительно регрессии.
Формально необходимо проверить нулевую гипотезу H0: В = 0 против альтернативы H1: В ¹ 0. Если В не равно нулю, то регрессия является значимой. Вычисления по проверке значимости регрессии лучше всего проводить в так называемой таблице дисперсионного анализа. В этой таблице общая сумма квадратов разбита на сумму квадратов регрессии и остаточную сумму квадратов.
Величина 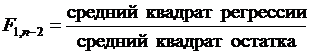 имеет F-распределение. Если вычисленное значение достаточно велико, то нулевая гипотеза отклоняется, следовательно, регрессия значима.
имеет F-распределение. Если вычисленное значение достаточно велико, то нулевая гипотеза отклоняется, следовательно, регрессия значима.
4.5. Множественная линейная регрессия
Уравнение линейной регрессии имеет вид
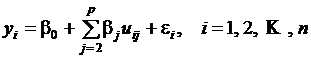 . (4.12)
. (4.12)
Обозначим 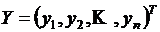 ,
, 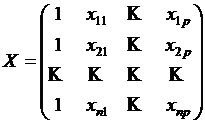 ,
, 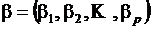 ,
, 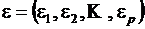 . Тогда в матричной форме модель примет вид
. Тогда в матричной форме модель примет вид ![]() . Оценкой является уравнение
. Оценкой является уравнение ![]() . Для оценки вектора неизвестных параметров b применяется МНК. Условие минимизации остаточной суммы может быть записано в виде
. Для оценки вектора неизвестных параметров b применяется МНК. Условие минимизации остаточной суммы может быть записано в виде
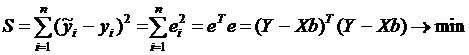 . (4.13)
. (4.13)
На основании необходимого условия экстремума функции нескольких переменных необходимо приравнять частные производные по этим переменным к нулю или в матричном виде
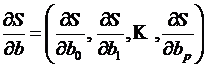 . (4.14)
. (4.14)
Для вектора частных производных получим формулу ![]() . Получаем систему уравнений в матричной форме
. Получаем систему уравнений в матричной форме
![]() . (4.15)
. (4.15)
Решением системы (4.15) является вектор ![]() .
.
Как и в случае парной регрессии в случае множественной регрессии общая вариация Q - сумма квадратов отклонений зависимой переменной от средней может быть разложена на две составляющие ![]() ;
; ![]() - сумма квадратов отклонений, обусловленных регрессией,
- сумма квадратов отклонений, обусловленных регрессией, ![]() - сумма квадратов отклонений, характеризующая влияние неучтенных факторов:
- сумма квадратов отклонений, характеризующая влияние неучтенных факторов:
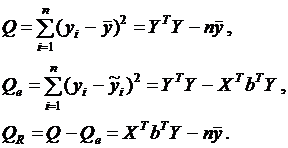 (4.16)
(4.16)
Уравнение множественной регрессии значимо (т. е. гипотеза о равенстве нулю коэффициентов 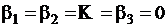 отвергается), если
отвергается), если 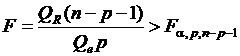 .
.
Одной из наиболее эффективных оценок адекватности регрессионной модели является коэффициент детерминации
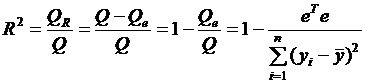 . (4.17)
. (4.17)
Коэффициент является мерой качества модели, характеристикой ее прогностической силы. Чем ближе R2 к единице, тем лучше регрессия описывает зависимость между объясняющими переменными и зависимой переменной.
Вместе с тем, использование только одного коэффициента детерминации для выбора наилучшего уравнения регрессии может оказаться недостаточным. На практике встречаются случаи, когда плохо определенная модель регрессии может дать сравнительно высокий коэффициент детерминации. Недостатком коэффициента детерминации является то, что он увеличивается при добавлении новых объясняющих переменных, хотя это и не обязательно улучшает качество регрессионной модели. В этом смысле предпочтительнее использовать скорректированный коэффициент детерминации
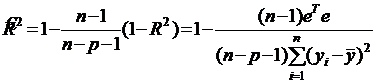 . (4.18)
. (4.18)
В отличие от коэффициента детерминации скорректированный коэффициент детерминации может уменьшаться при введении в модель новых объясняющих переменных, не оказывающих существенного влияния на зависимую переменную. Однако даже увеличение скорректированного коэффициента детерминации при введении в модель новой объясняющей переменной не всегда означает, что ее коэффициент регрессии значим.
4.6. Нелинейные модели регрессии
Для оценки параметров нелинейных моделей используется два подхода. Первый основан на линеаризации модели и заключается в том, что с помощью подходящих преобразований исходных переменных исследуемую зависимость представляют в виде линейного соотношения между преобразованными переменными.
Второй подход обычно применяется в случае, когда подобрать соответствующее линеаризующее преобразование не удается. В этом случае применяют методы нелинейной оптимизации на основе исходных переменных.
Для линеаризации модели в рамках первого подхода могут использоваться как модели нелинейные по переменным, так и нелинейные по
параметрам.
Если модель нелинейна по переменным, то введением новых переменных ее можно легко свести к линейной. Например, нелинейная модель ![]() путем преобразований
путем преобразований ![]() может быть приведена к линейному виду
может быть приведена к линейному виду ![]() .
.
Более сложной проблемой является нелинейность модели по параметрам, так как непосредственное применение МНК для их оценки невозможно. Например, для модели 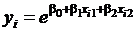 или
или 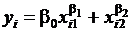 . В ряде случаев путем подходящих преобразований эти модели удается
. В ряде случаев путем подходящих преобразований эти модели удается
привести к линейному виду. Для приведенных в примере моделей это
удается сделать логарифмированием (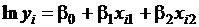 и
и 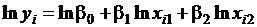 ).
).
Определение коэффициентов нелинейной регрессии в этом случае основано на решении системы линейных уравнений. Для этого можно применять универсальные пакеты численных методов или специализированные пакеты обработки статистических данных.
С ростом степени уравнения регрессии возрастает и степень моментов распределения параметров, используемых для определения коэффициентов. Так, для определения коэффициентов уравнения регрессии второй степени используются моменты распределения параметров до четвертой степени включительно. Известно, что точность и достоверность оценки моментов по ограниченной выборке экспериментальных данных резко снижается с ростом их порядка. Применение в уравнениях регрессии полиномов степени выше второй нецелесообразно.
Если модель нельзя привести к линейному виду, то для оценки параметров необходимо использовать специальные итеративные процедуры оценивания, например, многомерный метод Ньютона - Рафсона. Иногда решение, основанное на МНК, может быть найдено методом наискорейшего спуска. Очевидно, что для получения нелинейных регрессий необходимы помощь ЭВМ.
Качество полученного уравнения регрессии оценивают по степени близости между результатами наблюдений за показателем и предсказанными по уравнению регрессии значениями в заданных точках пространства параметров. Если результаты близки, то задачу регрессионного анализа можно считать решенной. В противном случае следует изменить уравнение регрессии (выбрать другую степень полинома или вообще другой тип уравнения) и повторить расчеты по оценке параметров.
4.7. Проблемы практического использования модели множественной регрессии
К числу проблем использования модели регрессии относятся:
– мультиколлинеарность, ее причины и методы устранения;
– использование фиктивных переменных при включении в модель качественных объясняющих переменных;
– линеаризация модели;
– корреляция между переменными.
Под мультиколлинеарностью понимается высокая взаимная коррелированность объясняющих переменных. Мультиколлинеарность может проявляться в функциональной (явной) и стохастической (скрытой) формах. При функциональной форме мультиколлинеарности по крайней мере одна из парных связей между объясняющими переменными является
линейной функциональной зависимостью. В этом случае матрица ![]() особенная, т. е. содержит линейно зависимые векторы-столбцы и ее определитель равен нулю. Это приводит к невозможности решения системы уравнений и получения оценок параметров регрессионной модели.
особенная, т. е. содержит линейно зависимые векторы-столбцы и ее определитель равен нулю. Это приводит к невозможности решения системы уравнений и получения оценок параметров регрессионной модели.
Мультиколлинеарность чаще проявляется в стохастической форме, когда хотя бы между двумя объясняющими переменными существует тесная корреляция. В этом случае матрица ![]() не является особенной, но ее определитель очень мал. Вектор параметров пропорционален
не является особенной, но ее определитель очень мал. Вектор параметров пропорционален ![]() . В результате получают значительные средние квадраты отклонения коэффициентов регрессии, и оценка значимости коэффициентов по t-критерию не имеет смысла. Оценки становятся очень чувствительными к незначительному изменению результатов эксперимента и объема выборки. Уравнения регрессии в этом случае, как правило, не имеют реального смысла.
. В результате получают значительные средние квадраты отклонения коэффициентов регрессии, и оценка значимости коэффициентов по t-критерию не имеет смысла. Оценки становятся очень чувствительными к незначительному изменению результатов эксперимента и объема выборки. Уравнения регрессии в этом случае, как правило, не имеют реального смысла.
Точных количественных критериев для определения наличия или отсутствия мультиколлинеарности нет. Один из подходов заключается в анализе корреляционной матрицы между объясняющими переменными и выявлении пар переменных, имеющих высокие коэффициенты корреляции (больше 0,8). Другой подход основан на анализе множественного коэффициента детерминации между одной переменной и группой других: если множественный коэффициент детерминации больше 0,6, это свидетельствует о мультиколлинеарности. Еще один подход состоит в исследовании матрицы ![]() . Если определитель или собственные значения близки к нулю, а также если
. Если определитель или собственные значения близки к нулю, а также если ![]() значительно отклонено от
значительно отклонено от ![]() , то это свидетельствует о мультиколлинеарности.
, то это свидетельствует о мультиколлинеарности.
Для устранения или уменьшения мультиколлинеарности используется ряд методов. Самый простой состоит в том, что из двух переменных, имеющих высокий коэффициент корреляции, одну переменную исключают из рассмотрения. При этом, какую переменную оставить, а какую исключить решают в первую очередь из практических соображений. Другой метод устранения мультиколлинеарности заключается в переходе от несмещенных оценок, определяемых по МНК, к смещенным ![]() , где t - некоторое положительное число.
, где t - некоторое положительное число.
Для устранения мультиколлинеарности может быть использован переход от исходных объясняющих переменных, связанных между собой корреляционной связью, к новым переменным, представляющим собой линейные комбинации исходных. При этом новые переменные будут слабокоррелированны или некоррелированны.
Еще одним из возможных методов устранения или уменьшения мультиколлинеарности является использование пошаговой процедуры
отбора наиболее информативных переменных. На первом шаге рассматривается лишь одна объясняющая переменная, имеющая с зависимой переменной наибольший коэффициент детерминации. На втором шаге включается в регрессию новая объясняющая переменная, которая вместе с первой отобранной образует пару объясняющих переменных и т. д. Процедура введения новых переменных продолжается до тех пор, пока будет увеличиваться соответствующий коэффициент детерминации.
Кроме пошаговой процедуры присоединения переменных используется также процедура удаления переменных. Следует отметить, что какая бы процедура не использовалась, она не гарантирует определения оптимального в смысле получения максимального коэффициента детерминации набора объясняющих переменных. Однако в большинстве случаев получаемые с помощью пошаговых процедур отбора переменных модели оказываются оптимальными или близкими к оптимальным.
Анализируя сущность уравнения регрессии, следует отметить следующие положения. Рассмотренный подход не обеспечивает раздельной (независимой) оценки коэффициентов – изменение значения одного коэффициента влечет изменение значений других. Полученные коэффициенты не следует рассматривать как вклад соответствующего параметра в значение показателя. Уравнение регрессии является всего лишь хорошим аналитическим описанием имеющихся экспериментальных данных, а не законом, описывающим взаимосвязи параметров и показателя. Это уравнение применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т. е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Главной причиной неточности прогноза является не столько неопределенность экстраполяции линии регрессии, сколько значительная вариация показателя за счет неучтенных в модели факторов. Ограничением возможности прогнозирования служит условие стабильности неучтенных в модели параметров и характера влияния учтенных факторов модели. Если резко меняется внешняя среда, то составленное уравнение регрессии потеряет свой смысл. Нельзя подставлять в уравнение регрессии такие значения объясняющих переменных, которые значительно отличаются от представленных в выборке экспериментальных данных. Рекомендуется не выходить за пределы одной трети размаха вариации параметра как за максимальное, так и за минимальное значения фактора.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определять доверительный интервал прогноза.
При построении модели множественной регрессии следует соблюдать ряд рекомендаций:
– показатель должен находиться в причинной связи с параметрами;
– уравнение регрессии должно соответствовать логике связи показателя с параметрами;
– параметры не должны дублировать друг друга. Следует исключать дублирующие параметры, т. е. параметры с коэффициентом корреляции более 0,8;
– не следует включать параметры разных уровней иерархии.
5. Интерполяция и сглаживание экспериментальных данных
5.1. Задача интерполяции. Методы интерполяции
Пусть 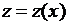 - обычная числовая функция, значения которой экспериментально установлены в точках
- обычная числовая функция, значения которой экспериментально установлены в точках ![]() :
: ![]() . Имеется, кроме того, точка
. Имеется, кроме того, точка ![]() . Требуется найти число
. Требуется найти число ![]() , предполагая данную функцию бесконечно дифференцируемой всюду, где она рассматривается. Решение этой задачи называется интерполяцией. Если указанное число будет найдено не точно, а приближенно, то необходимо указать явно допущенную ошибку.
, предполагая данную функцию бесконечно дифференцируемой всюду, где она рассматривается. Решение этой задачи называется интерполяцией. Если указанное число будет найдено не точно, а приближенно, то необходимо указать явно допущенную ошибку.
Существует несколько методик решения этой задачи. Одной из них является метод Лагранжа.
Введем функцию
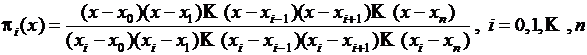 . (5.1)
. (5.1)
Ясно, что 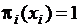 , а во всех остальных точках
, а во всех остальных точках ![]() . Поэтому многочлен п-ой степени
. Поэтому многочлен п-ой степени 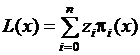 принимает в точках
принимает в точках ![]() те же значения, что и функция . Этот многочлен называется многочленом Лагранжа. Если вместо искомого числа
те же значения, что и функция . Этот многочлен называется многочленом Лагранжа. Если вместо искомого числа ![]() взять
взять ![]() , то ошибку можно указать совершенно точно:
, то ошибку можно указать совершенно точно:
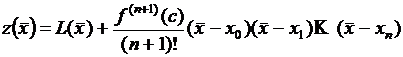 , (5.2)
, (5.2)
где с – некоторая точка из 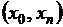 .
.
Предложенную Лагранжем методику нетрудно распространить на любое число переменных. Ограничимся далее лишь двумя переменными; случай трех и более переменных допускает точно такое же обобщение.
Пусть функция 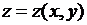 оказалась установленной в результате некоторого эксперимента в точках
оказалась установленной в результате некоторого эксперимента в точках 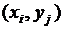 и имеются числа
и имеются числа ![]() ,
, 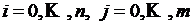 . Требуется установить значение данной функции в некоторой точке
. Требуется установить значение данной функции в некоторой точке ![]() ,
, 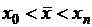 ,
, 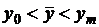 . Если это значение будет найдено приближенно, то указать погрешность. О функции предполагается, что она обладает непрерывными производными всех порядков.
. Если это значение будет найдено приближенно, то указать погрешность. О функции предполагается, что она обладает непрерывными производными всех порядков.
Введем функции
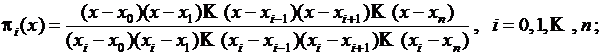
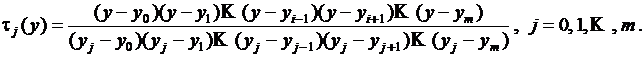
Ясно, что ![]() , а во всех остальных точках
, а во всех остальных точках ![]()
Поэтому многочлен от двух переменных
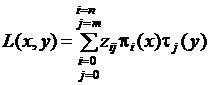 , (5.3)
, (5.3)
где ![]() , в каждой точке
, в каждой точке ![]() принимает то же самое значение, что и данная функция, т. е.
принимает то же самое значение, что и данная функция, т. е. 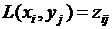 . Следуя идее Лагранжа, примем за значение функции
. Следуя идее Лагранжа, примем за значение функции ![]() в точке
в точке ![]() число
число ![]() .
.
Оценим погрешность такого допущения, т. е. выясним, насколько велика разница между 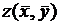 и
и 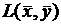 . Заметим, что
. Заметим, что 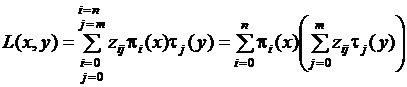 , тогда выражение
, тогда выражение 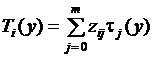 можно рассматривать как многочлен Лагранжа для системы точек
можно рассматривать как многочлен Лагранжа для системы точек 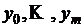 с соответствующими значениями в них функции
с соответствующими значениями в них функции ![]() . Поэтому
. Поэтому
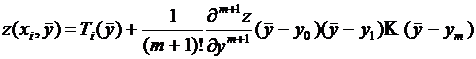 .
.
Частная производная 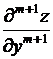 берется в некоторой точке интервала
берется в некоторой точке интервала ![]() .
.
Выражение 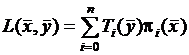 можно воспринимать как значение при
можно воспринимать как значение при ![]() многочлена Лагранжа
многочлена Лагранжа 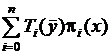 . Поэтому
. Поэтому
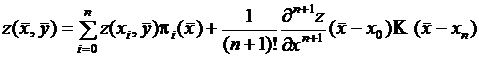 , (5.4)
, (5.4)
где частная производная ![]() вычислена в некоторой точке. Учитывая вышесказанное, получаем:
вычислена в некоторой точке. Учитывая вышесказанное, получаем:
 (5.5)
(5.5)
Заметим, что в каждом слагаемом здесь частная производная считается в своей, новой, точке. Поэтому, если считать, что частная производная ![]() ограничена по модулю константой
ограничена по модулю константой ![]() , а частная производная ограничена по модулю константой
, а частная производная ограничена по модулю константой ![]() , то нетрудно получить оценку:
, то нетрудно получить оценку:
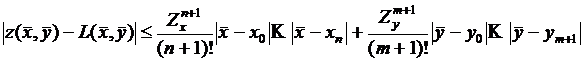 . (5.6)
. (5.6)
Рассмотрим метод интерполяции по Бернштейну (случаи размерностей 1 и 2). Предположим, что некоторая функция одной переменной ![]() задана в точках
задана в точках ![]() для
для ![]() при некотором фиксированном числе n. Это значит, что отрезок [0, 1] разбит на n равных частей и функция
при некотором фиксированном числе n. Это значит, что отрезок [0, 1] разбит на n равных частей и функция ![]() задана в точках деления. Положим
задана в точках деления. Положим
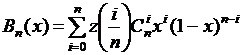 , (5.7)
, (5.7)
где ![]() - биномиальный коэффициент (число сочетаний из п по i). Многочлен
- биномиальный коэффициент (число сочетаний из п по i). Многочлен ![]() называется многочленом Бернштейна функции степени п.
называется многочленом Бернштейна функции степени п.
Можно доказать, что при 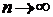 функция
функция 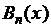 стремится к функции
стремится к функции ![]() равномерно по x в отрезке [0, 1]. Аналогичное утверждение верно в отношении любой производной функции
равномерно по x в отрезке [0, 1]. Аналогичное утверждение верно в отношении любой производной функции ![]() : при
: при ![]()
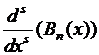 стремится к
стремится к 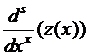 при произвольном s (если только у функции
при произвольном s (если только у функции ![]() есть непрерывные производные всех порядков).
есть непрерывные производные всех порядков).
На отрезке [0, 1] имеет место следующее неравенство:
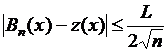 , (5.8)
, (5.8)
где L – число, ограничивающее первую производную функции ![]() на отрезке [0, 1] (например, максимум этой производной при условии, что производная непрерывна).
на отрезке [0, 1] (например, максимум этой производной при условии, что производная непрерывна).
Следовательно, возникает возможность заменять значения функции значениями ее многочлена Бернштейна, указывая при этом ошибку замены.
Данная конструкция применима, когда исходная функция z(x) задана в точках деления на равные части единичного отрезка. Кроме того, приближение функции с заданной точностью производится в любой точке отрезка, т. е. равномерно.
Нетрудно перенести конструкцию с единичного отрезка на отрезок произвольный, который также делится на равные части и в точках деления задается исследуемая функция. Пусть z(x) задана на отрезке [a, b] в точках ![]() ; положим
; положим 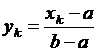 ; тогда последнее выражение будет меняться по точкам деления на n равных частей единичного отрезка; пусть
; тогда последнее выражение будет меняться по точкам деления на n равных частей единичного отрезка; пусть 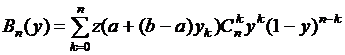 . Заменив в последнем выражении y на его выражение через x, получим многочлен Бернштейна на произвольном отрезке:
. Заменив в последнем выражении y на его выражение через x, получим многочлен Бернштейна на произвольном отрезке:
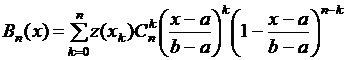 . (5.9)
. (5.9)
Рассмотрим случай двух переменных. Пусть функция z = z(x, y) задана в точках ![]() единичного квадрата (n, m - фиксированы,
единичного квадрата (n, m - фиксированы, ![]() ):
): ![]() . Построим двумерный многочлен Бернштейна:
. Построим двумерный многочлен Бернштейна:
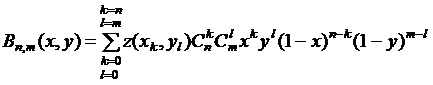 . (5.10)
. (5.10)
Для любых u, v при наличии у функции z непрерывных производных соответствующих порядков многочлены при ![]() стремятся равномерно относительно x, y к функции
стремятся равномерно относительно x, y к функции 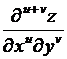 .
.
Поэтому при заданной точности возможна замена функции в точке на значение многочлена Бернштейна в точке в произвольном месте единичного квадрата. Если числа L, M ограничивают первые частные производные функции z, то для всех точек единичного квадрата справедливо неравенство:
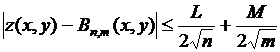 . (5.11)
. (5.11)
Так же, как и в случае одной переменной, проведенные построения обобщаются на случай не единичного квадрата, а любого прямоугольника со сторонами, параллельными осям координат.
На практике функция двух переменных редко задается таблицей, точки которой расположены так, как этого требует конструкция Бернштейна; поэтому таблицу формируют по заданному условию приближенно, заменяя функцию в узлах соответствующей решетки на числа, которые строятся тем или иным способом.
5.2. Сглаживание экспериментальных данных
сплайн-функциями
Пусть 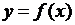 - функция на некотором отрезке [a, b]. Фиксируем произвольное разбиение D этого отрезка на N частей
- функция на некотором отрезке [a, b]. Фиксируем произвольное разбиение D этого отрезка на N частей ![]() .
.
Сплайном порядка m относительно разбиения D называется функция ![]() со следующими свойствами:
со следующими свойствами:
– на каждом из отрезков ![]() эта функция является многочленом степени m:
эта функция является многочленом степени m: 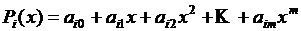 , i = 1, 2, … , N ;
, i = 1, 2, … , N ;
– в точках ![]() выполняются равенства
выполняются равенства 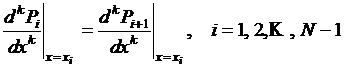 , при
, при ![]() .
.
Таким образом, сплайн - это функция на отрезке, связанная с разбиением этого отрезка. Если m = 1, то сплайн называется линейным. Его график - ломаная линия. Поскольку многочлен степени m задается m + 1 своими коэффициентами, в определении сплайна подразумевается
(N – 1) m условия, накладываемые на N (m + 1) коэффициентов. Следовательно, с данным разбиением связан не один сплайн порядка m, а множество сплайнов порядка m. Все сплайны этого множества могут быть
описаны как решение системы линейных алгебраических уравнений, в
котором N + m коэффициентов из общего числа N (m + 1) свободны, а остальные через них линейно выражаются.
Когда из этого множества требуется отобрать сплайн, близкий в том или ином смысле к функции 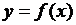 , говорят о сплайне функции
, говорят о сплайне функции ![]() . Например, необходимо найти линейный сплайн, который совпадает с данной функцией во всех точках деления данного отрезка:
. Например, необходимо найти линейный сплайн, который совпадает с данной функцией во всех точках деления данного отрезка: ![]() . В этом случае на 2N коэффициентов возникает ровно 2N условий.
. В этом случае на 2N коэффициентов возникает ровно 2N условий.
Опишем основные процедуры, необходимые для построения сплайна в общем случае.
Исходная информация: разбиение ![]() и число m – порядок сплайна. Требуется получить N многочленов , отыскав все их коэффициенты через уравнения
и число m – порядок сплайна. Требуется получить N многочленов , отыскав все их коэффициенты через уравнения 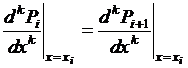 .
.
Всего в уравнениях участвует N (m + 1) коэффициентов aij в качестве неизвестных. Необходимо решить систему линейных алгебраических уравнений MZ = B, где Z - столбец неизвестных; B - столбец свободных членов; M - матрица системы. Решаем систему уравнений методом жордановых исключений.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
