
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Совместная плотность вероятности
L(x1, x2, … , xn; T) = f (х1, T) f (х2, T) … f (хп, T), (2.21)
рассматриваемая как функция параметра T, называется функцией правдоподобия.
В качестве оценки q параметра T следует взять то значение, которое обращает функцию правдоподобия в максимум. Для нахождения оценки необходимо заменить в функции правдоподобия Т на f (х1, T),
f (х2, T), … , f (хп, T) и решить уравнение ¶L / ¶q = 0.
Для упрощения вычислений переходят от функции правдоподобия к ее логарифму ln L. Такое преобразование допустимо, т. к. функция правдоподобия – положительная функция, и она достигает максимума в той же точке, что и ее логарифм. Если параметр распределения векторная величина
q = (q1, q2, … , qп),
то оценки максимального правдоподобия находят из системы уравнений
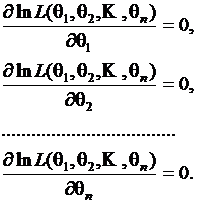 (2.22)
(2.22)
Для проверки того, что точка оптимума соответствует максимуму функции правдоподобия, необходимо найти вторую производную от этой функции. И если вторая производная в точке оптимума отрицательна, то найденные значения параметров максимизируют функцию.
Нахождение оценок максимального правдоподобия включает следующие этапы: построение функции правдоподобия (ее натурального
логарифма); дифференцирование функции по искомым параметрам и составление системы уравнений; решение системы уравнений для нахождения оценок; определение второй производной функции, проверку ее знака в точке оптимума первой производной и формирование выводов.
Метод максимального правдоподобия позволяет получить состоятельные, эффективные, достаточные, асимптотически нормально распределенные оценки. Метод особенно полезен при малых выборках. Если функция максимального правдоподобия имеет несколько максимумов, то из них выбирают глобальный.
2.7.2. Метод моментов
Метод предложен К. Пирсоном в 1894 г. Сущность метода:
– выбирается столько эмпирических моментов, сколько требуется оценить неизвестных параметров распределения. Желательно применять моменты младших порядков, т. к. погрешности вычисления оценок резко возрастают с увеличением порядка момента;
– вычисленные по экспериментальным данным оценки моментов приравниваются к теоретическим моментам;
– параметры распределения определяются через моменты, и составляются уравнения, выражающие зависимость параметров от моментов, в результате получается система уравнений. Решение этой системы дает оценки параметров распределения генеральной совокупности.
Метод моментов позволяет получить состоятельные, достаточные оценки, они при довольно общих условиях распределены асимптотически нормально. Смещение удается устранить введением поправок. Эффективность оценок невысокая, т. е. даже при больших объемах выборок дисперсия оценок относительно велика (за исключением нормального распределения, для которого метод моментов дает эффективные оценки). В реализации метод моментов проще метода максимального правдоподобия.
Метод целесообразно применять для оценки не более чем четырех параметров, т. к. точность выборочных моментов резко падает с увеличением их порядка.
2.7.3. Метод квантилей
Сущность метода квантилей схожа с сущностью метода моментов: выбирается столько квантилей, сколько требуется оценить параметров; неизвестные теоретические квантили, выраженные через параметры распределения, приравниваются к эмпирическим квантилям. Решение полученной системы уравнений дает искомые оценки параметров.
Дисперсия D(xa) выборочной квантили обратно пропорциональна квадрату плотности распределения
D(xa) = [a(1 – a)] / [nf 2(xa)] (2.23)
в окрестностях точки xa. Поэтому следует выбирать квантили вблизи тех значений х, в которых плотность вероятности максимальна.
Метод квантилей позволяет получить асимптотически нормальные оценки, однако они несут в себе некоторый субъективизм, связанный с относительно произвольным выбором квантилей. Эффективность оценок не выше метода моментов. Определение оценок может приводить к необходимости численного решения достаточно сложных систем уравнений.
2.8. Интервальная оценка параметров распределения
Интервальный метод оценивания параметров распределения случайных величин заключается в определении интервала (а не единичного значения), в котором с заданной степенью достоверности будет заключено значение оцениваемого параметра. Интервальная оценка характеризуется двумя числами – концами интервала, внутри которого предположительно находится истинное значение параметра. Иначе говоря, вместо отдельной точки для оцениваемого параметра можно установить интервал значений, одна из точек которого является своего рода «лучшей» оценкой. Интервальные оценки являются более полными и надежными по сравнению с точечными, они применяются как для больших, так и для малых выборок. Совокупность методов определения промежутка, в котором лежит значение параметра Т, получила название методов интервального оценивания. К их числу принадлежит метод Неймана.
Постановка задачи интервальной оценки параметров заключается в следующем.
Имеется выборка наблюдений (x1, x2, … , xn) за случайной величиной Х. Объем выборки n фиксирован.
Необходимо с доверительной вероятностью g = 1 – a определить интервал от t0 до t1 (t0 < t1), который накрывает истинное значение неизвестного скалярного параметра Т.
Эта задача решается путем построения доверительного утверждения, которое состоит в том, что интервал от t0 до t1 накрывает истинное значение параметра Т с доверительной вероятностью не менее g. Величины t0 и t1 называются нижней и верхней доверительными границами. Доверительные границы интервала выбирают так, чтобы выполнялось условие P (t0 £ q < t1) = g.
В инженерных задачах доверительную вероятность g назначают в пределах от 0,95 до 0,99. В доверительном утверждении считается, что статистики t0 и t1 являются случайными величинами и изменяются от выборки к выборке. Это означает, что доверительные границы определяются неоднозначно, существует бесконечное количество вариантов их
установления.
На практике применяют два варианта задания доверительных границ:
– устанавливают симметрично относительно оценки параметра, т. е. 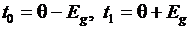 , где Еg выбирают так, чтобы выполнялось доверительное утверждение. Следовательно, величина абсолютной погрешности оценивания Еg равна половине доверительного интервала;
, где Еg выбирают так, чтобы выполнялось доверительное утверждение. Следовательно, величина абсолютной погрешности оценивания Еg равна половине доверительного интервала;
– устанавливают из условия равенства вероятностей выхода за верхнюю и нижнюю границу 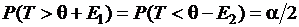 .
.
В общем случае величина Е1 не равна Е2. Для симметричных распределений случайного параметра q в целях минимизации величины интервала значения Е1 и Е2 выбирают одинаковыми, следовательно, в таких случаях оба варианта эквивалентны.
Нахождение доверительных интервалов требует знания вида и параметров закона распределения случайной величины q. Для ряда практически важных случаев этот закон можно определить из теоретических соображений.
Общий метод построения доверительных интервалов позволяет по имеющейся случайной выборке построить функцию и (Т, q), распределенную асимптотически нормально с нулевым математическим ожиданием и единичной дисперсией. В основе метода лежат следующие положения. Пусть:
– f (х, q) – плотность распределения случайной величины Х;
– ln [L(x, q)] – логарифм функции правдоподобия;
– 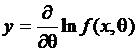 ;
;
– дисперсия y.
Если математическое ожидание М(у) = 0 и дисперсия у конечна, то распределение случайной величины 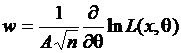 асимптотически нормально с параметрами 0 и 1 при неограниченном увеличении n.
асимптотически нормально с параметрами 0 и 1 при неограниченном увеличении n.
Рассмотрим случай, когда среднее значение ![]() выборки объема N значений случайной величины x(k) используется в качестве оценки истинного значения mx. Практически полезнее находить для истинного среднего значения mx такой интервал
выборки объема N значений случайной величины x(k) используется в качестве оценки истинного значения mx. Практически полезнее находить для истинного среднего значения mx такой интервал ![]() , в который с некоторой
, в который с некоторой
степенью достоверности будет заключено истинное значение mx. Этот интервал можно найти, если известно выборочное распределение используемой в качестве оценки выборочной величины. Для нормально распределенной случайной величины с неизвестным средним значением и дисперсией эту вероятность находят следующим образом:
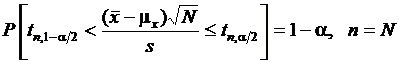 . (2.24)
. (2.24)
После извлечения выборки значения ![]() и s принимают определенные числовые значения, а значит, не являются случайными. Поэтому данное выражение для вероятности уже не приемлемо, так как величина
и s принимают определенные числовые значения, а значит, не являются случайными. Поэтому данное выражение для вероятности уже не приемлемо, так как величина 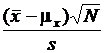 либо попадает, либо не попадает в казанные пределы, т. е. после того, как выборка извлечена, теоретически верное выражение для вероятности имеет вид
либо попадает, либо не попадает в казанные пределы, т. е. после того, как выборка извлечена, теоретически верное выражение для вероятности имеет вид 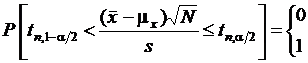 . Будет ли точное значение вероятности равно 0 или 1 обычно не известно. Однако если повторно извлекается большое число выборок и по каждой из выборок вычисляются
. Будет ли точное значение вероятности равно 0 или 1 обычно не известно. Однако если повторно извлекается большое число выборок и по каждой из выборок вычисляются ![]() и s, то следует ожидать, что доля случаев, для которых отношение будет попадать в интервал от tn;1–a/2 до tn;a/2 составит 1 - a.
и s, то следует ожидать, что доля случаев, для которых отношение будет попадать в интервал от tn;1–a/2 до tn;a/2 составит 1 - a.
В таких случаях можно указать интервал, в который, как можно ожидать, отношение попадет с большой степенью достоверности. Такой интервал называют доверительным интервалом.
При оценке среднего значения доверительный интервал можно получить по известным выборочным величинам ![]() и s.
и s.
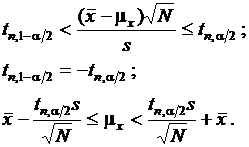 (2.25)
(2.25)
Доверительная вероятность, соответствующая данному интервалу, составляет 1 - a.
Аналогичные выводы можно сделать для оценок любых параметров.
Например, из формулы 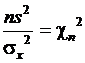 можно получить доверительный интервал при оценке дисперсии
можно получить доверительный интервал при оценке дисперсии
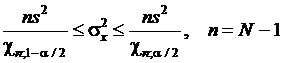 .
.
Пример 2.4.
Пусть имеется нормально распределенная случайная величина x(k). Произведено N = 31 независимых наблюдений этой величины x:
60 | 61 | 47 | 56 | 61 | 65 | 69 | 54 | 59 | 43 |
63 | 61 | 55 | 61 | 56 | 48 | 67 | 65 | 60 | 58 |
57 | 62 | 57 | 58 | 53 | 59 | 58 | 61 | 67 | 62 |
54 |
Найдем 90 %-е доверительные интервалы для среднего значения и дисперсии случайной величины х. Определим доверительный интервал с уровнем доверия 1 - a для среднего значения mx по выборочному среднему ![]() и дисперсии s2 при размере выборки N = 31:
и дисперсии s2 при размере выборки N = 31:
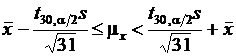 .
.
По статистическим таблицам для a = 0,1 находим t30;0.05 = 43,77, значит интервал имеет вид 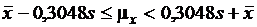 .
.
Доверительный интервал дисперсии ![]() с уровнем доверия 1 - a строится по выборочной дисперсии s2 при размере выборки N = 31:
с уровнем доверия 1 - a строится по выборочной дисперсии s2 при размере выборки N = 31:
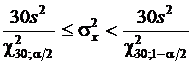 .
.
По статистическим таблицам для a = 0,1 находим ![]() и
и ![]() , поэтому интервал имеет вид
, поэтому интервал имеет вид ![]() .
.
Вычислим выборочное среднее и выборочную дисперсию и подставим полученные значения в формулы доверительных интервалов. Выборочное среднее вычислим по формуле:
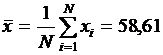 .
.
Выборочную дисперсию находим по формуле:
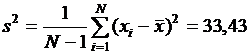 .
.
Доверительные интервалы с уровнем доверия 90 % для среднего значения и дисперсии случайной величины таковы:
![]()
![]() .
.
2.9. Проверка статистических гипотез
2.9.1. Сущность задачи проверки статистических гипотез
Статистическая гипотеза представляет собой некоторое предположение о законе распределения случайной величины или о параметрах этого закона, формулируемое на основе выборки.
Различают простые и сложные гипотезы. Гипотезу называют простой, если она однозначно характеризует параметр распределения случайной величины. Например, если l является параметром экспоненциального распределения, то гипотеза Н0 о равенстве l = 10 – простая гипотеза. Сложной называют гипотезу, которая состоит из конечного или бесконечного множества простых гипотез. Сложная гипотеза Н0 о неравенстве l > 10 состоит из бесконечного множества простых гипотез Н0 о равенстве l = bi, где bi – любое число, большее 10. Гипотеза Н0 о том, что математическое ожидание нормального распределения равно двум при неизвестной дисперсии, тоже является сложной. Сложной гипотезой будет предположение о распределении случайной величины Х по нормальному закону, если не фиксируются конкретные значения математического ожидания и дисперсии.
Проверка гипотезы основывается на вычислении некоторой случайной величины – критерия, точное или приближенное распределение которого известно. Обозначим эту величину через z, ее значение является функцией от элементов выборки z = z(x1, x2, … , xn). Процедура проверки гипотезы предписывает каждому значению критерия одно из двух решений – принять или отвергнуть гипотезу. Тем самым все выборочное пространство и соответственно множество значений критерия делятся на два непересекающихся подмножества S0 и S1. Если значение критерия z попадает в область S0, то гипотеза принимается, а если в область S1, то гипотеза отклоняется. Множество S0 называется областью принятия гипотезы или областью допустимых значений, а множество S1 – областью отклонения гипотезы или критической областью. Выбор одной области однозначно определяет и другую область.
Принятие или отклонение гипотезы Н0 по случайной выборке соответствует истине с некоторой вероятностью и, соответственно, возможны два рода ошибок. Ошибка первого рода возникает с вероятностью a тогда, когда отвергается верная гипотеза Н0 и принимается конкурирующая гипотеза Н1. Ошибка второго рода возникает с вероятностью b в том случае, когда принимается неверная гипотеза Н0, в то время как справедлива конкурирующая гипотеза Н1. Доверительная вероятность – это вероятность не совершить ошибку первого рода и принять верную гипотезу Н0. Вероятность отвергнуть ложную гипотезу Н0 называется мощностью критерия.
Рассмотрим случай, когда некоторая несмещенная оценка параметра ![]() вычислена по выборке объема N независимых наблюдений случайной величины x(k). Предположим, есть основания считать, что истинное значение параметра F равно F0. Даже если F = F0, то выборочное значение
вычислена по выборке объема N независимых наблюдений случайной величины x(k). Предположим, есть основания считать, что истинное значение параметра F равно F0. Даже если F = F0, то выборочное значение ![]() не будет точно совпадать с F0 из-за выборочной изменчивости статистики
не будет точно совпадать с F0 из-за выборочной изменчивости статистики ![]() .
.
Тогда возникает вопрос: если принять гипотезу, что F = F0, то на сколько велико должно быть различие между ![]() и F0, чтобы отвергнуть гипотезу как ошибочную. Рассмотрим вероятность достижения некоторой заданной разности между
и F0, чтобы отвергнуть гипотезу как ошибочную. Рассмотрим вероятность достижения некоторой заданной разности между ![]() и F0 на основе выборочного распределения параметра
и F0 на основе выборочного распределения параметра ![]() . Если вероятность превышения отклонения
. Если вероятность превышения отклонения ![]() от F0 заданного уровня мала, этот уровень следует считать значимым и гипотезу F = F0 следует отвергнуть. Если вероятность превышения заданной разности не является малой, то наличие этой разности можно отнести за счет обычной статистической изменчивости и гипотезу F = F0 можно считать правдоподобной.
от F0 заданного уровня мала, этот уровень следует считать значимым и гипотезу F = F0 следует отвергнуть. Если вероятность превышения заданной разности не является малой, то наличие этой разности можно отнести за счет обычной статистической изменчивости и гипотезу F = F0 можно считать правдоподобной.
Пусть выборочная величина ![]() , представляющая собой несмещенную оценку параметра, имеет плотность распределения
, представляющая собой несмещенную оценку параметра, имеет плотность распределения ![]() . Если гипотеза, состоящая в том, что F = F0 верна, то функция
. Если гипотеза, состоящая в том, что F = F0 верна, то функция ![]() должна обладать средним значением F0. Вероятность того, что параметр
должна обладать средним значением F0. Вероятность того, что параметр ![]() не будет превышать нижнего уровня
не будет превышать нижнего уровня ![]() , составит
, составит 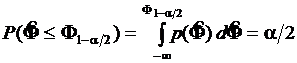 . Вероятность того, что параметр
. Вероятность того, что параметр ![]() превысит уровень
превысит уровень ![]() , составит
, составит 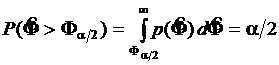 . Вероятность того, что параметр
. Вероятность того, что параметр ![]() выйдет за пределы интервала с границами
выйдет за пределы интервала с границами 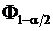 и
и ![]() составляет a. Примем величину a настолько малой, чтобы попадание параметра
составляет a. Примем величину a настолько малой, чтобы попадание параметра ![]() за пределы интервала (
за пределы интервала (![]() ,
, ![]() ) было маловероятным. Если после извлечения выборки и определения
) было маловероятным. Если после извлечения выборки и определения ![]() окажется, что она выходит за пределы интервала (
окажется, что она выходит за пределы интервала (![]() ,
, ![]() ), т. е. основания подвергнуть сомнения справедливость проверяемой гипотезы F = F0. Если гипотеза верна, то значение
), т. е. основания подвергнуть сомнения справедливость проверяемой гипотезы F = F0. Если гипотеза верна, то значение ![]() будет маловероятным. Следовательно, гипотезу равенства величин F и F0 следует отвергнуть. Отсюда следует, что вероятность допустить ошибку первого рода равна a (равна уровню значимости критерия).
будет маловероятным. Следовательно, гипотезу равенства величин F и F0 следует отвергнуть. Отсюда следует, что вероятность допустить ошибку первого рода равна a (равна уровню значимости критерия).
Если параметр ![]() попадает в интервал (
попадает в интервал (![]() ,
, ![]() ), то в этом случае нет оснований подвергать сомнению справедливость гипотезы и гипотезу F = F0 можно принять.
), то в этом случае нет оснований подвергать сомнению справедливость гипотезы и гипотезу F = F0 можно принять.
Малое значение вероятности a, используемое для проверки гипотезы, называется уровнем значимости критерия. Интервал значений ![]() , при котором гипотезу можно принять, носит название области принятия гипотезы. Целесообразно полагать одинаковыми значения вероятности выхода параметра
, при котором гипотезу можно принять, носит название области принятия гипотезы. Целесообразно полагать одинаковыми значения вероятности выхода параметра ![]() за нижний и верхний пределы интервала. Такое допущение во многих случаях позволяет минимизировать доверительный интервал, т. е. повысить мощность критерия проверки. Суммарная вероятность
за нижний и верхний пределы интервала. Такое допущение во многих случаях позволяет минимизировать доверительный интервал, т. е. повысить мощность критерия проверки. Суммарная вероятность
выхода параметра ![]() за пределы интервала с границами
за пределы интервала с границами 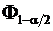 и
и ![]() составляет величину a.
составляет величину a.
Если предположить, например, что истинное значение параметра в действительности равно F + d, то согласно гипотезе Н0 о равенстве F = F0 – вероятность того, что оценка параметра F попадет в область принятия гипотезы, составит b.
При заданном объеме выборки вероятность совершения ошибки первого рода можно уменьшить, снижая уровень значимости a. Однако при этом увеличивается вероятность ошибки второго рода b (снижается мощность критерия). Аналогичные рассуждения можно провести для случая, когда истинное значение параметра равно F - d.
Единственный способ уменьшить обе вероятности состоит в увеличении объема выборки (плотность распределения оценки параметра при этом становится более «узкой»). При выборе критической области руководствуются правилом Неймана – Пирсона: следует так выбирать критическую область, чтобы вероятность a была мала, если гипотеза верна, и велика в противном случае. Однако выбор конкретного значения a относительно произволен. Употребительные значения лежат в пределах от 0,001 до 0,2.
При выборе уровня значимости необходимо учитывать мощность критерия при альтернативной гипотезе. Иногда большая мощность критерия оказывается существеннее малого уровня значимости, и его значение выбирают относительно большим, например 0,2. Такой выбор оправдан, если последствия ошибок второго рода более существенны, чем ошибок первого рода. Например, если отвергнуто правильное решение «продолжить работу пользователей с текущими паролями», то ошибка первого рода приведет к некоторой задержке в нормальном функционировании системы, связанной со сменой паролей. Если же принято решение не менять пароли, несмотря на опасность несанкционированного доступа посторонних лиц к информации, то эта ошибка повлечет более серьезные последствия.
Пример 2.5.
Пусть есть основания считать ![]() случайной величины x(k) равной 10. Известна дисперсия величины x(k):
случайной величины x(k) равной 10. Известна дисперсия величины x(k): ![]() . Каков должен быть объем выборки для проверки гипотезы
. Каков должен быть объем выборки для проверки гипотезы 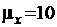 при 5 % уровне значимости, причем вероятность допустить ошибку второго рода при определении 10 % отклонения от гипотезы величина должна составить 2,5 %.
при 5 % уровне значимости, причем вероятность допустить ошибку второго рода при определении 10 % отклонения от гипотезы величина должна составить 2,5 %.
Несмещенная оценка 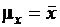 . Соответствующее выборочное распределение параметра
. Соответствующее выборочное распределение параметра ![]() можно получить из формулы
можно получить из формулы 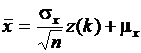 , где z(k) - нормально распределенная случайная величина с
, где z(k) - нормально распределенная случайная величина с ![]() и
и ![]() . Верхняя и нижняя границы области принятия гипотезы имеют вид:
. Верхняя и нижняя границы области принятия гипотезы имеют вид:
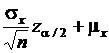 - верхняя граница;
- верхняя граница;
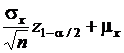 - нижняя граница.
- нижняя граница.
Если в действительности истинное значение ![]() , то ошибка второго рода допускается с вероятностью b, когда выборочное значение
, то ошибка второго рода допускается с вероятностью b, когда выборочное значение ![]() лежит ниже верхней или выше нижней границы:
лежит ниже верхней или выше нижней границы:
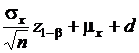 - верхняя граница;
- верхняя граница;
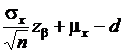 - нижняя граница.
- нижняя граница.
Следовательно,
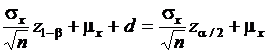 ,
,
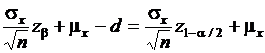 .
.
В данном примере 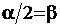 , значит
, значит
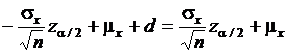 ,
,
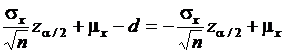 .
.
Вычитая из второго уравнения первое, получим:
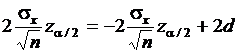 ,
,
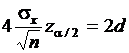 ,
,
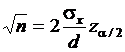 ,
,
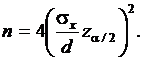
Подставляя 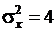 ,
, 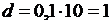 и
и 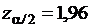 , получим n = 62.
, получим n = 62.
Область принятия гипотезы: 10,5 – верхняя граница; 9,5 – нижняя граница.
Теперь следует извлечь выборку объема n = 62 и вычислить ![]() . Если
. Если ![]() , то гипотезу
, то гипотезу ![]() можно принять, учитывая возможность 2,5 % риска. Если же
можно принять, учитывая возможность 2,5 % риска. Если же ![]() будет вне интервала, то гипотезу
будет вне интервала, то гипотезу ![]() следует отвергнуть, учитывая возможность 5 % риска.
следует отвергнуть, учитывая возможность 5 % риска.
В зависимости от сущности проверяемой гипотезы и используемых мер расхождения оценки характеристики от ее теоретического значения применяют различные критерии. К числу наиболее часто применяемых критериев для проверки гипотез о законах распределения относят критерии c2 Пирсона, Колмогорова, Мизеса, Вилкоксона, о значениях параметров – критерии Фишера, Стьюдента.
2.9.2. Проверка гипотез о законе распределения
Пусть имеется выборка экспериментальных данных фиксированного объема, выбран или известен вид закона распределения генеральной совокупности. Необходимо оценить по этой выборке параметры закона, определить степень согласованности экспериментальных данных и выбранного закона распределения, в котором параметры заменены их оценками. Рассмотрим вопрос проверки согласованности распределений с использованием наиболее употребительных критериев.
Критерий c2 К. Пирсона
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F(x) и эмпирическим распределением Fn (x), которая приближенно подчиняется закону распределения c2. Гипотеза Н0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Пусть выборка представлена статистическим рядом с количеством разрядов y. Наблюдаемая частота попаданий в i-й разряд ni. В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i-й разряд составляет Fi. Разность между наблюдаемой и ожидаемой частотой составит величину (ni – Fi). Для нахождения общей степени расхождения между F(x) и Fn (x) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда 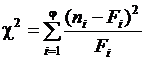 .
.
Величина c2 при неограниченном увеличении n имеет распределение c2. Это распределение зависит от числа степеней свободы k. Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся y – 1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются f параметров распределения, то число степеней свободы составит k = y – f – 1.
Очевидно, что чем меньше расхождение между теоретическими и эмпирическими частотами, тем меньше величина критерия. Область принятия гипотезы Н0 определяется условием c2 < c2 (k; a), где c2 (k; a) – критическая точка распределения c2 с уровнем значимости a. Вероятность ошибки первого рода равна a, вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n > 200, допускается применение при n > 40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Критерий

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
