
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для применения критерия А. Н. Колмогорова экспериментальные данные требуется представить в виде вариационного ряда (данные недопустимо объединять в разряды). В качестве меры расхождения между теоретической F(x) и эмпирической Fn(x) функциями распределения непрерывной случайной величины Х используется модуль максимальной разности ![]() .
.
А. Н. Колмогоров доказал, что какова бы ни была функция распределения F(x) величины Х при неограниченном увеличении количества наблюдений n функция распределения случайной величины 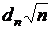 асимптотически приближается к функции распределения
асимптотически приближается к функции распределения
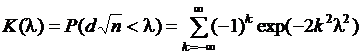 . (2.26)
. (2.26)
Иначе говоря, критерий А. Н. Колмогорова характеризует вероятность того, что величина не будет превосходить параметр l для любой теоретической функции распределения. Уровень значимости a выбирается из условия ![]() , в силу предположения, что почти невозможно получить это равенство, когда существует
, в силу предположения, что почти невозможно получить это равенство, когда существует
соответствие между функциями F(x) и Fn (x).
Н. Колмогорова позволяет проверить согласованность распределений по малым выборкам, он проще критерия c2, поэтому его часто применяют на практике. Но требуется учитывать два обстоятельства.
1. В соответствии с условиями его применения необходимо пользоваться следующим соотношением 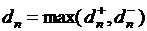 , где
, где
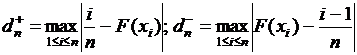 .
.
2. Условия применения критерия предусматривают, что теоретическая функция распределения известна полностью – известны вид функции и значения ее параметров. На практике параметры обычно неизвестны и оцениваются по экспериментальным данным. Но критерий не учитывает уменьшение числа степеней свободы при оценке параметров распределения по исходной выборке. Это приводит к завышению значения вероятности соблюдения нулевой гипотезы, т. е. повышается риск принять в качестве правдоподобной гипотезу, которая плохо согласуется с экспериментальными данными (повышается вероятность совершить ошибку второго рода). В качестве меры противодействия такому выводу следует увеличить уровень значимости a, приняв его равным 0,1 – 0,2, что приведет к уменьшению зоны допустимых отклонений.
Мизеса
В качестве меры различия теоретической функции распределения F(x) и эмпирической Fn (x) по критерию Мизеса (критерию w2) выступает средний квадрат отклонений по всем значениям аргумента x:
 . (2.27)
. (2.27)
Статистика критерия
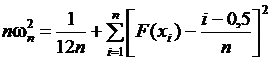 . (2.28)
. (2.28)
При неограниченном увеличении n существует предельное распределение статистики n. Задав значение вероятности a, можно определить критические значения n (a). Проверка гипотезы о законе распределения осуществляется обычным образом: если фактическое значение n окажется больше критического или равно ему, то согласно критерию Мизеса с уровнем значимости a гипотеза Н0 о том, что закон распределения генеральной совокупности соответствует F(x), должна быть отвергнута.
Достоинством критерия Мизеса является быстрая сходимость к предельному закону.
Сопоставляя возможности различных критериев, необходимо отметить следующие особенности. Критерий Пирсона устойчив к отдельным случайным ошибкам в экспериментальных данных. Однако его применение требует группирования данных по интервалам, выбор которых относительно произволен и подвержен противоречивым рекомендациям. Критерий Колмогорова слабо чувствителен к виду закона распределения и подвержен влиянию помех в исходной выборке, но прост в применении. Критерий Мизеса имеет ряд общих свойств с критерием Колмогорова: оба основаны непосредственно на результатах наблюдения и не требуют построения статистического ряда, что повышает объективность выводов; оба не учитывают уменьшение числа степеней свободы при определении параметров распределения по выборке, а это ведет к риску принятия ошибочной гипотезы. Их предпочтительно применять в тех случаях, когда параметры закона распределения известны априори, например, при проверке датчиков случайных чисел.
При проверке гипотез о законе распределения следует помнить, что слишком хорошее совпадение с выбранным законом распределения может быть обусловлено некачественным экспериментом или предвзятой предварительной обработкой результатов (некоторые результаты отбрасываются или округляются).
Выбор критерия проверки гипотезы относительно произволен. Разные критерии могут давать различные выводы о справедливости гипотезы, окончательное заключение в таком случае принимается на основе неформальных соображений. Точно также нет однозначных рекомендаций по выбору уровня значимости.
Рассмотренный подход к проверке гипотез, основанный на применении специальных таблиц критических точек распределения, сложился в эпоху «ручной» обработки экспериментальных данных, когда наличие таких таблиц существенно снижало трудоемкость вычислений. В настоящее время математические пакеты включают процедуры вычисления стандартных функций распределений, что позволяет отказаться от использования таблиц, но может потребовать изменения правил проверки.
2.9.3. Критерий инверсий
Рассмотрим последовательность N наблюдений случайной величины x(k). Подсчитаем, сколько раз в последовательности имеют место неравенства xi > xj при i < j. Каждое такое неравенство называют инверсией. Общее число инверсии обозначим А. Для множества наблюдений
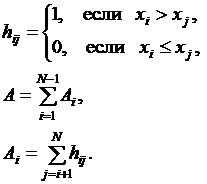 (2.29)
(2.29)
Если последовательность из N наблюдений состоит из N независимых исходов одной и той же случайной величины, то число инверсий является случайной величиной А со средним ![]() и дисперсией
и дисперсией 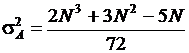 . Статистическая таблица процентных точек распределения числа инверсий содержит 100a-процентные точки распределения. Критерий инверсий применяется для обнаружения монотонного тренда.
. Статистическая таблица процентных точек распределения числа инверсий содержит 100a-процентные точки распределения. Критерий инверсий применяется для обнаружения монотонного тренда.
Пример 2.6.
Пусть имеется случайная величина x(k). Произведено N = 8 независимых наблюдений этой величины (x: . Проверим наличие тренда в последовательности при уровне значимости a = 5 %
Для данной выборки А1 = 3, А2 = 1, А3 = 4, А4 = 4, А5 = 1, А6 = 0, А7 = 1.
А = 3 + 1 + 4 + 4 + 1 + 0 + 1 = 14.
Пусть гипотеза заключается в том, что наблюдения представляют собой независимые исходы случайной величины x, т. е. тренда нет.
Область принятия гипотезы 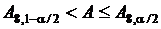 . По таблице находим А8;0,975 = 11, А8;0,025 = 33. Подставляем найденные значения в неравенство
. По таблице находим А8;0,975 = 11, А8;0,025 = 33. Подставляем найденные значения в неравенство ![]() . Так как А = 14 попадает в интервал, заключенный между 11 и 33, то гипотеза должна быть принята с уровнем значимости 5 %.
. Так как А = 14 попадает в интервал, заключенный между 11 и 33, то гипотеза должна быть принята с уровнем значимости 5 %.
3. Корреляционный анализ
Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными. Различают два вида зависимостей между величинами (факторами): функциональную и статистическую.
При функциональной зависимости двух величин значению одной из них обязательно соответствует одно или несколько точно определенных значений другой величины. Функциональная связь двух факторов возможна лишь при условии, что вторая величина зависит только от первой и не зависит ни от каких других величин. Функциональная связь одной величины с множеством других возможна, если эта величина зависит только от этого множества факторов. В реальных ситуациях существует бесконечно большое количество свойств самого объекта и внешней среды, влияющих друг на друга, поэтому такого рода связи не существуют, иначе говоря, функциональные связи являются математическими абстракциями. Их применение допустимо тогда, когда соответствующая величина в основном зависит от соответствующих факторов.
При исследовании функционирования систем многие параметры следует считать случайными, что исключает проявление однозначного соответствия значений. Воздействие общих факторов, наличие объективных закономерностей в поведении объектов приводят лишь к проявлению статистической зависимости. Статистической называют зависимость, при
которой изменение одной из величин влечет изменение распределения других (другой), и эти другие величины принимают некоторые значения с определенными вероятностями. Функциональную зависимость в таком случае следует считать частным случаем статистической: значению одного фактора соответствуют значения других факторов с вероятностью, равной единице. Однако на практике такое рассмотрение функциональной связи применения не нашло.
Более важным частным случаем статистической зависимости является корреляционная зависимость, характеризующая взаимосвязь значений одних случайных величин со средним значением других, хотя в каждом отдельном случае любая взаимосвязанная величина может принимать различные значения.
Если же у взаимосвязанных величин вариацию имеет только одна переменная, а другая является детерминированной, то такую связь называют не корреляционной, а регрессионной. Например, при анализе скорости обмена с жесткими дисками можно оценивать регрессию этой характеристики на определенные модели, но не следует говорить о корреляции между моделью и скоростью.
При исследовании зависимости между одной величиной и такими характеристиками другой, как, например, моменты старших порядков (а не среднее значение), то эта связь будет называться статистической, а не корреляционной.
Термин «корреляция» впервые применил французский палеонтолог Ж. Кювье, который вывел «закон корреляции частей и органов животных» (этот закон позволяет восстанавливать по найденным частям тела облик всего животного). В статистику указанный термин ввел английский биолог и статистик Ф. Гальтон (не просто связь – relation, а «как бы связь» – co-relation). Корреляционная связь описывает следующие виды зависимостей:
– причинную зависимость между значениями параметров. Примером такой зависимости является взаимосвязь пропускной способности канала передачи данных и соотношения сигнал/шум (на пропускную способность влияют и другие факторы – характер помех, амплитудно-частотные характеристики канала, способ кодирования сообщений и др.). Установить однозначную связь между конкретными значениями указанных параметров не удается. Но очевидно, что пропускная способность зависит от соотношения уровней сигнала и помех в канале. Иногда причину и следствие особо не выделяют. В некоторых случаях такая корреляция является бессмысленной, например: если в качестве исходного фактора взять доходы разработчиков антивирусных программ, а за результат –
количество вновь появляющихся вирусов, то можно сделать вывод, что разработчики антивирусов «стимулируют» создание вирусов;
– «зависимость» между следствиями общей причины. Подобная
зависимость характерна, в частности, для скорости и безошибочности набора текста оператором (указанные факторы зависят от квалификации оператора).
Существование взаимных связей двух и более случайных величин и их относительную силу можно измерить с помощью корреляционного момента (коэффициента ковариации):
 . (3.1)
. (3.1)
Этот показатель неудобен для практического применения, т. к. имеет размерность, равную произведению размерностей вариант, и по его величине трудно судить о зависимости параметров.
Коэффициент ковариации rx,y нормированных случайных величин называют коэффициентом корреляции, его оценка
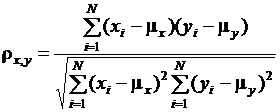 . (3.2)
. (3.2)
Коэффициент корреляции зависит не от значений случайных величин, а от их вариаций, так если значение величины увеличить на порядок, то коэффициент не изменится. Значение коэффициента корреляции лежит в пределах от – 1 до + 1. Если случайные величины Uj и Uk независимы, то коэффициент корреляции обязательно равен нулю, обратное утверждение неверно. Коэффициент корреляции характеризует значимость линейной связи между случайными величинами (параметрами):
– при rjk = 1 значения uij и uik полностью совпадают. Иначе говоря, имеет место функциональная зависимость: зная значение одного параметра, можно однозначно указать значение другого параметра;
– при rjk = – 1 величины uij и uik принимают противоположные значения. В этом случае имеет место функциональная зависимость;
– при rjk = 0 величины uij и uik практически не связаны друг с другом линейным соотношением. Это не означает отсутствия каких-то других (например, нелинейных) связей между параметрами;
– при |rjk| > 0 и |rjk| < 1 однозначной линейной связи величин uij и uik нет. И чем меньше абсолютная величина коэффициента корреляции, тем в меньшей степени по значениям одного параметра можно предсказать значение другого.
Интерпретация коэффициента корреляции заключается в следующем: отклонение одной случайной величины от среднего значения на
величину среднего квадратического отклонения приводит в среднем по совокупности к отклонению другой случайной величины от своего среднего значения на rjk ее среднего квадратического отклонения.
Нелинейная связь и разброс данных, вызванный ошибками измерения или неполной коррелированностью случайных данных, приводит к уменьшению абсолютного значения коэффициента корреляции.
Пусть из случайных величин x и y получена выборка, состоящая из N пар наблюденных значений. Оценка коэффициента корреляции называется выборочным коэффициентом корреляции и вычисляется по формуле:
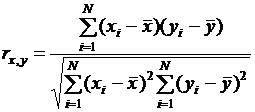 . (3.3)
. (3.3)
Кроме коэффициента корреляции, применяют и производную от него величину – коэффициент детерминации, равный ![]() . Коэффициент детерминации характеризует долю общей дисперсии одного параметра, которая объясняется вариацией другого параметра.
. Коэффициент детерминации характеризует долю общей дисперсии одного параметра, которая объясняется вариацией другого параметра.
Для оценки точности выборочного значения rx,y используют функцию от rx,y: 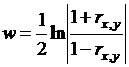 . Распределение случайной величины w можно аппроксимировать нормальным распределением с
. Распределение случайной величины w можно аппроксимировать нормальным распределением с 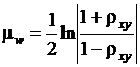 и
и 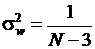 . На основе этих соотношений можно построить доверительный интервал для rx,y по выборочной оценке rx,y. Из-за выборочной изменчивости оценок корреляции приходится проверять, свидетельствует ли ненулевое значение выборочного коэффициента корреляции о существовании значимой корреляции между случайными величинами. Для этого надо проверить гипотезу rx,y = 0. При rx,y = 0 величина w распределена нормально с
. На основе этих соотношений можно построить доверительный интервал для rx,y по выборочной оценке rx,y. Из-за выборочной изменчивости оценок корреляции приходится проверять, свидетельствует ли ненулевое значение выборочного коэффициента корреляции о существовании значимой корреляции между случайными величинами. Для этого надо проверить гипотезу rx,y = 0. При rx,y = 0 величина w распределена нормально с 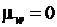 и . Поэтому область принятия гипотезы
и . Поэтому область принятия гипотезы 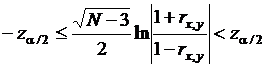 .
.
Многие объекты исследования характеризуются множеством параметров, и по результатам наблюдения за их функционированием формируются многомерные совокупности (матрицы) экспериментальных данных:
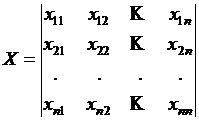 .
.
Строки такой матрицы соответствуют результатам регистрации всех наблюдаемых параметров объекта в одном эксперименте, а столбцы содержат результаты наблюдений за одним параметром (фактором, вариантой) во всех экспериментах. Обозначим количество параметров через m (m > 1), а количество наблюдений – через n.
В матрице элемент хij соответствует значению j-й варианты в i-м наблюдении. Матрица, вообще говоря, может содержать пустые значения некоторых элементов, например, из-за пропусков в регистрации значений параметров. В многомерном анализе желательно устранить пропущенные значения. Для этого существуют специальные приемы, в частности, вычеркивание соответствующих строк матрицы или занесение средних значений вместо отсутствующих. В дальнейшем будем считать, что матрица не содержит пустых элементов, а параметры объекта характеризуются
непрерывными случайными величинами.
Методы обработки матрицы экспериментальных данных основаны на следующем предположении: если объект подвергнуть новому обследованию и получить, вообще говоря, другую матрицу данных, то после ее обработки с помощью тех же методов будут получены результаты, близкие к результатам обработки первой матрицы. Данное предположение
основано на статистической гипотезе формирования матрицы экспериментальных данных. Матрица порождается случайным образом в соответствии с определенной вероятностной закономерностью, а именно: в
m-мерном пространстве параметров существует некоторое (пусть и неизвестное) распределение вероятностей, и каждая строка матрицы появляется в соответствии с этим распределением независимо от появления других строк.
Каждый столбец матрицы представляет собой случайную выборку значений одного параметра объекта. Указанное предположение означает, во-первых, что оценки моментов и параметров распределения, вычисленные по выборке, будут близки к истинным значениям, во-вторых, значения непрерывных функций, построенных по этим оценкам, будут близки к значениям функций, построенным по истинным значениям параметров.
Используя понятие коэффициента корреляции, матрице экспериментальных данных можно поставить в соответствие квадратную матрицу оценок коэффициентов корреляции (корреляционную матрицу)
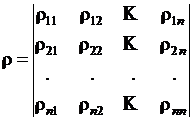 .
.
К числу характерных свойств корреляционной матрицы относят:
1) симметричность относительно главной диагонали rjk = rkj ;
2) единичные значения элементов главной диагонали, rkk = 1 (rkk соответствует дисперсии стандартизованного параметра uk), k = 1, 2, … , m.
Таким образом, постановка задачи линейного корреляционного анализа формулируется в следующем виде:
– имеется матрица наблюдений;
– необходимо определить оценки коэффициентов корреляции для всех или только для заданных пар параметров и оценить их значимость. Незначимые оценки приравниваются к нулю;
– допущения:
· выборка имеет достаточный объем. Понятие достаточного объема зависит от целей анализа, требуемой точности и надежности оценки коэффициентов корреляции, от количества факторов. Минимально допустимым считается объем, когда количество наблюдений не менее чем в 5 – 6 раз превосходит количество факторов;
· выборки по каждому фактору являются однородными. Это допущение обеспечивает несмещенную оценку средних величин;
· матрица наблюдений не содержит пропусков.
Если необходима проверка значимости оценки коэффициента корреляции, то требуется соблюдение дополнительного условия – распределение вариант должно подчиняться нормальному закону.
Задача анализа решается в несколько этапов:
1) проводится стандартизация исходной матрицы;
2) вычисляются парные оценки коэффициентов корреляции;
3) проверяется значимость оценок коэффициентов корреляции, незначимые оценки приравниваются к нулю. По результатам проверки делается вывод о наличии связей между вариантами (факторами).
Корреляционная зависимость не обязательно устанавливается только для двух величин, с ее помощью можно анализировать связи между несколькими вариантами (множественная корреляция). А кроме линейной, существуют и другие виды корреляции.
4. Регрессионный анализ
4.1. Задача регрессионного анализа
Одной из типовых задач обработки многомерных экспериментальных данных является определение количественной зависимости показателей качества объекта от значений его параметров и характеристик внешней среды. Примером такой постановки задачи является установление
зависимости между временем обработки запросов к базе данных и интенсивностью входного потока. Время обработки зависит от многих факторов, в том числе от размещения искомой информации на внешних носителях, сложности запроса. Следовательно, время обработки конкретного
запроса можно считать случайной величиной. Но вместе с тем, при увеличении интенсивности потока запросов следует ожидать возрастания его среднего значения, т. е. считать, что время обработки и интенсивность потока запросов связаны корреляционной зависимостью.
Корреляционный анализ позволяет установить степень взаимосвязи двух и более случайных величин. Однако наряду с этим желательно иметь модель этой связи, которая позволяла предсказывать значение одной величины по конкретным значениям других. Методы решения таких задач носят название «регрессионный анализ».
Постановка задачи регрессионного анализа формулируется следующим образом.
Имеется совокупность результатов наблюдений. В этой совокупности один столбец соответствует показателю, для которого необходимо установить функциональную зависимость с параметрами объекта и среды, представленными остальными столбцами. Будем обозначать показатель через y* и считать, что ему соответствует первый столбец матрицы наблюдений. Остальные m – 1 (m > 1) столбцов соответствуют параметрам (факторам) х2, х3, … , хm .
Требуется установить количественную взаимосвязь между показателем и факторами. В таком случае задача регрессионного анализа понимается как задача выявления такой функциональной зависимости y* = f (х2, х3, … , хm), которая наилучшим образом описывает имеющиеся экспериментальные данные.
Допустим, что количество наблюдений достаточно для проявления статистических закономерностей относительно факторов и их взаимосвязей; обрабатываемые экспериментальные данные содержат некоторые ошибки (помехи), обусловленные погрешностями измерений, воздействием неучтенных случайных факторов; матрица результатов наблюдений является единственной информацией об изучаемом объекте, имеющейся в распоряжении перед началом исследования.
Функция f (x2, x3, … , xn), описывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии. Термин «регрессия» (regression (лат.) – отступление, возврат к чему-либо) связан со спецификой одной из конкретных задач, решенных на стадии становления метода. Его ввел английский статистик Ф. Гальтон. Он исследовал влияние роста родителей и более отдаленных предков на рост детей. По его модели рост ребенка определяется наполовину родителями, на четверть – дедом с бабкой, на одну восьмую прадедом и прабабкой и т. д. Другими словами, такая модель характеризует движение назад по генеалогическому дереву. Ф. Гальтон назвал это явление регрессией как противоположное движению вперед – прогрессу. В настоящее время термин «регрессия» применяется в более широком плане – для описания любой статистической связи между случайными величинами.
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
– предварительная обработка экспериментальных данных;
– выбор вида уравнений регрессии;
– вычисление коэффициентов уравнения регрессии;
– проверка адекватности построенной функции результатам наблюдений.
Предварительная обработка включает стандартизацию матрицы экспериментальных данных, расчет коэффициентов корреляции, проверку их значимости и исключение из рассмотрения незначимых параметров. В
результате преобразований будут получены стандартизованная матрица наблюдений U (через y будем обозначать стандартизованную величину y*) и корреляционная матрица r.
Стандартизованной матрице U можно сопоставить одну из следующих геометрических интерпретаций:
– в m-мерном пространстве оси соответствуют отдельным параметрам и показателю. Каждая строка матрицы представляет вектор в этом пространстве, а вся матрица – совокупность n векторов в пространстве параметров;
– в n-мерном пространстве оси соответствуют результатам отдельных наблюдений. Каждый столбец матрицы – вектор в пространстве наблюдений. Все вектора в этом пространстве имеют одинаковую длину, угол между двумя векторами характеризует взаимосвязь соответствующих величин. Чем меньше угол, тем теснее связь (тем больше коэффициент корреляции).
В корреляционной матрице особую роль играют элементы левого столбца – они характеризуют наличие или отсутствие линейной зависимости между соответствующим параметром ui (i = 2, 3, … , n) и показателем объекта y. Проверка значимости позволяет выявить такие параметры, которые следует исключить из рассмотрения при формировании линейной функциональной зависимости, и тем самым упростить последующую обработку.
4.2. Выбор вида уравнения регрессии
Задача определения функциональной зависимости, наилучшим образом описывающей экспериментальные данные, связана с преодолением ряда принципиальных трудностей. В общем случае для стандартизованных данных функциональную зависимость показателя от параметров можно представить в виде
![]() , (4.1)
, (4.1)
где f – заранее не известная функция, подлежащая определению; e - ошибка аппроксимации экспериментальных данных.
Указанное уравнение принято называть выборочным уравнением регрессии y на u. Это уравнение характеризует зависимость между вариацией показателя и вариациями факторов.
Регрессионное уравнение не обеспечивает оценку раздельного влияния каждого фактора на показатель, такая оценка возможна лишь в случае, когда все другие факторы не связаны с изучаемым. Если изучаемый фактор связан с другими, влияющими на показатель, то будет получена смешанная характеристика влияния фактора. Эта характеристика содержит как непосредственное влияние фактора, так и опосредованное влияние, оказанное через связь с другими факторами и их влиянием на показатель.
В регрессионное уравнение не рекомендуется включать факторы, слабо связанные с показателем, но тесно связанные с другими факторами. Не включают в уравнение и факторы, функционально связанные друг с другом (для них коэффициент корреляции равен 1). Включение таких факторов приводит к вырождению системы уравнений для оценок коэффициентов регрессии и к неопределенности решения.
Функция f должна подбираться так, чтобы ошибка e была минимальна. В целях выбора функциональной связи заранее выдвигают гипотезу о том, к какому классу может принадлежать функция f, а затем подбирают «лучшую» функцию в этом классе. Выбранный класс функций должен обладать некоторой «гладкостью», т. е. «небольшие» изменения значений аргументов должны вызывать «небольшие» изменения значений функции (экспериментальные данные содержат некоторые ошибки измерений, а само поведение объекта подвержено влиянию помех, маскирующих истинную связь между параметрами и показателем).
Простым, удобным для практического применения и отвечающим указанному условию является класс полиномиальных функций
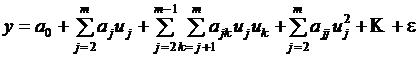 . (4.2)
. (4.2)
Для такого класса задача выбора функции сводится к задаче выбора значений коэффициентов a0, aj, ajk, … , ajj, … . Однако универсальность полиномиального представления обеспечивается только при возможности неограниченного увеличения степени полинома, что не всегда допустимо на практике, поэтому приходится применять и другие виды функций.
Частным случаем, широко применяемым на практике, является полином первой степени или уравнение линейной регрессии:
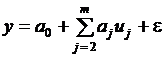 . (4.3)
. (4.3)
Это уравнение в регрессионном анализе следует трактовать как векторное.
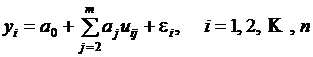 . (4.4)
. (4.4)
Для выбора вида функциональной зависимости можно рекомендовать следующий подход:
1) в пространстве параметров графически отображают точки со значениями показателя. При большом количестве параметров можно строить точки применительно к каждому из них, получая двумерные распределения значений;
2) по расположению точек и на основе анализа сущности взаимосвязи показателя и параметров объекта делают заключение о примерном виде регрессии или ее возможных вариантах;
3) после расчета параметров оценивают качество аппроксимации, т. е. оценивают степень близости расчетных и фактических значений;
4) если расчетные и фактические значения близки во всей области задания, то задачу регрессионного анализа можно считать решенной. В противном случае можно попытаться выбрать другой вид полинома или другую аналитическую функцию, например периодическую.
4.3. Вычисление коэффициентов уравнения регрессии. Метод наименьших квадратов
Систему уравнений 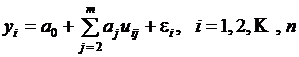 на основе имеющихся экспериментальных данных однозначно решить невозможно, т. к. количество неизвестных всегда больше количества уравнений. Для преодоления этой проблемы нужны дополнительные допущения. Желательно выбрать коэффициенты полинома так, чтобы обеспечить минимум ошибки аппроксимации. Для оценки ошибок аппроксимации могут применяться различные меры. В качестве такой меры широкое применение нашла среднеквадратическая ошибка. На ее основе разработан специальный метод оценки коэффициентов уравнений регрессии – метод наименьших квадратов (МНК). Этот метод позволяет получить оценки максимального правдоподобия неизвестных коэффициентов уравнения регрессии при нормальном распределения вариант, но его можно применять и при любом другом распределении факторов.
на основе имеющихся экспериментальных данных однозначно решить невозможно, т. к. количество неизвестных всегда больше количества уравнений. Для преодоления этой проблемы нужны дополнительные допущения. Желательно выбрать коэффициенты полинома так, чтобы обеспечить минимум ошибки аппроксимации. Для оценки ошибок аппроксимации могут применяться различные меры. В качестве такой меры широкое применение нашла среднеквадратическая ошибка. На ее основе разработан специальный метод оценки коэффициентов уравнений регрессии – метод наименьших квадратов (МНК). Этот метод позволяет получить оценки максимального правдоподобия неизвестных коэффициентов уравнения регрессии при нормальном распределения вариант, но его можно применять и при любом другом распределении факторов.
Метод наименьших квадратов как вычислительная процедура был описан Лагранжем в 1806 г. в его труде Nouvelles methodes pour la determination des orbites des cometes. Им также было предложено название этого метода. Первым, кто связал метод наименьших квадратов с теорией вероятностей, был Гаусс (1809 г.).
В основе МНК лежат следующие положения:
1) значения величин ошибок и факторов независимы, а значит, и некоррелированы, т. е. предполагается, что механизмы порождения помехи не связаны с механизмом формирования значений факторов;
2) математическое ожидание ошибки e должно быть равно нулю (постоянная составляющая входит в коэффициент a0), иначе говоря, ошибка является центрированной величиной;
3) выборочная оценка дисперсии ошибки должна быть минимальна.
Рассмотрим МНК применительно к линейной регрессии стандартизованных величин. Пусть между двумя случайными величинами x и y имеет месть линейная связь. Это означает, что прогноз значения случайной величины y по заданному значению x имеет вид ![]() . Если данные связаны идеальной линейной зависимостью (rx,y = 1), то предсказанное значение
. Если данные связаны идеальной линейной зависимостью (rx,y = 1), то предсказанное значение ![]() будет в точности совпадать с эмпирическим значением yi при данном xi. Однако на практике обычно отсутствует идеальная линейная зависимость между данными. Внешние случайные воздействия приводят к разбросу данных, возможны искажения из-за присутствия нелинейных эффектов. Если предположить существование линейной связи, то можно подобрать такие значения А и В, которые дадут возможность предсказать ожидаемое значение yi для любого данного xi. Это означает, что
будет в точности совпадать с эмпирическим значением yi при данном xi. Однако на практике обычно отсутствует идеальная линейная зависимость между данными. Внешние случайные воздействия приводят к разбросу данных, возможны искажения из-за присутствия нелинейных эффектов. Если предположить существование линейной связи, то можно подобрать такие значения А и В, которые дадут возможность предсказать ожидаемое значение yi для любого данного xi. Это означает, что ![]() не обязательно совпадет с эмпирическим значением yi, но оно будет равно среднему значению всех таких эмпирических значений.
не обязательно совпадет с эмпирическим значением yi, но оно будет равно среднему значению всех таких эмпирических значений.
По МНК определяются такие значения коэффициентов уравнения регрессии А и В, которые обеспечивают безусловный минимум выражению
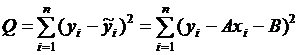 . (4.5)
. (4.5)
Минимум находится приравниванием нулю всех частных производных Q, взятых по неизвестным коэффициентам А и В:
![]() , (4.6)
, (4.6)
и решением системы уравнений
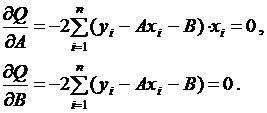 (4.7)
(4.7)
Последовательно проведя преобразования (4.7), получим:
(4.8)
Из второго уравнения системы (4.8) следует:
![]() . (4.9)
. (4.9)
Подставляем выражение (4.9) в первое уравнение системы (4.8), получаем выражение:
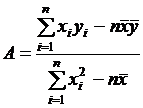 . (4.10)
. (4.10)
4.4. Критерий значимости линии регрессии
Проверка значимости регрессии начинается с исследования общей суммы квадратов отклонений значений ![]() от среднего
от среднего ![]() :
: 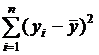 .
.
Для метода наименьших квадратов имеет место следующее разложение:
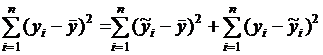 . (4.11)
. (4.11)
Таким образом, сумма квадратов может быть разбита на две положительные компоненты:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
