

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Пример 1: 1. Соотношение числа наименее обеспеченных избирателей к числу наиболее обеспеченных: столбец С: [строка №1/строка №5]=[9,5/5,0]=1,9 раза.
Пример 2. Соотношение числа тех, чьи доходы не ниже 30 тысяч рублей с числом тех, чьи доходы ниже 30 тысяч рублей: столбец С: [строки№4+№5]/строки[№3+№2+№1] =
= [(20,0+5,0)/(40,0+25,5+9,5)] =1/3
3.2. Ряды распределения. Нормальное распределение.
Список или ряд значений признака и соответствующих им частот, как уже отмечалось ранее, в статистике принято называть вариационным рядом. Варианты, или отдельные значения вариационного ряда, могут быть выражены в относительной, номинальной или порядковой позиционной шкале измерения.
Описательный анализ статистической совокупности принято начинать с определения нормальности рядов распределения вариант изучаемых признаков, выраженных в относительных шкалах измерений. Нормальность - свойство, присущее распределению частот большинства признаков. Оно основано на «Законе больших чисел», и проявляется в том, что значения частот, соответствующие значениям вариант признака, приближаются (графически) по мере увеличения количества единиц наблюдения к некоей «нормальной» кривой, напоминающей форму колокола с вершиной, соответствующей среднему значению признака.
Если сгруппированный вариационный ряд представить в виде графика, по оси Х отложить значения вариант, а по оси Y - соответствующие им частоты, то координата Х вершины графика нормально распределенных данных соответствует центру распределения, а его концы уходят значениями в ± бесконечность. Ее вид показан сплошной линией на графиках 1-3. Нормальная кривая – есть предельное, теоретическое распределение частот при условии отсутствия в распределении случайных отклонений. Необходимыми предпосылками к условию нормальности являются однородность совокупности по изучаемым признакам, не подверженность рассматриваемого признака влиянию какого-нибудь другого существенного признака (или нескольких), а также достаточное для проявления нормальности количество единиц наблюдения.
Считается, что единиц должно быть не меньше 30-ти, а оптимальным минимумом считается 100-120 единиц. В практике опросов, правда, ограничиваются 50-60-ю. Если единиц менее 30-ти, то теоретическое распределение имеет более отлогую форму и становится зависимым от параметра (N-1). Такое распределение называется распределением Стьюдента. По мере увеличения единиц до 100-120, - это распределение приближается и сливается с нормальным видом.
Основные методы описательного анализа статистической совокупности, сводящиеся к расчету из значений признака и его частот обобщающих показателей, называются параметрическими. Они предполагают, по крайней мере, приблизительно нормальное распределение вариант признака. Если это условие не выполняется, то обобщающие показатели, рассчитываемые по таким данным, могут не корректно характеризовать всю совокупность. В случаях, когда распределение не имеет хотя бы приблизительно нормального распределения, его пытаются математическими преобразованиями над значениями признака, например, логарифмированием, перевести в таковое. Если и это не удается, то пользуются так называемыми непараметрическими методами анализа, основанными на использование рангов и частот изучаемых значений признаков.
Как определить, нормально ли распределены варианты признака, и где находится та граница, за которой нормальное распределение становится ненормальным? Нормальность распределения определяется следующими путями.
Первый путь - по визуальному сравнению реального (эмпирического) распределения и теоретической кривой. Возьмем для примера реальные данные Росстата за 2004 год по 79 основным регионам России (кроме Чеченской Республики). Столбчатый график, на котором показывается распределение частот в зависимости от значений признака, называют гистограммой (Histogram). Пример гистограммы приведен на рис. 1.
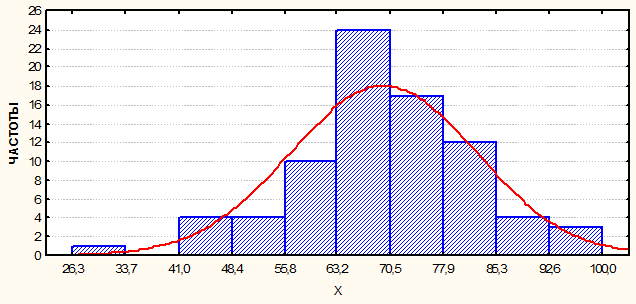 Рис. 1.Распределение регионов России по доле городского населения (Х), в 2004 году, в процентах.
Рис. 1.Распределение регионов России по доле городского населения (Х), в 2004 году, в процентах.
По графику на рис. 1 видно, что нормальная кривая проходит достаточно близко с реальным (или эмпирическим) распределением. Если по данному графику построить полигон, т. е. ломаную линию, соединяющую середины верхних линий столбиков гистограммы между собой, то близость реального и теоретического (нормального) распределений будет еще более очевидна.
Если это же распределение представить в виде 14 интервалов, то оно будет иметь совсем другой - менее нормальный графический вид (см. рис.2).
Если же количество интервалов, наоборот, сократить до семи, то график станет более «нормальным». Очевидно, что визуальное определение нормальности распределения зависит от количества интервалов, выбранных для построения гистограммы, т. е. от субъективного решения самого исследователя.
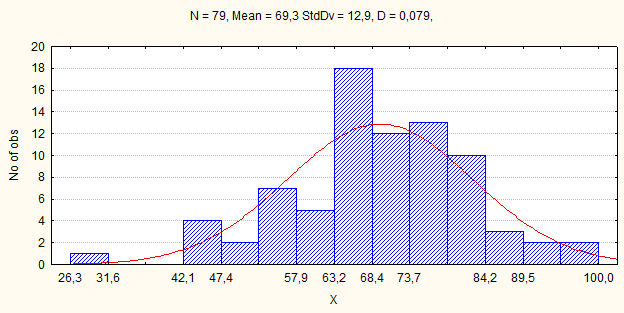 Рис.2. Распределение основных регионов России по доле городского населения (Х), в 2004 году, в процентах (Вариант 2 рисунка 1).
Рис.2. Распределение основных регионов России по доле городского населения (Х), в 2004 году, в процентах (Вариант 2 рисунка 1).
Тем не менее, все три графика имеют так или иначе близкий к нормальному распределению вид. В случае, когда интервалов 14 - в каждом из них находится в среднем по около пяти единиц наблюдения, что не всегда достаточно для сглаживания случайных отклонений. Поэтому и график становится визуально менее нормальным.
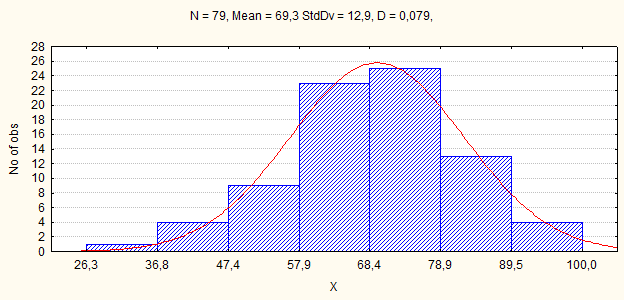 Рис.3. Распределение 79 основных регионов России по доле городского населения (Х), в 2004 году, в процентах. (Вариант 3 рисунка 1).
Рис.3. Распределение 79 основных регионов России по доле городского населения (Х), в 2004 году, в процентах. (Вариант 3 рисунка 1).
Считается, что для устранения случайных отклонений нужно, чтобы на каждый из интервалов в среднем приходилось хотя бы по 10 единиц наблюдения.
Пример 2. Теперь возьмем из того же сборника обеспеченность населения врачами на 10 000 населения. Получаем следующую картину распределения (см. рис.4). По графику-гистограмме видно, что максимальное количество регионов имеет обеспеченность врачами 33-39 человек на 10 000 населения, меньше – практически нет, больше - постепенно сокращаются. Очевидно, что имеется признак, который влияет на такое распределение, которое нормальным назвать нельзя.
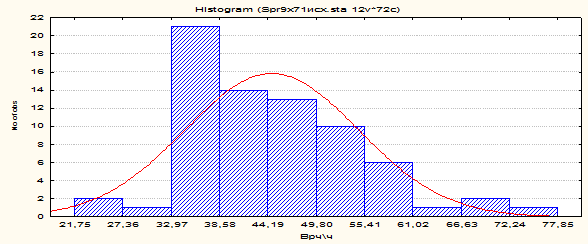
Рис. 4. Распределение регионов России в 2004 году по обеспеченности врачами на 10 000 населения.
Почему нельзя пользоваться данными с таким распределением для дальнейшего статистического анализа? Потому, что параметрические статистики, рассчитываемые по нему, не будут адекватно характеризовать все распределение, а выявление связей с другими признаками, имеющими нормальное распределение, будет давать искаженный результат, тем самым, вводя в заблуждение исследователя.
По гистограммам можно выявить много необходимой информации о распределении вариант. Так, если распределение имеет не одну, а две (или более) вершины, то можно сделать вывод о неоднородности совокупности и необходимости провести группировку по какому-нибудь существенному признаку для выделения более однородных подсовокупностей. (Пример - см. рис.5 стр.74). По гистограмме видно, что имеются две вершины распределения. Это объясняется, очевидно, неоднородностью распределения регионов России по этому параметру.
Второй путь определения нормальности - с помощью так называемых непараметрических «критериев нормальности». Принцип их построения - математические преобразования над отклонениями между реальным распределением и теоретической нормальной кривой. Среди них самые известные - это критерий Пирсона «Хи-квадрат», критерий Колмогорова-Смирнова (D), основанный на порядках распределения значений, и Шапиро-Уилка (SW-W, или W), основанный на связи между эмпирическими и теоретическими порядками значений. В ПСП в качестве дополнительных функций к построению гистограмм представлены два критерия (D и SW-W).
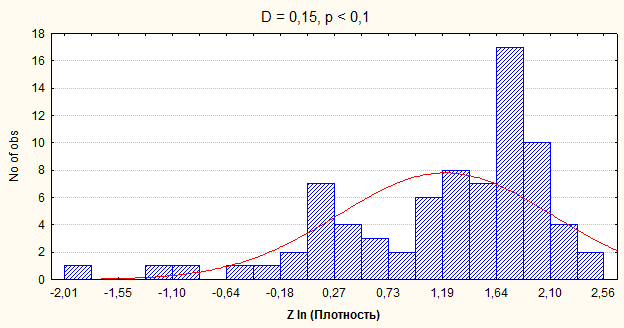 Рис.5. Гистограмма распределения стандартизированных взвешенных значений логарифмов от плотности населения по регионам России, по данным за гг.
Рис.5. Гистограмма распределения стандартизированных взвешенных значений логарифмов от плотности населения по регионам России, по данным за гг.
Критерий Колмогорова-Смирнова (D) предназначен, прежде всего, для оценки функции (для данного случая - нормальности) распределения генеральной совокупности по выборке. Но также его можно использовать и для сравнения между собой уровней нормальности распределений не выборочных совокупностей равного объема. «Более точную информацию о форме распределения можно получить с помощью критериев нормальности (например, критерия Колмогорова-Смирнова или W критерия Шапиро-Уилка)» [14]. При равном количестве единиц наблюдения вид распределения рассматриваемой совокупности более близок к нормальному виду, чем вид распределения другой совокупности, если критерий нормальности Колмогорова-Смирнова (при равной вероятности или уровне значимости) первой совокупности ниже.
Критерий Колмогорова-Смирнова предполагает сравнение расчетного критерия с табличным (критическим). Величину последнего можно рассчитать по формуле (при N>30) для различных вероятностей. Так, для вероятности P=0,95: D кр. = 1,36 / ![]() . [1, с.640].
. [1, с.640].
Если расчетный критерий меньше табличного, то распределение с принятой вероятностью можно считать нормальным, если приблизительно равен или больше табличного - распределение не нормальное.
Приведем пример по двум распределениям логарифмов МИПС[2] выбытий (миграционных индексов пространственной структуры, показывающих территориальные предпочтения в парных выбытиях между регионами) из Белгородской области и из г. Москвы. Количества единиц обеих совокупностей равны по 78 единиц, N=78. Совместное распределение приведено на рис.6 стр.77.
Распределение значений МИПС выбытий из города Москвы визуально менее нормально, чем из Белгородской области. Количественно это различие и можно выразить с помощью критериев Колмогорова-Смирнова (D) двух распределений. Значение D (Белгородской области) меньше, чем D (города Москвы).
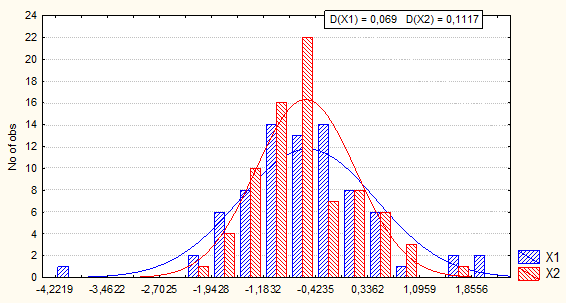
Где: Х1 – Белгородская область, Х2 – г. Москва.
Рис.6.Гистограммы распределения логарифмов значений МИПС выбытий из Белгородской области и из г. Москвы, по данным за гг.
Поэтому распределение значений МИПС первого региона более близко к нормальному виду, чем второго. При вероятности P=0,95 (уровне значимости 5%) D критическое примерно равно 0,15 , т. е. оба распределения, будь они выборочными, т. е., отобранными по статистической методологии, предполагающей равновероятностный отбор для любой из единиц генеральной совокупности, могли бы с данной вероятностью характеризовать распределение генеральной совокупности как нормальное. А из этого следует, что их вид достаточно нормален не только для процедуры оценивания, но и для суждения о том, что они и сами распределены по нормальному закону при выбранной вероятности утверждения об этом.
Используя любой критерий, Колмогорова-Смирнова или иной, необходимо все же помнить, что они не могут полностью заменить визуального определения нормальности по гистограмме.
Третий путь - с помощью таких параметрических статистик (показателей), как коэффициенты Ассиметрии и Эксцесса, которые дают количественные критерии таким особенностям распределения как асимметричность и - пологость (или остроконечность) фактического ряда по сравнению с теоретической кривой.
3.3. Характеристики центра распределения.
Для того чтобы сравнивать статистическую совокупность по значениям признаков либо с другой схожей совокупностью, либо во времени, - пользоваться рядом распределения признаков неудобно, да и достаточно сложно. Поэтому одной из основных задач описательной статистики является создание такой минимальной по количеству системы показателей – параметров, с помощью которых можно бы было охарактеризовать и сравнивать данную совокупность по отдельным признакам. Прежде всего, к этим параметрам относятся характеристики центра распределения – мода (Мо), медиана (Ме, Мd) и среднее арифметическое значение (![]() ).
).
Построение таких показателей предполагает нормальность распределений сравниваемых признаков совокупностей. Но цели построения таких показателей шире, чем сравнение признаков совокупностей. Они позволяют характеризовать распределения вариант с помощью нескольких параметров и сравнивать индивидуальные значения с типичным уровнем ряда.
Мода (Мо) - значение признака с максимальной частотой. В любой шкале измерений есть варианта, или варианты, имеющие наибольшую частоту. Для вариант, выраженных в номинальной шкале измерения, мода – единственная из характеристик центра распределения.
Медиана (Ме, Md) – серединное значение ряда распределения. Для дискретных вариант при нечетном количестве единиц наблюдения N это:
[(N+1)/2]-ое значение, при четном - среднее из N/2 –того и [(N/2)+1]-того значений. Медиана делит всю совокупность на две равные по количеству части. Так как для ее нахождения требуется упорядочение совокупности по возрастанию значений, то для признаков, выраженных в номинальной шкале, расчет медианы не возможен.
Кроме медианы при характеристике ряда распределения используются и другие деления совокупности на равные по количеству входящих в них частот части: на 4 равнонаполненные части – квантили, на 10 равнонаполненных частей – децили, на 100 равнонаполненных частей – процентили. Использование этих характеристик в описательном анализе связано с переходом к вероятностной интерпретации распределения вариант, а медианы – еще и с ее сравнением со следующей, основной характеристики ряда распределения, средней арифметической.
Средняя арифметическая (![]() ) – используемое лишь для вариант относительной шкалы измерения типичное значение, характеризующее одним числом уровень значения признака всей совокупности. Оно есть «мера [значения] признака в расчете на единицу совокупности» [4, c. 56 ].
) – используемое лишь для вариант относительной шкалы измерения типичное значение, характеризующее одним числом уровень значения признака всей совокупности. Оно есть «мера [значения] признака в расчете на единицу совокупности» [4, c. 56 ].
Средняя – есть форма обобщающего показателя, включающего в себя то общее, что присуще всем единицам совокупности, - наиболее ожидаемое значение вариационного ряда. Необходимое условие для корректного использования средней – однородность и приблизительная нормальность распределения совокупности по усредняемому признаку. Сущность сравнения средних во времени или в пространстве состоит в том, что они, погашая случайные отклонения, учитывают лишь изменения, происходящие под воздействием основных факторов, позволяя исследователю сравнивать лишь наиболее существенные закономерности в изменениях значений изучаемых признаков. Расчет среднего арифметического идет через деление суммарного значения признака на общее количество единиц совокупности – в случае, если среднее арифметическое рассчитывается из индивидуальных абсолютных показателей. Из формулы расчета средней вытекает основное ее свойство. Сумма отклонений всех значений вариационного ряда от средней величины равна нулю, т. е. средняя является «центром равновесия» всех значений.
Если исходные данные – не сгруппированные отдельные значения, то расчет средней арифметической идет по формуле (i - номера единиц совокупности i=1,N):
![]() = å Х i /N,
= å Х i /N,
где å Х i - Суммарное значение признака; N - общее количество единиц совокупности.
Имея исходные данные по доходу избирателей участка № N, расчет среднего дохода, был бы следующим:
![]() = [(25+10+30+12+ … +26+30+20)/1000] =23,7 тысяч рублей.
= [(25+10+30+12+ … +26+30+20)/1000] =23,7 тысяч рублей.
Если исходные данные представлены в виде интервальных групп, то для расчета средней арифметической берут серединные значения интервалов
(Хсер j) и умножаются (взвешиваются) на частоты f j. Расчет серединных значений интервалов (столбец С таблицы 6) происходит следующим путем: для всех закрытых интервалов – это среднее значение между границами интервала, например, для интервала № 4 30-39 серединное значение равно (30+40)/2=35 тысяч рублей. Для крайних открытых интервалов - подразумевают, что они имеют такую же длину, как и закрытые интервалы и ведут расчет при таком допущении: серединное значение интервала № 1. = (0+10)/2=5 тысяч рублей, Интервала № 5.=(40+50)/2=45 тысяч рублей.
Таблица 6.
Отдельные показатели уровня доходов,
по условной совокупности.
Уровень доходов ( в тыс. рублей), Х j | Доля в общей численности, (в %) , (W j) | Серединное значение в группе, (Х сер j) (в тыс. рублей) |
A | В | С |
До 10 | 9,5 | 5 |
10 - 19 | 25,5 | 15 |
20 – 29 | 40,0 | 25 |
30 – 39 | 20,0 | 35 |
40 и более | 5,0 | 45 |
ИТОГО | 100,0 | X |
Необходимо помнить, что расчет серединных значений - вынужденная процедура, когда исследователь имеет исходные данные уже в сгруппированном виде, ведь серединные значения далеко не всегда равны средним арифметическим в группах, и поэтому могут искажать реальную картину распределения значений. Например, в группе №5. средний арифметический доход может равняться и 41, и 50 тысячам рублей. В этой связи необходимо подчеркнуть, что любое сжатие информации всегда ведет к потере полной информации и к ее частичному искажению.
Итак, имея серединные значения групп Х сер j, где j - номер группы, j=1,k и соответствующие им частоты fj (или частости wj), формула расчета средней арифметической взвешенной будет иметь вид:
![]() = å Х сер j * fj / å fj N,
= å Х сер j * fj / å fj N,
где å Х сер j * fj - суммарное значение признака; å fj N – общее количество единиц совокупности;
Вместо fj в этой формуле могут стоять wj. Для данного примера:
=(5*9,5+25,5*15+40*25+20*35+5*45)/100 =23,6 тыс. рублей.
Примечательно, что средние в обоих расчетах немного отличаются: как уже говорилось – это издержки группировки: первое значение, естественно, более точное.
Не всегда расчет средней арифметической возможен по приведенным выше формулам. Когда исходные значения признака представлены в виде относительных показателей, расчет суммарного значения признака через суммирование не подходит, так как для индивидуальных относительных показателей частотами служат значения признаков в знаменателе (нижней части отношения). Если индивидуальный относительный показатель обозначить через Xi/Yi, то формула расчета средней арифметической из таких показателей будет иметь вид:
Х /Y = å [(Хi/Yi)*Yi] / å ( Yi).
Пример: плотность населения - показатель интенсивности, рассчитываемый как отношение численности населения данной территории (Xi) к ее площади (Yi) - см. таблица 7.
Чтобы найти среднюю плотность населения по всей стране, необходимо плотности отдельных округов умножить (взвесить) по их территориям, и потом все сложить и разделить на общую площадь:
Х/Y = [å ( 57,7 *650,7+ 8,2* 1677,9 +…+ 1,1*6215,9)] /
/ å [(650,7+1677,9+…+6215,9)] = 8,4 жителей на 1 кв. км.
Таблица 7.
Плотность населения России по федеральным
округам на 1 января 2005 года (данные Росстата).
Федеральные округа (ФО) | Территория, тыс. км² | Количество человек на 1 км² |
Центральный ФО | 650,7 | 57,7 |
Северо-Западный ФО | 1677,9 | 8,2 |
Южный ФО | 589,2 | 38,7 |
Приволжский ФО | 1038 | 29,6 |
Уральский ФО | 1788,9 | 6,9 |
Сибирский ФО | 5114,8 | 3,9 |
Дальневосточный ФО | 6215,9 | 1,1 |
Российская Федерация (ИТОГО) | Y= 17075,4 | Х/Y (?) |
Зная плотность и площадь, можно было бы рассчитать среднюю плотность населения по округам, найдя сначала численности населения округов, и разделив сумму численностей жителей на сумму площадей. И этот путь также правильный, ведь:
[Сумма численностей /Сумма площадей ] =å [(Хi] / å [ Yi]=
= [ Cредняя численность округа /Средняя площадь округа]= = ( å [(Хi] / 7) / ( å [Yi] / 7 ) ,
Х/Y = X ср / Y ср = å (Хi) / å (Yi) =
= [å (Хi)/N] / [å (Yi)/N],
т. е. это есть соотношение средних арифметических двух признаков, выраженных в форме абсолютных показателей. Данные расчеты показывают, что средняя арифметическая, рассчитываемая из индивидуальных относительных показателей интенсивности, не подходит под классическое определение средней арифметической. Следовательно, должно существовать более общее определение этой характеристики: она есть не только мера в расчете на единицу совокупности, - она есть мера в расчете на единицу либо совокупности, либо в расчете на единицу значения другого признака, в отличие от показателей интенсивности, которые лишь являются мерой соотношения двух разноименных показателей. В вышеприведенном примере плотность населения отдельных федеральных округов как исходные данные – есть показатели интенсивности, а плотность населения России – средняя арифметическая из них.
Кроме средней арифметической в статистике используют и другие виды средних, в том числе среднюю геометрическую, среднюю хронологическую (при анализе временных рядов).
В социально-экономической практике довольно часто можно встретить другие характеристики значений признака совокупности. Часто используется средняя арифметическая, при расчете которой варианты не взвешивают по частотам. Также в качестве характеристики признака иногда используется суммарное значение вариант признака без взвешиваний (например, суммарный коэффициент рождаемости в демографии, финансовые индексы деловой активности и т. п.).
Зная характеристики центра распределения, можно добавить определение нормальности распределения использованием следующего соотношения между ![]() , Mo и Me: вариационный ряд симметричен, если все эти три характеристики равны между собой. При правосторонней асимметрии Мо > Me >
, Mo и Me: вариационный ряд симметричен, если все эти три характеристики равны между собой. При правосторонней асимметрии Мо > Me > ![]() , при левосторонней – наоборот. Если значения средней и медианы приблизительно равны между собой, то асимметрия отсутствует, если же они значительно отличаются друг от друга, то асимметрия значительна, а распределение далеко от нормального распределения.
, при левосторонней – наоборот. Если значения средней и медианы приблизительно равны между собой, то асимметрия отсутствует, если же они значительно отличаются друг от друга, то асимметрия значительна, а распределение далеко от нормального распределения.
3.4. Характеристики вариации.
Зная средние значения, можно сравнивать уровни вариационных рядов между собой. Но для их более полной характеристики знания одних средних бывает не достаточно. В двух вариационных рядах, например, могут быть одинаковые значения средней, но в одном из них большинство значений находятся рядом со средним, а в другом – достаточно удалены от него. Как оценить эту меру близости или удаленности индивидуальных значений от среднего? Грубо это можно сделать, рассчитав размах (R) или охват значений вычитанием из максимального значения минимального: R = Xmax – Xmin. В вариационном ряду, где разброс значений вокруг средней больше - размах должен быть тоже больше. Но такая характеристика, как разность двух крайних значений, не всегда будет объективной и единственно правильной, учитывая еще и то обстоятельство, что крайние значения, или как их в последнее время стало модно называть «маргинальные», очень часто после предварительного анализа приходится либо исключать, либо исправлять. Поэтому для характеристики меры разброса значений вокруг средней используют другие характеристики, среди которых есть т. н. межквантильный размах (Rмежкв), равный разнице значений 3-его и первого квантиля: например, в совокупности, состоящей из ста единиц, это будет разница между 75-ым и 25-ым значениями, упорядоченными по возрастанию или убыванию признака. Размах и межквантильный размах служат для характеристики уровня вариации в совокупности по изучаемому признаку, а также для вспомогательных целей, например, для расчета длины равных интервалов при группировке признаков, выраженных в относительных шкалах:
l = R/ k или l = Rмежкв*2/k, где l – длина интервала, а k – количество групп.
Основные объективные характеристики для оценки уровня вариации – среднее линейное и среднее квадратическое (зарубежный аналог – стандартное) отклонение. Среднее линейное отклонение, рассчитываемое по формуле:
![]() =å[ç
=å[ç![]() -Хiç*fi]/åfi, довольно редко используется в практике. Перед стандартным отклонением у него есть одно преимущество: оно в меньшей степени, чем последнее, подвержено влиянию «выпирающих» крайних значений вариационного ряда. Среднее квадратическое отклонение (в дальнейшем будем использоваться более часто употребляемым термином – стандартное отклонение – stdDv (standard deviation)) рассчитывается по формуле:
-Хiç*fi]/åfi, довольно редко используется в практике. Перед стандартным отклонением у него есть одно преимущество: оно в меньшей степени, чем последнее, подвержено влиянию «выпирающих» крайних значений вариационного ряда. Среднее квадратическое отклонение (в дальнейшем будем использоваться более часто употребляемым термином – стандартное отклонение – stdDv (standard deviation)) рассчитывается по формуле:
σ =![]() { å [(
{ å [(![]() -Хi)²*fi]/åfi}
-Хi)²*fi]/åfi}

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
