

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Подкоренная часть этой формулы называется дисперсией, поэтому анализ, основанный на использовании этой характеристики и её составляющих
в отечественной статистике называют дисперсионным анализом. В зарубежной литературе и ПСП используются лишь термины латинского происхождения (от «variatio» - различие, изменение), поэтому аналогичные методы называются «Анализом вариации», или ANOVA (сокращенно от «Analysis of variation»).
Без доказательств примем к сведению, что сумма квадратов отклонений индивидуальных значений от средней – минимальна и единственна. Поэтому стандартное отклонение является однозначно рассчитываемой, объективной характеристикой вариации. Теперь для сравнения уровней вариации двух рядов, имеющих равные средние, достаточно будет сравнить значения их стандартных отклонений - чье отклонение больше, в том ряду и уровень вариации выше. Если средние двух сравниваемых рядов не равны между собой, то переходят к относительной мере вариации – коэффициенту вариации, рассчитываемому путем деления стандартного отклонения на среднее значение ряда:
Кv (или Vo) = σ / ![]() .
.
Теперь, зная как оценить уровень вариации, вернемся к вопросу о нормальном распределении и выясним те его свойства, которые используются при анализе реальных распределений, близких к нормальному, а также в статистическом оценивании.
Для сравнения реального распределения с теоретической кривой - варианты реального распределения переводят в т. н. стандартизированный вид, т. е. лишают их размерности. В результате этих преобразований вариационный ряд получает среднее значение, равное нулю и стандартное отклонение, равное единице. Это достигается путем преобразований над всеми значениями ряда по формуле: xi → Zi=( Xi -![]() )/σ . Таким образом, Zi – нормированные значения признака и кривая распределения, построенная по ним, сравнима с теоретической кривой распределения, которая уже исходно стандартизирована. Было доказано, что площадь под кривой нормального распределения, представляющая собой сумму всех частот, равна единице (при анализе от единицы переходят к 100%). Соответственно под каждой половиной кривой, разделенной средним значением (равным 0), площади равны по 0,5 или имеют по 50% единиц совокупности.
)/σ . Таким образом, Zi – нормированные значения признака и кривая распределения, построенная по ним, сравнима с теоретической кривой распределения, которая уже исходно стандартизирована. Было доказано, что площадь под кривой нормального распределения, представляющая собой сумму всех частот, равна единице (при анализе от единицы переходят к 100%). Соответственно под каждой половиной кривой, разделенной средним значением (равным 0), площади равны по 0,5 или имеют по 50% единиц совокупности.
Любая точка на оси Х, указывающая удаленность от среднего значения (после стандартизации равного нулю), разделяет перпендикуляром, из нее исходящим, всю площадь под кривой распределения на две табулируемые части – указывающие, сколько единиц совокупности находятся до и (или) после значения Х.
Площадь под кривой нормального теоретического стандартизированного распределения табулирована. В справочниках и учебниках приводят различные варианты ее значений. Это могут быть либо значения площади, отсекаемой ± Zi, тогда это означает площадь от - Zi до + Zi, или может быть так, что каждому значению Zi соответствует табличное значение той более отдаленной от нуля площади, которую отсекает вертикаль из этого значения от площади 0,5. Или обе площади за пределами до - Zi до + Zi. К таблицам обычно дают комментарий с графиком.
Так, например, при Zi =1 P(1)= 0,683 . Это означает, что в интервале
![]() ±1.0*σ находится 68,3 % всех единиц совокупности, в интервале
±1.0*σ находится 68,3 % всех единиц совокупности, в интервале ![]() ± 2.0*σ находится – 95,4 % всех единиц совокупности, а в интервале
± 2.0*σ находится – 95,4 % всех единиц совокупности, а в интервале
![]() ± 3 * σ находится 99,73% единиц совокупности, т. е. в пределах этого отклонения находятся почти все варианты нормально распределенной совокупности. Вследствие этого последнее соотношение называют «правилом трех сигм». Те единицы совокупности, что не попадают в пределы
± 3 * σ находится 99,73% единиц совокупности, т. е. в пределах этого отклонения находятся почти все варианты нормально распределенной совокупности. Вследствие этого последнее соотношение называют «правилом трех сигм». Те единицы совокупности, что не попадают в пределы
![]() ± 2 * σ при вероятности 95,4% (или в пределы
± 2 * σ при вероятности 95,4% (или в пределы ![]() ± 3 * σ при вероятности 99,73%), называют «статистическими выбросами», крайними, выпирающими значениями. В описательном анализе их выделение и анализ - важный этап предварительной работы. Как поступать с выпирающими значениями исследователь решает в каждом случае, руководствуясь сущностью изучаемого явления или процесса.
± 3 * σ при вероятности 99,73%), называют «статистическими выбросами», крайними, выпирающими значениями. В описательном анализе их выделение и анализ - важный этап предварительной работы. Как поступать с выпирающими значениями исследователь решает в каждом случае, руководствуясь сущностью изучаемого явления или процесса.
Выделение крайних парных значений (и минимальных, и максимальных) всех типов исходных данных и сводных показателей требуется, во-первых, для определения значений, требующих отдельного дополнительного рассмотрения. Во-вторых, эта процедура необходима для расчета надежных обобщающих показателей (параметров) массива, и, в-третьих, для выявления общих закономерностей и взаимозависимостей. Крайне отклоняющиеся, «выпирающие», «маргинальные» значения - могут вызвать серьезное смещение всех типов расчетов и оценок.
В теории статистики имеется отработанный алгоритм, позволяющий с преобладанием здравого смысла над сугубо статистическими методами проводить дальнейший анализ при наличии в исходном распределении статистических «выбросов». «…Если исследование предназначено для общественности или представляет собой государственное исследование, то следует очень осторожно и со всей ответственностью отнестись к исключению выбросов значений» [5,с.92-93]. По мнению Сигала, как компромисс можно выполнить два различных анализа: один с учетом выбросов, а другой — с исключением их. Тогда интерпретация будет содержать все результаты. Если результаты обоих анализов будут примерно одинаковыми, тогда можно будет сделать вывод, что наличие выбросов не имеет существенного значения. В более сложном случае, когда эти два анализа дадут разные результаты, ваши выводы и рекомендации будут менее определенными и однозначными.
Если данные содержат выбросы, то их следует выделить из всей совокупности и проанализировать отдельно. Необходимо обосновать мотив такого раздельного анализа. Прежде всего, наличие выбросов может приводить к проблемам при анализе данных. Трудно интерпретировать подробности структуры набора данных, если одно значение доминирует в общей картине и поэтому привлекает к себе повышенное внимание (г. Москва, например, в анализе регионов России). Кроме того, многие из распространенных современных статистических методов нельзя использовать для анализа тех данных, распределение которых сильно отличается от нормального вида.
3.5. Описательная статистика по выборке.
В главе 2 был рассмотрен вопрос о способах проведения выборки и об объективной ошибке выборки – ошибке репрезентативности (от фр.. Любая ошибка выборки привязана к конкретному обобщающему показателю или к конкретной статистической задаче – это может быть либо ошибка при расчете среднего значения по выборке, либо ошибка стандартного отклонения, либо ошибка при утверждениях – гипотезах о равенстве двух средних, взятых по двум различным выборкам, и т. д. Рассмотрим самый простой и чаще всего встречающийся вид ошибки выборки, возникающей при расчете среднего значения.
Если имеется генеральная совокупность численностью N, и из нее произведена выборка собственно-случайным или механическим способом численностью n, то для оценки неизвестных параметров в генеральной совокупности рассчитываются параметры по выборке и по ним дается интервальная оценка. Если среднее значение генеральной совокупности обозначить через ![]() г, а среднее, полученное по выборке -
г, а среднее, полученное по выборке - ![]() в, то оценка будет выглядеть следующим образом:
в, то оценка будет выглядеть следующим образом: ![]() г=
г=![]() в ± μ, где μ - интервал ошибки, или средняя ошибка оценивания средней. Почему возможно оценивать лишь интервально, а не точечно? Дело в том, что возможных вариантов значений
в ± μ, где μ - интервал ошибки, или средняя ошибка оценивания средней. Почему возможно оценивать лишь интервально, а не точечно? Дело в том, что возможных вариантов значений ![]() в слишком много. И их величины, которые могут быть получены по всем возможным выборкам, распределяются также, как и любые значения вокруг их среднего значения, которым является (примем это без доказательств) -
в слишком много. И их величины, которые могут быть получены по всем возможным выборкам, распределяются также, как и любые значения вокруг их среднего значения, которым является (примем это без доказательств) -![]() г.
г.
В теории вероятностей было доказано, что распределение обобщающих характеристик значений в выборке подвержено нормальному закону, даже если в генеральной совокупности распределение значений не имеет нормальной формы. А раз имеется нормальное распределение ![]() в, и рассчитываемая по собранным выборочным данным характеристика может иметь различные значения (находиться в различных местах этого распределения), то и границы значений генерального среднего можно указать лишь интервально – через границы существования выборочного среднего.
в, и рассчитываемая по собранным выборочным данным характеристика может иметь различные значения (находиться в различных местах этого распределения), то и границы значений генерального среднего можно указать лишь интервально – через границы существования выборочного среднего.
Размах этих границ зависит от той вероятности, или той площади значений, которая будет заказана самим исследователем, ведь на 100% оценить генеральную среднюю можно, лишь имея все возможные значения нормально распределенной выборочной характеристики, а предельных значений в теоретическом нормальном распределении, как известно, нет (они существуют лишь в пределе). Но, зная, что значения нормального нормированного распределения табулированы, можно выбрать ту достаточно высокую вероятность и соответствующую ей площадь «отсеченных» значений, при которой можно было бы с достаточной уверенностью утверждать, что генеральная средняя находится в данной ограниченной области. Утверждения эти всегда сопровождаются указанием той вероятности, с которой эти утверждения выведены. Обычно в практике и во многих статистических программах по умолчанию эту вероятность берут равной 0,95 - соответствующее ей стандартизированное значение Z = 1,96 . Т. е. с вероятностью 95% утверждается, что
![]() г =
г = ![]() в ±1.96* μ
в ±1.96* μ
и соответственно имеется шанс, или вероятность 5%, при которой ![]() г выйдет за границы этого интервального оценивания.
г выйдет за границы этого интервального оценивания.
Другие значения Z можно найти в приложениях к любому учебнику по статистике, в том числе и в Интернет-учебнике [14, «Распределения»].
Как рассчитать μ и от чего она зависит? При расчете средней ошибки μ исходят из допущения, что σг ≈ σв при n > 30. Тогда μ= σв / ![]() .
.
При n ≤ 30 μ = σв /![]() .
.
Проведя выборку и рассчитав по ней значения характеристик, ![]() в и σв, - можно интервально с выбранной вероятностью и соответствующему ей значению Z оценить значение генеральной средней:
в и σв, - можно интервально с выбранной вероятностью и соответствующему ей значению Z оценить значение генеральной средней:
![]() г =
г = ![]() в ± Z * σв /
в ± Z * σв / ![]() .
.
Аналогичным образом происходит оценивание показателей структуры по выборке. В отличие от оценивания средней - интервал оценивания доли p рассчитывается по следующей формуле:
Р г = р ± Z * 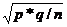 Где Р г - доля в генеральной совокупности, р - доля по выборке, q=1-p.
Где Р г - доля в генеральной совокупности, р - доля по выборке, q=1-p.
Сравнение средней и доли по выборке
При проведении выборочных обследований наиболее часто встречающейся задачей статистического оценивания является определение значимости различий между обобщающими или структурными показателями частей генеральной совокупности. Например, исследователя может интересовать вопрос о значимости различий в заработной плате мужчин и женщин в генеральной совокупности по данным выборки, или равная ли доля мужчин и женщин относится положительно к тому или иному вопросу. Оценить значимость таких различий помогает так называемый t-критерий парного сравнения. Формулы для его расчета по различным случаям парного сравнения можно найти, например, в [10,Глава 9]. Здесь же попытаемся без дополнительных формул объяснить принцип и механизм таких сравнений, позволяющий проводить их в прикладных работах.
Оценив интервально каждую из двух сравниваемых характеристик, наносим их на ось вместе с интервалами оценивания. Если с выбранной вероятностью выборочные характеристики не перекрываются хотя бы одним из интервалов оценивания вторых (сравниваемых) характеристик, то из этого следует, что две характеристики между собой имеют достаточно ощутимые различия, чтобы по ним судить и о различиях соответствующих им характеристик в генеральных совокупностях.
Например, по выборке имеем: 1) опрошено 100 мужчин, их средняя зарплата равна 7,5 тыс. рублей в месяц; 2) опрошено 120 женщин, их средняя заработная плата равна 6,9 тыс. рублей в месяц. Ощутимы ли различия в заработной плате мужчин и женщин в генеральной совокупности по данным выборки? С вероятностью 95% и соответствующим ей интервалом Z = 1,96 попытаемся ответить на этот вопрос. Сперва рассчитаем выборочные стандартные отклонения, S м и Sж. Пусть они будут равны 1,5 и 1,2 тыс. рублей соответственно. Оценим интервально зарплаты в генеральной совокупности:
Х г м = 7,5 ± 1,96 * 1,5 / ![]() = 7,5 ± 0,3
= 7,5 ± 0,3
Х г ж = 6,9 ± 1,96 * 1,2 /![]() = 6,9 ± 0,2
= 6,9 ± 0,2
__6,7_____6,9______7,1_______7,2_______7,5____7,8___
Хж Хм
Обе границы интервального оценивания не «захватывают» серединные значения (6,9 и 7,5) выборочных средних. Следовательно, различия с принятой вероятностью можно считать ощутимыми и в генеральной совокупности. Аналогичным путем сравнивают и доли по различным выборкам.
Глава 4. изучение взаимосвязи
в статистике.
4.1. Факторы и особенности статистической связи.
Изучение связей между признаками в статистике направлено, помимо прочего, на решение двух основных стратегических задач - на повышение надежности и обоснованности прогнозирования и на поиск путей воздействия, управления, регулирования явлениями и процессами. Статистические связи изучают в первую очередь между признаками, выраженными в относительных шкалах измерений, как чаще всего встречающимися в практике, хотя аппарат статистической науки разработан для описания связей между признаками, выраженными в любых типах шкал измерений.
Любой фактор есть статистически отражаемый признак объекта анализа. Изучаемые признаки можно рассматривать как результирующие факторы, или результанты (Y). Все остальные статистические признаки, отобранные исследователем для определения их взаимодействий с результантами, есть просто факторы (Хi).
Широко используемые в прикладных статистических программах и зарубежной литературе термины - зависимые (dependent) и независимые (independent) переменные применительно к факторам, на наш взгляд, - не совсем удачные, так как не отвечают логическому содержанию этих понятий: в отношении статистической связи терминология «зависимости» вообще не применима.
Любые связи между общественными массовыми явлениями и процессами имеют две логических формы. Выделяют причинно – следственные (однонаправленные) и взаимодействующие (обоюдные) формы связи. Причинно – следственные связи предполагают, что одно массовое явление или процесс вызывает другое, и предшествует ему во времени. Например, рост числа высокооплачиваемых рабочих мест в Ленинградской области, вызванный ускоренным развитием в ней промышленности, в том числе автомобилестроения (завод «Форд»), при сохранении относительно не высоких цен на жильё (в сравнение с двумя первыми мегаполисами и Московской областью), - привел заметному повышению интенсивности и результативности межрегиональных прибытий в этот регион.
Взаимодействующие формы связи имеют место, когда изменение одного массового явления вызывает изменение другого массового явления, и наоборот, изменение второго явления вызывает изменение первого. Чем интенсивней миграционный обмен населением в регионе – тем выше в нем (при прочих равных условиях) доля миграционно - активного населения, и наоборот, чем выше в населении доля миграционно - активного населения, тем выше интенсивность миграционного обмена населением данного региона. Оба признака - взаимосвязаны логически, и являются друг для друга - и причиной и следствием.
Помимо выделения причинно – следственных и взаимодействующих форм связи, необходимо выделение форм выражения связи - функциональных и статистических. Довольно часто причинно-следственные связи отождествляют с функциональными связями, что не верно. Причина этого - не только путаница форм связи и конкретных форм ее выражений, но и уровней рассмотрения связей. Статистическая методология предполагает проведение анализа лишь на массовых явлениях и процессах, складывающихся из единичных случаев, событий, или значений единиц наблюдений. Именно рассмотрение связей на единичном уровне приводит к смешению и отождествлению понятий причинно-следственной и функциональной связи. Например, основной причиной переезда отдельного человека может являться «желание улучшить свои бытовые условия». В данном случае мы имеем и причинно – следственную связь, и ее конкретное, функциональное проявление - переезд по указанной причине. На массовом уровне рассмотрения функциональность любой, даже самой тесной причинно – следственной связи социально – экономических явлений ослабевает - она переходит в статистическую связь, т. е. связь, закономерную лишь в основной массе наблюдений.
Таким образом, форма связи и форма ее выражения - есть не одно и то же. Любая форма связи массового явления или процесса может быть описана лишь статистически. При этом обратной закономерности – нет: не любую статистически выявленную связь можно отождествить с той или иной формой связи. Статистическая связь, или если её более корректно назвать, взаимосвязь, или корреляция, - выявляет лишь взаимное изменение параметров, уровней различных признаков друг относительно друга, и не более того: «корреляция может указывать на возможную причинно-следственную связь. Но не объясняет ее. Знание о том, что два события коррелируют, не говорит нам ничего о причинности. Корреляция не доказывает наличие причинно-следственной связи» [6, с.47].
Взаимное статистическое изменение уровней различных факторов может происходить не только вследствие той или иной формы причинно-следственной связи между ними. Основным источником заблуждений, приводящим к отождествлению статистической связи логической, является действие других, более общих факторов, оказывающих однонаправленное логическое воздействие на рассматриваемые факторы.
Например, имеется умеренная взаимосвязь между двумя демографическими факторами - ожидаемой продолжительностью жизни при рождении и коэффициентами разводимости.
Прямую логическую связь между этими двумя факторами по общим данным установить проблематично, хотя между ними и имеется заметная статистическая взаимосвязь. Объяснение ей - логическая зависимость обоих факторов от общего более существенного фактора, описать который одним признаком невозможно. Этот фактор - уровень жизни и социально-экономического благополучия регионов. Чем выше уровень этого комплексного фактора - тем (при прочих равных условиях) выше уровень ожидаемой продолжительности жизни при рождении и тем ниже уровень разводимости. Вследствие этого воздействия, а также и вследствие зависимости уровня разводимости от других, также существенных факторов, таких, например, как преобладающий тип местности регионов или половозрастной состав населения регионов, - существует и заметная взаимосвязь между двумя производными факторами (см. рис.7 – более подробно об подобных графиках будет сказано в следующем пункте данной главы).
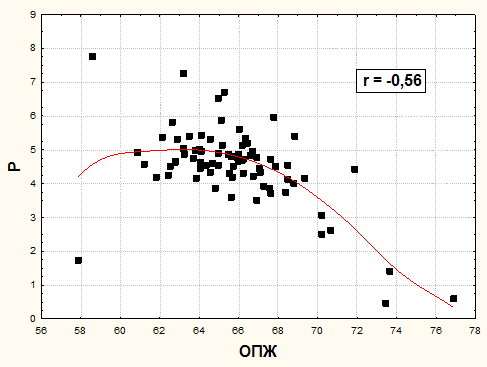
Рис.7. Взаимосвязь между ожидаемой продолжительностью жизни при рождении (ОПЖ, лет) и уровнем разводимости (Р, в промилле) по регионам России в среднем за гг.
Таким образом, при изучении взаимосвязи, можно выделить следующие группы факторов: 1) те, для которых результант является логическим следствием; 2) те, что являются логическими следствиями из результанта; 3) равно - взаимодействующие с результантом факторы.
Но помимо такого опосредованного воздействия, статистическая взаимосвязь различных факторов между собой может объясняться и иными обстоятельствами, среди которых особое место занимает специфика методики расчета и представления уровней изучаемых факторов. Необходимо в этой связи сделать одно принципиальное замечание. Оно касается форм выражения рядов показателей, соответствующих тем или иным факторам. Корректно сопоставимыми могут быть лишь те ряды значений факторов, которые отражают лишь отдельные (элементарные) свойства объекта изучения. Другими словами, если фактор выражен рядом агрегатных показателей, отражающих два или более свойства одновременно, то его использование в анализе может привести к снижению объективности выводов (предшествующий пример на рис.7 с продолжительностью предстоящей жизни при рождении и коэффициентами разводимости - яркое тому подтверждение).
Другой пример. Если в качестве результанта выступает ряд итоговых коэффициентов интенсивности выбытий регионов, то и в качестве факторов могут выступать лишь показатели в расчете на 1000 человек среднепериодной численности населения. Использование рядов других видов показателей, например, таких как суммарный коэффициент рождаемости, а также различных структурных показателей, таких как коэффициент трудовой нагрузки или коэффициент нагрузки пенсионерами, - не вполне корректно. Последние показатели рассчитываются исходя не из всей численности населения, а лишь из её части, или вообще с элиминированием численности населения, и величина этой части в различных регионах - далеко не одинакова. Сравнивая интенсивность выбытий в расчете на человека (1000 человек) с суммарным коэффициентом рождаемости в расчете на 1 женщину (или 1000 женщин), мы тем самым сравниваем показатель, аккумулирующий особенности половозрастной структуры, - с показателем, элиминирующим эти особенности. В результате чего «на выходе» имеем взаимосвязь не уровней двух явлений, а взаимосвязь функции от двух факторов - с другим фактором. Поэтому и сравнения таких рядов разнобазисных показателей - не всегда дают корректные результаты.
Цель работы по изучению факторов - это выявление среди них наиболее существенных, определение форм их взаимосвязи с результантами, тесноты, направления и других характеристик этих связей. Результаты такой работы позволяют не только выявить всю систему механизмов взаимодействия уровней результантов и их факторов, но и дают возможность выработать оптимальный механизм их регулирования, т. е. управления.
До начала любого анализа взаимосвязей исследователь имеет информацию о причинно – следственных связях, составляющих теорию той или иной науки. О наличии взаимосвязей между рассматриваемыми признаками, таким образом, исследователь может знать заранее, а может лишь предполагать - т. е. выдвигать гипотезу. Выбранные для анализа признаки могут быть явно или не явно взаимосвязанными с результантом. После предварительного анализа взаимосвязей этот вопрос частично выясняется. Этот анализ, прежде всего, сводится к рассмотрению связей между результантом и каждым из факторов, а также, между всеми факторами на парном уровне.
4.2. Парная статистическая связь.
На парном уровне рассмотрения предметом изучения в статистике являются следующие свойства связи. Во-первых, это мера тесноты, или силы статистической связи. Для случаев, когда ряды значений признаков распределены нормально, и форма связи между ними близка к линейной форме, т. е. может быть приблизительно описана с помощью уравнения Y = X*A+B, мера тесноты связи адекватно выражается с помощью коэффициента линейной корреляции r. Чем абсолютное значение (модуль) r выше, тем парная связь сильнее.
В зависимости от абсолютного значения r можно условно выделить следующие группы по силе связи:
│r│< 0,3 - связь слабая. На самом деле связь необходимо рассматривать более подробно уже при │r│≥ 0,2 . В ПСП ( Statistica Statsoft) в таблицах парных корреляций все коэффициенты r, абсолютное значение которых больше либо равно 0,2 - специально из-за этого выделяются красным цветом.
При 0,3 ≤│r │ < 0,5 связь считают умеренной,
При 0,5 ≤│r │ < 0,7 связь считают заметной,
При 0,7 ≤│r │ < 0,9 связь считают тесной,
При │r │ ≥ 0,9 связь считают близкой к функциональной (очень тесной).
Для коэффициента парной детерминации, равного r²=R², при парной связи его значение - есть доля описанной парной вариации, либо помноженный на 100 – ее процент (от всей парной вариации). По значениям вышеприведенной шкалы, например, при заметной связи будет описываться 25-49% вариации Y (от 0,5*0,5*100 до 0,7*0,7*100)%. Это будет означать, что 25-49% вариации результанта будет объясняться вариацией фактора, или так называемой «ковариацией» - совместной вариацией результанта и фактора.
Остаточный (до ста) процент, - есть не описанная данной связью вариация. Он показывает долю вариации, приходящейся на так называемые «случайные», или не раскрытые исследователем факторы. Использование этой доли актуально в случаях изучения связи одновременно по многим факторам либо в случаях оценивания связи по выборке.
Помимо тесноты связи статистика определяет направленность парной связи. Если с возрастанием значений фактора Х – значения результанта Y также возрастают - то связь называется прямой, если же с возрастанием Х – Y уменьшается, то – обратной. Коэффициент корреляции при прямой связи больше нуля, при обратной связи - меньше нуля.
Существенным в изучении парной связи является определение её формы. Для выяснения этого вопроса служат графики распределения единиц совокупности одновременно по двум признакам, называемые графиками рассеивания (scatter plots). По оси Х откладывают обычно значения факторного признака, по оси Y - результанта. Прямая, оптимально описывающая парную линейную связь, называется «линией регрессии». Обычный принцип ее поиска - метод наименьших квадратов - в качестве условия ее построения выдвигает минимизацию суммы квадратов отклонений всех индивидуальных значений (Xi, Yi) от прямой (под отклонениями подразумевают длины перпендикуляров с координат единиц совокупности на эту прямую). Пример такой прямой приведен на рис. 8.
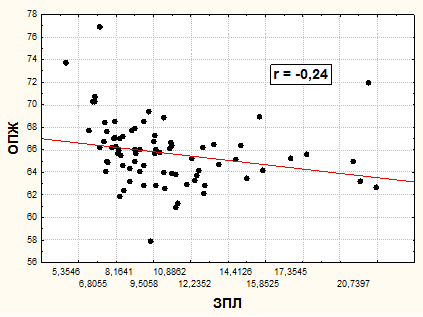
Рис. 8. Взаимосвязь заработной платы занятых в экономике (ЗПЛ), тыс. рублей в месяц, и ожидаемой продолжительности жизни при рождении (ОПЖ), лет, по регионам России, в среднем за гг.
Коэффициент линейной корреляции (r) близок к нулю. Но вывод об отсутствии связи на основании лишь такого анализа делать нельзя. Повторим, что этот коэффициент может быть корректно использован для описания силы связи лишь в случае, если форма связи близка к линейной и имеет однонаправленный вид. Поэтому вначале необходимо воспользоваться специальным методом выявления формы связи (определением тренда, или основной линии связи) - методом скользящей средней. В ПСП (Statistica StatSoft, SPSS) он представлен несколькими модификациями, наиболее гибкая из которых называется «Distance Weighted LS». Этот метод также широко используется и в прогнозировании и основан на сглаживании индивидуальных значений путем их замены на результаты усреднения с несколькими (обычно тремя – пятью) последующими значениями:
Предположим, имеем ряд значений факторного признака X1,X2,X3,X4,X5,X6,Xi….Xn и ряд значений результанта Y1,Y2,Y3,Yi…Yn.
Тогда значения нового ряда (из преобразованных методом скользящей средней значений) будут рассчитываться по следующим формулам:
Xcр1= (Х1+Х2+Х3+Х4+Х5)/5
Xcр2= (Х2+Х3+Х4+Х5+X6)/5
Xcр3= (Х3+Х4+Х5+Х6+Х7)/5
… и так далее ….
При этом Хср1 ставится на место Х3, Хср2 ставится на место Х4, и т. д.
Значения Yср i находятся аналогично. Шаг (в данном примере он равен 5) выбирается произвольно – в зависимости от размаха последовательных индивидуальных значений. Приведенный на рис. 8 график рассеивания с выявлением тренда формы связи будет выглядеть следующим образом (см. рис. 9). Из данного графика видно, что связь имеет не однонаправленную форму. Два участка связи, примерно до Х=12 и после - однонаправлены, из чего можно сделать вывод о том, что совокупность по данному парному распределению не однородна. Вследствие этого рассмотрение связи по всей совокупности не выявляет единой закономерности.
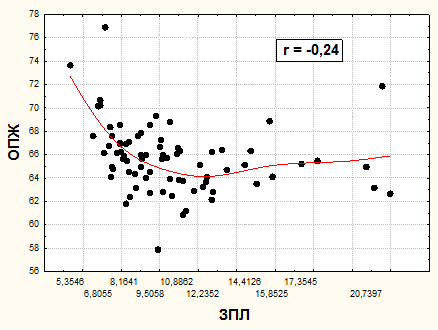
Рис. 9. Взаимосвязь заработной платы занятых в экономике (ЗПЛ), тыс. рублей в месяц, и ожидаемой продолжительности жизни при рождении (ОПЖ), лет, по регионам России, в среднем за гг.
Из-за подобной (чашеобразной) формы тренда коэффициент линейной корреляции близок к нулю, хотя заметная и противоположно направленная связь имеется на двух участках значений Х. При такой ситуации необходимо всю совокупность разделить на части и провести анализ связи раздельно, по отдельным однородным группам.
Данный пример подводит к еще одному важному выводу - обязательности проведения предварительного анализа распределений признаков. Если они распределены нормально, то проблем с выяснением тесноты связи нет. Если же хотя бы один из признаков распределен ненормально – это часто приводит к искажениям результатов выявления тесноты связи. Поясним примером.
Связь между условными признаками Х и Y по совокупности объёмом 80 единиц на первый взгляд сверхтесная и имеет следующий вид (см. рис.10).
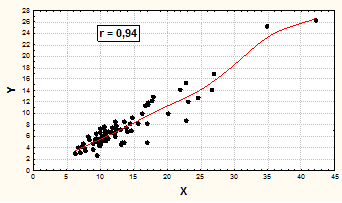
Рис.10. Взаимосвязь между признаками Х и Y, в усл. ед.
Но данная связь предопределяется положением двух групп значений - основной массы низких и двух крайне высоких, задающих угол наклона линии, служащей для расчета меры тесноты связи. Если, к примеру, два этих крайних значения Y заменить на средние по массиву, то теснота линейной связи резко сократится и форма скользящей средней изменится (см. рис.11).
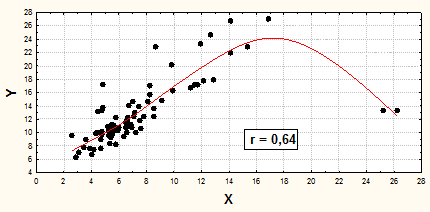
Рис.11. Взаимосвязь между признаками Х и Y, в усл. ед.
В данном случае результатами анализа тесноты связи пользоваться не корректно. Вначале необходимо рассмотреть распределения исходных признаков Х и Y (см. рис.12-13).
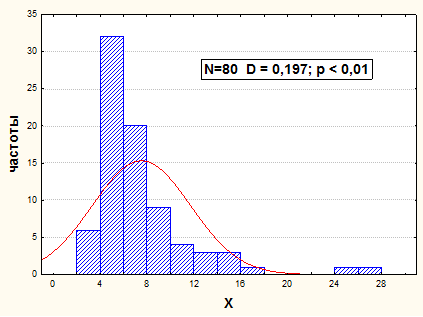
Рис.12. Гистограмма распределения значений Х, в усл. ед.
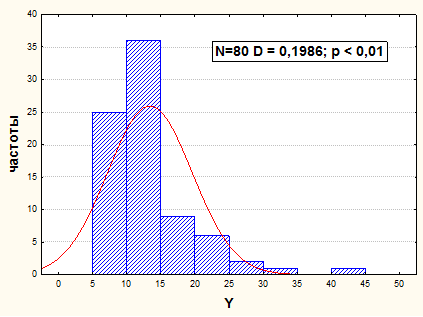
Рис.13. Гистограмма распределения значений Y, в усл. ед.
Оба распределения не имеют нормального вида. Они - логарифмически - нормальны. Привести их к удовлетворительно нормальной форме можно последовательным логарифмированием значений. После первого логарифмирования распределение значений ln Х становится удовлетворительно нормальным - D наблюдаемое равно 0,106, а D критическое при вероятности 95% равно 0,152 (см. рис.14).
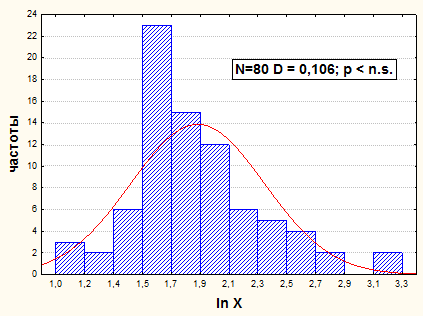
Рис.14. Гистограмма распределения значений ln Х.
Распределение значений Y приводится к удовлетворительно нормальному виду последовательным двойным логарифмированием. Распределение значений ln ln Y удовлетворительно нормально - D наблюдаемое равно 0,108, а D критическое при вероятности 95% равно 0,152 (см. рис.15).
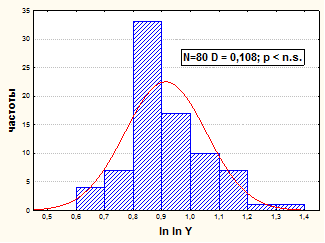
Рис.15. Гистограмма распределения значений ln ln Y.
Теперь связь между двумя рядами нормально распределенных преобразованных значений - ln Х и ln ln Y – будет иметь близкую к линейной форму. Она адекватно отражает тесноту связи между рассматриваемыми признаками (см. рис. 16).
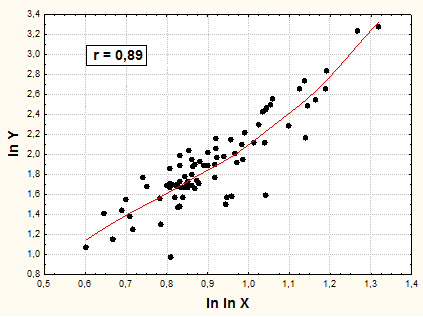
Рис.11. Взаимосвязь между признаками ln Х и ln ln Y.
При преобразовании значений Х или Y необходимо помнить, что конечная цель таких преобразований - максимально приблизить совместное распределение двух признаков к линейной форме, так как коэффициент корреляции показывает меру линейности связи, или, другими словами, ее близости к функциональной линейной связи.
4.3.Вопросы многофакторного анализа связи
Рассмотрев особенности парной связи, теперь можно выстроить алгоритм проведения анализа связи результанта одновременно с многими факторами. Вначале исследователь ставит перед собой задачу по поиску и установлению набора тесно взаимосвязанных с результантом факторов. О наличии логической и статистической связи с частью из них он знает «по предшествующему опыту», часть других отбирается им по предположению, «по гипотезе». После статистического анализа из второй части, возможно, остается несколько новых выявленных факторов, имеющих и логическую и статистическую связь с результантом. Они позволяют исследователю расширить теорию науки о результанте, найти новые пути воздействия на него и более обоснованно провести прогноз его изменений.
После сбора всей возможной информации об известных и новых факторах, проведения предварительного и описательного анализа каждого из них, исследователь приступает к анализу связей факторов с результантом.
Первым шагом такого анализа является построение таблицы парных корреляций, т. е. таблицы коэффициентов парных связей всех факторов, как с результантом, так и между собой. По этой таблице, во-первых, выявляется значимость силы парных связей всех факторов с результантом - чем больше по абсолютной величине значение r, тем фактор сильнее статистически связан с результантом. И, во-вторых, выявляется свойство мультиколлинеарности, т. е., тесной статистической связи между парами факторов. После более подробного рассмотрения парных связей те факторы, что имеют тесную мультиколлинеарную связь с другими и имеют при этом самую слабую связь с результантом - из анализа исключаются, так как они не только не усиливают тесноту связи факторов с результантом, но и искажают всю картину этой связи.
В анализе иногда возникают ситуации, когда группа факторов отражает некое сложное свойство, признак, о котором исследователь иногда даже и не подозревает. В статистике имеются специальные методы (факторный анализ - см. о нем, например, [16, с. 465-468]), позволяющие выделить новые факторы с помощью линейной функции от исходных факторов. В социально – экономической практике, тем не менее, задачи подобного рода решаются куда более простыми методами. Поэтому большинство сложных статистических методов имеет широкое применение лишь в естественных науках, биологии, археологии, палеонтологии, медицине, и т. п., а также в психологии. В социально – экономической жизни - если анализ и доходит до многомерных статистических методов - то довольно редко: обычно исследователю хватает информации и здравого смысла для объяснений сути явлений и процессов и без использования сложных и порой излишне формальных приемов анализа данных.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
