

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
После анализа таблиц парных корреляций и отбора части факторов из них - исследователь может рассчитать в ПСП множественный коэффициент линейной корреляции R. Суть его такая же, как и у парного. Его квадрат - R² (коэффициент детерминации) есть доля описываемой данной связью ковариации, т. е. изменения значений результанта во взаимосвязи с изменениями значений выбранной группы факторов. Остаток до единицы, или (1 - R²), - есть остаточная вариация, или доля ковариации со случайными (не раскрытыми исследователем) факторами.
Если анализ связи проводится по выборке, то соотношение остаточной вариации к коэффициенту детерминации, имеющее специфическое F-распределение, служит основой для расчетов критериев значимости для коэффициентов тесноты связи. При изучении связей по выборке минимальный объем последней в практике часто привязывают к количеству описываемых факторов. В [14], к примеру, советуют использовать, по крайней мере, от 10 до 20 единиц совокупности на каждый включенный в модель фактор.
4.4.Кластерный анализ.
Довольно часто в практической деятельности исследователь сталкивается с проблемами классификации сразу по многим признакам, выраженным в относительных шкалах измерений. Последовательность процедур такой многомерной группировки называется кластерным анализом. Итак, кластерный анализ – это алгоритм процедур по распределению единиц совокупности по группам (кластерам) одновременно по трем и более признакам, выраженным в относительных шкалах измерений. Строго говоря, путем кластерного анализа можно группировать всю совокупность и по двум признакам, несмотря на наличие для этой процедуры и более простых статистических приемов.
Кластерный анализ используется, когда обычная одномерная или двумерная группировка не работает, и выделить из нескольких признаков существенный не представляется возможным, или группировка не дает существенных различий в значениях других признаков. Кластерный анализ, как и любая группировка, - статистический метод со значительной долей субъективного подхода. Субъективность подхода наблюдается на всех этапах этого анализа, так как исследователь сам выбирает и пути группировки на всех этапах, и меры схожести или различий образуемых этим методом групп. Вследствие этой специфики статистическое оценивание к результатам кластерного анализа (если он проведен по результатам выборки) не применимо.
Алгоритм кластерного анализа включает объединение признаков в группы с использованием меры сходства (различия) между их значениями. Результатом такой кластеризации является выделение наиболее близких по определенному набору признаков групп единиц совокупности. Построение по ним так называемого «иерархического дерева» - есть графическая иллюстрация результатов кластеризации. Иерархическое дерево - это схема группировки всех единиц совокупности в зависимости от меры близости между ними по выбранным для анализа признакам. Первым звеном такой группировки является все отдельные единицы совокупности, последним - одна группа, состоящая из всех единиц совокупности. Все промежуточные звенья - группы, объединяющие несколько подгрупп предшествующего звена.
На первом этапе – объединении в группы единиц совокупности и на последующих этапах - объединении групп в более крупные группы - используются различные алгоритмы.
До начала процедур кластерного анализа необходимо провести предварительный описательный анализ и преобразования всех рядов значений признаков, отобранных для многомерной группировки.
Если значения признаков не распределены нормально, необходимо попытаться их привести к нормальному виду путем элементарных математических преобразований. В противном случае придется на последующих этапах анализа подбирать специфические методы объединения в группы, учитывающие особенности различий между подгруппами. Поэтому для использования самых простых методов объединения из всех имеющихся в арсенале статистической науки, необходимо подобное предварительное приведение распределений исходных значений признаков к нормальному виду.
После приведения рядов значений исходных признаков к нормальному виду необходимо также провести стандартизацию их величин. В некоторых учебниках по статистике (например, [14]) пишут, что это не обязательно. На наш взгляд, это необходимо, так как, объединяя по признакам, выраженным, например, в натуральных единицах измерения, рублях и километрах, мы объединяем несоизмеримые между собой разности признаков. Поэтому их нужно исходно перевести в безразмерный, стандартизированный вид. Кроме того, исходные величины могут различаться масштабом: например, быть в рублях или тысячах рублей, что не может не влиять на результаты кластеризации.
Таким образом, нормализация и стандартизация исходных значений признаков, отобранных для кластерного анализа, - необходимый этап предварительной работы по его корректному проведению.
На первом этапе группировки находят меру близости по нормализованным стандартизированным признакам между всеми единицами совокупности. Наиболее известный и общепризнанный метод вычисления расстояний между такими объектами состоит в вычислении так называемых евклидовых расстояний, т. е. геометрических расстояний в многомерном пространстве (в их основе лежит теорема Пифагора), вычисляемых по следующей формуле для двух любых единиц Х и Y совокупности:
Евклидово расстояние (Х, Y) = 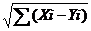 ²
²
Где i=1,k - признаки.
На первом шаге, таким образом, евклидово расстояние между объектами служит критерием меры сходства или различия, т. е. критерием отбора в группы второго шага кластерного анализа. Однако когда связываются вместе несколько подгрупп единиц совокупности на втором и последующих шагах, возникает вопрос, как следует определить расстояния между группами. Здесь имеется много различных вариантов поиска сходств, выбор каждого из которых предопределяется спецификой объекта изучения, видом представленных данных и другими особенностями. Среди наиболее известных путей - метод ближнего соседа. При нём кластеры объединяют по геометрическому расстоянию наиболее близких между собой двух единиц в двух кластерах. Помимо этого метода и его альтернативы – метода дальнего соседа, на наш взгляд, наилучшей «статистически объективной» формой обладает метод «взвешенного попарного среднего». В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. В результате расчета таких характеристик на втором этапе в зависимости от выбранной самим исследователем величины этой меры можно объединить кластеры в более крупные группы. На дальнейших этапах метод объединения остается аналогичным, и кластеризация осуществляется до тех пор, пока не создается ситуация, при которой все полученные кластеры можно объединить лишь в один – т. е. во всю совокупность. В зависимости от того, сколько групп нужно выделить исследователю или от выбранной им меры сходств, «на выходе» получается разделенная на кластеры совокупность, каждая из подгрупп которой содержит наиболее близкие между собой по выбранному набору признаков единицы.
4.5. Индексный метод анализа
В статистике индексами называют показатели относительного сравнения уровней явлений (значений признаков), а также комбинации из них (например, рейтинг – «индекс развития человеческого потенциала», ИЧПР). В форме индексов между собой могут сравниваться уровни: 1) одного и того же явления во времени, 2) различных явлений в пространстве, 3) различных явлений с условным уровнем (средним, максимальным значением, либо моделью). Классическое определение индексов, сохранившееся в некоторых современных учебниках по статистике с середины прошлого века, - более узкое. Согласно этому определению, «Индекс в статистике - это, как правило, обобщающий показатель сравнения общественно-экономических явлений, состоящих из элементов, непосредственно не поддающихся суммированию» (Струмилин с.207). Индексы, получаемые таким путём, называются «агрегатными». Именно они требуют отдельного рассмотрения в курсе теории статистики вследствие их широкого применения в социально-экономическом и демографическом анализе, а также сложности их строения.
Суть агрегатных индексов и индексного метода в наиболее доступной форме объясняется по ценам на различные товары (признак p) и по их количествам (признак q), проданным за два различных периода времени – базисный (po, qo) и отчетный, или текущий (p1, q1). Приравнивая все виды товаров через стоимость перемножением цен на количества, сложением получают товарооборот (Q) по каждому из двух периодов. По базисному периоду он равен:
Qo = ∑ po* qo.
По отчётному периоду товарооборот равен:
Q1 = ∑ p1 * q1.
Отношение товарооборота отчетного периода к товарообороту базисного периода – дает агрегатный индекс общего изменения товарооборота («индекс переменного состава») между двумя периодами:
I q p = ∑ p1 * q1 / ∑ po* qo.
Абсолютная величина общего изменения товарооборота равна разнице:
∆ I q p = ∑ p1 * q1 - ∑ po* qo.
Далее индекс общего изменения товарооборота раскладывают на две части – «индексы фиксированного состава» - индексы изменения цен при неизменных количествах товара и индексы изменения количеств товара при неизменных ценах. В зависимости от того, какой из двух периодов берётся при этом в качестве неизменного, возможны два варианта расчетов. Первый вариант, при котором взвешивание цен идет по количествам базисного периода, имеет форму:
Ipo = ∑ p1 * qo / ∑ po* qo
- индекс цен (Ласпейреса), показывающий как изменился бы товарооборот, если бы количества проданного товара оставались бы на уровне базисного периода. Этот индекс характеризует среднее изменение цен по совокупности проданных товаров относительно базисного периода, так как его можно представить как соотношение двух средних цен:
Ipo = { ∑ p1 * qo / ∑ qo} / { ∑ po* qo / ∑ qo }.
Абсолютная величина изменения товарооборота лишь за счет роста цен равна разнице:
∆ Ip o = ∑ p1 * qo - ∑ po* qo.
Второй вариант, при котором взвешивание цен идет по количествам отчетного периода, имеет форму:
Ip1 = ∑ p1 * q1 / ∑ po* q1
- индекс цен (Пааше), показывающий как изменился бы товарооборот, если бы количества проданного товара были бы на уровне отчетного периода. Этот индекс также характеризует среднее изменение цен по совокупности проданных товаров, но относительно отчетного периода. Аналогично анализируют и вклад изменения структур, или количеств (физического объёма) товара на изменение товарооборота. Цены фиксируются на уровне базисного, либо отчетного периода:
I q o = ∑ po * q1 / ∑ po* qo или
I q 1 = ∑ p1 * q1 / ∑ p1* qo
– индексы физического объёма. Если количества (q) перевести в доли (d), то имеем:
I q o = ∑ po * d1 / ∑ po* d o или
I q 1 = ∑ p1 * d 1 / ∑ p1* d o
-- индексы структуры.
Где: d o= qo / ∑ q o d1 = q1 / ∑ q1
Оба вида агрегатных индексов физического объёма (либо структуры) показывают, как изменился бы товарооборот, если бы цены проданного товара оставались на одном уровне (базисного или отчетного периода). Далее произведением связывают между собой индексы двух групп - цен и физического объёма:
I q p = I q1 * Ipо = Ip1 * I q о
∑ p1 * q1 / ∑ po* qo =
= { ∑ p1 * q1 / ∑ p1* qo}*{ ∑ p1 * qo / ∑ po* qo} =
= { ∑ p1 * q1 / ∑ po* q1}* { ∑ po * q1 / ∑ po* qo }
Таким образом, общее относительное изменение товарооборота складывается из произведения двух относительных изменений - цен и физического объёма, построенных, правда, по различным периодам. Подобное индексное разложение целого на две части иногда называют «факторным индексным анализом», подразумевая, что общее изменение товарооборота происходит под воздействием двух факторов - цен и физического объёма. Не следует путать данную терминологию с другой, так как в теории статистики термин «факторный» употребляется довольно часто (например, имеется и собственно «факторный анализ», и дисперсионный одно и двухфакторный анализ).
Для конкретных задач сравнительного анализа, особенно, если сравниваемых совокупностей не две, а много, или если сравнение идет не в динамике, а в пространстве, могут потребоваться варианты замены реальных постоянных весов в агрегатных индексах цен или физического объема на условные веса, общие для всех сравниваемых совокупностей. В качестве этих весов могут выступать либо средние значения из фиксируемых величин (например, (p1 + po)/2 или √ [p1* po] ), либо искусственно вводимые величины. Во всех случаях индексный метод позволяет выделить из общего изменения совокупного значения признака - изменение вследствие действия лишь одной из двух составляющих - при неизменной другой.
Подойдём к вопросу построения агрегатных индексов с другой стороны, не от практики их непосредственного использования в анализе динамики товарооборота и его составляющих, а от методики анализа отдельных признаков совокупности в разрезе существенных свойств. Если сопоставляемые совокупные значения признака представить рядами отдельных значений в разрезе какого-либо свойства и рядами соответствующих им частот (или частостей), то по этим двум рядам можно построить аналогичные индексам цен и физического объема агрегатные, или двумерные индексы. Одно измерение будет представлено рядом значений, второе - рядом частот. Например, в демографии общий коэффициент смертности (m), показывающий, сколько умерло человек на каждую тысячу средней за рассматриваемый период численности постоянного населения, можно рассмотреть в разрезе существенного свойства - пола-возраста [3] населения. В этом случае общий коэффициент смертности будет представлять собой сумму произведений половозрастных коэффициентов смертности (mj), на доли половозрастных групп населения (dj):
m = ∑ mj * dj
Сопоставляя две совокупности во времени либо в пространстве по общему уровню смертности, например, пользуясь для простоты восприятия той же терминологией двух периодов времени, - mo и m1, можно выделить две меры различий. Первая - будет вследствие разницы уровней рядов половозрастных коэффициентов (moj и m1j). Вторая - вследствие различий половозрастных структур сравниваемых совокупностей (doj и d1j). Так как любое парное сравнение относительно одного из двух сравниваемых, то будем иметь, как и в случае с индексами цен и физического объёма, два варианта агрегатных индексов:
∑ m1j * d1j /∑ moj * doj =
={∑ m1j * d1j / ∑ moj * d1j*{ ∑ moj * d1j / ∑ moj * doj } =
={∑ m1j * d1j / ∑ m1j * doj}*{∑ m1j * doj / ∑ moj * doj }.
При этом индексы
∑ m1j * d1j / ∑ moj * d1j и
∑ m1j * doj / ∑ moj * doj
– будут отражать меру изменения общего коэффициента смертности лишь за счет изменения половозрастных уровней смертности, а индексы
∑ moj * d1j / ∑ moj * doj и
∑ m1j * d1j / ∑ m1j * doj
– меру изменения общего коэффициента смертности лишь за счет изменения половозрастной структуры населения между периодами.
Сопоставляя в половозрастном разрезе общие уровни смертности нескольких совокупностей в пространстве (например, различных государств или регионов одной страны), в качестве весов структуры населения может выступать как средняя арифметическая из весов всех участвующих в сравнении территорий, так и некий общепринятый стандарт. Этим стандартом в межгосударственных сравнениях могут служить модели европейской или мировой структуры стабильного населения, предлагаемые с 70-х гг. XX века Всемирной организацией здравоохранения (ВОЗ). Рассчитанные по такому пути итоговые коэффициенты смертности называются стандартизированными «прямым методом». Они отражают итоговые различия лишь в половозрастных уровнях смертности сравниваемых территорий (общие коэффициенты смертности, в отличие от стандартизированных показателей, выявляют совокупный эффект различий половозрастных уровней смертности и половозрастных структур населения).
Стандартизацию также можно провести по половозрастным коэффициентам смертности, т. е. вторым, или «косвенным методом», взяв в качестве стандартов средние уровни половозрастных коэффициентов смертности по группе сравниваемых территорий, либо некие стандарты. Выявленные таким путём различия итоговых стандартизированных коэффициентов смертности будут объясняться лишь различиями половозрастных структур населения сравниваемых территорий. Данный приём используется не только при сравнениях, но и для восстановления половозрастной структуры населения, в частности, в ретроспективном анализе.
Выбирая веса для любой стандартизации необходимо помнить, что идеального стандарта не существует. Поэтому выбор стандартов - субъективный момент в исследовании, предопределяющий результаты сравнений и выводов. Максимально обоснованный выбор весов для стандартизации повышает объективность результатов исследования. Пользоваться отвлеченными стандартами необходимо лишь в случае крайней необходимости - когда средние веса для этой цели подойти не могут. Сравнивая между собой, например, регионы России, использовать европейские или мировые стандарты - нет нужды. Для этой цели более подходят средние взвешенные показатели, либо по стране в целом, либо по группе сравниваемых между собой регионов.
Попытки создать универсальные агрегатные индексы (например, идеальный индекс Фишера, представляющий собой среднюю геометрическую из двух индексов физического объёма, Iq1 и Iq о) - введение формальных, субъективных условностей, еще менее допустимых, чем стандартизация по отдельным весам. Любой сравнительный анализ относителен, а даже сравнение двух показателей имеет два уровня относительности результатов (относительно первого и относительно второго из двух сравниваемых). Поэтому любые попытки формализовать индексный метод анализа - снижают объективность получаемых с его помощью выводов.
4.6. Анализ временных рядов
Совокупность значений одного и того же явления в различные моменты или периоды времени называют временным, или динамическим рядом, а её элементы, или отдельные значения, - уровнями ряда. Любой динамический ряд можно представить, с одной стороны, в виде динамической совокупности, с другой стороны, - в виде взаимосвязи двух признаков - факторов, один из которых - время. Например, если мы изучаем динамику численности населения России, то с одной стороны динамический имеет вид диаграммы (см. рис. 17).
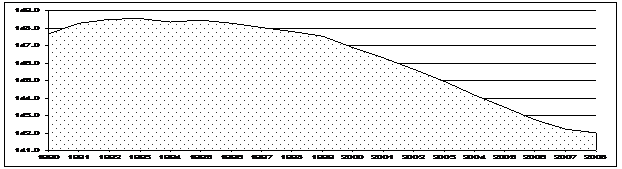
Рис 17. Динамика численности населения России по данным Росстата (млн. человек).
С другой стороны этот же динамический ряд можно представить в виде графика рассеивания двух признаков (см. рис. 18).
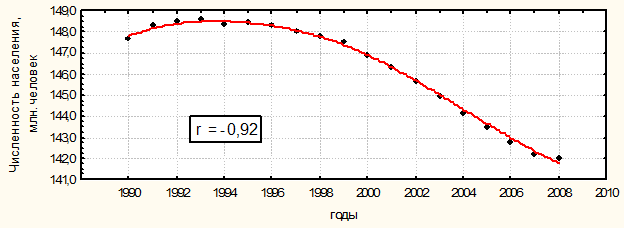 Рис 18. Динамика численности населения России по данным Росстата.
Рис 18. Динамика численности населения России по данным Росстата.
Линия, полученная на рис. 18 методом «скользящей средней» - тренд изменения явления во времени, или основная тенденция развития.
Такая «двойственная» природа динамических рядов предопределяет специфику их изучения, отличную от анализа обычных (не динамических) статистических совокупностей. Рассмотрим вначале формы представления элементов динамического ряда. Уровни динамического ряда могут относиться как к определенным моментам времени (моментный ряд), так и к определенным периодам времени (интервальный ряд). Например, численность населения России на 1 января по годам - моментный ряд, числа всех родившихся по годам - интервальный ряд. Уровни интервальных рядов, таким образом, представляют собой результаты определенных процессов за интервалы времени. В отличие от моментных рядов, их можно суммировать между собой, образуя кумулятивные значения за объединённые периоды времени. Не всегда бывает очевидным, к какому временному ряду, моментному или интервальному, относятся те или иные показатели. Например, среднегодовая численность населения России по годам, хоть и относится к интервалам времени длиною год, интервальным уровнем временного ряда не является: во всех расчетах данный показатель представляется как серединное значение года.
Моменты времени в моментных динамических рядах могут фиксироваться, либо через равные промежутки времени (например, ежегодная численность населения России на 01 января 2001, 2002, 2003, 2004, 2006, 2007, 2008, 2009 гг.), либо через различные промежутки времени (например, численность населения России на моменты послевоенных переписей 1959, 1970, 1979, 1989, 2002 гг.).
Интервалы времени в интервальных динамических рядах также могут быть равные по продолжительности и не равные. Более того, интервальные уровни могут идти последовательно – один за другим, а могут иметь между собой разрывы во времени, причем не всегда равной длины. Пример ряда динамики с равными по продолжительности уровнями, но не равными интервалами между ними показан ниже (см. таблицу 8).
Таблица 8.
ПРОДАНО ЖИЛЫХ ПОМЕЩЕНИЙ В ДОМАХ ГОСУДАРСТВЕННОГО, МУНИЦИПАЛЬНОГО И ДРУГИХ ФОРМ СОБСТВЕННОСТИ ЖИЛИЩНОГО ФОНДА ГРАЖДАНАМ И ЮРИДИЧЕСКИМ ЛИЦАМ
1993 | 1995 | 2000 | 2003 | 2004 | 2005 | 2006 | 2007 | |
Число проданных жилых помещений | 8610 | 26483 | 44766 | 36925 | 36641 | 39033 | 35014 | 33196 |
Общая площадь проданных жилых помещений, тыс. м2 | 481 | 1359 | 2920 | 2767 | 2647 | 2722 | 2717 | 2651 |
Особенности представления данных во временных рядах, а также различная форма самих показателей, характеризующих отдельные уровни ряда (это могут быть, как абсолютные, так и относительные, а также средние показатели), предопределяют специфику отдельных шагов исследования динамики.
Анализ динамических рядов сводится к решению двух основных последовательных задач. Первая задача - это анализ ситуации, т. е. имеющейся в распоряжении исследователя совокупности временных уровней явления. Она включает определение корректности сопоставимости между собой всех уровней ряда, расчет их среднего (или серединного, или типичного) уровня, темпов изменения уровней, выявление основной тенденции (тренда) изменения, наличия (либо отсутствия) в нём сезонности, автокорреляции (взаимосвязи между уровнями ряда с определенным лагом запаздывания), а также возможного выделения данных компонент из тренда. Вторая задача – экстраполяция, т. е. построение перспективного (в будущее), ретроспективного (в прошлое) продолжения временного ряда по тренду, либо восстановление пропущенных значений ряда на основе всей имеющейся в распоряжении исследователя информации.
Чем длиннее исходные временные ряды, тем (при прочих равных условиях) точнее прогноз. При этом надо помнить, что построение прогнозов лишь по трендам - условный и достаточно формальный приём анализа. Тем не менее, даже самый обоснованный расчет, построенный по взаимосвязям изучаемого явления с существенными факторами, с использованием социологических опросов и всей имеющейся необходимой информации - не может обойтись без компонент простого (по трендам) прогнозирования отдельных составляющих этот прогноз элементов. Любое продолжение выявленного тренда - условность, допущение о сохранении (либо предполагаемом изменении) сложившейся в имеющемся временном ряду тенденции. Общая ситуация или воздействующие на неё компоненты могут со временем меняться, и прогнозирование лишь по тренду - тем менее эффективно, - чем на более длительный срок делается прогноз.
Рассмотрим первую задачу - анализ ситуации, или исходной динамической совокупности. До начала любых расчетов необходимо выяснить, сопоставимы ли между собой все уровни временного ряда, т. е. выражены ли они в одних и тех же единицах измерения, по одной и той же методике ли построены, и т. п. Если сопоставлять все уровни ряда между собой не корректно, то исследователь пытается привести все уровни к такому виду, в котором дальнейшие сравнения могут проводиться корректно.
Первая вспомогательная подзадача - расчет обобщающего показателя - среднего уровня ряда. В зависимости от вида представляемых уровней ряда она решается по-разному. Так, если ряд представлен N моментными равноотстоящими уровнями (ежегодная численность населения России (Si) на 01 января 2000, 2001, …….., 2008, 2009 гг., N = 10), то средний уровень такого ряда рассчитывается как средняя хронологическая величина (S ср. хрон.). В случае временного ряда средняя величина рассчитывается по всему рассматриваемому периоду, а он в данном примере имеет границы с 01.01.2000 по 01.01.2009, и для расчета общей за весь период средней - вначале находят средние арифметические по каждому отдельному внутреннему периоду между всеми датами:
Sср. хрон. = {(S1 + S2) / 2 + (S2 + S3)/2 + …….+(SN-1+ +SN) /2} / (N-1) =
= {(S2000 /2 + S2001 + S2002 + …+ S2007 + S2008 + +S2009)/2} / 9
Если ряд представлен N моментными не равноотстоящими уровнями, то при расчете средней хронологической необходимо частные средние взвешивать на длины их интервалов. Например, если ряд моментных данных о численности населения региона (Si) представлен лишь на 01.01. по годам: [199], то расчет средней хронологической будет иметь вид:
Sср. хрон. = [(S1990 + S1995)/2}*5 +{(S1995 + +S1998)/2}*3 + (S1998 + S1999)/2]/ 9
Если ряд представлен интервальными данными, то расчет средней ведется по формуле арифметической взвешенной величины.
Но далеко не во всех случаях обобщающим уровнем, характеризующим тот или иной динамический ряд, будет являться средняя арифметическая или хронологическая величина. Её использование в качестве параметра уровня ряда возможно лишь тогда, когда тренд (основная тенденция изменения) ряда близка по форме к прямой линии. Если же она имеет другой однонаправленно изменяющийся вид, то для расчета обобщающего параметра уровня ряда требуется вначале привести путём арифметических преобразований все уровни к такому виду, чтобы тренд был максимально близким к прямой линии, и лишь по преобразованным значениям рассчитывать среднюю арифметическую величину.
* * *
Когда статистический анализ проведен, перед исследователем встает ответственная задача – донести его результаты в доступной для предполагаемых пользователей форме. Тот набор терминов и методов, что был помощником в статистическом анализе - становится порой преградой в общении с конечным потребителем результатов научной деятельности - типичными представителями основной части населения страны, руководителями всех звеньев власти и предпринимателями. В этой связи необходимо подчеркнуть, что язык анализа и язык интерпретации его результатов для практических потребителей - должны различаться. Первый должен быть строгим и методологически корректным, второй - по возможности более простым и понятным статистически не подготовленному потребителю результатов прикладного исследования.
II. Учебно-методическое обеспечение курса
Литература.
1. Общая теория статистики, под ред. и 5-е изд., М., Финансы и статистика, 2004.
2. Общая теория статистики, под ред. , . 5-е изд., Москва, Финансы и статистика, 2003 г.
3. Основы прикладной социологии, Под ред. и , Москва, «Академия», 1995 г.
4. Пасхавер величины в статистике, Москва, Статистика,1979 г.
5. Практическая бизнес-статистика, Сигел 4-е издание, Изд. дом «Вильямс», 2002 г.
6. Психология, Минск, Попурри, 2001 г.
7. Социология, под ред. , издательство РАГС, Москва, 2004.
8. Статистика, коллектив авторов под рук. акад. , Финансы и статистика, Москва, 1969 г.
9. Статистика, под ред. , Москва, издательство РАГС, 2005 г.
10. Статистика: социологические и маркетинговые исследования, Дж. Хили, 6-е изд., изд-во «ДиаСофтЮП», СПб, Питер, 2005 г. (В 2007 г. вышло 7-е изд.).
11. StatSoft, Inc. (2001). Электронный учебник по статистике. StatSoft. WEB: http://www. *****/home/textbook/default. htm.
12. Статистика, под ред. , Экономистъ, М., 2006 г.
УЧЕБНО-ТЕМАТИЧЕСКИЙ План
№ | Темы занятий | Всего часов | Аудиторные занятия (час), в том числе | Самостоятельная работа | |
Лекции | Семинары и т. п. | ||||
1 | Роль статистики в современной жизни. Статистическая методология. Основные категории. Шкалы измерений. Система статистических показателей. | 8 | 2 | 2 | 4 |
2 | Сбор и предварительный анализ статистической информации | 10 | 2 | 2 | 6 |
3 | Характеристики статистической совокупности. | 12 | 2 | 2 | 8 |
4 | Выборочный метод в статистических исследованиях. | 16 | 4 | 4 | 8 |
5 | Характеристики статистической связи. Кластерный анализ. | 16 | 4 | 4 | 8 |
6 | Индексный метод. Анализ временных рядов. | 12 | 2 | 2 | 8 |
7 | Подготовка реферата и к зачету | 26 | 0 | 0 | 26 |
8 | И Т О Г О | 100 | 16 | 16 | 68 |

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
