

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Мужчины | Женщины | ||
Высокий рост | 21 | 7 | 28 |
Низкий рост | 3 | 26 | 29 |
24 | 33 | 57 |
Степень свободы таблицы 2 ![]() :
:
Ст. своб.=(n-1)(m-1)=1
Уровень значимости - 5%
α1=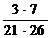 =0,038
=0,038
Данное отклонение от единицы значительно и составляет 0,962, что показывает: явления связаны, между ними наблюдается существенная связь.
2. Составим таблицу из ожидаемых признаков (Оi):
Мужчины | Женщины | ||
Высокий рост | 12 | 16 | 28 |
Низкий рост | 12 | 17 | 29 |
24 | 33 | 57 |
α=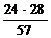 =12
=12
Высчитаем перекрестное значение α2:
α2=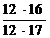 =0,941
=0,941![]()
3. Высчитаем хи-квадрат:
x2=![]()
x2=![]()
При 5% уровне значимости и 1 степени свод x2=3,8415
Найденный x2=23,32>3,8415, что показывает существенную связь наблюдаемых признаков.
Вывод: на основании проведенного исследования я могу утверждать, что выдвинутая мной гипотеза подтвердилась. Действительно рост от 175 см сантиметров и выше гораздо чаще встречается у мужчин, чем у женщин.
Проект по статистике.
Выполнили: студентки 305 группы
Глазовская Екатерина
Лукина Екатерина
Цели и задачи исследования, их эволюция.Целью предлагаемого исследования является проверка гипотезы о том, что
люди, родившиеся в весенне-летний период, любят апельсины больше остальных.
По нашему мнению, этот феномен связан со спецификой их внутриутробного развития: оно происходило преимущественно в осенние и зимние месяцы на фоне дефицита витаминов в организме матери.
Задачи:
1) сбор статистических данных;
2) обработка полученных данных (составление таблицы);
3) анализ данных таблицы (используя формулы вычисления перекрестного отношения и степени свободы);
4) выводы (интуитивный и на основе полученных вычислений), их сравнение.
Эволюция:
На начальном этапе работы нами предполагалось производить группировку опрашиваемых на основе месяца их рождения. Однако, по мере продвижения исследования, этот метод показал свою непродуктивность в силу недостаточно большого объема полученных данных. В результате было решено объединить месяцы в соответствующие сезоны, а затем в два периода: теплый и холодный. Это позволило нам получить более четкие и убедительные данные, а также существенно облегчило их анализ.
Методика сбора данных.При сборе данных мы использовали методику фронтального и дистантного (интернет) опроса. Выделим преимущества и недостатки каждого способа.
Преимущества | Недостатки |
Фронтальный опрос | |
1. Оперативность: данные получаются непосредственно в момент опроса | 1. Достаточно малое количество опрошенных |
2. Высокая степень объективности данных | 2. Невозможность дальнейшей корректировки и уточнения данных |
Дистантный опрос | |
1. Возможность получения большого числа данных | 1. Отдаленность результатов во времени |
2. Удобство сбора данных | 2. Существенная степень действия субъективного фактора: некоторое влияние предыдущих результатов на последующие |
3. Возможность последующего уточнения информации в случае необходимости | 3. Опасность потери полученных данных или возможности их дальнейшего сбора в результате технических причин |
Используя преимущества двух этих способов и взаимно компенсируя их недостатки, мы добились оптимизации процесса исследования.

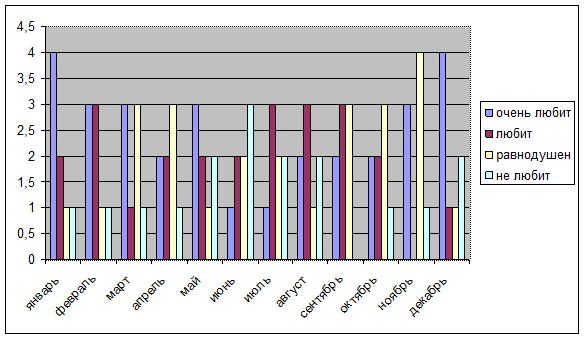 |
Таблица № 1
Для объективности результатов мы опросили одинаковое количество человек (по 8; всего опрошенных - 96), родившихся в каждом месяце. Из предварительного анализа данных таблицы и графика мы может сделать заключение о том, что наша теория не подтверждается, т. к. самые высокие показатели «очень любит» мы видим в январе и феврале, а самые низкие – в июне и июле.
Показатель «любит» - ведет себя несколько бессистемно и принимает самые высокие значения в июле августе и сентябре, что отчасти подтверждает нашу теорию, но в совокупности с первым критерием является нелогичным.
Также представляется странным резкий скачок показателя «равнодушен» в ноябре к показателю «очень любит» в декабре.
Показатель «не любит» также полностью противоречит нашей теории, т. к. принимает самые высокие значения в летних месяцах. Таким образом, исходя из результатов первый таблицы, мы не можем подтвердить нашу теорию.
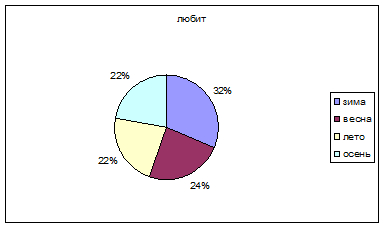 Таблица № 2
Таблица № 2
любит | не любит | |
зима | 17 | 7 |
весна | 13 | 11 |
лето | 12 | 12 |
осень | 12 | 12 |
В данной таблице мы объединили месяца в сезоны, а критерии оценки в «любит» и «не любит». Таким образом, согласно данным таблицы и диаграмме, наша теория диаметрально противоположна получившимся результатам – большинство опрошенных (32%), родившихся зимой любят апельсины. Остальные проценты распределились примерно поровну: весна – 24%, лето и осень – по 22%.
Таблица № 3 (а)
Наблюдаемые значения (Н)
Любит | Не любит | |
Холодное время | 29 | 19 |
Теплое время | 25 | 23 |
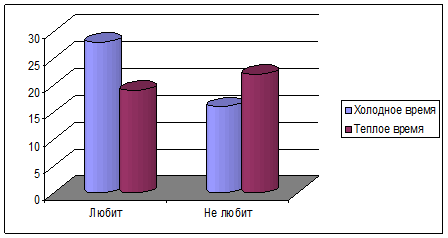
На третьем этапе исследования мы упростили таблицу ещё больше и свели ее содержимое к таблице 2*2, что позволило нам провести следующие вычисления:
1. Вычисляем ожидаемые значения.
Таблица № 3 (б)
Ожидаемые значения (О)
Любит | Не любит | |
Холодное время | 27 | 21 |
Теплое время | 27 | 21 |
Эти значения мы получили согласно формуле: сумма значений строки * сумма значений столбца
общее количество опрошенных
2. Вычисляем χ² по формуле:
χ²=∑(Н-О)²/О
Используя Excel, получаем χ²=0,410536
3. Вычисляем степень свободы по формуле: (n-1)(m-1), где n – количество строк, а m – количество столбцов.
(2-1)(2-1)=1
Получаем: степень свободы = 1
(ДА, ВЫВОД О СВЯЗИ НЕ ПОДТВЕРЖДАЕТСЯ ДАННЫМИ ПРИ 5% у. з.)
Завершающая работа по курсу «Статистика».
Тема: выявление зависимости между частотой употребления определенных согласных в лирических произведениях от темы этих произведений.
(На примере лирики .)
Выполнили: студентки 305 группы филологического факультета МПГУ
Городишенина Юлия и Юсуфова Алият.
2009
1. Вступление.
При разборе лирических произведений филолог обязан обращать внимание на фонетический строй текста, так как считается, что сочетания и повторения определенных звуков помогают поэту передать определенное настроение, погрузить читателя в мир своего творения. Поэтому нами была выдвинута
гипотеза о зависимости частоты использования определенных согласных от темы произведения.
2. Ход работы.
Для чистоты эксперимента мы выбрали произведения одного автора – . Были случайным образом отобраны два произведения гражданской лирики автора (см. приложение 1 и приложение 2) и два – любовной лирики (см. приложение 3 и приложение 4). Были сделаны фонетические транскрипции данных стихотворений и в них подсчитано количество каждого согласного звука (для простоты аккомодация[1] не учитывалась). Были получены следующие результаты:
1 | 2 | 3 | 4 | |
б | 6 | 8 | 4 | 3 |
б' | 6 | 0 | 3 | 4 |
в | 9 | 7 | 10 | 12 |
в' | 7 | 4 | 3 | 2 |
г | 11 | 4 | 1 | 4 |
г' | 0 | 1 | 1 | 0 |
д | 17 | 8 | 4 | 4 |
д' | 9 | 1 | 2 | 5 |
ж | 8 | 3 | 8 | 3 |
ж' | 0 | 0 | 0 | 0 |
з | 7 | 5 | 3 | 5 |
з' | 1 | 0 | 0 | 1 |
j | 13 | 10 | 24 | 12 |
к | 15 | 4 | 8 | 11 |
к' | 2 | 0 | 2 | 0 |
л | 14 | 3 | 5 | 5 |
л' | 17 | 2 | 8 | 8 |
м | 19 | 3 | 8 | 6 |
м' | 4 | 1 | 2 | 3 |
н | 31 | 13 | 13 | 8 |
н' | 13 | 7 | 14 | 6 |
п | 16 | 9 | 6 | 4 |
п' | 1 | 0 | 3 | 0 |
р | 24 | 17 | 8 | 10 |
р' | 7 | 2 | 5 | 3 |
с | 29 | 8 | 10 | 11 |
с' | 7 | 3 | 4 | 5 |
т | 19 | 9 | 18 | 17 |
т' | 5 | 4 | 3 | 2 |
ф | 10 | 1 | 5 | 2 |
ф' | 0 | 0 | 1 | 0 |
х | 5 | 1 | 3 | 2 |
х' | 1 | 0 | 0 | 0 |
ц | 2 | 0 | 2 | 1 |
ч' | 6 | 3 | 4 | 6 |
ш | 9 | 2 | 6 | 3 |
ш' | 2 | 2 | 4 | 2 |
Цифрами 1, 2, 3 и 4 в шапке таблицы обозначаются стихотворения, находящиеся в приложениях.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
