
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Во-вторых, одна величина s вне сравнения со средней величиной ![]() не даст еще правильной оценки рассеяния. Ведь две различные статистические совокупности могут иметь одно и то же значение s при различных средних
не даст еще правильной оценки рассеяния. Ведь две различные статистические совокупности могут иметь одно и то же значение s при различных средних ![]() и
и ![]() . Очевидно, если
. Очевидно, если ![]() <
< ![]() , то при одном и том же s варианты первой совокупности более рассеяны относительно средней, чем второй.
, то при одном и том же s варианты первой совокупности более рассеяны относительно средней, чем второй.
Пример 10.20. Пусть ![]() = 10 г и
= 10 г и ![]() = 100 г, а s = 2 г. По отношению к
= 100 г, а s = 2 г. По отношению к ![]() = 10 г величина s = 2 г составляет 20%, а по отношению к
= 10 г величина s = 2 г составляет 20%, а по отношению к ![]() = 100 г - лишь 2%.
= 100 г - лишь 2%.
Истинное положение с рассеянием может быть выявлено лишь с помощью отношения s и ![]() , которое называется коэффициентом вариации.
, которое называется коэффициентом вариации.
Коэффициент вариации
Коэффициентом вариации u называется отношение среднего квадратического отклонения к средней величине, выраженное в процентах.
В работах по математической статистике, связанных с текстильным производством, коэффициент вариации иногда обозначают буквой С.
Итак, 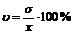
Пример 10.21 Найти коэффициенты вариации при тех же данных, что и в примерах 10.17 и 10.18.
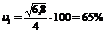 ;
; 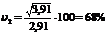
Коэффициентом вариации в качестве меры рассеяния не рекомендуется пользоваться, когда варианты колеблются около нуля. В этом случае s и ![]() близки к нулю, и незначительное изменение того или другого может привести к резкому изменению коэффициента вариации u.
близки к нулю, и незначительное изменение того или другого может привести к резкому изменению коэффициента вариации u.
Коэффициент вариации u, как мера рассеяния, значительно совершеннее коэффициента неровноты Н.
Пример 10.22. Подсчитаем коэффициенты вариации для числовых данных примеров 10.15 и 10.16, в каждом из которых, несмотря на явное различие в неровноте двух совокупностей, коэффициенты неровноты оказались одинаковыми.
Для первого ряда из примера 10.15 имеем:
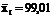 ;
; 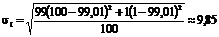
следовательно, ![]()
Для второго ряда из этого же примера
![]() ;
; 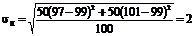
следовательно, ![]()
Коэффициент вариации u1 значительно больше, чем uII, что вполне соответствует действительности.
Аналогично для двух рядов из примера 10.16 имеем:
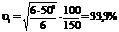 ;
; 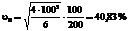
И в этом примере коэффициенты вариации, в отличии от коэффициентов неровноты, свидетельствуют об истинной неровноте.
Замечательный сравнительный анализ различных мер рассеяния дан . Им, в частности, установлено, что в тех случаях, когда коэффициент неровноты дает верную информацию о неровноте, коэффициент вариации при одинаковых объемах испытаний дает результаты на 20–25 % более точные, чем коэффициент неровноты Н.
10.7. Двумерные выборочные совокупности.
Составление эмпирических формул
Статистические зависимости
Большой практический интерес представляет изучение статистических совокупностей объектов одновременно по двум каким-нибудь признакам X и Y. Так, например, для расчета размерно-ростовочного ассортимент при изготовлении одежды швейным предприятием необходимо изучить статистическую совокупность людей одновременно по обхвату груди X и росту Y. Совокупность образцов пряжи целесообразно рассматривать одновременно, к примеру, по влажности X и прочности Y или по крутке X (число кручений на 1 м) и укрутке Y (длине образца после кручения) и т. д.
Взаимосвязь между величинами X и Y бывает двух видов:
1. Точная функциональная зависимость, когда каждому значению х величины X соответствует вполне определенное значение у величины Y. Такова, скажем, зависимость между силой тока Y и сопротивлением X, выражаемая законом Ома.
2. Расплывчатая статистическая, или корреляционная, зависимость, когда одному и тому же значению величины X может соответствовать целая статистическая совокупность значений величины Y со своим законом распределения, из меняющимся с изменением X. Подобными зависимостями являются зависимости между обхватом груди X и ростом Y, между круткой X и укруткой Y и т. д. При статистической зависимости расплывчатая связь, или корреляция, между X и Y может быть более тесной, т. е. более близкой к функциональной, и менее тесной, вплоть до полного ее отсутствия.
Раздел математической статистики, изучающий статистические (корреляционные) зависимости, называется теорией корреляции.
Различают два вида корреляции – неполную и полную, в зависимости от того, как ставится эксперимент.
Неполной называется корреляция, когда одному из признаков, например X, даются те или иные фиксированные значения х1у х2, . . ., xk и для каждого из них путем эксперимента находят совокупность значений у признака Y. В этом случае результаты эксперимента оформляются в виде таблицы, верхняя строка которой содержит фиксированные значения х1 , х2 , . . . , xk признака X, а по столбцам – получаемые из эксперимента соответствующие значения признака Y, которые обозначаются через ух. Заметим, что при непрерывном изменении признака X под x1 , х2, . . . , xk надо понимать середины частных интервалов Δxi на которые разбивается общий интервал изменения признака X в данной выборочной совокупности.
Примером такой таблицы может служить обведенная жирными линиями часть табл. 10.14, в первой строке которой выписаны фиксированные значения крутки X (число кручений на 10 см) пряжи, а в столбцах — числовые значения укрутки Y (длины скрученных образцов пряжи в процентах от длины нескрученных образцов), определенные при фиксированных крутках.
Таблица 10.14
X | х1 = 10 | х2 = 50 | х3 = 100 | х4 = 150 | х5 = 200 | |
yx | 99 100 100 101 100 | 98 100 99 | 99 97 99 97 | 96 94 | 87 86 89 90 | |
№ 1 | mx |
|
|
|
|
|
№ 2 |
|
|
|
|
|
|
Обработка подобной таблицы состоит в следующем:
1) подсчитывают число испытаний (измерений) укрутки Y для каждого значения xi ,т. е. численности тх, которые записываются в строке № 1 под нижней жирной линией;
2) находят средние значения ух для каждого значения xi называемые условными средними, которые записывают в строке № 2.
В рассматриваемом примере для каждого фиксированного значения крутки X проводилось разное число тх испытаний, а именно 5, 3, 4, 2 и 4 – всего 18. Но чаще всего для простоты вычислений числа тх испытаний Y для каждого хi берут одинаковыми.
Полной называется корреляция, когда каждый из отобранных элементов статистической совокупности объектов испытывается срази по двум признакам X и Y. В этом случае результаты эксперимента оформляются в виде первоначальной двумерной таблицы, состоящей из пар значений (X; Y). Примером такой таблицы служит табл. 10.15, в которой X — обхват груди (см), a Y — рост (см) 20 мужчин некоторого города.
Таблица 10.15
X | 91 | 95 | 97 | 99 | 92 | 96 | 100 | 100 | 97 | 101 | 97 | 95 | 102 | 98 | 101 | 99 | 103 | 104 | 104 | 103 |
Y | 160 | 169 | 162 | 168 | 164 | 164 | 165 | 169 | 159 | 170 | 171 | 165 | 171 | 166 | 172 | 175 | 170 | 181 | 176 | 175 |
Статистическая обработка такой таблицы состоит в составлении корреляционной таблицы распределения численностей, являющейся двумерной аналогией одномерной таблицы распределения численностей. В двух верхних строках и двух левых столбцах корреляционной таблицы выписывают частные интервалы Δх и Δу и их середины xi и yi для признаков X и Y, а в остальных клетках таблицы фиксируют численности m (х1; y1) = m11; m (х2; y1) = m21; m (х3; y1) = m31; … тех пар значений X и Y из первоначальной таблицы (табл. 10.15), которые одновременно попадают в соответствующие столбец и строку. Эти численности находят путем предварительных отметок посредством системы точек и подсчета точек. В частности, первоначальной двумерной таблице для обхвата груди X и роста Y (табл. 10.15) соответствует корреляционная таблица численностей, приведенная в табл. 10.16.
Первичная обработка корреляционной таблицы численностей состоит в следующем:
1) подсчитывают численности тх значений Y при фиксированных значениях х и численности ту значений X при фиксированных значениях у с занесением результатов в строку № 1 внизу и столбец № 1 справа;
2) находят условные средние ух и ху как средние взвешенные значения ух и ху по столбцам или по строкам с учетом соответствующих численностей и заносят их в строку № 2 и столбец № 2.
Так, для х2 = 96 имеем:
![]()
для y1 = 158
![]()
Таблица 10.16
X Y | Δx | 90 – 94 | 94 – 98 | 98 – 102 | 102 – 106 | № 1 | № 2 |
Δy | x y | х1 = 92 | х2 = 96 | х3 = 100 | х4 = 104 | my |
|
155 – 161 | y1 = 158 |
|
|
|
| ||
161 – 167 | y2 = 164 |
|
|
|
|
| |
167 – 173 | y3 = 170 |
|
|
|
|
| |
173 – 179 | y4 = 176 |
|
|
|
| ||
179 – 185 | y5 = 182 |
|
|
| |||
№ 1 | mx |
|
|
|
| n = 20 |
|
№ 2 |
|
|
|
|
|
|
В теории корреляции разрешаются две основных задачи:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
