
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для цього розрахуємо коефіцієнти парної кореляції по формулах:
| (2.76) |
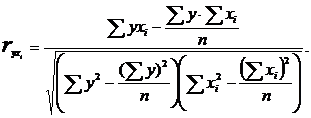
Дані беремо з таблиці 1 з рядка «РАЗОМ» відповідних стовпців:
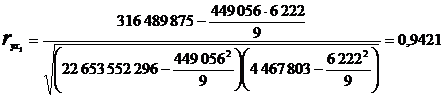
Аналогічно:
![]()
![]()
Набуті значення коефіцієнтів парної кореляції більше по модулю 0,3, значить, всі три фактори слід включити в модель, що розробляється.
4. Перевірка показників на мультиколінеарність.
Під мультиколінеарністю розуміють наявність висококореляційного зв'язку між двома факторами.
Для цього визначаємо парні коефіцієнти кореляції по формулах:
| (2.77) |
| (2.78) |
| (2.79) |
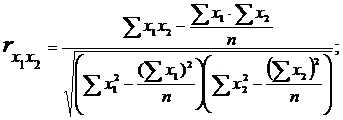
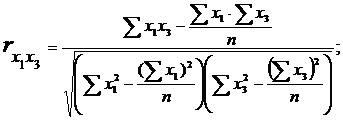
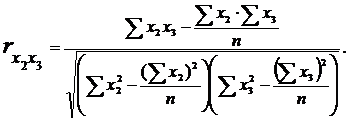
Маємо:
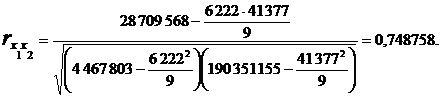
Аналогічно:
![]()
![]() .
.
Теоретично вважається, що мультиколінеарність відсутня, якщо коефіцієнти парної кореляції менше 0,85 по модулю.
У нас коефіцієнт 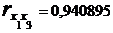 більше 0,85, тому робимо висновок про наявність мультиколінеарності.
більше 0,85, тому робимо висновок про наявність мультиколінеарності.
Оцінка будь-якої регресії страждатиме від мультиколінеарності певною мірою, якщо тільки всі незалежні змінні не виявляться абсолютно некорельованими.
У нашому випадку на наявність мультиколінеарності може впливати недостатнє число спостережень. Можливо збільшення кількості спостережень зменшить проблему мультиколінеарності.
5. Перевірка надійності впливу окремих факторів на результат.
Ця перевірка здійснюється за допомогою коефіцієнтів надійності:
| (2.80) |
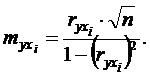
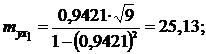
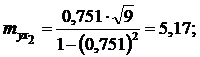
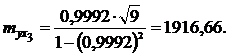
Оскільки всі коефіцієнти надійності по модулю більше 2,6, то всі дані фактори дійсно впливають на обсяг споживчих кредитів.
6. Розрахунок коефіцієнта кореляції.
Автокореляція – це кореляційна залежність між послідовними значеннями рівнів однієї і тієї ж ознаки.
Щоб виявити наявність автокореляції за часом в помилках використовують наступну ідею: якщо кореляція є у помилок Е, то вона присутня і в залишках, одержуваних після застосування методу МНК.
Лінійний коефіцієнт автокореляції першого порядку обчислюється по формулі:
| (2.81) |
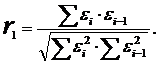
де ![]() – залишки;
– залишки;
![]() – розрахункові значення у по рівнянню регресії;
– розрахункові значення у по рівнянню регресії;
![]() – залишки, зсунуті на 1 крок.
– залишки, зсунуті на 1 крок.
тоді (за даними таблиці 2.6):
![]() .
.
В тому випадку, якщо коефіцієнт автокореляції першого порядку менше 0,5, то автокореляція відсутня, а якщо більше 0,5, то автокореляція присутня.
У нашому випадку 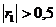 , тому ми можемо стверджувати, що автокореляція присутня.
, тому ми можемо стверджувати, що автокореляція присутня.
Перевіряючи гіпотезу про існування лінійної автокореляції першого порядку, виконують перевірочну процедуру, засновану на обчисленні d-статистики Дарбіна-Уотсона:
| (2.82) |
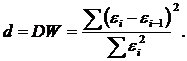
де d – взвішена сума квадратів різниць послідовних залишків.
Маємо:
![]() .
.
По таблиці значень d-статистики Дарбіна – Уотсона: рівень значущості ![]() , числі спостережень n=9, числі незалежних змінних в рівнянні регресії R=3 знаходимо два критичні значення: нижнє
, числі спостережень n=9, числі незалежних змінних в рівнянні регресії R=3 знаходимо два критичні значення: нижнє ![]() (межа для визнання позитивної автокореляції залишків) і верхнє
(межа для визнання позитивної автокореляції залишків) і верхнє ![]() (межа визнання її відсутності)
(межа визнання її відсутності)
Тоді:
![]()
![]() .
.
Обчислене значення d=![]() потрапляє в інтервал
потрапляє в інтервал 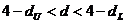 .
.
По таблиці 4 із завдання 1 одержуємо, що d потрапляє в область невизначеності, (у разі передбачуваної негативної кореляції), тому гіпотеза про відсутність автокореляції не приймається і не відкидається.
7. Визначимо приватні коефіцієнти множинної кореляції для зміни тісноти зв'язку між у і факторами  по формулах:
по формулах:
| (2.83) |
| (2.84) |
| (2.85) |
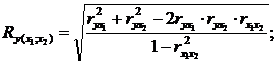
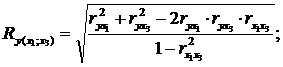
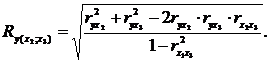
Маємо:
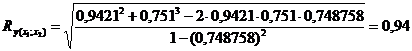
Аналогічно:
![]()
![]()
8. Перевірка достовірності одержаної моделі здійснюється:
1) за допомогою розрахунку теоретичних значень по одержаному рівнянню ![]() .
.
Якщо, 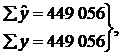 то рівняння достовірне.
то рівняння достовірне.
2) за допомогою розрахунку коефіцієнта детермінації:
![]() , значить, рівняння достовірне і може бути використане для прогнозу.
, значить, рівняння достовірне і може бути використане для прогнозу.
Знайдемо скоректований коефіцієнт ![]() по формулі:
по формулі:
| (2.86) |
де n – число спостережень;
m – число незалежних змінних.
Маємо:
![]()
При невеликому числі спостережень величина, як правило, завищується.
9. Обчислимо стандартну помилку регресії:
| (2.87) |
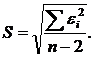
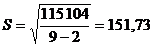
Знайдемо відношення стандартної помилки до середнього значення залежної змінної:
![]() або 0,304%.
або 0,304%.
Це відношення служить критерієм прогнозних якостей оціненої регресійної моделі.
Алгоритм використання інструменту КОРРЕЛЯЦИЯ.
Інструмент аналізу Корреляция (який також поставляється разом з надбудовою Пакет анализа) використовується для оцінки ступеня залежності між двома наборами даних. Щоб застосувати інструмент Корреляция, виконайте ряд, дій.
4.1. Виберіть команду Сервис - Анализ данных.
4.2. В діалоговому вікні, що відкрилося, Анализ данных в списку Инструмеиты анализа виберіть пункт Корреляция і клацніть на кнопці ОК.
Ехсеl відобразить на екрані діалогове вікно Корреляция.
4.3. Визначте значення X і У, які повинні бути проаналізовані.
В полі Входной интервал вкажіть посилання на комірки. Якщо цей діапазон містить підписи даних, встановіть прапорець Метки в першому рядку. Перевірте, чи правильно вибраний перемикач Группирование, визначаючий спосіб організації даних у виділеному діапазоні комірок.
4.4. Вкажіть місце, куди повинні бути поміщені результати обчислень, що проводяться.
Використовуйте перемикачі групи Параметри выводов, щоб вказати Ехсel, де повинен бути розміщений звіт про одержані результати. Наприклад, щоб помістити цей звіт на тому ж листі, де розташовані початкові дані, виберіть перемикач Выходной интервал і в полі праворуч від нього вкажіть адресу комірок, які повинні містити обчислені значення. Щоб помістити звіт в якому-небудь іншому місці, виберіть один з двох інших перемикачів.
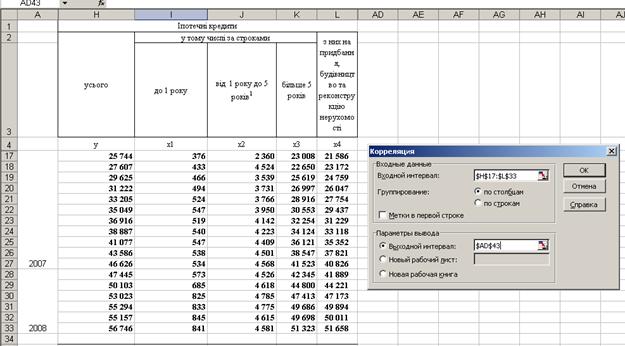
4.5. Клацніть на кнопці ОК.
Ехсеl обчислить коефіцієнт кореляції для вказаних вами даних і помістить його в задане місце. Значення цього коефіцієнта, наприклад, рівне числу 0,, що означає, що майже на 92% обсяги депозитів залежать від кількості виходів реклами.
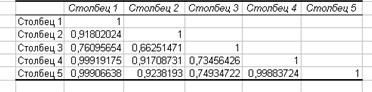
Побудова моделі множинної регресії
Вхідні дані для побудови моделі множинної регресії лінійного виду та у вигляді функції Кобба-Дугласа наведені нижче:
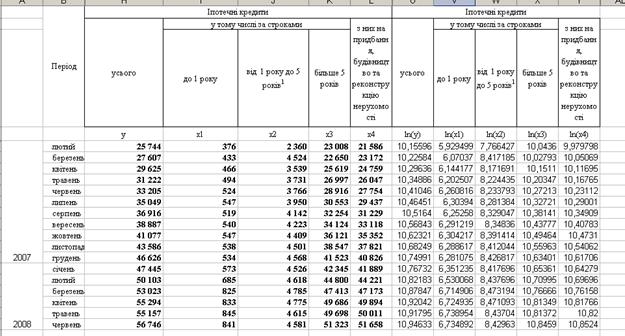
5.1. Вибираємо команду Сервис-Айализ данных.
5.2. В діалоговому вікні, що відкрилося, Анализ данных в списку Инструменты анализа вибираємо пункт Регрессия і клацаємо на кнопці ОК. На екрані відображається діалогове вікно Регрессия.
5.3. Визначте значення Х і У.
В полі Входной интервал У вкажіть посилання на діапазон комірок, в яких міститься набір залежних значень; (об'єм продажів). Потім перейдіть до поля Входной интервал X. Переконайтеся, наприклад, що дані про розміри торгової площі і чисельності, персоналу розташовуються в сусідніх колонках. Помітьте блок, що складається з цих обох колонок, як значення X. В цьому полягає єдина відмінність введення даних для лінійного і множинного регресійного аналізу. Потім аналіз проводиться аналогічно попередньому, але коли з’являються його результати, ми-бачимо два коефіцієнти при X.
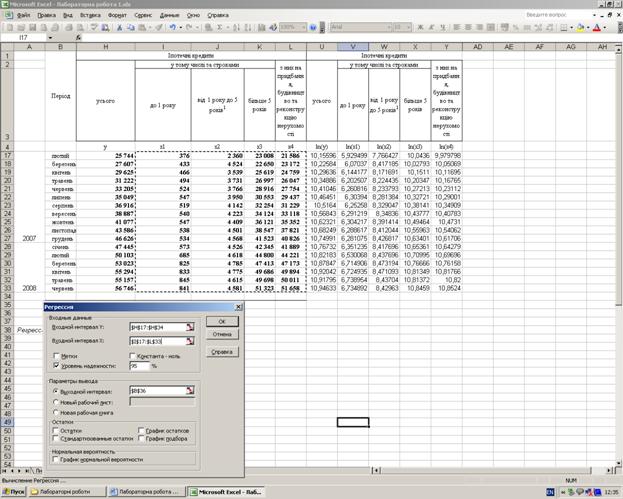
Отримаємо наступні результати:
– лінійна модель 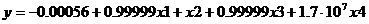
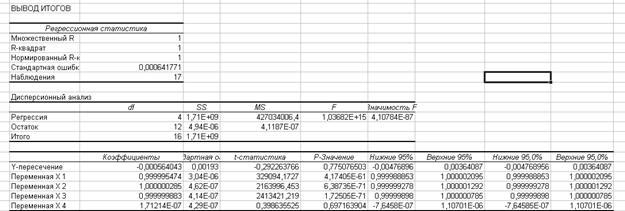
– модель у вигляді функції Кобба-Дугласа ![]()
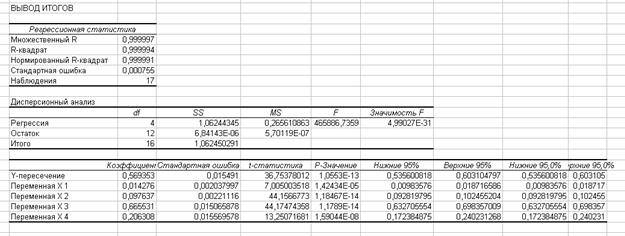
6. Для оцінки суттєвості лінійного коефіцієнта кореляції використаємо критерій Стьюдента. Проведемо порівняння розрахованого значення критерію Стьюдента з його критичним значенням. Критичне значення знаходимо за таблицями розподілу Стьюдента для заданого рівня ймовірності та числа ступенів свободи 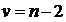 , де
, де ![]()
![]() – число спостережень.
– число спостережень.
За умови, якщо ![]() лінійний коефіцієнт кореляції можна вважати статистично значимим. Для заданих умов tкрит ( 0,05;8)=2,307.
лінійний коефіцієнт кореляції можна вважати статистично значимим. Для заданих умов tкрит ( 0,05;8)=2,307.
Оцінка суттєвості рівняння регресії проводиться за критерієм Фішера. Якщо, розрахункове значення критерію Фішера перевищує його критичне значення модель можна вважати адекватною. Fкрит (0,05;1;8)=5,32
Оскільки коефіцієнт детермінації для обох рівнянь суттєво не відрізняється і приблизно дорівнює 1, F-критерій Фішера показує адекватність обох рівнянь, а t-критерій Стьюдента підтверджує значимість лише коефіцієнтів при ![]() для лінійної моделі і значимість усіх коефіцієнтів для моделі у вигляді функції Кобба-Дугласа, тому більш прийнятною вважається модель у вигляді функції Кобба-Дугласа.
для лінійної моделі і значимість усіх коефіцієнтів для моделі у вигляді функції Кобба-Дугласа, тому більш прийнятною вважається модель у вигляді функції Кобба-Дугласа.
![]()
2.10 ПРОГНОЗУВАННЯ ЗА ЛІНІЙНОЮ МОДЕЛЛЮ
Якщо побудована модель адекватна за F-критерієм, то її застосовують для прогнозування залежної змінної.
Про прогнозування регресанда говорять тоді, коли в часових рядах прогнозний період настає пізніше, ніж базовий. Якщо регресія побудована за просторовими даними, прогноз стосується тих елементів генеральної сукупності, що перебувають за межами застосованої вибірки.
Якість прогнозу тим краща, чим повніше виконуються передумови моделі в прогнозний часовий період, надійніше (вірогідніше) оцінено параметри моделі й більш точно визначено прогнозні значення регресорів.
Значення ![]() для майбутнього періоду чи додаткового елемента обчислюють за формулою (2.3) за відомим вектором оцінених параметрів
для майбутнього періоду чи додаткового елемента обчислюють за формулою (2.3) за відомим вектором оцінених параметрів ![]() і за вектором значень незалежних змінних
і за вектором значень незалежних змінних ![]() , що не належать до базового періоду. Розрізняють прогноз середній (оцінку математичного сподівання регресанда) та індивідуальний (оцінку певної реалізації регресанда
, що не належать до базового періоду. Розрізняють прогноз середній (оцінку математичного сподівання регресанда) та індивідуальний (оцінку певної реалізації регресанда![]() , що відповідає моменту p). Перша з них базується на передумові МНК про нульове математичне сподівання випадкової складової рівняння регресії, а друга застосовує оцінене значення
, що відповідає моменту p). Перша з них базується на передумові МНК про нульове математичне сподівання випадкової складової рівняння регресії, а друга застосовує оцінене значення ![]() . Оцінену дисперсію прогнозу обчислюють відповідно за формулами:
. Оцінену дисперсію прогнозу обчислюють відповідно за формулами:
| (2.88) |
| (2.89) |
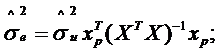
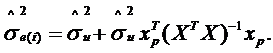
Зрозуміло, що здебільшого реальне значення показника yt не збігатиметься зі значенням його математичного сподівання, але якщо розглядати велику кількість вибірок, на підставі яких визначатиметься прогноз, то можна гарантувати, що приблизно (1 - a)×100 % результатів потраплять відповідно до інтервалів
| (2.90) |
| (2.91) |
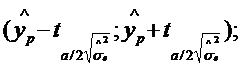
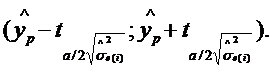
де tα/2 – табличне значення критерію Стьюдента з n-m-1 ступенями свободи та при заданому рівні значущості α/2. (Значення α/2 вибирають, як і раніше, через двосторонні критичні межі.)
Очевидно, з віддаленням від середнього значення вибірки спостережень похибка прогнозу зростатиме, що призведе до збільшення довірчого інтервалу для індивідуального значення залежної змінної.
2.11 МЕТОДИ ПОБУДОВИ БАГАТОФАКТОРНОЇ РЕГРЕСІЙНОЇ МОДЕЛІ
На кожний економічний показник впливає безліч факторів. При побудові регресійного рівняння виникає питання, які саме з них слід уводити в модель. Причому при використанні моделі для прогнозу бажано включити якомога більше факторів. З іншого боку збирання та обробка великої кількості інформації потребують значних витрат, тобто кількість факторів доцільно зменшити.
Для вибору компромісного рішення не існує єдиної процедури.
Тому для побудови «найкращого» рівняння застосовують один із таких методів.
1. Метод усіх можливих регресій – історично один із перших методів побудови регресійної моделі – найбільш громіздкий, тому що передбачає побудову регресій, які містять усі можливі комбінації впливових факторів. Іншими словами, якщо розглядається m факторів, то досліджується 2m регресій, які порівнюються між собою за значеннями коефіцієнта детермінації та стандартною похибкою рівняння. Хоча цей метод і дає змогу дослідити усі можливі рівняння, однак при великій кількості факторів він, звичайно, неприйнятний.
2. Метод виключень економніший щодо обчислень і базується на дослідженні часткових F-критеріїв, які дають змогу встановлювати статистичну значущість співвідношення між залишками моделі з найбільшою кількістю факторів і залишками моделі з одним вилученим фактором. Якщо для деякого вилученого фактора таке співвідношення не є значущим (приймається нульова гіпотеза), то він до моделі не повертається. Таке дослідження проводиться також для рівняння з меншою кількістю факторів, але з більшим числом ступенів свободи.
3. Покроковий регресійний метод діє у зворотному порядку порівняно з попереднім методом, тобто до моделі послідовно включаються фактори, що мають найбільший коефіцієнт кореляції із залежною змінною. Модель аналізується за значеннями коефіцієнта детермінації та частковими F-критеріями. Фактори, що не задовольняють критерії, з моделі вилучаються. Процес припиняється, якщо жоден з факторів рівняння вилучити не вдається, а новий претендент на включення не відповідає частковому F-критерію. На практиці цей метод найпоширеніший.
Завдання для самоконтролю
1. Схарактеризуйте стисло алгоритм покрокової регресії.
2. Чим відрізняються коефіцієнти парної та часткової кореляції?
3. Запишіть співвідношення між коефіцієнтами кореляції і детермінації.
4. Як визначаються дисперсія залишків, загальна дисперсія і дисперсія регресії?
5. Який між ними зв’язок?
6. Критерій Фішера. Перевірка лінійної регресійної моделі на адекватність.
7. Покажіть залежність між F-критерієм і ![]() .
.
8. Як оцінити вірогідність коефіцієнта кореляції?
9. Як обчислюється t-критерій?
10. Теоретична та емпірична лінійна множинна модель та їх запис у векторно-матричній формі.
11. Що таке стандартна помилка оцінок параметрів моделі.
12. Описати алгоритм побудови довірчих інтервалів із заданою надійністю g для параметрів ![]() теоретичної множинної лінійної регресії. Навести відповідні формули.
теоретичної множинної лінійної регресії. Навести відповідні формули.
13. Перевірка статистичної значущості параметрів ![]() та перевірка загальної якості множинної регресії. Навести відповідні формули.
та перевірка загальної якості множинної регресії. Навести відповідні формули.
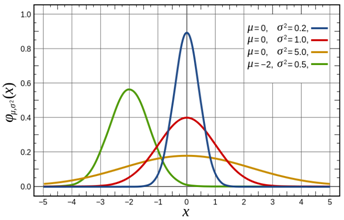
[1] Нормальний розподіл (розподіл Ґауса) — розподіл ймовірностей випадкової величини, що характеризується щільністю ймовірності.
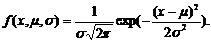
деμ — математичне сподівання,σ2 — дисперсія випадкової величини. Параметр σ також відомий, як стандартне відхилення. Розподіл із μ = 0 та σ 2 = 1 називають стандартним нормальним розподілом.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
