
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
4. Имеется n камней (известна их масса), разложить эти камни на две кучки так, чтобы массы этих кучек отличались друг от друга как можно меньше (в идеале совпадали).
5. Даны две строки, определить может ли первая строка быть получена путем зачеркивания элементов второй.
6. Известны массы n гирек. определить, можно ли заданный груз взвесить этими гирьками. Если можно, то указать наилучший (по числу используемых гирек) способ взвешивания. Задачу решить для двух случаев: а) груз на одной чаше весов, гирьки на другой; б) гирьки могут находиться на обеих чашках весов.
Контрольная работа:
1. Дан ряд цифр 1, 2, 3, 4, 5, 6, 7, 8, 9. Можно ли получить данное число s, расставляя между цифрами знаки + и -. Если можно то указать способ расстановки знаков. ( Тесты: s=45 1+2+3+4+5+6+7+8+9; s=2 нельзя (любое четное нельзя); s=1 1-2-3-4+5-6-7+8+9 (12 вариантов); s=47 нельзя; s=31 1+2+3+4+5+6-7+8+9 (3 варианта).
2. Известно количество страниц в каждом из n произведений. определить можно ли распределить эти произведения на 3 тома так, чтобы все тома оказались одинаковыми. Если можно, то вывести один из вариантов распределения. (Тесты: n=6 (7, 10, 4, 8, 2, 5) можно (7+5, 8+4, 10+2); n=5 (5, 4, 6, 3, 8) нельзя; n=3 (5, 5, 5) можно (5, 5, 5); n=8 (5, 4, 3, 4, 2, 1, 6, 5) можно (по 10); n=6 (3, 3, 3, 3, 3, 5) нельзя).
3. Известны массы n камней. Распределить камни на три кучки так, чтобы массы самой легкой и самой тяжелой кучки отличались минимально. в идеале совпадали.
Генерация перестановок.
Предположим, что нам дана такая задача: Вывести на экран все перестановки чисел 1..n (то есть последовательности длины n, в каждую из которых каждое из чисел 1..n входит по одному разу).
Для определенности рассмотрим пример при n=5.
Изначально имеем такую расстановку чисел 1 2 3 4 5.
На первом шаге поменяем местами два последних элемента, получим 1 2 3 5 4.
Дальше начнем искать первый с конца элемент, который будет меньше следующего за ним (5>4, а вот 3<5). Следовательно, таким элементом будет тройка, стоящая на третьей позиции. Теперь необходимо найти самый правый элемент больший, чем этот ( 5>3, но правее стоит 4, и она тоже больше тройки), следовательно таким элементом будет четверка стоящая на пятой позиции. Меняем их местами. Получили такую перестановку: 1 2 4 5 3. при этом хвост массива, то есть элементы, стоящие на двух последних местах оказались упорядоченными по убыванию, поэтому если мы ничего не изменим, то они так и останутся навсегда на своих местах, и тем самым мы потеряем некоторые варианты, для того чтобы этого не произошло, переставим их в порядке возрастания, и только после этого будем считать, что мы нашли новый, третий по счету вариант перестановки: 1 2 4 3 5.
Теперь опять начинаем просматривать массив с конца в поисках первой пары элементов, из которых левый меньше правого, а также самый правый элемент больший этого левого (3<5, и при этом 5 самый правый), следовательно, необходимо поменять их местами
{Этот алгоритм хорошо известен и достаточно подробно изложен. Опишем его (при N=5), от чего рассуждения не утратят общности. Алгоритм составлен так, что в процессе его исполнения перестановки N чисел располагаются лексикографически (в словарном порядке). Это значит, что перестановки сравниваются слева направо поэлементно. Больше та, у которой раньше встретился элемент, больше соответствующего ему элемента во второй перестановке. (Например, если S=(3,5,4,6,7), а L=(3,5,6,4,7), то S<L).
Принцип работы алгоритма разъясним на примере. Допустим, необходимо воспроизвести все перестановки цифр 3,4,5,6,7. Первой перестановкой считаем перестановку (3,4,5,6,7). Последней воспроизводимой перестановкой будет (7,6,5,4,3). Предположим, что на некотором шаге работы алгоритма получена перестановка
P=(5,6,7,4,3).
Для того чтобы определить непосредственно следующую за ней перестановку, необходимо, пересматривая данную перестановку справа налево, следить за тем, чтобы каждое следующее число было больше предыдущего, и остановиться сразу же, как только это правило нарушится. Место останова указано стрелкой:
(5,6,7,4,3).
Затем вновь просматриваем пройденный путь ( справа налево ) до тех пор, пока не дойдем до первого числа, которое уже больше отмеченного. Ниже место второго останова отмечено двойной стрелкой.
(5,6,7,4,3).
Поменяем местами, отмеченные числа:
(5,7,6,4,3).
Теперь в зоне, расположенной справа от двойной стрелки, упорядочим все числа в порядке возрастания. Так как до сих пор они были упорядочены по убыванию, то это легко сделать, перевернув указанный отрезок. Получим: Q=(5,7,3,4,6).
Q и есть та перестановка, которая должна воспроизводиться непосредственно после P.
Действительно, P<Q, так как, пересматривая эти перестановки слева направо, (P(2)=6,Q(2)=7). Пусть существует такая перестановка R, что P<R<Q. Тогда P(1)=R(1)=Q(1). По построению же Q(2) – это наименьшее во множестве Q\Q(1)={3,4,6,7} число, такое, что Q(2)>P(2). Поэтому для R(2) верно одно из двух равенств: R(2)=Q(2) или R(2)=P(2). Но так как в P элементы, начиная с P(3), убывают, то из P<R следует, что если P(2)=R(2), то и P=R. Аналогично, так как в Q элементы, начиная с Q(3), возрастают, то из R<Q следует, что если R(2)=Q(2), то и R=Q.}
Алгоритм генерации перестановок:
1. Просматриваем a1,.., an с кона до тех пор, пока не попадется ai<ai+1. если таковых нет, значит, генерация закончена.
2. Рассматриваем ai+1, …, an. Находим первый с конца am>ai и меняем их местами.
3. ai+1, ai+2, …, an переставим в порядке возрастания.
4. Выводим найденную перестановку.
5. Возвращаемся к первому пункту.
В результате всех перестановок, всевозможных вариантов должно получиться n!, где n – количество элементов рассматриваемого массива.
Первой должна быть перестановка 1 2 3 …n, а последней n n-1…2 1.
program perest;
uses crt;
var
a: array [1..20] of byte;
i, j, k, n, kol, z: integer;
procedure form;
begin
i:=n-1;
while (i>0) and (a[i]>a[i+1]) do dec(i);
if i>0 then begin
j:=n;
while a[j]<a[i] do dec(j);
z:=a[i]; a[i]:=a[j]: a[j]:=z;
for k:=i+1 to (i+1+n) div 2 do begin
z:=a[k];
a[k]:=a[n-k+i+1];
a[n-k+i+1]:=z;
end;
end;
end;
procedure obr;
begin
for i:=1 to n do
write (a[i], ‘ ‘ );
writeln;
inc(i);
end;
begin
clrscr;
writeln(‘Введите количество элементов');
readln(n);
for i:=1 to n do
a[i]:=i;
repeat
obr;
form;
until i=0;
writeln(‘Количство вариантов’, kol);
readln;
end.
Задачи:
1. Вывести на экран все перестановки последовательности n различных букв: абвгд…
2. Письма на удачу вкладываются в подписанные конверты. Определить количество раскладок, когда ни одно из n писем не попадает к своему адресату.
3. Вывести на экран все перестановки из n различных букв при условии, что гласные буквы не могут стоять рядом. Определить количество таких перестановок.
4. В ряд выкладываются b белых шаров, s синих шаров и k красных шаров. Определить количество расстоновок шаров, если шары одинакового цвета не могут стоять рядом. вывести эти расстановки на экран.
5. Расстаивть n ладей на поле размером n´n так, чтобы они не били друг друга. Определить количество таких расстановок.
6. Расставить n ферзей на шахматной доске размером n´n так, чтобы они не били друг друга. Определить количество таких расстановок.
7. Имеется n юношей и n девушек. Некоторые юноши знакомы с некотрыми девушками. Определить максимальное число возможных браков между ними, если известно, что браки могут заключаться только между знакомыми людьми, а многоженство и многомужество запрещены.
Поиск в графе.
Определим граф как конечное множество вершин V и набор E неупорядоченных и упорядоченных пар вершин и обозначим G=(V, E). Мощности множеств V и E будем обозначать буквами N и M. Неупорядоченная пара вершин называется ребром, а упорядоченная пара - дугой. Граф, содержащий только ребра, называется неориентированным; граф, содержащий только дуги, - ориентированным, или орграфом. Вершины, соединенные ребром, называются смежными. Ребра, имеющие общую вершину, также называются смежными. Ребро и любая из его двух вершин называются инцидентными. Говорят, что ребро (u, v) соединяет вершины u и v. Каждый граф можно представить на плоскости множеством точек, соответствующих вершинам, которые соединены линиями, соответствующими ребрам. В трехмерном пространстве любой граф можно представить таким образом, что линии (ребра) не будут пересекаться.
Способы описания. Выбор соответствующей структуры данных для представления графа имеет принципиальное значение при разработке эффективных алгоритмов. При решении задач используются следующие четыре основных способа описания графа: матрица инциденций; матрица смежности; списки связи и перечни ребер. Мы будем использовать только два: матрицу смежности и перечень ребер.
Матрица смежности - это двумерный массив размерности N*N.
A[i, j]=![]()
Для хранения перечня ребер необходим двумерный массив R
размерности M*2. Строка массива описывает ребро.
Множество алгоритмов на графах требует просмотра вершин графа. Рассмотрим их.
Поиск в глубину
Идея метода. Поиск начинается с некоторой фиксированной вершины v. Рассматривается вершина u, смежная с v. Она выбирается. Процесс повторяется с вершиной u. Если на очередном шаге мы работаем с вершиной q и нет вершин, смежных с q и не рассмотренных ранее (новых), то возвращаемся из вершины q к вершине, которая была до нее. В том случае, когда это вершина v, процесс просмотра закончен. Очевидно, что для фиксации признака, просмотрена вершина графа или нет, требуется структура данных типа:
Nnew : array[1..N] of boolean.
|
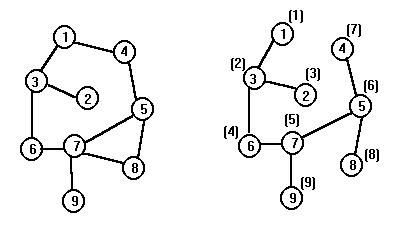
Пример. Пусть граф описан матрицей смежности A. Поиск начинается с первой вершины. На левом рисунке приведен исходный граф, а на правом рисунке у вершин в скобках указана та очередность, в которой вершины графа просматривались в процессе поиска в глубину.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
