
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Затем поверяется гипотеза о диагональности ковариационной матрицы.
Выдвигается нулевая гипотеза:
Н0: соv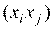 =0,
=0, 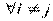 и альтернативная Н1: соv
и альтернативная Н1: соv![]() .
.
Рассчитывается статистика ![]() , которая распределяется по закону
, которая распределяется по закону ![]() с
с ![]() степенями свободы.
степенями свободы.
Если расчетное значения критерия будет больше табличного значения
![]() >
>![]() , то гипотеза Н0 отвергается и принимается альтернативная Н1:
, то гипотеза Н0 отвергается и принимается альтернативная Н1: ![]() значима, что подтверждает мультиколлениарность данных, следовательно имеет смысл проводить компонентный анализ.
значима, что подтверждает мультиколлениарность данных, следовательно имеет смысл проводить компонентный анализ.
Для выделения главных компонент на уровне информативности 0,85 пользуются мерой информативности, которая показывает, какую часть или какую долю дисперсии исходных переменных составляют k-первых главных компонент. На заданном уровне информативности выделяются k главных компонент.
Для решения данной задачи необходимо использовать пакет прикладных программ статистического анализа, например, Statgraphics Plus.
Программа выдает матрицу коэффициентов корреляции A между центрировано – нормированными исходными переменными и ненормированными главными компонентами размерностью (n x k):
 |
|
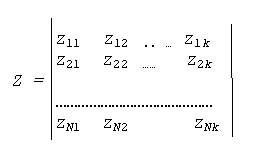 Программа выдает матрицу наблюденных значений главных компонент Z размерностью (n x k):
Программа выдает матрицу наблюденных значений главных компонент Z размерностью (n x k):
Используя значения главных компонент, строится модель главных компонент:
|
|
Подставляя в полученное уравнение значения главных компонент z1 – zk , выраженные через центрированные переменные x1 - xn, получаем окончательное уравнение регрессии:
|
Это уравнение отличается более высокой точностью, чем получаемое с использованием классического метода наименьших квадратов.
Пример
Имеются данные, описывающие зависимость результирующей переменной y от факторных переменных x1 – x3 (таблица 1)
Таблица 1 – Исходная выборка
х1 | х2 | х3 | у |
1,1 | 1,1 | 1,2 | 26,2 |
1,4 | 1,5 | 1,1 | 25,9 |
1,7 | 1,8 | 2 | 32,5 |
1,7 | 1,7 | 1,8 | 31,7 |
1,8 | 1,9 | 1,8 | 31,7 |
1,8 | 1,8 | 1,9 | 33,6 |
1,9 | 1,8 | 2 | 34,2 |
2 | 2,1 | 2,1 | 34,4 |
2,3 | 2,4 | 2,5 | 35,5 |
2,5 | 2,5 | 2,4 | 36,5 |
1) Подготовим данные для использования пакета Statgraphics Plus. Данные вводим непосредственно в Statgraphics Plus путем копирования таблицы 1 с данными.
Убираем с экрана лишние надписи путем удаления соответствующих строк и колонок таблицы с импортированными данными. Выполняем форматирование данных по каждой колонке в отдельности. Для этого помечаем мышью редактируемую колонку с данными. Входим в пункт меню редактирования Edit. Выбраем режим Modify Column. Установим формат данных с фиксированной точкой с необходимым числом цифр после запятой, например, с двумя цифрами после запятой Fixed Decimal 2 .
При этом необходимо запомнить размещение данных во вновь полученной таблице 2 по колонкам Col 1 - Col 4 .
Таблица 2 – Исходная выборка в Statgraphics Plus
Col_ 1 | Col_ 2 | Col_ 3 | Col_ 4 |
1,10 | 1,10 | 1,20 | 26,20 |
1,40 | 1,50 | 1,10 | 25,90 |
1,70 | 1,80 | 2,00 | 32,50 |
1,70 | 1,70 | 1,80 | 31,70 |
1,80 | 1,90 | 1,80 | 31,70 |
1,80 | 1,80 | 1,90 | 33,60 |
1,90 | 1,80 | 2,00 | 34,20 |
2,00 | 2,10 | 2,10 | 34,40 |
2,30 | 2,40 | 2,50 | 35,50 |
2,50 | 2,50 | 2,40 | 36,50 |
2) Проверим мультиколлениарность факторов x1–x3. Мультиколлениарность оцениваем по результатам анализа матрицы парных коэффициентов корреляции. Для расчета матрицы парных коэффициентов корреляции и выдачи ее на печать с исходными данными необходимо вызвать в главном меню программу Summary stats. В окно Data записать колонки Col_1, Col_2, Col_3, нажать ОК. Вызвать подменю Tabular options. В окне табличных настроек поставить флажок напротив Correlations, нажать клавишу OK. При этом на экране появится матрица коэффициентов парной корреляции. Для записи матрицы в таблицу с данными необходимо вызвать пункт подменю Save results, в окне Correlations установить флажок и нажать ОК. Файлу будет приписан идентификатор CMAT. Матрица коэффициентов парной корреляции будет продолжением таблицы с исходными данными с колонками CMAT_1, CMAT_2, CMAT_3. Матрица коэффициентов парной корреляции для рассматриваемого примера имеет вид табл. 3.
Таблица 3- Матрица парных коэффициентов корреляции
CMAT_1 | CMAT_2 | CMAT_3 |
1,0 | 0,985 | 0,931 |
0,985 | 1,0 | 0,915 |
0,931 | 0,915 | 1,0 |
Коэффициенты парной корреляции больше 0,8 что свидетельствует о коррелированности данных, следовательно, имеет смысл проводить компонентный анализ.
3) Выделим главные компоненты, построим уравнение главных компонент. Для выделения главных компонент воспользуемся специальной программой. Для этого в главном меню необходимо вызвать программу главных компонент: Special \ Multivariate Methods \ Principal Components. В окно Data внесите имена колонок с исходными данными Col_1, Col_2, Col_3, нажать ОК.
Для получения данных компонентного анализа вызываем подменю Tabular options и помечаем окно Analysis Summaru, нажимаем ОК. При этом на экране отобразятся результаты анализа (таблица 4):
Таблица 4- Главные компоненты
|
На уровне информативности 95% и выше выделяется одна главная компонента. Она имеет наибольшую дисперсию, равную 96,26%. Использование второй главной компоненты не приводит к существенному увеличению дисперсии (всего на 3,28%). Главная компонента является линейной комбинацией исходных данных x1 – x3. Для выдачи на печать параметров модели необходимо пометить окно Component Weights. При этом на экране появятся параметры модели (таблица 5).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
