


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Есть также аналогичный сервис nskgortrans, здесь используются данные, полученные из 2 сервисов: Яндекс. Карты и Google. Maps. При нажатии пользователем на определенную, интересующую его, машину, которая, в свою очередь, в числе многих отображается на картах, сервис выдаст приблизительное время прибытия на ряд последующих остановок.

Рисунок 1.1 - Работа сервиса nskgortrans
Как работают Яндекс. ПробкиЯндекс. Пробки – это веб-сервис от компании Яндекс, который позволяет пользователям узнавать информацию о дорожных заторах. Информация поступает из разных источников на сервис и отображается на Яндекс. Картах. В больших городах сервер предоставляет уровень пробок по балльной шкале. Сам процесс работы Яндекс. Пробки зависит от информации, которую посылают пользователи, другими словами водитель помогает водителю.
Источники данныхПриведу пример, недавнее ДТП на улице Дуси Ковальчук. Троллейбус, отъезжая от остановки, совершил столкновение с автомобилем Toyota RAV4, который совершал маневр разворота. Тем самым две дорожные линии были перекрыты. Автомобилисты, которые двигались в сторону Заельцовского метро вынуждены передвигаться по одной линии и объезжать ДТП. Пользователь приложений Яндекс мог передать информацию через средства связи и оповестить других водителей о данной проблеме. По мере приближения машин этих пользователей к ДТП их скорость будет уменьшаться, и устройства начнут «сообщать» сервису о заторе.
Информация обновляется каждые несколько секунд с передачей географических координат и это поступает на сервис Яндекс. Пробки. Затем программа-анализатор строит единый маршрут движения с информацией о скорости его прохождения — трек. Главный плюс этой системы, что пользователи остаются анонимными.
GPS-приёмники могут иметь погрешность в точности определение координат во время построения трека. Просчёты не значительны, например, автомобиль может быть сдвинут на несколько метров в любую сторону. Поступающие координаты воспроизводятся на электронной схеме города, где уже есть планировка улиц и всего того, что на ней находится. Это конкретизирование в программе понимает, как двигался автомобиль на самом деле.
При воссоздании картины пробок на дороге пользователю необходимо проверять трек. При ситуации, когда один из водителей останавливается, например, для заправки машины его трек будет замедляться и это не из-за загруженности дороги. Поэтому, чем больше пользователей у сервиса, тем точнее информация о дорожной ситуации.
Когда информация будет соотнесена, это всё отобразиться в приложении при этом используются оценки в цветовой гамме.
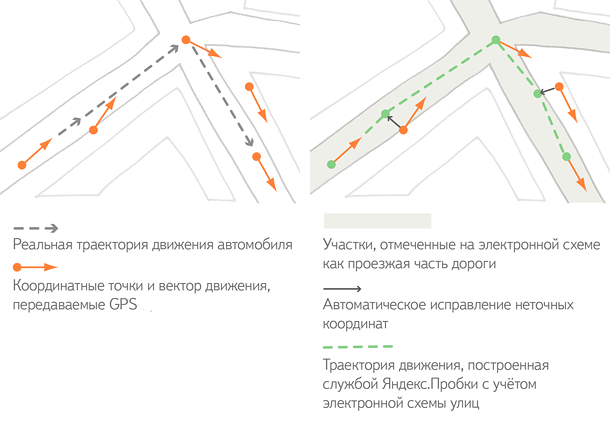
Рисунок 1.2 - Отображение в цветовой грамме
Процесс объединения элементов в одну систему происходит каждые две минуты и обрисовывается в единую схему на сервисе. Эта схема отображается на слое «Пробки» Яндекс. Карт — и в мобильном приложении, и на веб-сервисе.
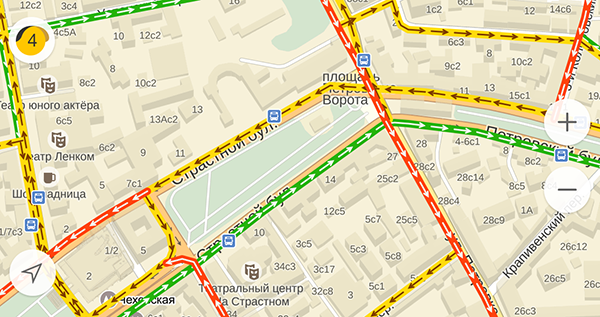
Рисунок 1.3 – Слой «Пробки»
Шкала балловВ таких крупных городах как Новосибирск, Москва, Санкт-Петербург пробки оцениваются по 10-балльной шкале. Обозначение очень простое, 0 – это свободное движение, а 10 – полный затор на дороге. Благодаря такой системе водитель сможет оценить загруженность и рассчитать для себя примерное время в пути.
Шкала баллов настроена по-разному для каждого из городов: то, что в Москве — небольшое затруднение, в другом городе — уже серьёзная пробка. Например, в Санкт-Петербурге при шести баллах водитель потеряет примерно столько же времени, сколько в Москве уже при пяти.
На сервере оценка баллов происходит таким образом. В определенном городе есть уже точно составленный маршрут транспорта по улицам. Каждый транспорт имеет свой отрезок времени в которой он должен преодолеть определенное расстояние. После оценки общей загруженности города программа-сборщик рассчитывает, на сколько отличается реальное время от эталонного. На основе разницы по всем маршрутам и вычисляется загруженность в баллах.
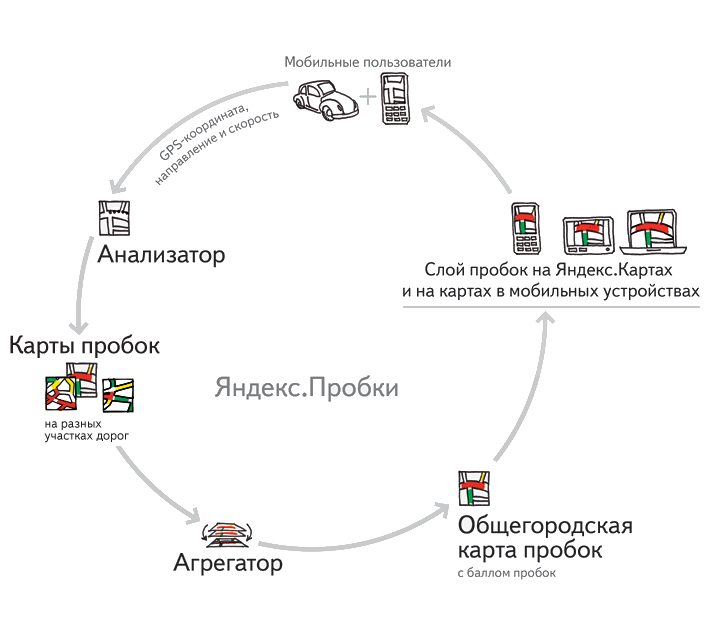
Рисунок 1.4 – Работа сервиса Яндекса в общем
Как работает Яндекс. ТранспортКогда пользователь нажимает на интересующую его остановку, сервер получает данные из Яндекс. Пробки, суммирует среднюю скорость в потоке на каждом участке требуемого маршрута, затем аналогичным образом находит длину пути до требуемой остановке и производит операцию деления второго на первое, тем самым получая значение о предположительном времени в пути.
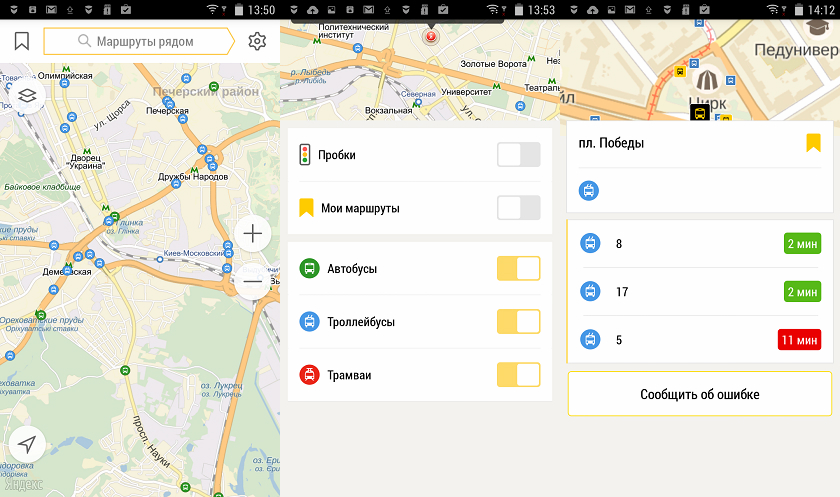
Рисунок 1.5 – Работа приложения Яндекс. Транспорт
Постановка задачиВ данной бакалаврской работе требуется:
Изучить передовые отечественные и зарубежные решения. Изучить модели и методы прогнозирования Определить корреляционно-зависимые переменные. Определить самую приемлемую модель прогнозирования для текущей задачи. Разработать экспериментальную модель для прогнозирования определенных маршрутов с помощью инструментов веб-разработки. Создать несколько дополнительных модулей для повышения точности прогнозирования. Проанализировать созданную модель.ОБЗОР моделей и методов прогнозирования
За последние несколько десятков лет, прогностика, как наука, развивалась очень стремительно. Было создано множество процедур, методов и приемов прогнозирования, по своему характеру очень отличающихся друг от друга. По мнению лучших отечественных и зарубежных ученых, работающих в данном направлении, основных методов прогнозирования насчитывается более ста штук, вследствие чего, вопрос выбора нужного метода прогнозирования, который бы давал наилучшие и адекватные результаты для изучаемых процессов или систем, очень остро стоит.
Существуют три принципиально важные проблемы, возникающие при прогнозировании, которые в свою очередь дают понять преимущества и недостатки тех или иных методов прогнозирования.
Проблема номер один – для грамотной оценки метода, нужно максимально точно определить необходимые и достаточные параметры для исследуемой предметной области.
Проблема номер два – в погоне за точностью прогнозирования, возникает желание в том, чтобы учесть как можно больше различных критериев и показателей оценки, что в свою очередь может привести к «пределу Тьюринга», а то есть к пределу быстродействия нашей компьютерной системы, вследствие большого объема обрабатываемых данных в единицу времени. Также эта проблема называется «проклятье размерности».
Проблема номер три – возникает вследствие феномена «надсистемности». Системы, которые взаимодействуют между собой, обладают собственными свойствами, тем самым образуют систему более высокого уровня, что в свою очередь создает проблему надсистемного отображения целевых функций для систем, которые входят в состав надсистемы.
Чтобы избежать вышеперечисленные проблемы, применяется череда попыток использования таких разделов современной вычислительной и фундаментальной математики, как нейрокомпьютеры, теория катастроф, теория рисков, теория стохастического моделирования (теория хаоса), синергетика и теория самоорганизующихся систем (включая генетические алгоритмы).
Научным миром принято считать, что данные методы позволяют увеличить точность и глубину прогноза, вследствие выявления скрытых взаимосвязей и закономерностей в среде трудно формализуемых обычными моделями и методами макроэкономических, политических и глобальных финансовых показателей.
Аналитический набор моделей и методов прогнозированияКак было сказано выше, по многим исследованиям отечественных и зарубежных ученых в области прогностики, на сегодняшний день насчитывается более ста различных методов прогнозирования. Количество основных, так называемых, базовых методов прогнозирования, которые каким-либо образом повторялись в других методах прогноза, значительно меньше.
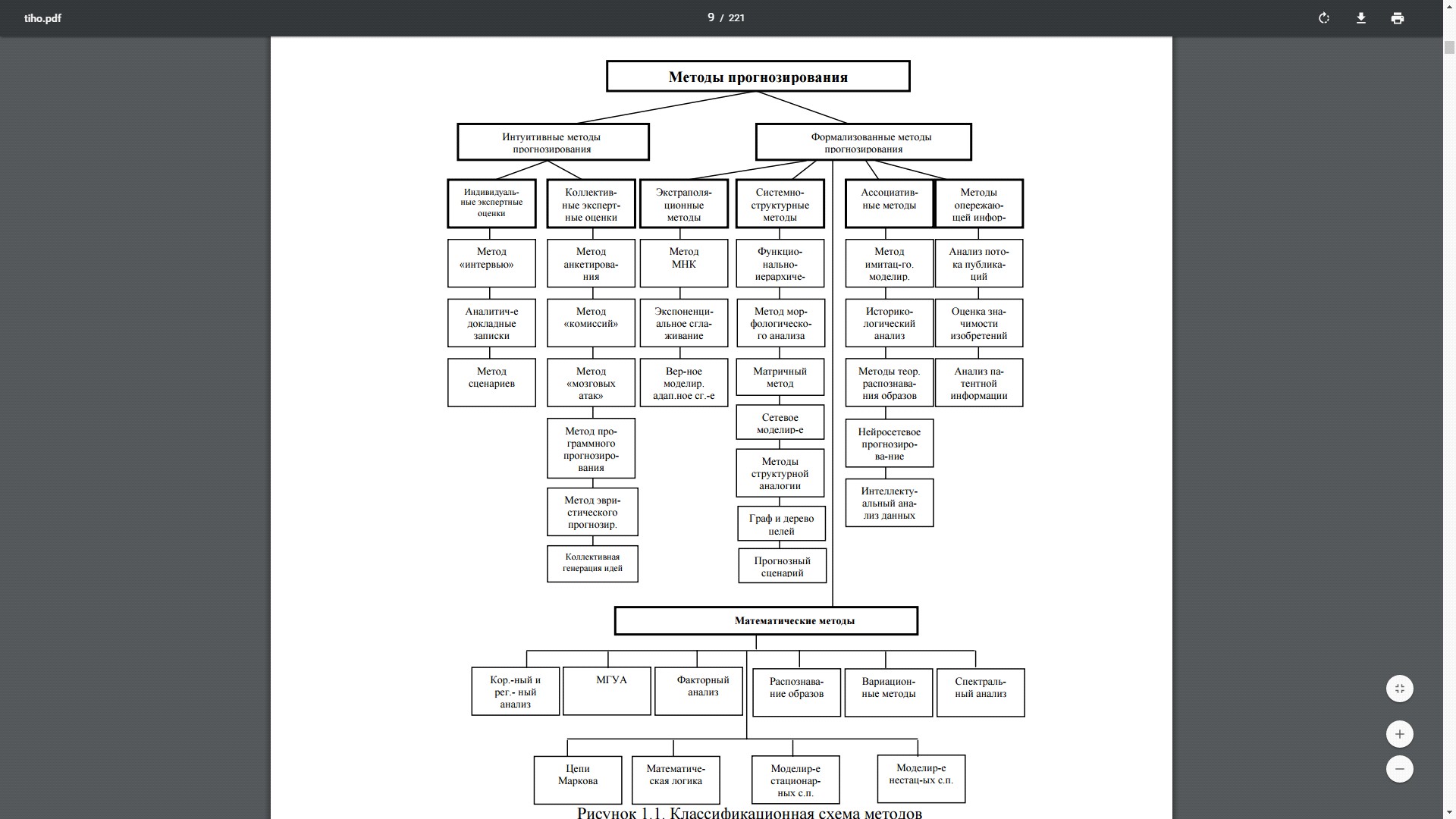
В различных источниках присутствует большое количество различных классифицированных схем разных моделей и методов прогнозирования. Хотя подавляющее большинство для применения на практики почти не возможны, или обладают недостаточными показателями, показывающих актуальность данных. Главной погрешностью нынешних классификационных схем является нарушение принципов классификации. К примеру, к числу фундаментальных таких принципов, на мой взгляд, относятся следующие: достаточная полнота охвата методов прогнозирования, присутствие единого признака классификации на каждом уровне разбиения, а также открытость. Вот схема, которая, на мой взгляд, максимально правильно отражает классификацию данных методов, показана на рисунке 1.1.
Несомненно, возможны для существования и другие, более частные классификационные схемы, которые бы акцентировались на определенной задачи или цели.
На каждом уровне детализации схемы, присутствует свой индивидуальный классификационный признак, это может быть: общий признак действия, степень той, или иной формализации, а также способ получения информации по прогнозу.
Исходя из степеней формализации, все существующие методы прогнозирования можно разделить на интуитивные и формализованные. Интуитивное прогнозирование используется в том случае, когда объект, над которым производится прогноз, весьма примитивен и прост, либо столь сложный, что простым анализом, практически не является возможным учесть влияние всех факторов прогнозирования. В данных ситуациях стараются опросить экспертов, далее, экспертные оценки индивидуального и коллективного разума, применяют как конечные прогнозы или в качестве исходных данных в комплексных системах прогнозирования.
Рисунок 2.1 - Классификационная схема методов прогнозирования
Глубина упреждения прогноза является одним из первостепенных показателей прогноза. В таком случае, важно знать не только абсолютную величину данного показателя, но и сопоставить ее с промежутком эволюционного цикла развития данного объекта прогнозирования. При таком раскладе, представляется возможным задействовать безразмерный показатель глубины (дальности) прогнозирования (ф), который был предложен В. Белоконем

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
