


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Однако использование последнего соотношения затруднено тем, что достоверно определить ![]()
![]() и
и ![]()
![]() из исходной информации очень сложно.
из исходной информации очень сложно.
Выбор параметра б целесообразно связывать с точностью про - гноза, поэтому для более обоснованного выбора б можно использо - вать процедуру обобщенного сглаживания, которая позволяет полу - чить следующие соотношения, связывающие дисперсию прогноза и параметр сглаживания.
Для линейной модели –
![]()
![]() . (1.13)
. (1.13)
Для квадратичной модели –
![]()
![]() (1.14)
(1.14)
Для обобщенной модели вида
![]()
![]() . (1.15)
. (1.15)
Дисперсия прогноза имеет следующий вид
![]()
![]() , (1.16)
, (1.16)
где ![]()
![]() – среднеквадратическая ошибка аппроксимации исходного динамического ряда; fi(t) – некоторая известная функция; V – матрица ковариации коэффициентов модели. Отличительная особенность этих формул состоит в том, что при б = 0 они обращаются в нуль. Это объясняется тем, что, чем ближе к нулю б, тем больше длина исходного ряда наблюдений t → ∞ и, следовательно, тем меньше ошибка прогноза. Поэтому для уменьшения ошибки прогноза необходимо выбирать минимальное б.
– среднеквадратическая ошибка аппроксимации исходного динамического ряда; fi(t) – некоторая известная функция; V – матрица ковариации коэффициентов модели. Отличительная особенность этих формул состоит в том, что при б = 0 они обращаются в нуль. Это объясняется тем, что, чем ближе к нулю б, тем больше длина исходного ряда наблюдений t → ∞ и, следовательно, тем меньше ошибка прогноза. Поэтому для уменьшения ошибки прогноза необходимо выбирать минимальное б.
В то же время параметр б определяет начальные условия, и, чем меньше б, тем ниже точность определения начальных условий, а следовательно, ухудшается и качество прогноза. Ошибка прогноза растет по мере уменьшения точности определения начальных условий.
Проектирование информационной системы прогнозирования
Определение подхода и модели прогнозирования
На мой взгляд, для наилучшего решения данной задачи, лучше всего использовать комбинированный подход, объединяющий метод статистических данных и метод архивных данных. Так как при поддержке модуля, который бы реагировал на внеплановые происшествия, наша система давала бы максимально точный прогноз времени прибытия транспорта.
Теперь основной задачей было определить алгоритм, или модель, по которому делать прогноз. После долгого изучения, мной было выделено основные 2 алгоритма: алгоритм скользящего среднего и алгоритм экспоненциального сглаживания. При дальнейшей работе я остановился на первом, так как он обладает рядом достоинств, ниже я расскажу какими.
Я остановился на этих двух алгоритмах, так как при моем подходе архивных данных, мы будем иметь дело с многочисленными данными временных рядов, а эти две модели просто и точно находят общую тенденцию и закономерности.
Построение модели
Моя основная задача в данной работе - разработка системы прогнозирования прибытия транспорта на места его остановок. Я решил для удобства пользователя создать веб-приложение, которое бы показывало время до прибытия следующего автобуса/троллейбуса с минимальной погрешностью. Геолокация пользователя определяется автоматически, при первом заходе на данный сервис. Схему работы моего приложения можно увидеть на рисунке 3.1.
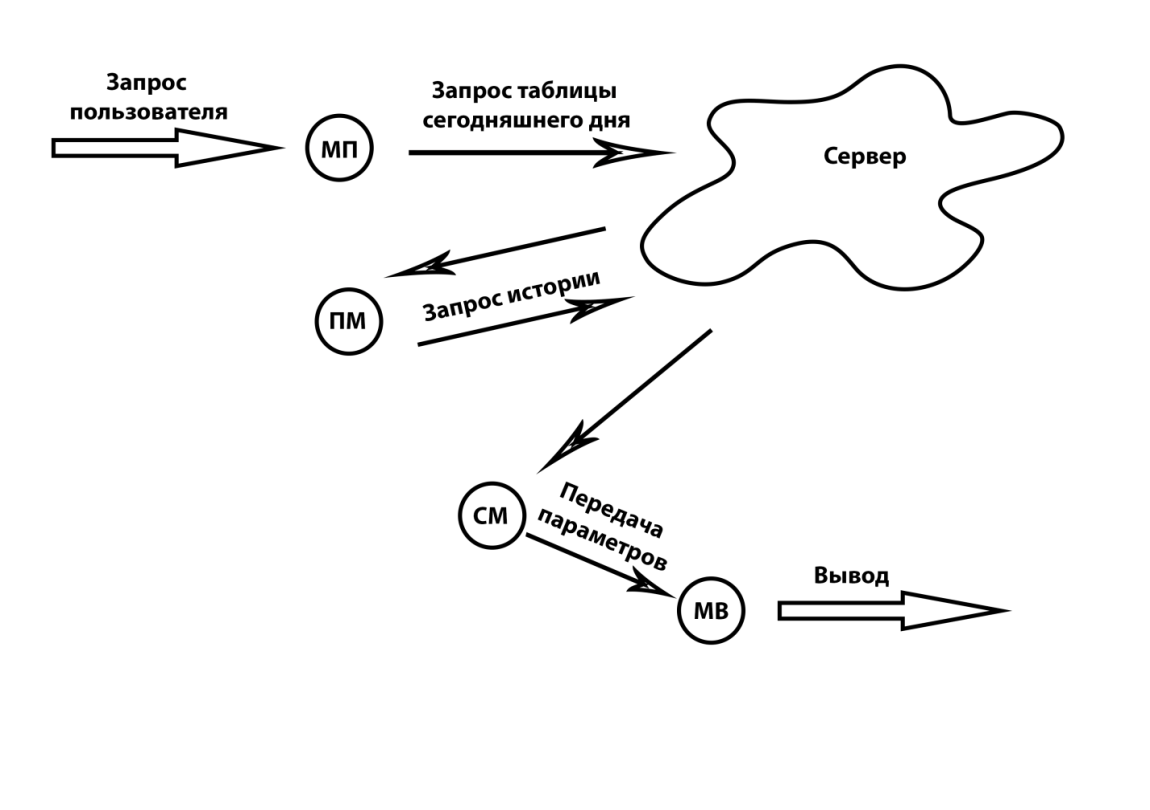
Рисунок 3.1 – Схема работы моего приложения
МП (модуль приема) – определяет геолокацию пользователя, сопоставляет местоположение его с остановками, получает id остановок в радиусе 100 метров. Отправляет на сервер запрос истории движения этого маршрута сегодня.
ПМ (поисковый модуль) – получает таблицы движений маршрутов сегодня, определяет ближайшие автобусы/троллейбусы, которые будут на остановке пользователя, берет их id и время, когда они были на предыдущей остановке, отправляет на сервер запрос истории движения этих автобусов в это время в другие дни.
СМ (самообучающийся модуль) – получает историю движения этих автобусов в другие дни. Подсчитывает, для прошлого понедельника, период прогноза для метода скользящее среднее, который бы выдавал наиболее точное значение. Передает эти значения следующему модулю.
МВ (модуль вывода) – получает периоды прогноза от прошлого модуля, считает по методу скользящее среднее ориентировочное время, в которое приедут автобусы на остановку пользователя, вычитает время текущее и выводит результат, также прибавляет половину времени отклонения прошлого ближайшего автобуса от обычного, в целях учета непредвиденных пробок.
Определение переменных факторов, влияющих на работу системы
Так как дело мы имеем с временными рядами, для начала разберемся с целями и проблемами общего масштаба.
Существуют две основные цели анализа временных рядов:
определение природы ряда прогнозирование (предсказание будущих значений временного ряда по настоящим и прошлым значениям).Обе эти цели требуют, чтобы модель ряда была идентифицирована и, более или менее, формально описана. Как только модель определена, вы можете с ее помощью интерпретировать рассматриваемые данные (например, использовать в вашей теории для понимания сезонного изменения цен на товары, если занимаетесь экономикой). Не обращая внимания на глубину понимания и справедливость теории, вы можете экстраполировать затем ряд на основе найденной модели, т. е. предсказать его будущие значения.
Так как временные ряды в большинстве случаев применяются для анализа экономических составляющих, то буду рассказывать на примере их.
Систематическая составляющая и случайный шумНаряду с другими видами математических анализов, анализ временных рядов включает в себя то, что содержащиеся данные имеют систематическую составляющую (обычно включающую несколько компонент) и случайный шум (ошибку), который в свою очередь значительно усложняет возможность обнаружения регулярных компонент. Почти все методы исследования временных рядов используют разного рода алгоритмы для фильтрации шума, которые позволяют рассмотреть регулярную составляющую более детально.
Два общих типа компонент временных рядов
Подавляющее большинство регулярных составляющих временных рядов можно разделить на две группы: либо в свою очередь они являются трендом, либо составляющей сезонного типа.
Тренд является общей систематической линейной или нелинейной компонентом, периодически изменяющимся или не изменяющимся во времени.
Сезонная составляющая - это компонента, которая периодически повторяется во времени.
Зачастую наблюдается присутствие этих двух компонент в ряде одновременно. Например, продажи компании могут возрастать из года в год, но они также содержат сезонную составляющую (как правило, 25% годовых продаж приходится на декабрь и только 4% на август).
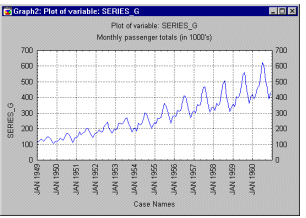
Рисунок 3.2 – Пример графа продаж компании
Эту общую модель можно понять на "классическом" ряде - Ряд G (Бокс и Дженкинс, 1976, стр. 531), представляющем месячные международные авиаперевозки (в тысячах) в течение 12 лет с 1949 по 1960 (см. файл Series_g. sta). График месячных перевозок ясно показывает почти линейный тренд, т. е. имеется устойчивый рост перевозок из года в год (примерно в 4 раза больше пассажиров перевезено в 1960 году, чем в 1949). В то же время характер месячных перевозок повторяется, они имеют почти один и тот же характер в каждом годовом периоде (например, перевозок больше в отпускные периоды, чем в другие месяцы). Этот пример показывает довольно определенный тип модели временного ряда, в которой амплитуда сезонных изменений увеличивается вместе с трендом. Такого рода модели называются моделями с мультипликативной сезонностью.
Анализ трендаНа сегодняшний день не имеется определенного метода или способа для того, чтобы "автоматически" обнаружить тренд во временном ряде. Впрочем, если наблюдается монотонный тренд, а то есть неизменно возрастающий или убывающий, то для такого ряда достаточно легко получить ряд сведений в результате анализа. При всем это, зачастую, большинство временных рядов содержат в той или иной мере значительную ошибку, в таком случае, для обнаружения тренда первым шагом производится операция сглаживание.
При применении сглаживания, преимущественно во всех случаях разного рода способы для локального усреднения данных, вследствие которых, компоненты несистематического характера взаимно воздействуют друг на друга, при этом погашая влияние последних и себя, в том числе, на тренд. Самый часто применяемый метод для сглаживания временных рядов - скользящее среднее, при котором каждое значение ряда заменяется простым или взвешенным средним n соседних значений, где n - ширина "окна. Помимо метода скользящего среднего применяется также способ использования медианы значений, попавших в окно. Главным преимуществом такого медианного сглаживания, по сравнению со сглаживанием скользящим средним, является то, что полученные значения меньше подлежат воздействию ко всяким выбросам (имеющимся внутри окна). Таким образом, при имеющихся в данных выбросах (например, связанные с ошибками измерений), применение метода сглаживания медианой обычно приводит к более гладким кривым на выходе (или, по крайней мере, более "надежным" кривым, по сравнению со скользящим средним с тем же самым окном). Основным недостатком медианного сглаживания это то, что при недостатке, а может и отсутствии определенных выбросов, зачастую приводит к более "зубчатым" кривым (чем сглаживание скользящим средним) и не позволяет использовать веса.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
