


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
// Предполагается, что на странице подключен jQuery
var $container = $('YMapsID'),
bounds = res. geoObjects. get(0).properties. get('boundedBy'),
Ниже представлен фрагмент кода, полную версию можно увидеть в «ПРИЛОЖЕНИИ А» под пунктом «Листинг кода определяющего местоположение»:
:
Определение id нужного автобуса
После того, как определено местоположение пользователя, а значит, определена текущая остановка пользователя, стоит задача определить, какой из автобусов ближе всего к его местоположению и на какой стоит нам делать прогноз.
Для этого я использую следующий алгоритм:
По определению, если автобус в день, который нас интересует, не был на какой-либо остановке, то соответствующая ячейка имеет значение NULL, в противном случае, там находится время прибытия текущего автобуса на соответствующую остановку. А значит, если перебирать значения сверху вниз в поисках первого значения NULL, то таким образом мы найдем ближайший автобус, которые ещё не был на текущей остановке.
Допустим, мы находимся на 3 остановке, сейчас на часах 6:04. Значит, начиная с первого автобуса, по 3 столбику движемся вниз в поисках первого значения NULL. Такое значение выпадает на автобус под идентификатором №2. А значит, нам следует ожидать прибытие автобуса №2.
id | Id_bus | Date | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
1 | 1 | 17.05 | 5:45 | 5:47 | 5:50 | … | … | … | … |
2 | 2 | 17.05 | 6:01 | 6:03 | null | null | null | null | null |
3 | … | … | null | null | null | … | |||
4 | 1 | 18.05 | … | .. | … | ||||
… | 2 | 18.05 |
Возможна такая ситуация, когда найденный автобус ещё не был на прошлой остановке.
id | Id_bus | Date | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
1 | 1 | 17.05 | 5:45 | 5:47 | 5:50 | … | … | … | null |
2 | 2 | 17.05 | 6:01 | null | null | null | null | null | null |
3 | … | … | null | null | null | … | |||
4 | 1 | 18.05 | … | .. | … | ||||
… | 2 | 18.05 |
Например, мы по-прежнему стоим на 3 остановке, и по предыдущему алгоритму ждем автобус №2, но он не был также и на 2 остановке, а значит, стоит учитывать время, за которое он доедет сначала до 2, а потом ещё и до 3.
А то есть, когда мы обнаружили первое значение NULL в определенном столбике, нам следует идти влево, до первой ячейки, которая бы хранила в себе не пустое значение. Таким образом, мы получаем id нужного автобуса и время, в которое он прибыл на предыдущую остановку.
Листинг кода, можно найти в «ПРИЛОЖЕНИИ А» под пунктом «Листинг кода, определения id автобуса».
Запрос истории движения автобуса под определённым id
После того, как нам стало известно, какой автобус мы ждем, там стоит запросить у сервера историю прохождения данного автобуса по этому участку в другие дни. Я образно разделил все дни на выходные и будние. Разумеется, при наличии большого объема данных, можно будет делать более тщательную выборку.
Допустим сегодня вторник, значит, запрашиваем историю за несколько предыдущих будних дней.
Листинг соответствующего фрагмента кода:
# Считаем среднее время в пути на этом участке
$strSQL2 = "SELECT * FROM bus5_history WHERE id_bus = '$id_bus'";
$rs = mysql_query($strSQL2);
Самообучающийся модульТак как трудно сказать, какой лучше всего использовать интервал прогнозирования (5, 10, или любое другое число дней), было решено создать модуль, который для предыдущего дня, считает прогнозируемое время прибытия для соответствующего автобуса на данном отрезке пути. Модуль перебирал все промежутки, определяя тот, который в совокупности с известным реальным временем движения, даст наиболее точный результат.
Ниже можно увидеть фрагмент кода, полный листинг данного кода лежит в «ПРИЛОЖЕНИИ А» под пунктом «Листинг самообучающегося модуля».
$strSQL= "INSERT INTO bus5_history (`time_inquiry`,`time_last_stop`,`station`,`Geolocation`, `id bus`) VALUES ('$time_now','$s','1','$geo_location','$i3');";
mysql_query($strSQL) or die (mysql_error());
$file = 'id. txt';
$iid = file_get_contents($file);
$iid=$iid+1;
file_put_contents($file,$iid, LOCK_EX);
$s=strtotime("$s");
$time_now=strtotime("$time_now");
for ($i=1; $i <=10 ; $i++) {
$sss=$s-$time_now-$p1;
$sss = date("H:i:s", $sss);
$strSQL="UPDATE bus5n SET `$i`='$sss' WHERE id = '$iid'";
mysql_query($strSQL) or die (mysql_error());
}
}
Использование скользящего среднего
Зная, какой промежуток наиболее оптимальный, подсчитываем для нашего автобуса предполагаемое время прохождения этого промежутка, суммируя все значения времени и применяя операцию деления на количество значений.
Вот фрагмент кода, полный листинг данного кода лежит в «ПРИЛОЖЕНИИ А» под пунктом «Листинг скользящего среднего».
# Считаем среднее время в пути на этом участке
$strSQL2 = "SELECT * FROM bus5_history WHERE id_bus = '$id_bus'";
$rs = mysql_query($strSQL2);
$time_varible=$date_now-259200;
$time_varible1=date("o-m-d",$time_varible);
//echo "$time_varible1 ";
$summALL=0;
Модуль учета непредвиденных пробок.
Для сглаживания погрешности в случае возникновения непредвиденных ситуаций на дороге, например перекрытие дороги в честь праздника 9 мая, был создан данный модуль. Он учитывает изменение во времени прохождения предыдущего автобуса по этому участку. К примеру, автобус №3 мы ждем, значит, если автобус №2, проходя наш участок, задержался на 5 минут, относительно его обычного движения, значит, возможна непредвиденная пробка.
Данных модуль делит время отклонения от движения предыдущего автобуса пополам и прибавляет его к текущему прогнозируемому времени.
Ниже предоставлен фрагмент кода, полный листинг данного кода лежит в «ПРИЛОЖЕНИИ А» под пунктом «Листинг модуля учета непредвиденных пробок».
$strSQL2 = "SELECT * FROM bus5n WHERE id = '$iid'";
// Выполнить запрос (набор данных $rs содержит результат)
$rs = mysql_query($strSQL2);
# Каждый ряд становится массивом ($row) с помощью функции mysql_fetch_array
while($row = mysql_fetch_array($rs)) {
$s1=0;
for ($i=2; $i <= 10; $i++) {
$s= $row["$i"];
$ss= $row["1"];
$s=strtotime("$s");
$ss=strtotime("$ss");
$s1=$s1+$s;
$s2=$ss-($s1/($i-1));
if ($i==3) {$s3=$s2; $s4=3;}
if ($i>4) {
if (($s2*$s2)<($s3*$s3)) {
Вывод времениПолучая все значения, находим среднее между ними всеми и выводим пользователю.
Итоги вывода можно увидеть на рисунке 4.5, а листинг кода в «ПРИЛОЖЕНИИ А» под пунктом «Листинг кода выводящего время»
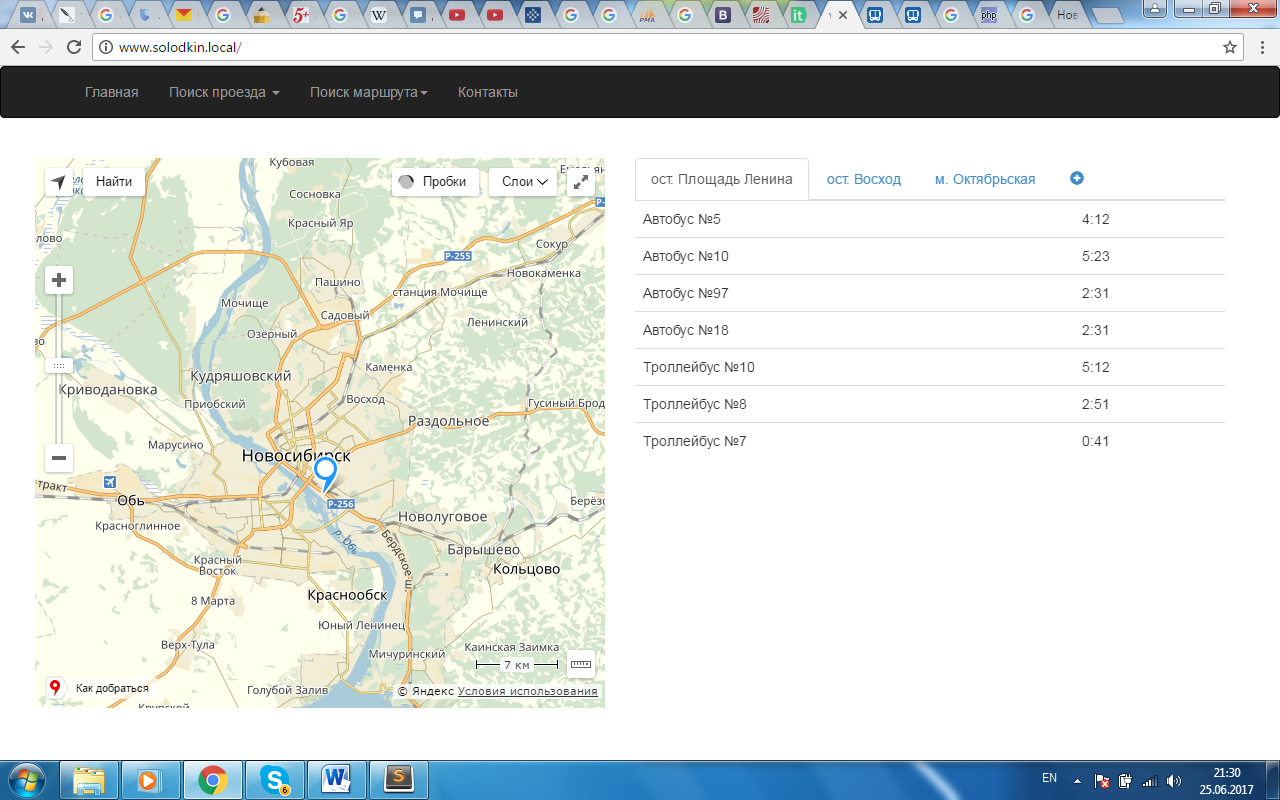
Рисунок 4.5 Вывод времени пользователю
заключениеНа сегодняшний день, текущий уровень научно-технического прогресса позволяет создавать сложные системы, которые в значительной мере облегчают жизнь людям. Так, с помощью достаточно затратной, но незаменимо полезной возможности мониторинга объектов по средствам спутниковой системы ГЛОНАСС, транснациональной компании Яндекс удалось создать потрясающую систему прогнозирования общественных транспортных маршрутов Яндекс. Транспорт.
По итогам работы, были подробно изучены разные виды прогнозирования. Рассмотрена их классификация. Подробно изучены 2 метода прогнозирования, посредствам использования временных рядов.
Также были более детально изучены возможности инструментов веб-разработки, такие как:
- Мультипарадигменный скриптовый язык общего назначения PHP, позволяющий создавать динамические объекты, а также производить вычисления.
- Каскадная таблица стилей CSS, помогающая разработчику создать более адаптивное оформление сайта.
- Библиотека bootstrap, упрощающая создание веб-интерфейса, посредствам уже имеющихся шаблонов. Кроссплатформенная реляционная система управления базами данных MySQL. JavaScrirt XAMPP И т. д.
Были использованы бесплатные технологии Яндекс, такие как Яндекс. Карты, Яндекс. Навигация, Яндекс. Пробки, вследствие использования соответствующих API. Также были изучены принципы действия некоторых сервисов данной компании.
Реализована веб-система прогнозирования, использующая архивные данные, хранящие историю движения транспорта за большой промежуток времени.
Это простая рабочая система, позволяющая пользователю в короткий срок узнать прогнозируемое время прибытия нужного ему автобуса на остановку. Данная система базируется на математическом алгоритме, который называется скользящее среднее. Так как он, на мой взгляд, давал хороших прогноз с высоким показателем точности, при всем этом был не затратным, с точки зрения вычислительных ресурсов, и как следствие - прост для реализации.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
