
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral

Рисунок В1.
На экране появится стартовая панель модуля Clustering Method (методы кластерного анализа): Joining (tree clustering) (иерархические агломеративные методы или древовидная кластеризация), K - means clustering (метод К средних), Two-way joining (двувходовое объединение).

Рисунок В2.
Joining (tree clustering) (иерархические агломеративные методы).
Откроем файл (Open Data) или же можно создать новую таблицу данных в самой программе. После выбора Joining (tree clustering) и нажатия кнопки ОК появляется окно Cluster Analysis: Joing (Tree Clustering) (окно ввода режимов работы для иерархических агломеративных методов), в котором кнопка Variables позволяет выбрать переменные участвующие в классификации. Нажмем на кнопку Variables и выберем все переменные Select All. После соответствующего выбора и нажмем кнопку OK

Рисунок В3.
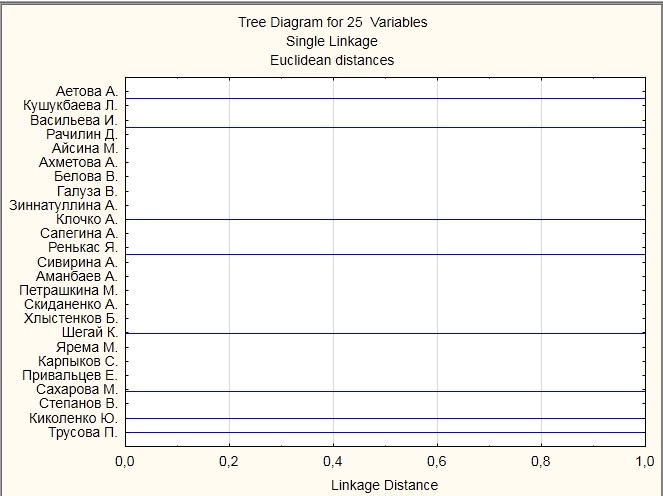
Рисунок В4.
Метод одиночной связи, также он известен как метод ближнего соседа. Кластерный анализ ищет сначала те объекты, которые очень близки друг другу. Минус метода в том, что трудно определить, как много кластеров находится в данных.
Второй метод - метод полной связи по-другому звучит как метод дальнего соседа
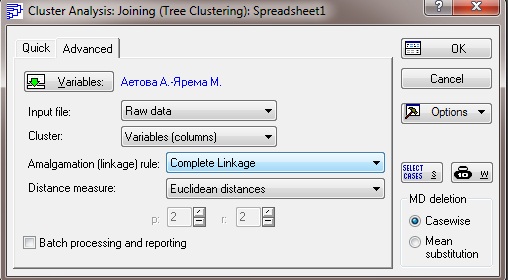
Рисунок В5.
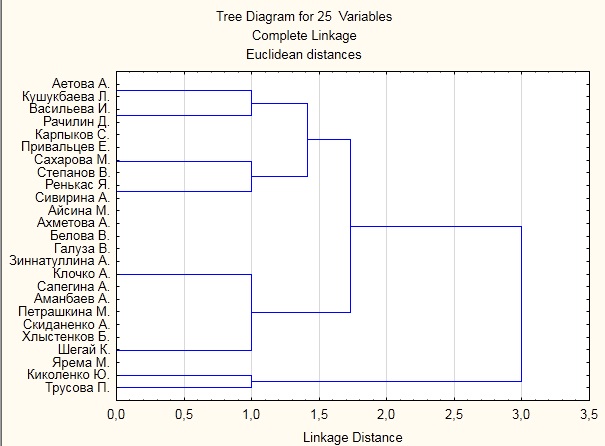
Рисунок В6.
Как видите этот метод более удачнее для выявления классов. Если в первом случае мы увидели отдельные линии, то сейчас видно сколько кластеров показано на дендограмме.
Третий метод – это метод К-средних.
Из стартовой панели модуля Clustering Method (методы кластерного анализа) выберем K - means clustering (метод К средних). Откроем файл (Open Data) .
После нажатия кнопки ОК появляется окно Cluster Analysis: K - means clustering (метод К средних), в котором кнопка Variables позволяет выбрать переменные участвующие в классификации. Нажмем на кнопку Variables и выберем все переменные Select All.
Рисунок В7.
После соответствующего выбора нажмем кнопка OK. Будут произведены вычисления и появится новое окно: "K - Means Clustering Results" .
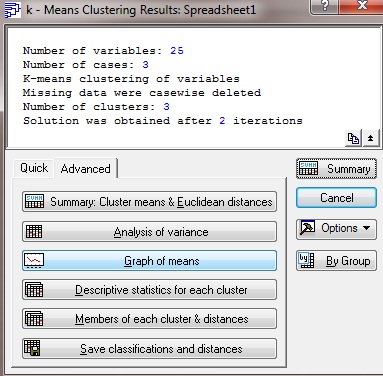
Рисунок В8.
Вывод результатов и их анализ
В верхней части окна (в том же порядке, как они идут на экране):
- Количество переменных; Количество наблюдений; Классификация наблюдений (или переменных, зависит от установки в предыдущем окне в строке Cluster) методом K - средних; Наблюдения с пропущенными данными удаляются (или: изменяются средними значениями. Зависит от установки в предыдущем окне в строке Missing data). Количество кластеров; Решение достигнуто после : итераций.
В нижней части окна расположены кнопки для вывода различной информации по кластерам.
Graph of means представляет собой графическое изображение информации содержащейся в таблице, выводимой при нажатии кнопку Analysis of Variance (анализ дисперсии). На графике показаны средние значения переменных для каждого кластера.
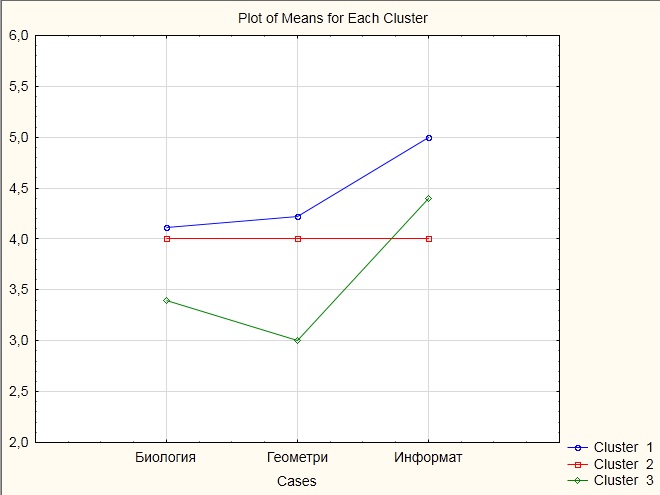
Рисунок В9.
По горизонтали отложены участвующие в классификации переменные, а по вертикали - средние значения переменных в разрезе получаемых кластеров.
Members for each cluster & distances. Выводится столько окон, сколько задано классов. В каждом окне указывается общее число элементов, отнесенных к этому кластеру, в верхней строке указан номер наблюдения (переменной), отнесенной к данному классу и евклидово расстояние от центра класса до этого наблюдения (переменной). Центр класса - средние величины по всем переменным (наблюдениям) для этого класса.
Средние значения по трем кластерам приведены ниже в таблице В2.
Таблица В2.
Кластер 1 | Кластер 2 | Кластер 3 | |
биология | 4,1 | 4 | 3,4 |
геометрия | 4,1 | 4 | 3 |
информатика | 5 | 4 | 4,4 |

Рисунок В10.
Вывод: Применив метод К-средних получено три кластера. В первый кластер вошли ученики, у которых средний балл по таким предметам как биология, информатика и геометрия выше оценки 4. Во второй кластер вошли учащиеся, у которых средний балл составляет ровно 4. И в третий, те, у кого средний бал по данным предметам ниже четверки.
Заключение
Увеличение знаний об окружающем мире остро ставят вопрос о поиске технологий для сжатия и классификации больших объемов информации. В современной школе одной из проблем является отсутствие методик для выше указанных задач, именно кластерный анализ является тем инструментом, облегчающий решение.
Кластерный анализ помогает наглядно рассмотреть подъем и спад каждого ученика по предметам.
В первой главе рассмотрены такие понятия как метрика, объект, плотность, признак, коэффициент корреляции. Сформулировано понятие «Кластерный анализ» и раскрыты все основные аспекты касающиеся данной темы. Показаны различные области применения кластерного анализа.
Во второй главе раскрыты самые основные методы кластерного анализа.
Рассматриваются такие методы как метод ближнего соседа, метод дальнего соседа, метод К-средних.
В третьей главе показана связь теории с практикой. Проведены исследования, показывающие важную роль математического метода кластерного анализа в современной школе.
Сейчас группу способов и алгоритмов, применяемых для автоматической сортировки этих данных, принято именовать кластерным анализов. Кластерный анализ дает рассматривать довольно большой размер информации и резко уменьшать, сжимать огромные массивы общественной и социальной информации, делать их малогабаритными и наглядными.
За счет этого наглядно можно проследить динамику уровня образования, количество успевающих и отстающих, занятие в каких либо кружках или секциях.
Цель дипломной работы выполнена в полном объеме:
- изучены основные математические модели кластерного анализа;
- предложен алгоритм и основные этапы решения предлагаемых методов;
- обосновано использование математических методов кластерного анализа в общеобразовательной школе;
- изучено и обосновано целесообразность использование математического пакета Statistica.
В ходе работы были решены следующие задачи:
- применен теоретический материал по математическим методам кластеризации;
- проведен анализ и алгоритм решения предлагаемых моделей в дипломной работе;
- теоретически обоснован и экспериментально подтверждена эффективность предложенных методов с использованием пакета Statistica.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ.
- Кластерный анализ и классификация: предпосылки и основные направления. В кн: Классификация и кластер /Под ред. Дж. Вэн Райзина М: Мир, 1980, стр. 7-19. Статистический словарь. М.: Финансы и статистика, 1989,стр. 623. Основы теории систематики: Учебное пособие. М.: Открытый лицей ВЗМШ, Диалог-МГУ, 1999, стр.56. Кластерный анализ. М.: Финансы и статистика, 1988, стр.176 Теория вероятностей и математическая статистика: Учебное пособие для вузов. М.: Высшая школа, 2004, стр. 479. Факторный, дискриминантный и кластерный анализ. М:Финансы и статистика, 1989, стр. 215. , , О структуре и содержании пакета программ по прикладному статистическому анализу//Алгоритмическое и программное обеспечение прикладного статистического анализа.—М., 1980. , Бежаева 3. И., Классификация многомерных наблюдений.—М.: Статистика, 1974. , Об анализе структуры матрицы коэффициентов связи//Вопросы экономико-статистического моделирования и прогнозирования в промышленности.— Новосибирск, 1970. , Структурные методы обработки данных.— М.: Наука, 1983. Большая советская энциклопедия: В 30 т. М.: Советская энциклопедия, 1969-1978. Интернет ресурсы: http://dic. academic. ru/dic. nsf/ruwiki/238149 . Федоров- Статистические методы в археологии. - М.: Высшая школа, 1987, стр. 216. Типология и классификация в социологических исследованиях. Отв. ред. , . М.: Наука, 1982, стр.296. Кластерный анализ. - М.: Финансы и статистика. 1988. - 176с. Математические методы и модели в экономике, стр.302. Интернет ресурсы: https://ru. wikipedia. org/wiki/Кластерный анализ Факторный, дискриминантный и кластерный анализ: Пер с англ./Дж. - О. Ким, , и др.; Под ред. . - М.: Финансы и статистика, 1989. Стр.215. ластерный анализ. - М.: Статистика, - 1977, стр.128. Классификация и кластер. /Под ред. Дж. Вэн Райзина. - М.: Мир, 1980, стр.390.
Решение задач методом ближнего соседа в программе Statistica.
Рассмотривается малая группа учеников из 8 человек. У которых ![]()
![]() это характеристика оценок по предмету алгебра,
это характеристика оценок по предмету алгебра, ![]()
![]() это характеристика оценок учащихся по предмету геометрия.
это характеристика оценок учащихся по предмету геометрия.
Заполним таблицу в программе Statistica:
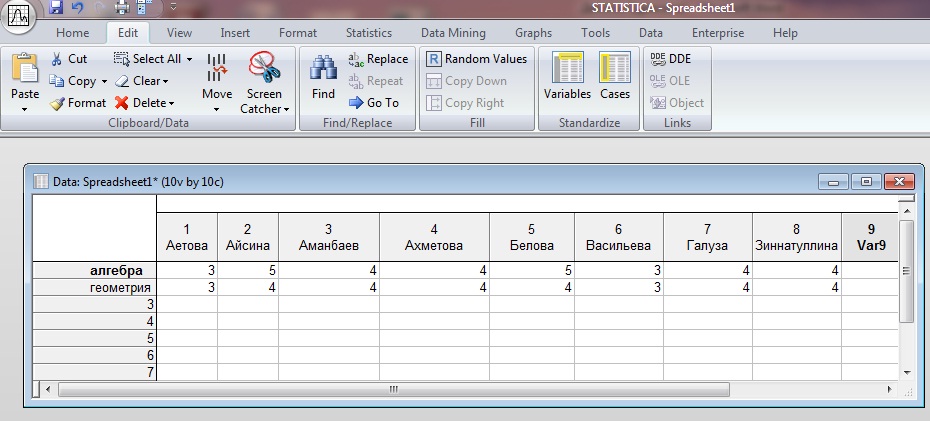
Рисунок А1.
Выделяем исследуемые объекты:
Рисунок А2.
Выбираем в Statistics графу Cluster
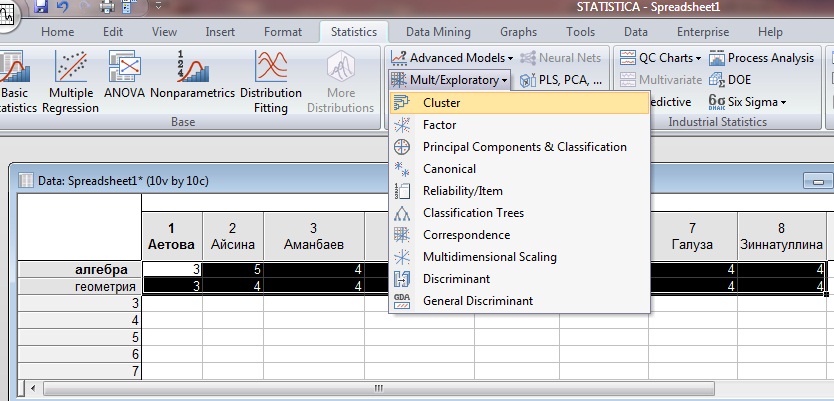
Рисунок А3.
В появившемся окне выбираем нужный метод. В данной задаче выбираем метод ближнего соседа.
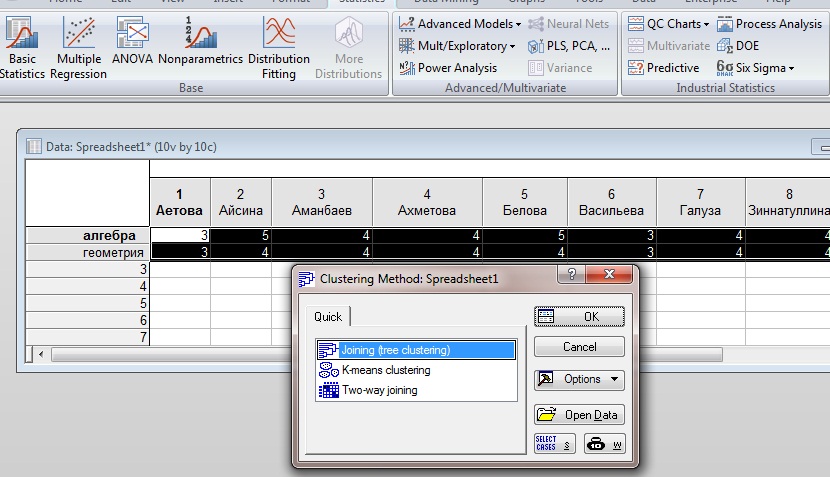
Рисунок А4
Выбираем вид дендограммы.
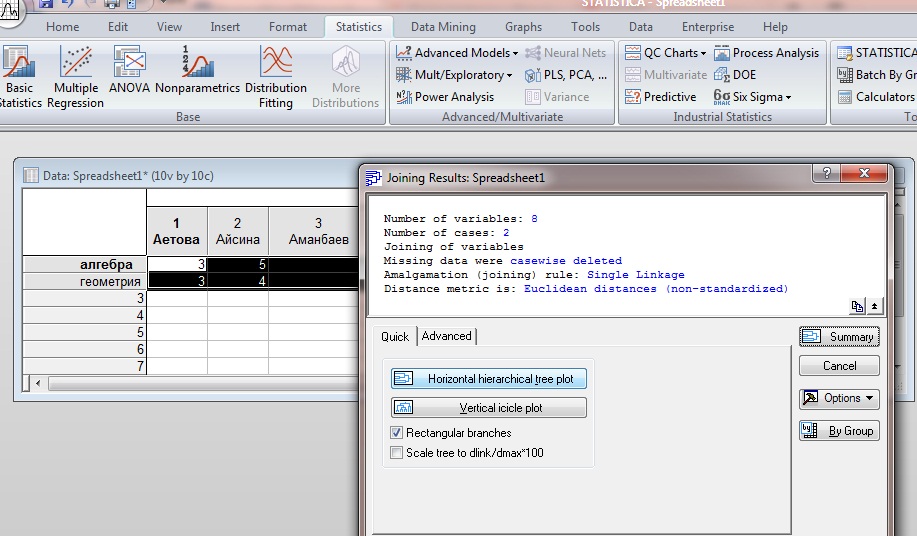
Рисунок А5
Применив « метод ближнего соседа » получим дендограмму, котора имеет вид показанный на рисунке A6.
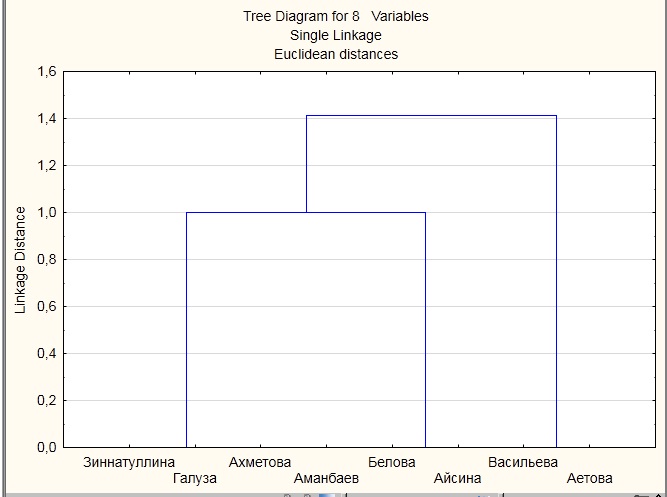
Рисунок А6.
Разобраться в значении кластеров помогают кластерные профили, которые представляют собой средние значения переменных, которые включены в анализ, распределенные по кластерной принадлежности. Средние значения учащихся по кластерам приведены в таблице A1.
Таблица А1.
Кластер 1 | Кластер 2 | |
Алгебра | 4,3 | 3 |
Геометрия | 4 | 3 |
Вывод: Применив метод ближнего соседа, получено два кластера. В первый кластер вошли 6 человека ( ). Во второй 2 человека ( ). В первый кластер вошли ученики, у которых средний бал по предмету больше 4. Во второй кластер вошли учащиеся, у которых средний бал по предмету равен 3.
Необходимо рассмотреть малую группу учащихся из 6 человек, которые прошли 6 различных теста.
Шаг 1. Данные таблицы веды в программу Statistica.
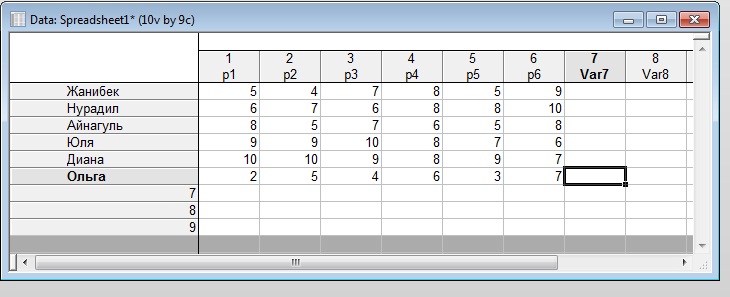
Рисунок Б1.
Шаг 2. Выделяем полученную таблицу. В панели задач выбираем пункт Mult/E[ploratory ?› Cluster.
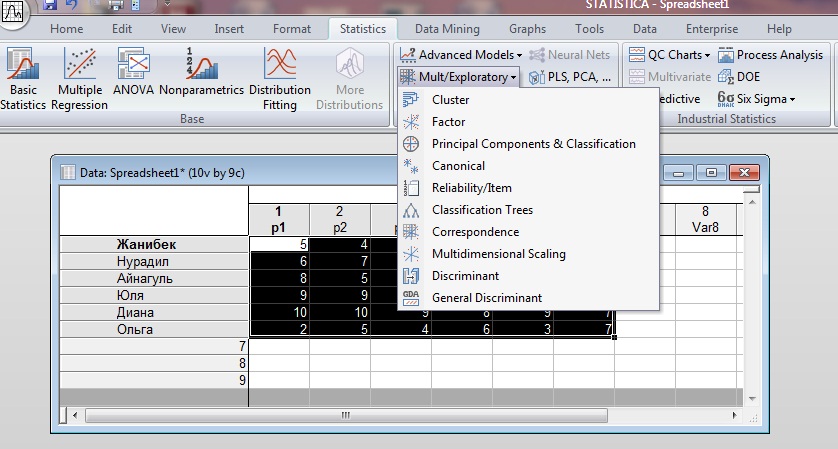
Рисунок Б2.
Шаг 3. Выбираем пункт Cluster. Затем выбираем расстояние, которое хотим рассчитать. В данном случае дальнее расстояние Complete Linkage.
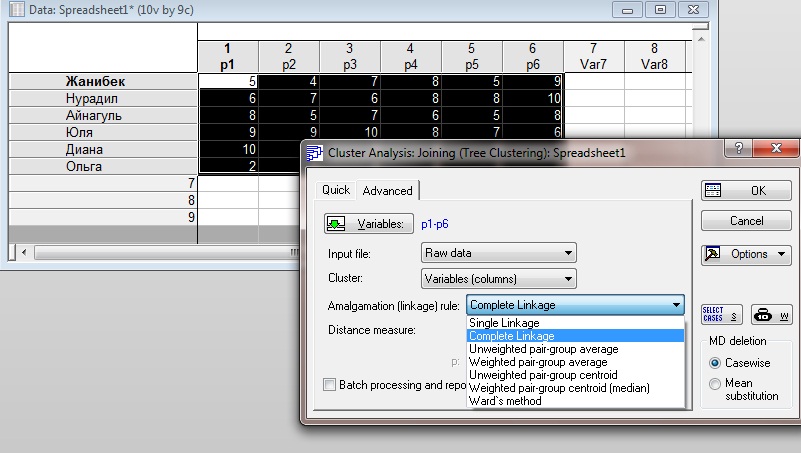
Рисунок Б3.
Шаг 4. Выбираем вид дендограммы: горизонтальную или вертикальную. В данном случае для удобства выбрана вертикальная дендограмма.
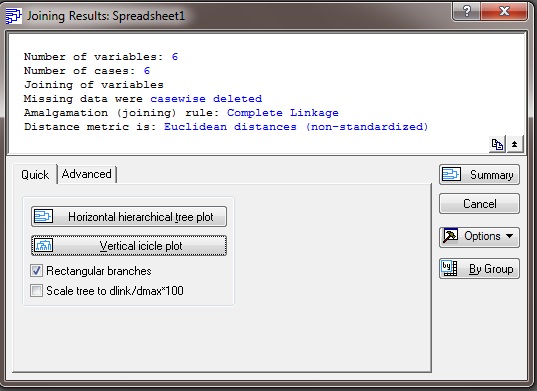
Рисунок Б4.
Шаг 5. Получено два кластера.
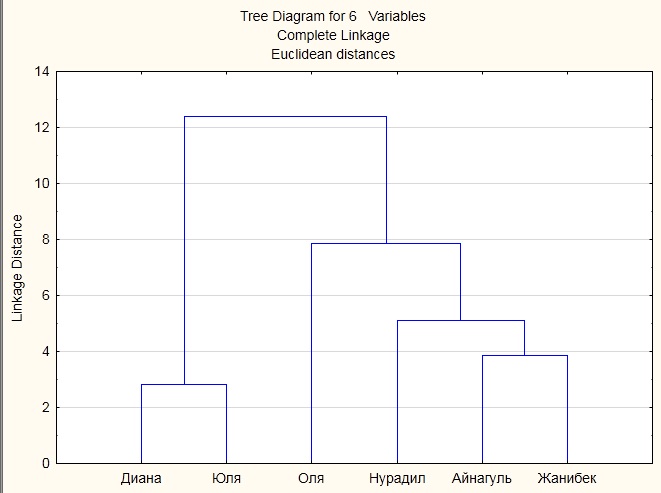
Рисунок Б5.
Вывод: Анализируя дендограмму можно предположить, что в один кластер входят 2 студента (Диана и Юля), в другой 4 человека (Оля, Нурадил, Айнагуль, Жанибек).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
