
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Воспользуемся этой формулой:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Полученные значения приведены в таблице 2.2
Таблица 2.2
1 | 2 | 3 | 4 | 5 | 6 | |
1 | 0 | 2,83 | 3,16 | 10,19 | 12,17 | 13,6 |
2 | 0 | 3,16 | 8,94 | 10,77 | 12,53 | |
3 | 0 | 7,07 | 9,06 | 10,44 | ||
4 | 0 | 2 | 3,61 | |||
5 | 0 | 2,24 | ||||
6 | 0 |
Применим метод «ближнего соседа или одиночной связи».
![]()
![]()
В таблице наименьший элемент находится в 5 столбце и 4 строке.
После объединения 4 и 5 столбца, получена новая таблица значений.
Таблица 2.3
1 | 2 | 3 | 4,5 | 6 | |
1 | 0 | 2,83 | 3,16 | 10,19 | 13,6 |
2 | 0 | 3,16 | 8,94 | 12,53 | |
3 | 0 | 7,07 | 10,44 | ||
4 | 0 | 3,61 | |||
5 | 2,24 | ||||
6 | 0 |
![]()
![]()
Объединим столбцы 4,5,6.
Таблица 2.4
1 | 2 | 3 | 4,5,6 | |
1 | 0 | 2,83 | 3,16 | 10,19 |
2 | 0 | 3,16 | 8,94 | |
3 | 0 | 7,07 | ||
4,5,6 | 0 |
![]()
![]()
Объединим столбцы 1 и 2.
Таблица 2.5
1,2 | 3 | 4,5,6 |
1,2 | 3,16 | 8,94 |
3 | 0 | 7,07 |
4,5,6 | 0 |
![]()
![]()
Таблица 2.6
1,2,3 | 4,5,6 | |
1,2,3 | 0 | 7,07 |
4,5,6 | 0 |
Используя математический пакет Statistica, получена вертикальная дендограмма, изображенная на рисунке 2.1
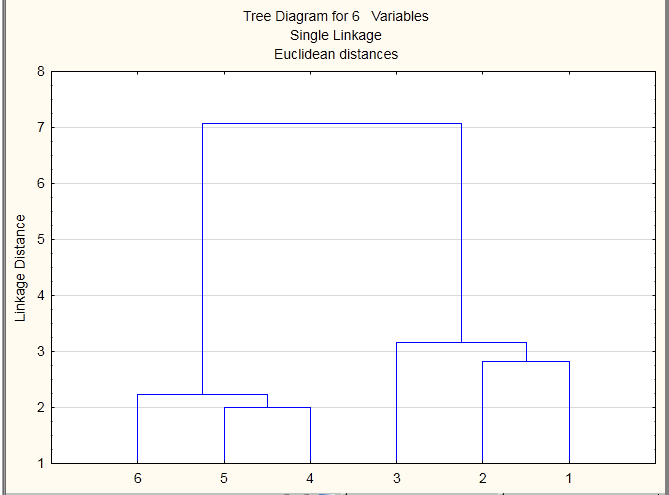
Рисунок 2.1
Вывод: Таким образом, проведя кластерный анализ по методу «ближайшего соседа», получим 2 кластера. Дендограмма при этом имеет вид, показанный на рисунке. Пошаговое решение в программе Statistica показано в приложении А.
2.2 Метод дальнего соседа (Complete linkage clustering).
Кластерный анализ объединяет в кластеры переменные или объекты, которые похожи друг на друга. Иными словами классифицирует, группирует объекты. В целом в психологии он редко используется, то же многомерное шкалирование используется куда чаще и то только психологами наверное. Дело в том, что иногда в некоторых случаях уместно не факторный анализ применять, а кластерный, поскольку метод сам по себе несложный. Кластерный анализ позволяет разбить выборку на нескольку групп по исследуемому признаку. Позволяет посмотреть, как группируются переменные, а также, как группируются объекты. В экономических исследованиях кластерный анализ регулярно используется, чтобы посмотреть например, какие сельские хозяйства похожи друг на друга по производительности. Процедура проведения простая
Открываем программу statistica 10. Заходим на вкладку statistics-mult/exploratory-cluster. Загружаем наши данные. Так, теперь вспоминаем, что кластерный анализ бывает нескольких видов: иерархических и метод к-средних (по-другому его ещё называют дисперсионный анализ наоборот). Начнем с иерархического. Бывает несколько форм иерархического кластерного анализа:
Метод одиночной связи, также он известен как метод ближнего соседа. С ним все просто кластерный анализ ищет сначала те объекты, которые очень близки друг другу. Минус метода в том, что трудно определить, как много кластеров находится в данных
Настраивая параметры кластерного анализа, нужно обратить внимание. На вкладке advanced, cluster рис.2.2
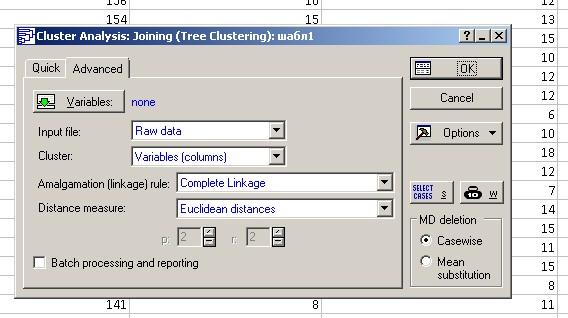
Рисунок 2.2
Есть важное примечание:
Что значит variables (columns)? Это значит, что будет видно как переменные друг с другом классифицируются, а если нажать на cases станет понятна классификация субъектов (испытуемых) по этим переменным, иными словами какие испытуемые сходны по проявлению этого признака.
Если у вас много испытуемых, или если наблюдения не люди, а какие-то объекты, то может получится нагромождение наподобие этого:
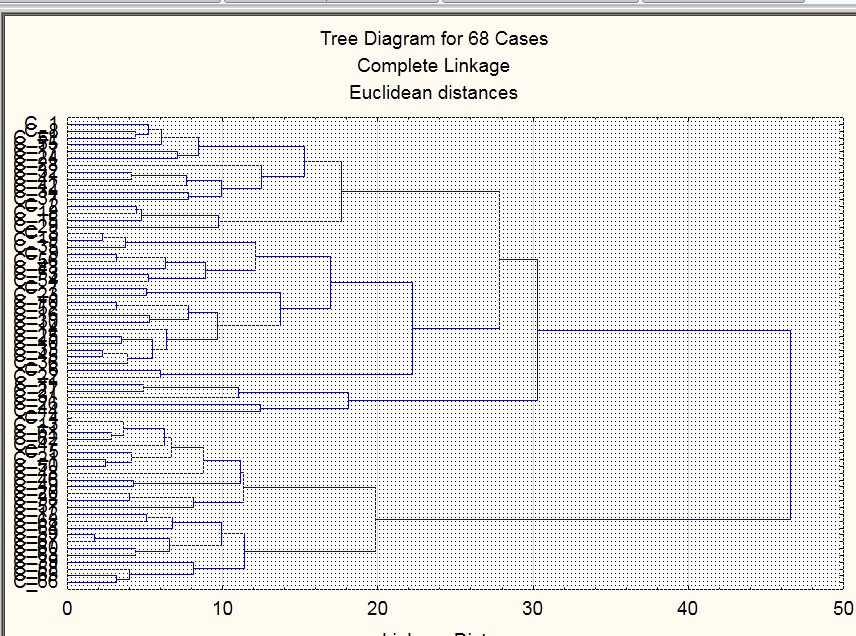
Рисунок 2.3
Возвращаемся к одиночной связи. Выбираем наши данные и видим результат:
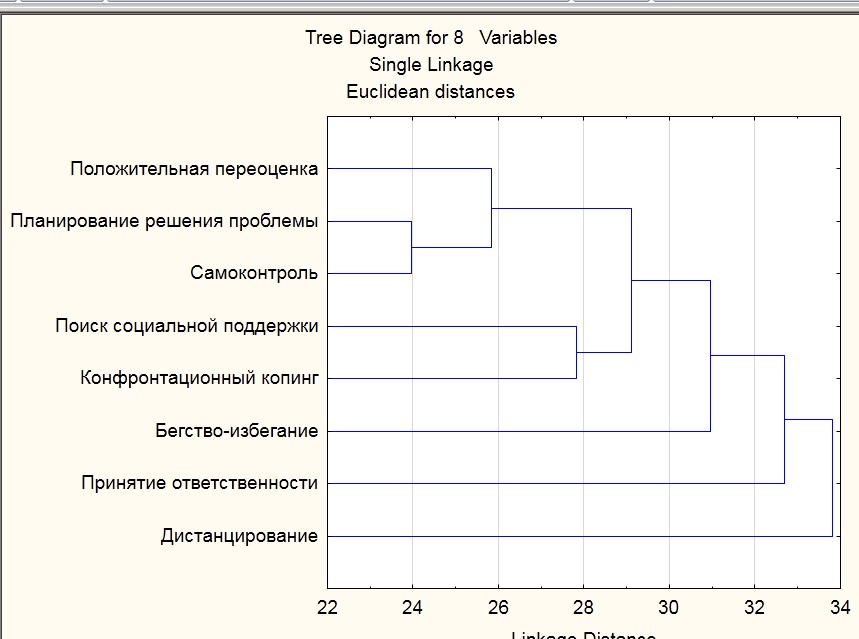
Рисунок 2.4
Например, переменная планирование решении проблемы и самоконтроль объединились в один кластер, а к ним присоединилась переменная положительная переоценка. Происходит другая цепочка. Смотрите переменные поиск социальной поддержки и конфронтационный копинг объединились в кластер и пытаются присоединится к кластеру образованному путем присоединяя положительной переоценке к кластеру планирование решение проблемы и самоконтроль. Значит, эти 3 переменные положительная переоценка, планирование решение проблемы и самоконтроль сгруппировались.
Второй метод - метод полной связи по другому звучит как метод дальнего соседа
Проанализируем результаты, исходя из нижеприведенной дендрограммы.
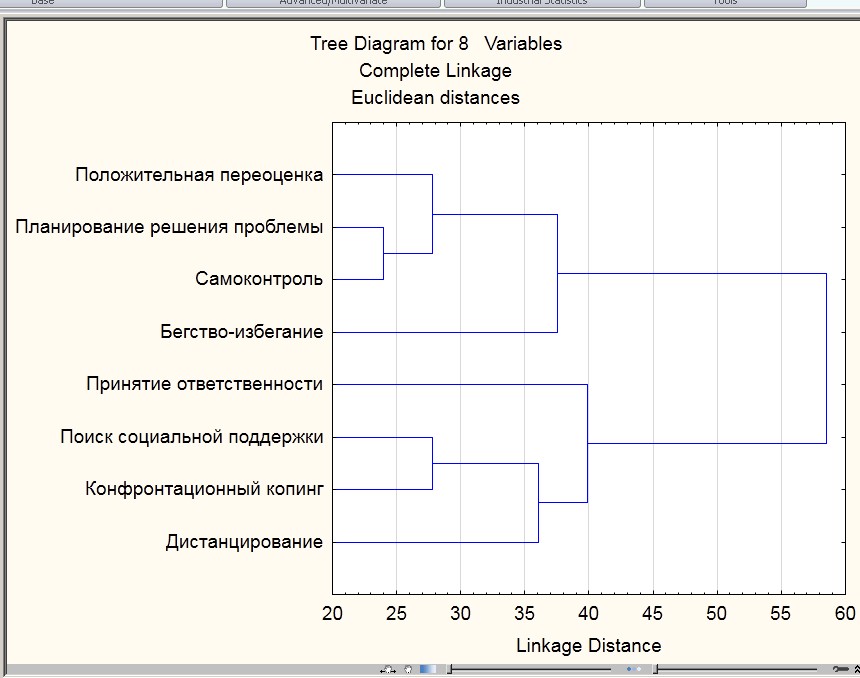
Рисунок 2.5
Видно что этот метод более удачнее для выявления классов. Если в первом случае получено нагромождёние цепочек, то во втором случае, четко выделены кластеры. Внешне эти методы отличаются.
Иными словами метод ближнего сосед старается минимизировать число больших кластеров, а метод дальнего соседа хочет увеличить число компактных кластеров. Возникает вопрос, а сколько нужно выбрать кластеров. Для решения этого вопроса применяется вкладка advanced-graph of amalgamation schedule.
Рисунок 2.6
Наша задача найти точку перегиба.
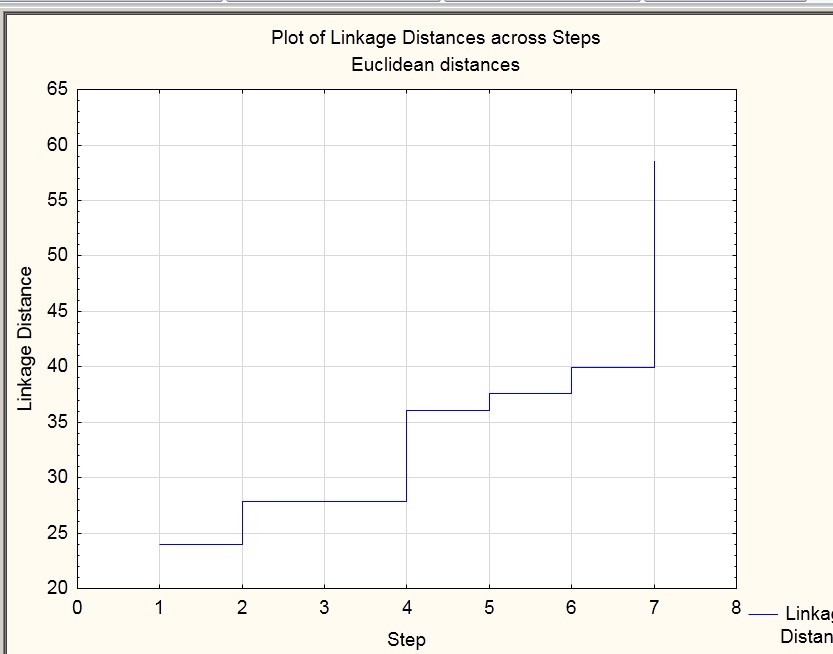
Рисунок 2.7
Тут существенный перегиб идет на 7 шаге кластеризации. Количество классов вычисляется: количество объектов минус количество шагов где начался перегиб. 8-7=1 (у нас 8 переменных и перегиб на 7 шаге). Т. е. всего один класс. Но это все условно. Тут также можно увидеть и второй перегиб на 4 шаге. Т. е. в таком случае классов будет 4. 8-4 =4. В общем случае количество кластеров для анализа предоставляется исследователю.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
