
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Он может быть полезен, когда необходимо систематизировать информацию огромного размера. Анализ большинства экспериментов, проводимых с помощью кластерного анализа, дал Хартиган (Hartigan, 1975).
В биологии кластеризация имеет множество приложений в самых разных областях. Например, в биоинформатике с помощью неё анализируются сложные сети взаимодействующих генов, состоящие порой из сотен или даже тысяч элементов. Кластерный анализ позволяет выделить подсети, узкие места, концентраторы и другие скрытые свойства изучаемой системы, что позволяет в конечном счете узнать вклад каждого гена в формирование изучаемого феномена [11].
В области экологии широко применяется для выделения пространственно однородных групп организмов, сообществ и т. п. Реже методы кластерного анализа применяются для исследования сообществ во времени. Гетерогенность структуры сообществ приводит к возникновению нетривиальных методов кластерного анализа (например, метод Чекановского).
В общем стоит отметить, что исторически сложилось так, что в качестве мер близости в биологии чаще используются меры сходства, а не меры различия (расстояния).
Кластерный анализ применим даже в медицине, например это систематизация болезней, лечение болезней или их симптомов, и таксономия пациентов, лекарств и так далее. В археологии это систематизация каменных сооружений, памятников и древнейших объектов и так далее [12]. В маркетинге это может быть задача сегментации конкурентов и потребителей. В менеджменте примером задачи кластеризации будет разбиение персонала на различные группы, классификация потребителей и поставщиков, выявление схожих производственных ситуаций, при которых возникает брак. В медицине - классификация симптомов. В социологии задача кластеризации - разбиение респондентов на однородные группы [13].
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров [14]. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров. Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа — отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа — визуальный анализ дендрограммы и сравнение результатов кластеризации, выполненной различными методами.
Визуальный анализ дендрограммы предполагает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология и ) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, таким образом будет достигнут 80 % уровень сходства. Если выделение кластеров по этой метке затруднено (на ней происходит слияние нескольких мелких кластеров в один крупный), то можно выбрать другую метку. Такая методика предлагается Олдендерфером и Блэшфилдом [15].
Теперь возникает вопрос устойчивости принятого кластерного решения. По сути, проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило — устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости:
- кофенетическая корреляция — не рекомендуется и ограниченна в использовании;
- тесты значимости (дисперсионный анализ) — всегда дают значимый результат;
- методика повторных (случайных) выборок, что, тем не менее, не доказывает обоснованность решения;
- тесты значимости для внешних признаков пригодны только для повторных измерений;
- методы Монте-Карло очень сложны и доступны только опытным математикам.
В маркетинговых исследованиях кластерный анализ применяется достаточно широко - как в теоретических исследованиях, так и практикующими маркетологами, решающими проблемы группировки различных объектов. При этом решаются вопросы о группах клиентов, продуктов и т. д.
Так, одной из наиболее важных задач при применении кластерного анализа в маркетинговых исследованиях является анализ поведения потребителя, а именно: группировка потребителей в однородные классы для получения максимально полного представления о поведении клиента из каждой группы и о факторах, влияющих на его поведение. Эта проблема подробно описана в работах Клакстона, Фрая и Портиса (1974), Киля и Лэйтона (1981)[16].
Важной задачей, которую может решить кластерный анализ, является позиционирование, т. е. определение ниши, в которой следует позиционировать новый продукт, предлагаемый на рынке. В результате применения кластерного анализа строится карта, по которой можно определить уровень конкуренции в различных сегментах рынка и соответствующие характеристики товара для возможности попадания в этот сегмент. С помощью анализа такой карты возможно определение новых, незанятых ниш на рынке, в которых можно предлагать существующие товары или разрабатывать новые.
Кластерный анализ также может быть удобен, например, для анализа клиентов компании. Для этого все клиенты группируются в кластеры, и для каждого кластера вырабатывается индивидуальная политика. Такой подход позволяет существенно сократить объекты анализа, и, в то же время, индивидуально подойти к каждой группе клиентов. Кластерный анализ так же применим и в информатике:
Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества.
Clusty — кластеризующая поисковая машина компании Vivisimo
Nigma — российская поисковая система с автоматической кластеризацией результатов
Quintura — визуальная кластеризация в виде облака ключевых слов
Сегментация изображений (англ. image segmentation) — кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (англ. edge detection) или распознавания объектов.
Интеллектуальный анализ данных (англ. data mining) — кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных.
Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.[17]
Для решения практических задач часто используются такие программы как Statistica и Excel. Рассмотрим процедуру решения практических задач кластерного анализа в программе STATISTICA. Задачей кластерного анализа является организация наблюдаемых данных в наглядные структуры. Для решения данной задачи в кластерном анализе используются следующие методы: Joining (tree clustering) (иерархические агломеративные методы или древовидная кластеризация), K - means clustering (метод К средних), Two-way joining (двувходовое объединение). Рассмотрим процесс формирования выборок в системе STATISTICA.
Среди переключателей модуля STATISTICA нужно открыть модуль Cluster Analysis (Кластерный Анализ). Высветите название модуля и далее нажать кнопку Switch to (Переключиться в) либо просто дважды щелкнув мышью по названию модуля Cluster Analysis. На экране появится стартовая панель модуля (рис.1.2) Clustering Method (методы кластерного анализа): Joining (tree clustering) (иерархические агломеративные методы или древовидная кластеризация), K - means clustering (метод К средних), Two-way joining (двувходовое объединение).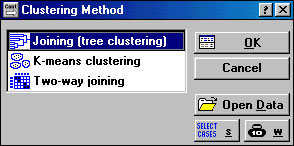
Рисунок 1.2 Стартовая панель модуля Clustering Method (методы кластерного анализа)
Joining (tree clustering) (иерархические агломеративные методы).
- Откроем файл (Open Data). После выбора Joining (tree clustering) и нажатия кнопки ОК появляется окно Cluster Analysis: Joing (Tree Clustering) (окно ввода режимов работы для иерархических агломеративных методов) (рис. 1.3), в котором кнопка Variables позволяет выбрать переменные участвующие в классификации. Нажмем на кнопку Variables и выберем все переменные Select All. После соответствующего выбора и нажмем кнопку OK
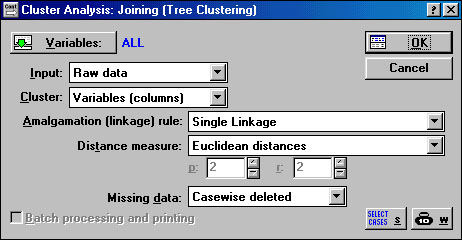
Рисунок 1.3 Cluster Analysis: Joing (Tree Clustering)
(окно ввода режимов работы для иерархических агломеративных методов)
Также можно задать Input (тип входной информации) и Cluster (режим классификации (по признакам или объектам)). Можно указать Amalgamation (linkage) rule (правило объединения) и Distance measure (метрика расстояний). Codes for grouping variable (коды для групп переменной) будут указывать количество анализируемых групп объектов. Missing data (пропущенные переменные) позволяет выбрать либо построчное удаление переменных из списка, либо заменить их на средние значения. Open Data - позволяет открыть файл с данными. Причем можно указать условия выбора наблюдений из базы данных - кнопка Select Cases. Можно задавать веса переменным, выбрав их из списка - кнопка W.
- После задания всех необходимых параметров и нажатия кнопки ОК будут произведены вычисления, а на экране появится окно, содержащее результаты кластерного анализа "Joining Results" рис.1.4.
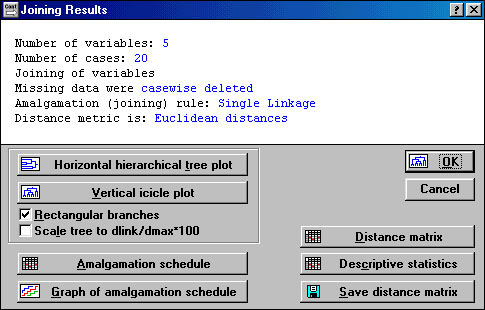

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
