
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица 3.7
Имя |
|
|
|
|
|
|
Жанибек | 5 | 4 | 7 | 8 | 5 | 9 |
Нурадил | 6 | 7 | 6 | 8 | 8 | 10 |
Айнагуль | 8 | 5 | 7 | 6 | 5 | 8 |
Юля | 9 | 9 | 10 | 8 | 7 | 6 |
Диана | 10 | 10 | 9 | 8 | 9 | 7 |
Ольга | 2 | 5 | 4 | 6 | 3 | 7 |
Все данные введены в программу Statistica и проведены расчеты.
При использовании математического пакета Statistica получены два кластера, которые изображены в виде вертикальной дендограммы. Дендограмма показана на рисунке 3.2
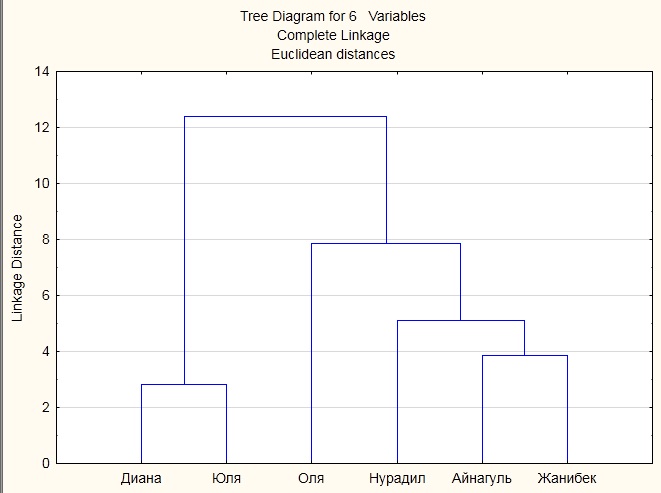
Рисунок 3.2
Вывод: Анализируя дендограмму видно, что в один кластер входят 2 студента (Диана и Юля), в другой 4 человека (Оля, Нурадил, Айнагуль, Жанибек). Разобраться в значении кластеров помогают кластерные профили, которые представляют собой средние значения переменных, которые включены в анализ, распределенные по кластерной принадлежности.
Определим средние значения всех переменных по каждому из выделенных кластеров. Средние значения наблюдений по тестам в кластерах показаны в таблице 3.8
Таблица 3.8
Предмет теста | Кластер 1 | Кластер 2 |
Память на числа | 9,5 | 5,25 |
Математические задачи | 9,5 | 5,25 |
Находчивость | 9,5 | 6 |
Сотрудничество | 8 | 7 |
Логические задачи | 8 | 5,25 |
Командный дух | 6,5 | 8,5 |
В первый кластер вошли испытуемые, которые имеют высокие показатели в математических тестах. Во второй кластер вошли те, у кого высокий показатель на тесты по социальной компетентности (находчивость, сотрудничество, командный дух), но с низким показателем по тестам на логические и математические задачи.
Ход данного исследования пошагово показан в приложении Б.
Решение задач методом K-среднихНеобходимо рассмотреть малую группу из 9 учеников. Значения ![]()
![]()
![]()
![]() - оценки учащихся за I четверть.
- оценки учащихся за I четверть.
![]()
![]()
![]()
![]() . Данные приведены в таблице 3.9
. Данные приведены в таблице 3.9
Таблица 3.9
Ученик/ Предмет |
|
|
|
3 | 3 | 5 | |
5 | 4 | 5 | |
4 | 4 | 4 | |
4 | 4 | 5 | |
5 | 4 | 5 | |
3 | 3 | 5 | |
4 | 4 | 5 | |
3 | 3 | 4 | |
5 | 5 | 5 |
В математическом пакете Statistica создаем таблицу с данными значениями. Выбираем пункт Mult/E[ploratory ?› Cluster.
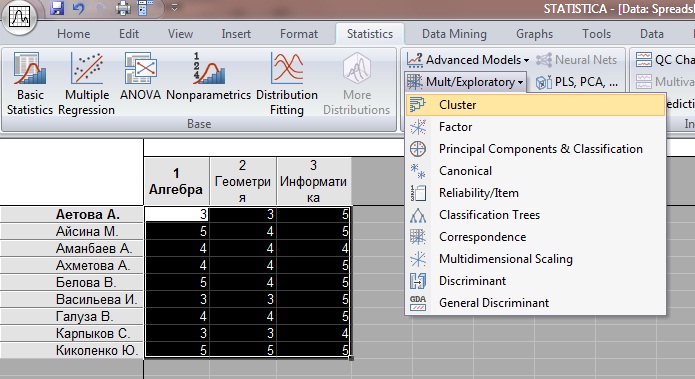
Рисунок 3.3
Затем выбираем метод K-means.
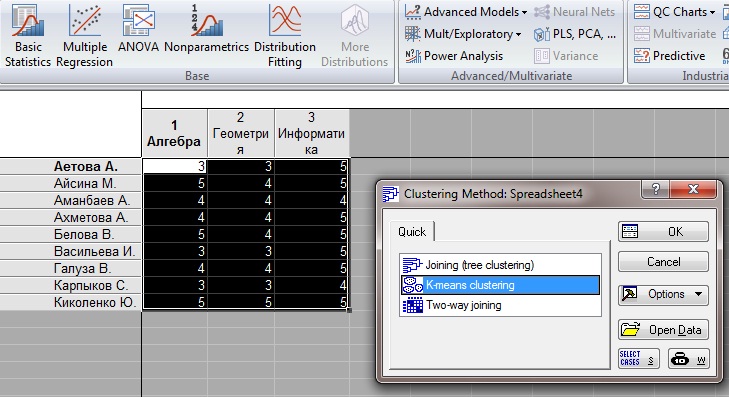
Рисунок 3.4
Выбираем количество кластера. Количество кластера задается произвольно. В данном примере задано три кластера.
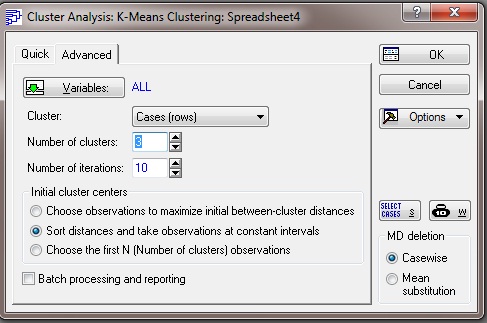
Рисунок 3.5
Выбираем пункт Graph of means.
Рисунок 3.6
Получено три кластера, представленных в виде трех графиков. Первый кластер обозначен синим цветом, второй – красным, третий – зеленым.
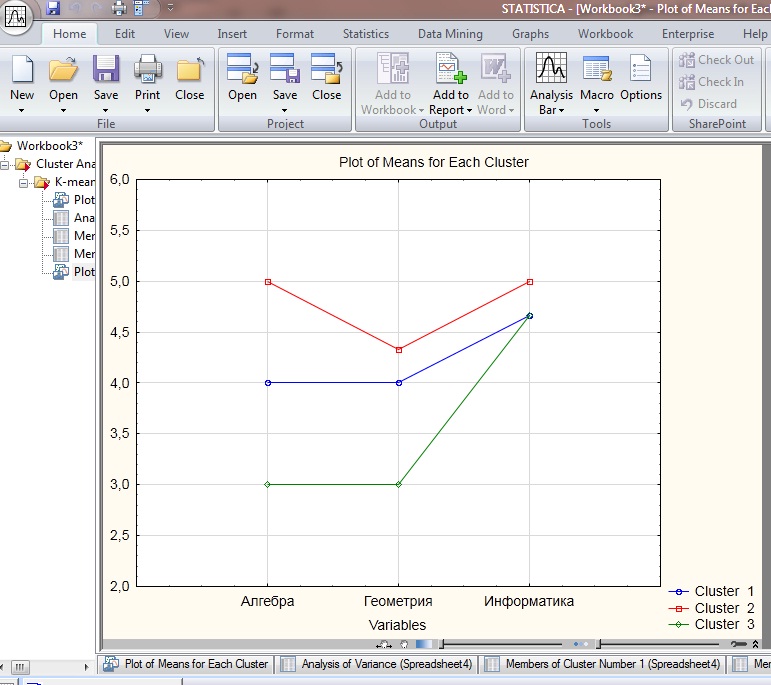
Рисунок 3.7
Чтобы понять, как произошло разбиение, достаточно посмотреть из чего состоят эти кластеры. В графе K-means clustering выбираем пункт members of each cluster and distances. Данный пункт показывает, какие ученики вошли в какой кластер, и высчитывает расстояние.
Рисунок 3.8
Видно, что в первый кластер вошли

Рисунок 3.9
Во второй кластер вошли:
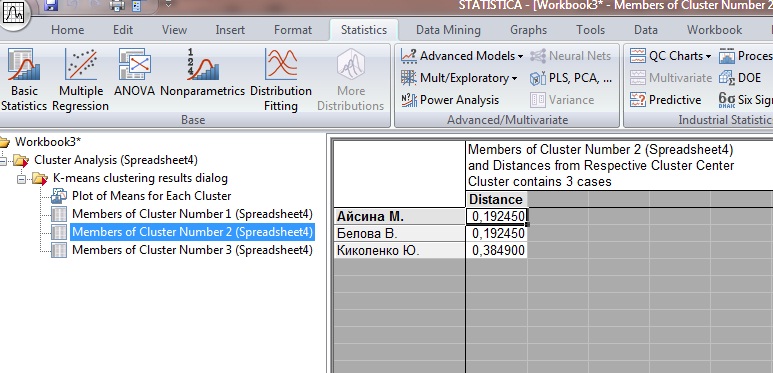
Рисунок 3.1
В третий кластер вошли:

Рисунок 3.11

Рисунок 3.12
Вывод: Методом K-means получено три кластера. В первый кластер вошли ученики: данных учеников оценки по предметам « Алгебра» и « Геометрия» 4, по предмету информатика видно, что оценки лучше у всех членов трех кластеров.
Во второй кластер вошли данных учеников оценки по алгебре и информатике одинаковые, и выше чем по геометрии.
В третий кластер вошли них оценки по алгебре и геометрии низкие и равны оценке «3», но по информатике «4 и 5».
По полученным кластерам можно проследить динамику успеваемости учащихся с прогнозированием и их дальнейшего обучения с корректировкой тех дисциплин, в которых низкие баллы.
Пример 4.
В данном исследовании рассматривается 9 «В» класс школы-гимназии № 3 г. Костанай. Нужно сравнить три метода: Метод ближнего соседа, метод дальнего соседа и метод К-средних. В таблице В1 приведены оценки за первую четверть по трем предметам.
Таблица В1.
Биология | Геометрия | Информатика | |
3 | 3 | 5 | |
4 | 4 | 5 | |
4 | 4 | 4 | |
4 | 4 | 5 | |
4 | 4 | 5 | |
4 | 3 | 5 | |
4 | 4 | 5 | |
4 | 4 | 5 | |
3 | 3 | 4 | |
Киколенко Ю, | 4 | 4 | 5 |
4 | 4 | 5 | |
3 | 3 | 5 | |
4 | 4 | 4 | |
3 | 3 | 4 | |
4 | 3 | 5 | |
4 | 3 | 4 | |
4 | 4 | 5 | |
3 | 3 | 4 | |
4 | 3 | 4 | |
4 | 4 | 4 | |
3 | 3 | 4 | |
5 | 5 | 5 | |
4 | 4 | 4 | |
4 | 4 | 4 | |
4 | 4 | 4 |
Для решения практических задач часто используются такие программы как Statistica и Excel. Рассмотрим процедуру решения задачи кластерного анализа в программе STATISTICA. Среди переключателей модуля STATISTICA нужно открыть модуль Cluster Analysis (Кластерный Анализ).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
