
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Различают математическую модель и регрессионную модель. Математическая модель предполагает участие аналитика в конструировании функции, которая описывает некоторую известную закономерность. Математическая модель является интерпретируемой — объясняемой в рамках исследуемой закономерности. При построении математической модели сначала создаётся параметрическое семейство функций, затем с помощью измеряемых данных выполняется идентификация модели — нахождение её параметров. Известная функциональная зависимость объясняющей переменной и переменной отклика — основное отличие математического моделирования от регрессионного анализа. Недостаток математического моделирования состоит в том, что измеряемые данные используются для верификации, но не для построения модели, вследствие чего можно получить неадекватную модель. Также затруднительно получить модель сложного явления, в котором взаимосвязано большое число различных факторов.
Регрессионная модель объединяет широкий класс универсальных функций, которые описывают некоторую закономерность. При этом для построения модели в основном используются измеряемые данные, а не знание свойств исследуемой закономерности. Такая модель часто неинтерпретируема, но более точна. Это объясняется либо большим числом моделей-претендентов, которые используются для построения оптимальной модели, либо большой сложностью модели. Нахождение параметров регрессионной модели называется обучением модели.
Недостатки регрессионного анализа: модели, имеющие слишком малую сложность, могут оказаться неточными, а модели, имеющие избыточную сложность, могут оказаться переобученными. Примеры регрессионных моделей: линейные функции, алгебраические полиномы, ряды Чебышёва, нейронные сети без обратной связи, например, однослойный персептрон Розенблатта, радиальные базисные функции и прочее.
И регрессионная, и математическая модель, как правило, задают непрерывное отображение. Требование непрерывности обусловлено классом решаемых задач: чаще всего это описание физических, химических и других явлений, где требование непрерывности выставляется естественным образом. Иногда на отображение ![]() накладываться ограничения монотонности, гладкости, измеримости, и некоторые другие. Теоретически, никто не запрещает работать с функциями произвольного вида, и допускать в моделях существование не только точек разрыва, но и задавать конечное, неупорядоченное множество значений свободной переменной, то есть, превращать задачи регрессии в задачи классификации.
накладываться ограничения монотонности, гладкости, измеримости, и некоторые другие. Теоретически, никто не запрещает работать с функциями произвольного вида, и допускать в моделях существование не только точек разрыва, но и задавать конечное, неупорядоченное множество значений свободной переменной, то есть, превращать задачи регрессии в задачи классификации.
8. Основные понятия регрессионного анализа. Типы регрессии. Их прикладная интерпретация.
Регрессионный анализ - метод моделирования измеряемых данных и исследования их свойств. Данные для анализа состоят из пар значений зависимой переменной (переменной отклика) и независимой переменной (объясняющей переменной). Регрессионная модель есть функция независимой переменной и параметров с добавленной случайной переменной.
Числовые данные обычно имеют между собой явные (известные) или неявные (скрытые) связи. Явно связаны показатели, которые получены методами прямого счета, т. е. вычислены по заранее известным формулам. Например, проценты выполнения плана, уровни, удельные веса, отклонения в сумме, отклонения в процентах, темпы роста, темпы прироста, индексы и т. д. Связи же второго типа (неявные) заранее неизвестны. Однако необходимо уметь объяснять и предсказывать (прогнозировать) сложные явления для того, чтобы управлять ими.
Математические модели строятся и используются для трех обобщенных целей: * для объяснения; * для предсказания; * для управления.
Пользуясь методами корреляционно-регрессионного анализа, аналитики измеряют тесноту связей показателей с помощью коэффициента корреляции. При этом обнаруживаются связи, различные по силе (сильные, слабые, умеренные и др.) и различные по направлению (прямые, обратные). Если связи окажутся существенными, то целесообразно будет найти их математическое выражение в виде регрессионной модели и оценить статистическую значимость модели. Регрессионный анализ называют основным методом современной математической статистики для выявления неявных и завуалированных связей между данными наблюдений.
Регрессия - величина, выражающая зависимость среднего значения случайной величины у от значений случайной величины х.
Уравнение регрессии выражает среднюю величину одного признака как функцию другого.
Виды регрессий:
1) гиперболическая - регрессия равносторонней гиперболы: у = а + b / х + Е;
2) линейная - регрессия, применяемая в статистике в виде четкой экономической интерпретации ее параметров: у = а+b*х+Е;
3) логарифмически линейная - регрессия вида: In у = In а + b * In x + In E
4) множественная - регрессия между переменными у и х1 , х2 ...xm, т. е. модель вида: у = f(х1 , х2 ...xm)+E, где у - зависимая переменная (результативный признак), х1 , х2 ...xm - независимые, объясняющие переменные (признаки-факторы), Е - возмущение или стохастическая переменная, включающая влияние неучтенных факторов в модели;
5) нелинейная - регрессия, нелинейная относительно включенных в анализ объясняющих переменных, но линейная по оцениваемым параметрам; или регрессия, нелинейная по оцениваемым параметрам.
6) обратная - регрессия, приводимая к линейному виду, реализованная в стандартных пакетах прикладных программ вида: у = 1/a + b*х+Е;
7) парная - регрессия между двумя переменными у и x, т. е, модель вида: у = f (x) + Е, где у - зависимая переменная (результативный признак), x – независимая, объясняющая переменная (признак - фактор), Е - возмущение, или стохастическая переменная, включающая влияние неучтенных факторов в модели.
9. Метод наименьших квадратов. Области его применения.
Метод наименьших квадратов — математический (математико-статистический) прием, служащий для выравнивания динамических рядов, выявления формы корреляционной связи между случайными величинами и др. Состоит в том, что функция, описывающая данное явление, аппроксимируется более простой функцией. Причем последняя подбирается с таким расчетом, чтобы среднеквадратичное отклонение (см.Дисперсия) фактических уровней функции в наблюдаемых точках от выровненных было наименьшим.
Напр., по имеющимся данным (xi, yi) (i = 1, 2, ..., n) строится такая кривая y = a + bx, на которой достигается минимум суммы квадратов отклонений
![]()
т. е. минимизируется функция, зависящая от двух параметров: a — отрезок на оси ординат и b — наклон прямой.
Уравнения, дающие необходимые условия минимизации функции S(a, b), называются нормальными уравнениями. В качестве аппроксимирующих функций применяются не только линейная (выравнивание по прямой линии), но и квадратическая, параболическая, экспоненциальная и др. Пример выравнивания динамического ряда по прямой см. на рис. M.2, где сумма квадратов расстояний (y1 – ȳ1)2 + (y2 – ȳ2)2 .... — наименьшая, и получившаяся прямая наилучшим образом отражает тенденцию динамического ряда наблюдений за некоторым показателем во времени.
Для несмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа: условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если: 1.математическое ожидание случайных ошибок равно нулю, и 2.факторы и случайные ошибки — независимые случайные величины. Первое условие можно считать выполненным всегда для моделей с константой, так как константа берёт на себя ненулевое математическое ожидание ошибок. Второе условие — условие экзогенности факторов — принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае).
Наиболее распространенным в практике статистического оценивания параметров уравнений регрессии является метод наименьших квадратов. Этот метод основан на ряде предпосылок относительно природы данных и результатов построения модели. Основные из них - это четкое разделение исходных переменных на зависимые и независимые, некоррелированность факторов, входящих в уравнения, линейность связи, отсутствие автокорреляции остатков, равенство их математических ожиданий нулю и постоянная дисперсия.
Одной из основных гипотез МНК является предположение о равенстве дисперсий отклонений еi, т. е. их разброс вокруг среднего (нулевого) значения ряда должен быть величиной стабильной. Это свойство называется гомоскедастичностью. На практике дисперсии отклонений достаточно часто неодинаковы, то есть наблюдается гетероскедастичность. Это может быть следствием разных причин. Например, возможны ошибки в исходных данных. Случайные неточности в исходной информации, такие как ошибки в порядке чисел, могут оказать ощутимое влияние на результаты. Часто больший разброс отклонений єi, наблюдается при больших значениях зависимой переменной (переменных). Если в данных содержится значительная ошибка, то, естественно, большим будет и отклонение модельного значения, рассчитанного по ошибочным данным. Для того, чтобы избавиться от этой ошибки нам нужно уменьшить вклад этих данных в результаты расчетов, задать для них меньший вес, чем для всех остальных. Эта идея реализована во взвешенном МНК.
10. Оценка качества регрессионной модели. Способы улучшения качества регрессионной модели.
Качеством модели регрессии называется адекватность построенной модели исходным (наблюдаемым) данным. Для оценки качества модели регрессии используются специальные показатели:
1) парной линейный коэффициент корреляции, который рассчитывается по формуле:
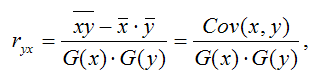
где G(x) – среднеквадратическое отклонение независимой переменной; G(y) – среднеквадратическое отклонение зависимой переменной. Также парный линейный коэффициент корреляции можно рассчитать через МНК-оценку коэффициента модели регрессии по формуле:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
