

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Кривые, полученные в МД-моделировании, демонстрируют подобное поведение, при этом у полученного ПП положение λ-пика в пределах погрешности совпадает с экспериментальными оценками ~2650К [64][65], у Морелона пик занижен и несколько сдвинут в область 2500~2550 К, а с ПП Базака пик существенно сдвинут в область 3000~3100 К. Можно предположить, что положение λ-пика напрямую связано с энергией образования дефекта Френкеля, которая несколько занижена по сравнению с экспериментальной у Морелона и существенно завышена у Базака (см. табл. 8.4). Следует заметить, что для обективного вывода о наличии пика теплоемкости в области суперионного перехода необходимо дополнительно проводить исследования по температурному поведению теплоемлоемкости через малые интервалы температур, что не входило в задачу описываемых исследований.
Модельные зависимости СP(T) при высоких температурах растут медленнее, чем экспериментальная, так как модельный коэффициент линейного расширения в этой области занижен по сравнению с экспериментом (см. рис. 3 и рис. 4). Более детальный анализ такого поведения мы провели в предыдущей работе [66].
Из рис. 8.6 видно, что результаты для теплоемкости с учетом вклада электронных и катионных дефектов точно совпадают с экспериментальной зависимостью вплоть до суперионного перехода ~2650 K, что говорит об адекватности выбранной модели в этом температурном диапазоне. Таким образом, по-видимому, подтверждается предположение, что корректное воспроизведение экспериментальной зависимости теплового расширения решетки позволяет прямо учесть все тепловые свойства ионной подсистемы и косвенно часть свойств электронной подсистемы (в частности, отличие зарядов ионов от целочисленных в кристаллической фазе).
Проблема воспроизведения коэффициента линейного расширения за суперионным переходом требует дополнительных исследований, поскольку она может быть связана:
· с недостаточной гибкостью модели, которой представлялись парные потенциалы взаимодействия (в частности катион-катионное),
· с тем, что эффективные парные потенциалы существенно изменяются при высоких температурах,
· с невозможностью моделирования процессов разупорядочения катионной подрешетки.
Мы, однако, предполагаем, что выход модельной теплоемкости на постоянное значение за суперионным переходом в первую очередь обусловлен «упрощенным» (только кулоновским) описанием взаимодействия между катионами. Это подтверждается также нашими оценками значений коэффициентов диффузии ионов урана в кристаллическом состоянии, которые занижены в текущем приближении. Соответственно, для дальнейшего усовершенствования модели необходимо детальнее исследовать это взаимодействие.
Таким образом, метод восстановления эмпирических межчастичных потенциалов в ионных системах по высокоточным экспериментальным данным о тепловом расширении быстрым «изохорным» МД-моделированием, позволяющим учесть кинетические свойства системы, следует считать вполне плодотворным. Даже локальным поиском решения косвенной оптимизационной задачи (минимизация по давлению вместо объема или периода решетки) удается получить набор потенциалов, воспроизводящий широкий спектр экспериментальных характеристик оксидного уранового топлива лучше, чем любые из предложенных ранее.
Предположение, что корректное воспроизведение экспериментальной зависимости теплового расширения позволяет прямо учесть все кинетические свойства ионной подсистемы и, косвенно, часть свойств электронной подсистемы, по-видимому, подтверждается.
10. Базовые особенности программирования графических процессоров шейдерной модели 4.0
10.1. Предпосылки появления новой шейдерной модели
Как мы показали в предыдущих разделах курса, шейдерная модель 3.0 (SM3) полностью реализует «чистую» поточно-параллельную обработку массивов данных по принципу SIMD (рис. 4.2, рис. 4.7-4.8). Параллельные процессоры (графические конвейеры) применяют ко всем векторам из входных массивов один и тот же алгоритм обработки, причём не имеют доступа к результатам работы других конвейеров. Для наглядности, этот принцип снова проиллюстрирован на рис. 9.1.

Рис. 9.1. Поточно-параллельный расчёт без связи между процедурами обработки отдельных элементов входных массивов. Здесь каждой тройке соответственных 4-векторов из входных массивов (таких массивов не обязательно именно три) ставится в соответствие одна ячейка массива результатов (рендер-цели). При этом, связи между графическими конвейерами, обрабатывающими различные тройки входных векторов, быть не может
Алгоритмы, обеспечивающие отсутствие связи между расчётами на параллельных графических конвейерах имеют то преимущество, что нет необходимости синхронизировать работу конвейеров, что могло бы существенно замедлить вычисления, а также осложнить работу программиста при необходимости программировать синхронизацию вручную.
С другой стороны, существует много алгоритмов, в которых обмен данными между параллельными ветвями расчёта необходим изредка (так что синхронизация не отнимает много времени), но обойтись без него совсем всё же нельзя. При расчётах на GPU шейдерной модели 3.0 такие алгоритмы можно было осуществлять только с использованием центрального процессора, что требовало приостановки параллельных вычислений.
В 2007 году появились графические процессоры, реализующие новую (и последнюю на сегодняшний день) шейдерную модель 4.0 (SM4). В GPU этой модели параллельные процессоры (теперь их уже не называют графическими конвейерами) получили возможность обмена данными между собой во время расчёта. Благодаря этому и другим архитектурным изменениям, графические процессоры шейдерной модели 4.0 фактически стали универсальными многопроцессорными системами (рис. 9.2).
Наши реализации молекулярной динамики на GPU с применением шейдерной модели 3.0 и библиотеки DirectX показали, что большая часть времени расчетов уходит на издержки, связанные с вызовами DirectX. Также наблюдалась сильная зависимость времени расчета от формата представления данных (размеров текстур), поскольку при неоптимальных размерах кэш использовался неэффективно.
Использование шейдерной модели 4.0 позволило нам значительно ускорить вычисления, поскольку эта модель даёт возможность на несколько порядков уменьшить издержки при доступе к GPU и позволяет программно управлять кэшем (см. описание технологии NVIDIA CUDA ниже).
10.2. Архитектура GPU шейдерной модели 4.0. Преимущества этой модели
На рис. 9.2 показана архитектура G80 – графического процессора шейдерной модели 4.0, выпускаемого компанией NVIDIA [67].
Ниже мы обсудим преимущества графических процессоров шейдерной модели 4.0 и особенности работы с ними. Но сразу отметим, что эти GPU обладают обратной совместимостью с шейдерной моделью 3.0, то есть они исполняют программы, написанные для GPU предыдущего поколения. При том же количестве «вычислителей» скорость исполнения программ для SM3 может даже увеличиться, поскольку в новых GPU значительно ускорены произвольные обращения к памяти.
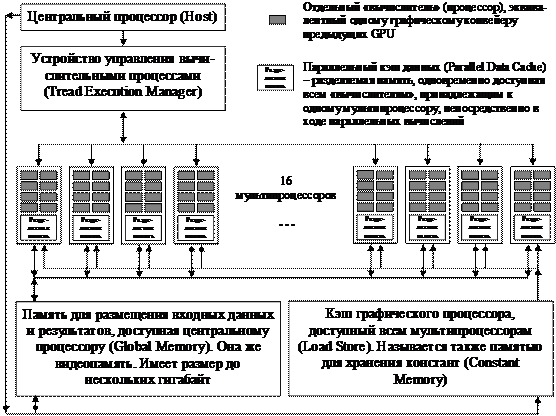
Рис. 9.2. Архитектура графического процессора шейдерной модели 4.0 G80
10.2.1. Иерархия вычислительных блоков и памяти в шейдерной модели 4.0
· Как и GPU предыдущих поколений, графические процессоры шейдерной модели 4.0 (рис. 9.2) представляют собой системы из параллельных «вычислителей» - процессоров, каждый из которых применяет заданную программу (вычислительное ядро) к некоторым элементам (4-векторам) входных массивов данных. Эти «вычислители» по иерархическому положению эквивалентны отдельным графическим конвейерам GPU предыдущих поколений, однако термин «графический конвейер» для них не используют, поэтому мы продолжим называть их «вычислителями». В англоязычной литературе используется термин “thread”, означающий процесс, исполняемый конкретным «вычислителем».
· В отличие от шейдерной модели 3.0, все «вычислители» универсальны, они не подразделяются больше на пиксельные и вершинные конвейеры. Вместо этого, «вычислители» объединены в мультипроцессоры – блоки, внутри которых «вычислители» имеют доступ к общей памяти и могут, таким образом, обмениваться данными в ходе параллельных вычислений (рис. 9.2).
· Одновременно мультипроцессоры могут исполнять только одну и ту же программу (вычислительное ядро, англ. kernel), но применительно к различным исходным данным. Таким образом, в некоторых случаях (когда требуется провести много однотипных расчётов с разными данными) может быть реализован параллелизм по задачам.
· Всем мультипроцессорам доступна общая память (Global Memory, она же видеопамять, рис. 9.2), в которой центральный процессор размещает исходные данные. В этой же памяти графический процессор размещает результаты расчётов, которые, таким образом, становятся доступными центральному процессору.
Физически, эта общая память представляет собой отдельные микросхемы на плате видеокарты, то есть расположена вне самого графического процессора. Соответственно, она работает сравнительно медленно, зато имеет большой объём (до нескольких гигабайт), обычно достаточный для хранения всех обрабатываемых данных.
«Вычислители» записывают в видеопамять результат своего расчёта, но они не могут обмениваться через неё данными в ходе вычислений.
· Кэш графического процессора (память для хранения констант, Constant Memory or Load Store на рис. 9.2) – «быстрая» память, доступная одновременно всем мультипроцессорам (и, соответственно, всем «вычислителям»). Эта память имеет небольшой размер (64 KB на G80), зато расположена прямо на кристалле графического процессора, так что доступ к ней оказывается очень быстрым (примерно в 100 раз быстрее, чем к видеопамяти).
Используется только для хранения констант, необходимых при выполнении программы. Эти константы могут быть записаны в эту память только центральным процессором перед началом параллельного расчёта. «Вычислителям» регистры доступны только для чтения.
· Параллельный кэш данных, или разделяемая память (Parallel Data Cache на рис. 9.2). Каждому из мультипроцессоров доступен один из блоков параллельной разделяемой памяти (16 KB на мультипроцессор). Размещена эта память на кристалле GPU и работает со скоростью регистров процессора (максимально возможной скоростью памяти). Предназначена для того, чтобы «вычислители» могли модифицировать общие данные и обмениваться информацией в ходе параллельного расчёта.
Каждый блок разделяемой памяти доступен одновременно всем «вычислителям» в составе одного мультипроцессора (см. рис. 9.2) для чтения и для записи, поэтому её и называют также параллельной. Конструкцией GPU предусмотрена автоматическая синхронизация доступа «вычислителей» к параллельной памяти. «Вычислители», принадлежащие к разным мультипроцессорам, не могут обмениваться данными через параллельную память (то есть, вообще не могут, потому что других путей нет).
Процессор G80 имеет следующие возможности использования «вычислителей» и памяти:
· максимум 512 параллельных потоков инструкций на «связку» (см. ниже) и 768 на 1 мультипроцессор;
· максимум 8битных регистра на все потоки, выполняемые на 1 мультипроцессоре;
· максимум 2 млн. ассемблерных инструкций на ядро;
· максимальный объем передаваемых параметров 256 байт на ядро.
10.2.2. Конвейерная обработка данных на GPU SM4
Как описано выше, физически графический процессор G80 состоит из 16 мультипроцессоров, в каждом из которых по 8 «вычислителей». Вместе с тем, эти «вычислители» имеют конвейерную архитектуру, то есть – могут одновременно исполнять несколько конкретных вычислительных процессов, находящихся на разных стадиях алгоритма (например, когда один процесс записывает данные в глобальную видеопамять, другой может вести вычисления). Эти вычислительные процессы принято называть потоками (англ. tread – обработка). Каждый мультипроцессор может одновременно исполнять до 768 параллельных потоков.
В программах должны быть логически разделены потоки, исполняемые на различных мультипроцессорах, поскольку только потоки, исполняемые на одном и том же мультипроцессоре, имеют общий доступ к разделяемой памяти. Поэтому, потоки объединяются в «связки» потоков (англ. blocks). Каждая «связка» исполняется на одном мультипроцессоре. В «связке» может быть до 512 потоков. На одном мультипроцессоре могут исполняться две «связки», при условии, что для этого достаточно его ресурсов (общее количество потоков – не более 768, требуемый объём разделяемой памяти не больше имеющегося).
10.2.3. Логическая структура вычислений на GPU SM4
Шейдерная модель 4.0 даёт программисту возможность управлять распределением обрабатываемых данных и задач по «связкам» и по конкретным потокам. Для этого существуют системные переменные, которые внутри каждого конкретного потока возвращают индексы именно этого потока, а также индексы той «связки», к которой он принадлежит. Методы использования этих индексов показаны в нижеследующих примерах.
Программист имеет и возможность задавать способ индексации связок и потоков. В общем случае индексы являются трёхмерными, что может быть удобно при обработке трёхмерных сеток. Допустимы также одно - и двухмерные индексы (см. примеры).
В системе программирования CUDA (см. ниже) переменные, возвращающие индексы «связок» и потоков, имеют следующие имена.
· dim3 – тип переменной, означающий 3-компонентный вектор;
· dim3 gridDim – размерности 3-мерной сетки «связок», задаваемые для исполнения алгоритма;
· dim3 blockDim - размерности 3-мерной сетки «вычислителей» внутри одной «связки», задаваемые для исполнения алгоритма;
· dim3 blockIdx – 3-мерные индексы (координаты) той «связки», к которой принадлежит исполняемый поток;
· dim3 threadIdx – 3-мерные индексы (координаты внутри «связки») исполняемого потока.
10.2.4. Преимущества GPU шейдерной модели 4.0
Архитектура GPU SM4 позволяет этим графическим процессорам исполнять все программы «чистого» поточно-параллельного моделирования, написанные для шейдерной модели 3.0, а кроме этого – предоставляет программисту дополнительные возможности, позволяющие использовать алгоритмы, которые раньше не были эффективны на GPU. Шейдерная модель 4.0 даёт следующие конкретные преимущества перед использованием стандартных графических библиотек DirectX и OpenGL:
· широко известный стандартный язык программирования Си с несколькими простыми расширениями;
· произвольная адресация при записи в память;
· программируемость кэша;
· значительно меньшие накладные расходы на взаимодействие CPU и GPU, некоторые операции выполняются асинхронно;
· побитные операции над целыми числами;
· двойная точность операций с плавающей запятой (аппаратная реализация, начиная с поколения чипов ATI Radeon 4xxx и NVIDIA GeForce GTX 2xx).
Приведённые возможности делают графические процессоры шейдерной модели 4.0 гораздо более универсальными вычислительными системами, чем предыдущие GPU.
10.3. Средства высокоуровневого программирования GPU шейдерной модели 4.0
10.3.1. Совместимость с шейдерной моделью 3.0
Как мы уже отметили выше, GPU SM4 могут исполнять программы, написанные для GPU SM3, причём в эти программы не потребуется вносить никаких изменений. Такими средствами программирования, как язык HLSL, библиотеки DirectX, XNA и OpenGL по-прежнему можно пользоваться для написания новых программ для GPU SM4.
Графические библиотеки, подобные DirectX и OpenGL, позволяют работать с GPU всех известных производителей, так что программы, написанные на основе таких библиотек, будут исполняться независимо от выбора GPU, и даже на GPU SM3, если не используют специфических для 4-й модели возможностей.
С другой стороны, библиотеки типа DirectX, будучи ориентированными на обработку графики, не всегда удобны для написания программ физико-математического моделирования и других, не связанных с графикой. Средствами графических библиотек программы обычно не удаётся максимально оптимизировать.
Шейдерная модель 4.0 разрабатывалась уже с учётом того, что новые процессоры будут широко использоваться как параллельные вычислительные системы общего назначения. Соответственно, разработчиками этих графических процессоров (NVIDIA, AMD/ATI) созданы новые высокоуровневые средства программирования таких процессоров для максимального использования их возможностей. Ниже мы кратко рассмотрим программирование GPU в рамках программно-аппаратной платформы CUDA, разрабатываемой компанией NVIDIA.
10.3.2. Специальные средства программирования GPU SM4. CUDA
Компания NVIDIA весь свой комплекс современных программных и аппаратных решений для графических процессоров объединяет общей аббревиатурой CUDA - Compute Unified Device Architecture, что означает Архитектура Объединённого Вычислительного Устройства. Из расшифровки очевидна ориентация NVIDIA на производство процессоров, эффективно исполняющих как поточно-параллельные вычисления, так и сложные алгоритмы обработки информации.
В рамках этого комплекса разработана система программирования CUDA (современная версия - NVIDIA CUDA 2.0), основанная на расширении языка C добавлением в него новых типов данных и процедур для управления графическим процессором. CUDA включает в себя возможности как языков, предназначенных для написания вычислительного ядра (HLSL), так и графических библиотек (DirectX, XNA, OpenGL), обеспечивающих взаимодействие между центральным и графическим процессорами. В том числе:
· операции выделения памяти GPU для внесения данных, операции записи данных в память и удаления из памяти (выполняются центральным процессором);
· операторы описания типов переменных, используемых в программе;
· Операторы и функции для математических вычислений на GPU;
· средства для запуска параллельных расчётов на исполнение.
Практически, программирование на CUDA сводится к использованию новых операций, процедур и типов данных в «обычных» программах на языках C и C++. Для этого нужно иметь специальные библиотеки CUDA, разработанные компанией NVIDIA. Эти библиотеки распространяются свободно и бесплатно доступны в Интернете.
При написании процедур (функций) на CUDA необходимо указывать, должны они исполняться графическим или центральным процессором. Для этого используются следующие спецификаторы
· __global__ - функция, вызываемая центральным процессором, но исполняемая на графическом процессоре, то есть - вычислительное ядро;
· __device__ - функция, исполняемая на GPU b вызываемая только другими функциями, исполняемыми на GPU, то есть – из вычислительного ядра. Не может вызываться центральным процессором;
· __host__ - функция, вызываемая и исполняемая центральным процессором, без использования GPU;
· __host__ and __device__ - функция, которая может исполняться либо на центральном, либо на графическом процессорах (применяется, например, при «перегрузке» операторов).
10.3.3. Средства для написания и компиляции программ на CUDA
Компиляторы, поддерживающие CUDA, существуют и для Windows, и для UNIX-подобных операционных систем, таких как Linux. Мы разрабатывали программы на CUDA как Windows-приложения, используя компьютер следующей программно-аппаратной конфигурации.
· AMD Athlon X2 4000+ (2100 MHz)
3 GB DDR2 (667 MHz)
· NVIDIA GeForce 8800 GTX (частота скалярных процессоров 1350 MHz)
768 MB 384-bit GDDR3 (1800 MHz)
· Microsoft Windows XP + Service Pack 2
· CPU Driver AMD 1.3.2.0/2007)
· GPU Driver NVIDIA Forceware 177/2008)
· Framework 3.5
· Microsoft DirectX 9.0c (4.09.0000.0904, 08/2007)
· NVIDIA CUDA 2.0 (Toolkit + SDK)
· Microsoft 32-bit C/C++ compiler 14.0 (в составе Visual Studio 2005)
Проект с кодом CUDA открывается и компилируется как обычный проект в Microsoft Visual Studio 2005. При сборке проекта возможны 4 выбора конфигурации: Release, Debug, EmuRelease, EmuDebug. Выбор конфигурации EmuDebug позволяет запускать проект в отладочном режиме.
Вычислительные ядра для GPU выглядят как обычные функции языка C, со следующими ограничениями:
· могут обращаться только к памяти GPU, но не к оперативной памяти компьютера;
· не возвращают никакого значения (тип возвращаемого значения – только void);
· допускают только фиксированное количество аргументов;
· не допускают рекурсивного вызова;
· не могут включать статических переменных.
Аргументы этих функций автоматически копируются из оперативной памяти компьютера в память GPU.
10.3.4. Структура программы на CUDA
Благодаря универсальности архитектуры, исполняемые на современных GPU алгоритмы могут иметь различные, достаточно сложные структуры. Приводимая ниже схема демонстрирует возможность распараллеливания вычислений и оптимизации обращений к памяти.
10.4. Перемножение матриц на CUDA
10.4.1. Алгоритм перемножения матриц
Одним из главных преимуществ GPU шейдерной модели 4.0 является то, что для них возможно программируемое управление отдельными блоками «вычислителей», что во многих задачах позволяет оптимизировать использование вычислительных возможностей графического процессора. Хорошим примером этого является реализация алгоритма перемножения матриц.
Математически задача перемножения двух матриц A и B формулируется следующим образом:
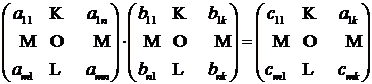 ,
,
где
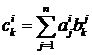 .
.
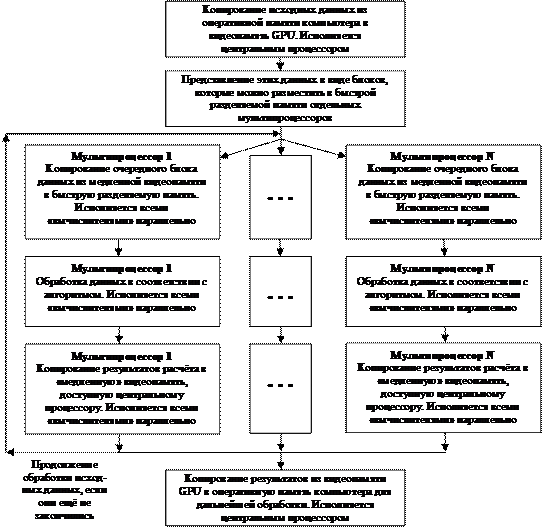
Рис. 9.3. Схема программы на графическом процессоре шейдерной модели 4.0
Для того, чтобы умножение было возможным, необходимо чтобы ширина матрицы A (равная n) совпадала с высотой матрицы B (тоже равной n). При этом получится, что у результирующей матрицы C высота совпадает с высотой матрицы A, а ширина – с шириной матрицы B. Этот принцип очень наглядно иллюстрируется умножением матрицы на вектор:
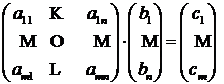 .
.
Метод распараллеливания умножения матриц на GPU SM4 заключается в следующем.
· Исходные матрицы A и B разбиваются на блоки, с тем, чтобы каждый из мультипроцессоров вычислял произведение одного из блоков матрицы A на один из блоков матрицы B. Пусть, для простоты, эти блоки будут кубическими.
· Размер блоков (Block_Size) выбирается таким образом, чтобы два перемножаемых блока целиком помещались в разделяемую память мультипроцессора (Parallel Data Cash на рис. 9.2).
· В ходе исполнения программы на каждом мультипроцессоре исполняются одна или две «связки» потоков, а каждый поток исполняется на одном конкретном «вычислителе». Потокам внутри «связки» нужно поставить в соответствие двухмерные номера – значения индексов i и k в диапазоне от 1 до Block_Size.
· Внутри отдельного потока запрограммировать суммирование
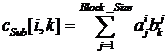 .
.
при фиксированных индексах (i, k), как это показано на рис. 9.4.
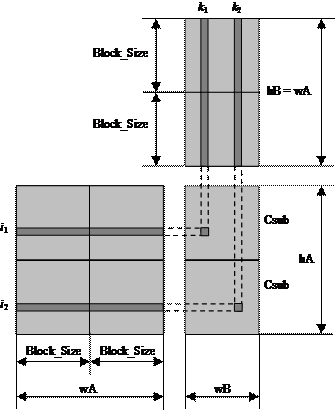
Рис. 9.4. Схема перемножения матриц на GPU шейдерной модели 4.0
На рис. 9.4 каждая матрица Csub равна произведению двух прямоугольных блоков: блока матрицы A размерами (wA, Block_Size), индексы строк которого совпадают с индексами строк матрицы Csub, и блока матрицы B размерами (Block_Size, wA), индексы столбцов которого совпадают с индексами столбцов матрицы Csub. Окончательно, матрица Csub вычисляется как сумма произведений квадратных блоков, показанных на рис. 9.4, по следующему принципу:
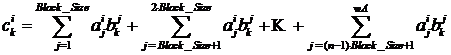 ,
,
где n = wA / Block_Size – количество блоков, приходящееся на ширину матрицы A и равную ей высоту матрицы B.
Для расчета каждого из этих произведений сначала в разделяемую память загружаются два соответствующих блока из глобальной памяти, а затем каждый поток «связки» вычисляет один элемент произведения. При этом происходит накопление суммы результатов ![]() , которая затем сохраняется в глобальной памяти.
, которая затем сохраняется в глобальной памяти.
Отметим, что рассмотренный алгоритм перемножения матриц на GPU SM4 не является самым быстрым из возможных. Тем не менее, он хорошо иллюстрирует принципы управления вычислительными потоками и оптимизации использования памяти при программировании GPU SM4. В частности, разбиение матриц на блоки позволило задействовать быструю разделяемую память, сокращая число выборок из глобальной памяти до n = wA / Block_Size раз.
10.4.2. Процедура перемножения матриц на GPU SM4
Рассмотрим конкретную программу, реализующую перемножение матриц на GPU SM4. Эта программа может быть откомпилирована любыми средствами, поддерживающими библиотеки CUDA. Детали реализации алгоритма обсуждаются в комментариях.
// Файл matrixMul_kernel. cu
#ifndef _MATRIXMUL_KERNEL_H_
#define _MATRIXMUL_KERNEL_H_
#include <stdio. h>
#include "matrixMul. h"
/* Следующая процедура имеет модификатор __global__, т. е. является вычислительным ядром. Это ядро исполняется одновременно на каждом мультипроцессоре и каждым потоком. Но всё-таки конкретные вычислительные процессы, исполняемые в различных «связках» и потоках, различаются значениями таких системных переменных, как blockIdx и threadIdx. Это позволяет нам «привязать» конкретные ячейки матриц к конкретным потокам.
Параметрами процедуры являются указатели (float*) на области оперативной памяти компьютера, в которых расположены матрицы A, B и C, а также целочисленные (int) значения wA и wB, задающие ширину входных матриц в единицах размера блока Block_Size */
__global__ void
matrixMul( float* C, float* A, float* B, int wA, int wB)
{
/* Присвоение локальным переменным значений координат текущей «связки» потоков */
int block_x = blockIdx. x;
int block_y = blockIdx. y;
/* Определение индексов (i, k), соответствующих конкретному потоку в составе «связки» */
int i = threadIdx. y;
int k = threadIdx. x;
/* Для понимания дальнейшего необходимо учесть, что в глобальной памяти графического процессора (Global memory на рис. 9.2) элементы исходных матриц A и B хранятся последовательно, в форме линейного массива, как это показано следующими формулами:
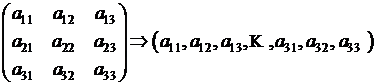 .
.
Как можно увидеть из рис. 9.4, элементы матрицы A, обрабатываемые одной «связкой», расположены в линейном массиве последовательно. Если нумеровать все элементы линейного массива подряд с нуля, то номер первого элемента последовательности, с которой работает заданная «связка» -
![]() .
.
Вводим целочисленную константу, равную этому начальному номеру: */
int a_First = wA * Block_Size * block_y;
/* Как, опять же, видно из рис. 9.4, последовательность элементов матрицы A, обрабатываемая выделенной «связкой», проходит через несколько блоков размера Block_Size, которые загружаются в разделяемую память поочерёдно. Для организации цикла, внутри которого будут загружаться в память и обрабатываться эти блоки, нам потребуется номер 1-ого элемента в последнем из блоков, который вычисляется по формуле
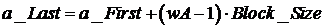 .
.
Определяем соответствующую целочисленную константу: */
int a_Last = a_First + (wA – 1) * BLOCK_SIZE;
/* Для организации этого же цикла потребуется шаг, задающий изменение 1-ого номера (т. е. «левого верхнего» элемента в блоке) при переходе от текущего блока к следующему */
int a_Step = Block_Size;
/* Индекс первого блока матрицы B, обрабатываемого текущей связкой
int b_First = Block_Size * block_x;
/* Шаг итераций «сверху вниз» (см. рис. 9.3) по блокам матрицы B */
int b_Step = Block_Size * wB;
/* Величины шагов при переходах от одних блоков к другим в матрицах A и B проиллюстрированы на рис. 9.5.
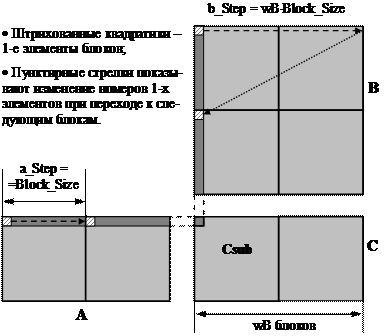
Рис. 9.5. Переходы к следующим блокам при умножении матриц */
// Вводим переменную, в которую будет записываться
//значение искомого элемента матрицы Csub (рис. 9.4-5)
float Csub = 0;
// Внешний цикл по всем блокам матриц A и B
for (int a = a_First, b = b_First;
a <= a_Last;
a += a_Step, b += b_Step) {
/* Создаём в разделяемой памяти массив, куда из глобальной видеопамяти будет скопирован очередной блок матрицы A. Модификатор __shared__ как раз означает, что массив As будет создан в «быстрой» разделяемой памяти */
__shared__ float As[Block_Size][Block_Size];
/* Такой же массив создается для хранения блока матрицы B */
__shared__ float Bs[Block_Size][Block_Size];
// Копируем блоки матриц в разделяемую память:
/* каждый поток загружает 1 элемент матрицы A и 1 элемент матрицы B */
As[i][k] = A[a + wA * i + k];
BS[i][k] = B[b + wB * i + k];
/* Принцип определения номера загружаемого элемента в блоке показан на рис. 9.6 */
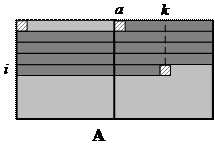
Рис. 9.6. Принцип расчёта линейного номера элемента с индексами (i, j) в текущем блоке: a – номер 1-го элемента в данном блоке, (i, j) – индексы вычислительного потока, копирующего данный элемент; эти индексы отсчитываются не от начала матрицы, а от начала блока.
/* Синхронизируем потоки, чтобы гарантировать то, что блоки матриц загружены полностью */
__syncthreads();
/* На этом этапе все элементы обрабатываемых блоков загружены в разделяемую память. Создавать цикл для их загрузки не требуется, так как этот код будет параллельно исполняться стольким числом потоков, равным количеству элементов в блоке матрицы Block_Size×Block_Size. */
/* Перемножение блоков матриц A и B, загруженных в «быструю» память GPU. Каждый поток вычисляет 1 элемент результирующей матрицы Csub
.
Использование оператора += обеспечивает добавление рассчитываемого слагаемого ко всей сумме
. */
for (int j = 0; j < Block_Size; ++j)
Csub += As[i][j] * Bs[j][k];
/* Отметим, что при суммировании выше конкретный поток работает не только с теми элементами матриц, которые были загружены в разделяемую память именно им, но и с другими элементами. Это показывает преимущество общего доступа потоков к разделяемой памяти. */
/* Синхронизируем потоки. Это гарантирует, что все вычисления будут закончены до того, как начнётся загрузка других блоков на следующей итерации внешнего цикла */
__syncthreads();
} // Возвращение к началу внешнего цикла
/* Обратное копирование вычисленного блока результирующей матрицы C в глобальную память GPU, где данные будут доступны центральному процессору. Каждый поток сохраняет 1 элемент */
int c = wB * Block_Size * block_y + Block_Size * block_x;
C[c + wB * i + k] = Csub;
}
#endif // #ifndef _MATRIXMUL_KERNEL_H_
10.4.3. Вызов процедуры перемножения матриц из программы на C
В принципе, использование CUDA позволяет писать процедуры для графического и центрального процессоров в одном и том же текстовом файле. В настоящем примере коды для GPU и для CPU разнесены в разные файлы, для того чтобы лучше структурировать проект. В Приложении 2 мы приводим код, исполняемый на СPU, с краткими комментариями. Подробности даны, например, в руководстве пользователя CUDA от NVIDIA [67].
В проект также должны входить заголовочный файл matrixMul.h и файл, содержащий непараллельную процедуру перемножения матриц на CPU matrixMul_gold.cpp. Тексты этих файлов [68] также приведены в Приложении 2.
10.5. Молекулярная динамика на CUDA
10.5.1. Алгоритм с использованием разделяемой памяти
Самые последние графические процессоры уже поддерживают вычисления с двойной точностью, что в принципе позволяет полностью реализовывать на GPU шаги молекулярной динамики, не обращаясь к центральному процессору. Всё же, здесь мы ограничимся только рассмотрением алгоритма расчёта межчастичных сил, который вполне демонстрирует новые возможности 4-й шейдерной модели и CUDA [69].
Этот алгоритм, приведённый на рис. 9.7, отличается от рассмотренных в главе 6 тем, что включает в себя «ручную» оптимизацию использования «быстрой» разделяемой параллельной памяти, которой не существовало у GPU шейдерной модели 3.0.
Кодирование алгоритма молекулярной динамики на CUDA не имеет принципиальных особенностей по сравнению с перемножением матриц, так что мы не будем приводить весь код. Остановимся только на одной из простых реализаций «треугольного» цикла расчёта сил, использующего 3-й закон Ньютона для двукратного уменьшения объёма вычислений.
10.5.2. Расчёт сил на GPU с использованием 3-го закона Ньютона
На рис. 9.8a (без учёта распараллеливания) показан самый простой цикл расчёта действующих между частицами сил. На GPU SM3 можно (с распараллеливанием) реализовать только этот цикл, поскольку каждая сила Fi рассчитывается независимо от сил Fj, действующих на другие частицы. Распараллеливание этого же цикла на GPU SM4 показано на рис. 9.7.
Вместе с тем, согласно 3-му закону Ньютона, Fij = -Fji, то есть ÑUij(Rij) = -ÑUji(Rji). Таким образом, алгоритм расчёта сил можно модифицировать согласно рис. 9.8б. В новом цикле суммирование по j начинается с j = i+1, а не с нуля, так что весь двойной цикл по i, j, становящийся «треугольным», содержит в 2 раза меньше операций вычисления сил. На рис. 9.9, иллюстрирующем «треугольный» цикл, тёмные прямоугольники соответствуют парам (i, j), для которых силы Fij реально считаются, а белые – обратным комбинациям (i, j), для которых Fji = - Fij.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
