

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 ИННОВАЦИОННАЯ ОБРАЗОВАТЕЛЬНАЯ ПРОГРАММА
ИННОВАЦИОННАЯ ОБРАЗОВАТЕЛЬНАЯ ПРОГРАММА
федеральное агентство по образованию
ГОУ ВПО «Уральский государственный технический университет – УПИ имени первого президента России Б.Н. Ельцина»
, ,
Системы и технологии управления параллельными вычислениями
Курс лекций
Научный редактор – доктор ф.-м. н., проф.
Екатеринбург
2008
УДК
, ,
К92 Физическое и математическое моделирование: курс лекций / , , . Екатеринбург: УГТУ-УПИ, 20 с.
В курсе лекций изложены основные методики высокоскоростного параллельного моделирования на графических процессорах, методы компьютерного моделирования процессов массопереноса в реакторных материалах, включающие методы численного решения дифференциальных уравнений, молекулярной динамики для моделирования свойств реакторных материалов. Продемонстрированы возможности указанных методов для расчета коэффициентов диффузии, дефектообразования, структурного разупорядочения и межчастичных взаимодействий в реакторных материалах и их структурных аналогах.
Курс предназначен для подготовки магистров по специальности 140305 «Ядерные реакторы и энергетичеcкие установки» (направление 140300 «Ядерная физика и технологии»).
Научный редактор – доктор ф.-м. н., проф.
Библиогр.: 69 назв. Рис. 67. Табл. 14. Прил. 2. | |
© Уральский государственный ©Купряжкин А. Я., Некрасов К. А., | |
Оглавление
ВВЕДЕНИЕ.. 7
1. Архитектура и принципы работы обычных ЭВМ с центральным процессором (CPU) 9
1.1. Структура традиционной ЭВМ.. 9
1.2. Организация работы ЭВМ.. 13
1.3. Иерархия памяти компьютера.. 13
1.4. Выполнение команд.. 24
1.5. Требования к коммуникационным линиям.. 24
1.6. Устройства ввода-вывода.. 25
2. Методы повышения производительности традиционных ЭВМ 27
2.1. Распараллеливание расчетов.. 27
2.2. Конвейерная обработка данных и команд.. 28
2.3. Высокопроизводительные процессоры.. 30
2.3.1. Суперскалярные процессоры.. 30
2.3.2. Процессоры RISC с сокращенным набором команд. 31
2.3.3. Процессоры со сверхдлинным командным словом. 34
2.3.4. Векторные процессоры.. 36
2.3.5. Процессоры для параллельных компьютеров. 37
2.3.6. Процессоры с многопоточной архитектурой. 38
2.3.7. Технология Hyper-Threading. 40
2.4. Требования к памяти высокопроизводительных ЭВМ 40
2.5. Коммуникационная сеть высокопроизводительных ЭВМ 41
2.5.1. Статические и динамические топологии и маршрутизация коммуникационных систем. 41
2.5.2. Многокаскадные сети и методы коммутации. 42
2.6. Классификация архитектур параллельных компьютеров 43
3. Типы архитектур высокопроизводительных вычислительных систем... 46
3.1. SIMD архитектура (с разделяемой и распределенной памятью) 46
3.2. MIMD архитектура с разделяемой и распределенной памятью 47
3.3. Комбинированные системы.. 50
3.4. Мультипроцессорные и мультикомпьютерные системы 52
3.5. Кластеры ПЭВМ и рабочих станций.. 52
3.6. Особенности параллельного программирования.. 57
4. Потоковые параллельные вычисления для физического моделирования.. 63
4.1. Общие принципы распараллеливания расчётов.. 63
4.2. Обмен данными между процессором и памятью... 65
4.3. Графические процессоры как вычислительные системы для поточно-параллельных расчётов.. 67
4.3.1. Вычислительные возможности центральных процессоров общего назначения и графических процессоров. 67
4.3.2. Графический конвейер. 69
4.3.3. История программируемости графических процессоров. 70
4.3.4. Требования к алгоритмам для GPU, поддерживающих шейдерную модель 3.0 73
4.3.5. Возможности GPU в рамках шейдерной модели 3.0 и взаимодействие GPU с памятью.. 77
4.3.6. Проблема одинарной точности. 79
4.4. Средства программирования графических процессоров 79
4.4.1. Общая структура программы
для физического моделирования на графическом процессоре. 79
4.4.2. Необходимое программное обеспечение. 81
4.5. Области использования графических процессоров.. 82
5. Применение графических процессоров на примерах сложения матриц и решения дифференциальных уравнений 83
5.1. Распараллеливание независимых вычислений.. 83
5.2. Используемый графический процессор. 85
5.3. Представление данных для графического процессора 85
5.4. Программирование вычислительного ядра.. 88
5.5. Взаимодействие центрального и графического процессоров 92
5.5.1. Функции центрального процессора. 92
5.5.2. Пример программы.. 93
6. Молекулярная динамика на графическом процессоре 101
6.1. Принципы моделирования ионных кристаллов методом молекулярной динамики.. 101
6.2. Программирование графического процессора для расчёта действующих на ионы результирующих сил.. 104
6.2.1. Исходные данные. 104
6.2.2. Представление исходных данных для GPU.. 105
6.2.3. Алгоритм расчёта результирующих сил с использованием графического процессора. 106
6.2.4. Шейдер для расчёта результирующей силы.. 108
6.3. Исполнение шейдера из программы МД-моделирования на C# 111
6.3.1. Этапы алгоритма моделирования, исполняемые на CPU.. 111
6.3.2. Процедуры на C#, обеспечивающие работу с графическим процессором 113
6.4. Постановка граничных условий и стабилизация
макросостояния молекулярно-динамической системы 120
6.4.1. Компенсация импульса и момента импульса. 120
6.4.2. Стабилизация температуры.. 122
7. Высокоскоростное моделирование систем с дальнодействием
7.1. Актуальность моделирования.. 126
7.2. высокоскоростные алгоритмы моделирования систем с дальнодействующими силами.. 127
7.3. Методика высокоскоростного молекулярно-динамического моделирования диоксида урана.. 138
7.4. Экспериментальные результаты и их обсуждение. 140
7.5. Анализ зависимостей среднего квадрата смещений ионов кислорода от времени.. 141
8.1. Задача восстановления потенциалов межчастичных взаимодействий в кристаллах.. 147
8.2. Исходные данные и метод восстановления потенциалов 147
8.3. Модель и детали реализации.. 150
9. Базовые особенности программирования графических процессоров шейдерной модели 4
9.1. Предпосылки появления новой шейдерной модели.. 162
9.2. Архитектура GPU шейдерной модели 4.0. Преимущества этой модели.. 163
9.2.1. Иерархия вычислительных блоков и памяти в шейдерной модели
9.2.2. Конвейерная обработка данных на GPU SM4. 166
9.2.3. Логическая структура вычислений на GPU SM4. 167
9.2.4. Преимущества GPU шейдерной модели 4
9.3. Средства высокоуровневого программирования GPU шейдерной модели 4
9.3.1. Совместимость с шейдерной моделью 3
9.3.2. Специальные средства программирования GPU SM4.
CUDA 169
9.3.3. Средства для написания и компиляции
программ на CUDA.. 170
9.3.4. Структура программы на CUDA.. 171
9.4. Перемножение матриц на CUDA.. 171
9.4.1. Алгоритм перемножения матриц. 171
9.4.2. Процедура перемножения матриц на GPU SM4. 174
9.4.3. Вызов процедуры перемножения матриц из
программы на C.. 179
9.5. Молекулярная динамика на CUDA.. 180
9.5.1. Алгоритм с использованием разделяемой памяти. 180
9.5.2. Расчёт сил на GPU с использованием
3-го закона Ньютона. 180
Библиографический список.. 185
Приложение 1 Операторы и функции языка HLSL, использованные в курсе лекций.. 190
П.1.2. Типы данных.. 190
П.1.2. Встроенные функции.. 190
П.1.3. Другие операторы и выражения.. 190
П.1.4. Системные переменные. 191
Приложение 2 Процедуры CUDA,
исполняемые на CPU.. 192
ВВЕДЕНИЕ
Рост объема вычислений, связанный с усложнением задач, решаемых с помощью ЭВМ в военной, технологической, научной и финансовой областях, привел к созданию мощных суперкомпьютеров и их более дешевых заменителей, многопроцессорных вычислительных комплексов – суперкластеров.
Несмотря на меньшую стоимость высокопроизводительные суперкластеры все еще достаточно дороги, занимают достаточно много места и имеют большой вес.
Так, например, 40-ядерный кластер, обеспечивающий при идеальном распараллеливании ускорение расчетов не более чем в 40 раз, требует для установки отдельную комнату, персонал для обслуживания и стоит порядка 2-млн. рублей.
Представляется перспективной разработка высокопроизводительных персональных ЭВМ разных классов, базирующихся на применении в качестве основных процессоров – графических процессоров. Последнее, как позволяет заключить имеющийся опыт, позволит в существенной мере (на порядки) минимизировать недостатки суперкластеров, сохранив, а в отдельных случаях и превысив их производительность.
Первые две лекции данного конспекта посвящены описанию архитектуры и принципов работы обычных ЭВМ. Последнее сделано для того, чтобы в дальнейшем материале можно было более четко акцентировать все последующие шаги по повышению их производительности.
Во втором разделе, включающем три лекции, изложены методы повышения производительности обычных ЭВМ, обеспечивающие эффективность работы высокопроизводительных ЭВМ. Последние к настоящему времени образуют отдельную отрасль, в которой разрабатывают и создают ЭВМ для решения сложных задач с большим потоком данных и сложными арифметическими операциями. Используют эти суперкомпьютеры в самых разных областях науки – от обработки статистики по чрезвычайным ситуациям во всей стране, до расчета сложнейших уравнений химических реакций. От обычных высокопроизводительные ЭВМ отличают большие на порядок (и более) объем памяти, быстродействие и прочие характеристики, существенные для выполняемых операций. Подобные компьютерные гиганты по карману далеко не всем исследовательским центрам. Поэтому сейчас высокопроизводительную ЭВМ вполне можно создать из нескольких обычных ЭВМ, объединив их в сеть.
В третьей части (в рамках одной лекции) проанализированы типы архитектур высокопроизводительных вычислительных систем, показано, что решение вопроса разработки высокопроизводительной и экономной ЭВМ может быть достигнуто за счет использования графических процессоров.
Основная часть материала лекций посвящена относительно новому методу высокоскоростного программирования на графических процессорах и проведению моделирования физических процессов в реакторных материалах с помощью указанных процессоров.
Этот раздел включает описание принципов работы графических процессоров, приемов их программирования. В нем достаточно подробно изложено описание взаимодействия графического и центрального процессоров, приведены конкретные примеры составления общей программы.
Особое внимание в этом разделе уделено программированию задачи моделирования методом молекулярной динамики кристаллов диоксида урана. Рассмотрены задачи восстановления потенциалов межчастичных взаимодействий по температурной зависимости периода решетки кристалла, получении коэффициентов диффузии кислорода по временной зависимости среднеквадратичных смещений по анализу механизмов диффузии кислорода в диоксиде урана.
Закрепление знаний, получаемых после чтения курса, предполагает выполнение ряда практических занятий, для которых имеется учебное пособие.
2. Архитектура и принципы работы обычных ЭВМ с центральным процессором (CPU)
По производительности и по внешнему виду современные компьютеры мало чем напоминают первые ЭВМ. В качестве примера можно привести компьютер, который мог занимать весь этаж института, а по выполняемым функциям едва дотягивал до того, что сейчас может сделать ноутбук, размером с школьный учебник. Однако, основные идеи, а также составные части, алгоритмы (хотя параллельную обработку следует признать колоссальным прорывом) практически не претерпели изменений со времен Алана Тьюринга и Джона фон Неймана. Поэтому в качестве основы всегда приводят неймановскую архитектуру ЭВМ.
2.1. Структура традиционной ЭВМ
Архитектура ЭВМ фон Неймана предполагает наличие в ЭВМ следующих устройств:
Арифметико-логическое устройство - АЛУ;
Устройство управления – УУ;
Запоминающее устройство – ЗУ;
Устройство ввода-вывода – УВВ;
Пульт управления – ПУ.
С развитием технологии некоторые узлы объединяют, так например, центральный процессор представляет АЛУ и УУ. Поэтому схематично структуру можно представить следующим образом (рис. 1.1):
Теперь остановимся на основных узлах компьютера подробнее.
Процессор. Основное устройство ЭВМ. Процессор – вычислительное устройство. Счет происходит по специальным алгоритмам. В значительной степени быстродействие всей ЭВМ определяется производительностью (быстродействием) именно процессора. Для увеличения производительности в процессоре есть небольшая собственная память, называемая
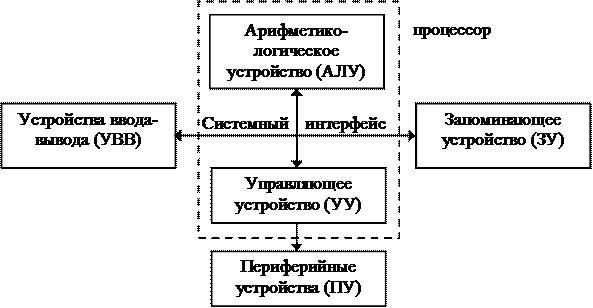
Рис. 1.1 Обобщённая логическая структура ЭВМ
сверхоперативной. Это позволяет отказаться от постоянного обращения к запоминающим устройствам. Все вычисления представляются в виде программы. Т. е. в виде инструкций для процессора в порядке их выполнения. При поступлении команды, процессор расшифрует ее, определит какие именно действия и над какими именно операндами необходимо выполнить (фактически, как таковых операций нет. К процессору поступает набор чисел – адресов ячеек памяти. В них может быть все что угодно – операция или операнд). Операции расшифровки и определения действия выполняет УУ. При помощи него же операнды из ЗУ помещаются в АЛУ. АЛУ, под управлением УУ, производит необходимые действия.
Память. Как было сказано выше, данные и программа находятся в ЗУ – памяти ЭВМ. Память – сложная структура, организованная по иерархическому принципу. В ней существуют (ЗУ) разных типов. Функционально их делят на внутреннюю память и внешнюю.
Под внутренней памятью понимают ЗУ, напрямую связанную с процессором. В ней хранится исполняемая часть кода программы и данные, которые непосредственно используются в вычислениях. Эту память отличает высокое быстродействие, однако она очень сильно ограничена по объему. Внутреннюю память делят на оперативную (ОЗУ) и постоянную (ПЗУ). Основную часть внутренней памяти составляет ОЗУ, именно в ней принимается, хранится и через нее выдается информация. Эта память энергозависима. Т. е. при выключении питания, данные, находящиеся в ней потеряются. ПЗУ заполняется на этапе изготовления ЭВМ (в ней находятся часто используемые (универсальные) программы, данные необходимые для загрузки и тестирования оборудования ЭВМ). Эта часть внутренней памяти энергонезависима.
Внешняя память – самая большая по объему вмещаемой информации. Выполнение запросов процессора выполняется без его непосредственного вмешательства. К внешней памяти относятся как жесткие диски, так и различные накопители (CD, DVD, карты памяти, внешние жесткие диски). Последние позволяют быстро и удобно переносить данные с одной ЭВМ на другую, однако обладают меньшим быстродействием. Чаще всего они служат для резервирования информации.
УВВ. Устройства ввода вывода ЭВМ, с которыми пользователь взаимодействует непосредственно. Именно к этой группе относятся клавиатура, мышь, монитор, принтер, сканер, различные манипуляторы и многие другие периферийные устройства. Это самое необходимое звено для общения человека и ЭВМ.
Для связи устройств ЭВМ существует системный интерфейс. В малых ЭВМ в качестве системного интерфейса используются системные шины. В высокопроизводительных ЭВМ могут использоваться специальные устройства, имеющие встроенные процессоры. Это обеспечивает высокую скорость передачи данных. По системным шинам может передаваться различная информация (различают шины адреса и шины данных, шины управляющих сигналов).
При описании ЭВМ важно выделить ее основные характеристики, такие как:
Быстродействие. С одной стороны, это количество элементарных операций, выполняемых центральным процессором в секунду (любая простейшая операция – сложение, пересылка, сравнение и т. д.). С другой – узким местом зачастую становится память ЭВМ. Т. к. независимо от количества возможных операций, при нехватке данных, основное ограничение будет накладывать время поиска необходимых операндов в памяти.
Производительность. В отличие от быстродействия, которое обусловлено системой элементов, производительность связана с архитектурой ЭВМ. Величина быстродействия не является постоянной, выделяют пиковое быстродействие (определяется тактовой частотой процессора без учета обращений к оперативной памяти), номинальное (учитывается время обращения к оперативной памяти), системное (учитываются системные издержки на организацию вычислительного процесса), эксплутационное (определяется характером решаемых задач).
Объем памяти. Величина, показывающая максимальный объем данных, которые можно хранить в ЭВМ.
Точность вычислений. Определяется разрядностью процессора (количеством разрядов, используемых для представления одного числа). В настоящее время используются 32 и 64 –разрядные процессоры. Для повышения точности используют удвоенную или утроенную разрядную сетку. При этом число разбивают на несколько частей, и каждую из них записывают в виде отдельного числа.
Система команд. Это набор команд, которое способен выполнить процессор ЭВМ. Также она показывает в каком виде должны быть записаны операнды, какой формат должны иметь команды. В современных процессорах число элементарных команд составляет от десятка до сотен команд. Это такие операции как сложение, сравнение, передача числа из регистра в регистр, преобразование в различные системы счисления. Сейчас выделяют две основные системы формирования команд. Это архитектура CISC (Complete Instruction Set Computer) – компьютер с полным набором команд, и RISC (Reduced Instruction Set Computer) – компьютер с сокращенным набором команд. Вторая архитектура проще в аппаратной реализации, однако при программировании необходимо «объяснять» процессору большее число операций.
Стоимость. Эта характеристика определяется набором элементов каждой конкретной ЭВМ. Сюда же относят стоимость внешних элементов, а также стоимость программного обеспечения.
Надежность. Эта характеристика во всех областях определяется одинаково, как способность сохранять свои свойства при заданных условиях эксплуатации в течение определенного времени. Для количественной оценки можно применять вероятность безотказной работы при данных условиях за определенное время, наработку на отказ и др. Зачастую отказ одного из элементов ЭВМ может привести к неработоспособности всей вычислительной системы.
Прочие характеристики. Сюда можно отнести габариты, масштабируемость, энергопотребление и др.
2.2. Организация работы ЭВМ
Организацию работы ЭВМ легко проследить на рис. 1.1. Следует отметить лишь некоторые моменты.
Как было сказано ранее, передача данных между элементами ЭВМ взаимодействие идет через системный интерфейс.
Вся работа программ строится на системе приоритетов. Каждому процессу присваивается определенный приоритет (в операционной системе Windows XP их 6: Низкий, Ниже среднего, Средний, Выше Среднего, Высокий, Реального времени). Далее (при последовательной обработке) каждому процессу выделяется процессорное время, т. е. время, в течение которого можно занимать ЦП. Далее начинает работу следующий процесс, потом следующий и т. д. Но, если у одного из процессов приоритет выше, чем у остальных, то предоставлять ресурсы ЦП ему будут существенно чаще.
Говоря о приоритетах, следует упомянуть то, что самым высоким приоритетом обладает обработчик нажатия клавиши клавиатуры или любого другого устройства управления.
2.3. Иерархия памяти компьютера
Кратко об иерархии памяти компьютера было рассказано в пункте 1.1. Физическая память компьютера имеет иерархическую структуру. Но логическая память организована иным способом. Об этом и пойдет речь в данном пункте.
Современные программы имеют очень длинный код и оперируют большими потоками данных. Все это должно хранится в ЭВМ. Размещение происходит в памяти. Однако при выполнении, данные и исполняемый код (возможно частично) должны находится в оперативной памяти. Однако там же (в оперативной памяти) должны находится компоненты операционной системы. Задачей распределения памяти между различными процессорами выполняет менеджер памяти.
Память можно разделить на внутреннюю и внешнюю. Внутренняя – это упорядоченный массив однобайтовых ячеек, обладающих уникальным адресом. Как было сказано в пункте 1.1, эта память энергозависима. Внешняя – энергонезависима, обладает намного большим объемом. Между внутренней и внешней памятью можно поместить промежуточную память (см. рис. 1.2).
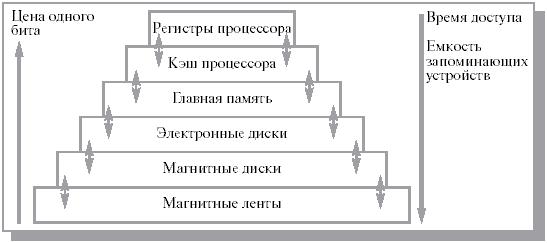
Рис. 1.2 Иерархия памяти [2]
При поиске необходимых данных процессор начинает искать на самом верхнем уровне. Если информации там нет, то он (процессор) продолжает поиск на более низком уровне. Так продолжается до тех пор, пока необходимые данные не будут найдены. Затем, найденная информация переносится на более быстрые уровни. Очевидно, что через некоторое время организуется некоторая система, в которой по мере увеличения времени доступа к уровню памяти, уменьшается частота обращений к нему. Оказывается, что реальные программы в некоторый временной промежуток работают с малым набором адресов. Это называют свойством локальности (локализация обращений). Подобный принцип справедлив не только в среде ЭВМ. Как правило, соседние во времени и пространстве объекты характеризуются схожими свойствами. Так и человек, решая задачу оперирует с ограниченным набором данных, остальное хранится во внешней памяти (например, в книгах). Программы работают по тому же принципу, какой-то фрагмент кода обрабатывает ограниченный набор данных. Поэтому, если он будет помещен в быструю память, то время доступа к нему существенно сократится. Именно это обусловливает использование иерархической схемы.
Кэш процессора, как правило, реализуется аппаратно. Поэтому менеджер памяти ОС распределяет информацию в основном во внутренней и внешней памяти. Иногда потоки между внутренней и внешней памятью регулирует сам разработчик программы, но это требует высокого уровня подготовки. Потому подобные операции передают ОС.
Под физическим адресным пространством понимают набор физических адресов (адреса основной памяти, указывающие на действительное расположение данных), с которыми работает программа.
Надо понимать, что программа состоящая из модулей, следующих друг за другом совсем не должна хранится в памяти именно таким образом (в общем случае вся программа может хранится в разных частях жесткого диска). Для того чтобы вся программа и данные образовывали линейное пространство адресов (располагались друг за другом) применяют сегментацию. Сегмент – область памяти, в которой поддерживается линейное пространство адресов. Т. е. сейчас память компьютера представляет собой двумерную, а не линейную структуру. Адрес имеет следующие компоненты – номер сегмента, смещение внутри сегмента. Оказалось, что удобнее размещать различные компоненты программы (данные, код и т. д.) в различных сегментах. На современном этапе развития можно контролировать сегменты (задать права доступа к ним и возможные операции). Пример расположения сегментов в памяти приведен на рис. 1.3.
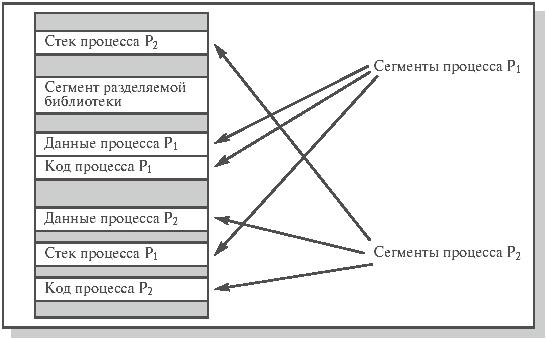
Рис. 1.3. Расположение сегментов процессов в памяти компьютера [2]
Практически все современные ОС поддерживают сегментную организацию памяти, а в ряде архитектур, это заложено на аппаратном уровне.
Таким образом, процесс обращается к адресу, который отличается от реального адреса в оперативной памяти. Адреса, используемые программой, могут быть представлены различными способами. В исходных текстах адреса чаще всего символические. Связь этих символических адресов с перемещаемыми адресами осуществляет компилятор. Такой адрес (сгенерированный программой) называют логическим. Совокупность логических адресов (иногда их называют виртуальными адресами) образует логическое (виртуальное) адресное пространство.
Как правило максимальный размер логического адресного пространства определяется разрядностью процессора (232, 264 и т. д.), что значительно превышает реальное физическое адресное пространство. Т. о. ОС и процессор должны отображать ссылки в коде программы в реальные физические адреса. Подобное отображение называют трансляцией (привязкой). Схема связывания адресов приведена на рис. 1.4.
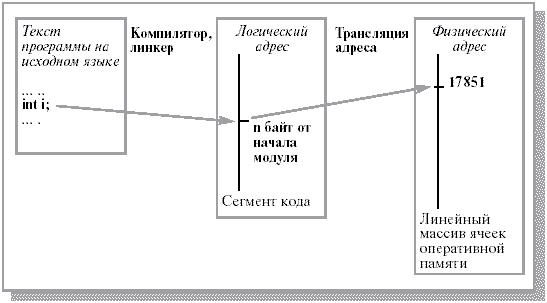
Рис. 1.4. Формирование логического адреса и связывание логического адреса с физическим [2]
Связать физический и логический адрес можно на следующих этапах.
Компиляция. Если на этапе компиляции точно известно место размещения процесса в памяти. В случае изменения стартового адреса программы, необходимо перекомпилировать код.
Загрузка. Когда неизвестно размещение программы на стадии компиляции, компилятор должен генерировать перемещаемый код. Тогда связывание произойдет на этапе загрузки. При изменении начального адреса, перезагружают код с учетом этого изменения.
Выполнение. В случае, когда есть возможность перемещать процессы прямо во время выполнения из одной области памяти в другую, связывать адреса необходимо на этапе выполнения. Для контроля подобной смены служат регистры перемещения. В современных ОС трансляция осуществляется на этапе выполнения.
Лекция 3. Управление памятью ЭВМ и доступ к данным
Рассмотрим системы управления памятью. Первые ОС работали с памятью достаточно просто. Каждый из процессов полностью помещался в основную память, должен был занимать непрерывную область памяти. Система могла принимать для обслуживания дополнительные процессы до тех пор, пока они могли поместиться в памяти все одновременно. Позже появилась система с «простым свопингом». Такие ОС, как и раньше, размещали каждый из процессов целиком в памяти, но теперь появлялась возможность целиком сбрасывать процесс из основной памяти во внешнюю и вносить на его место другой процесс. Такие сбросы производились по какому-нибудь критерию. Теперь рассмотрим системы, применяемые на некоторых современных компьютерах.
Система с фиксированными разделами. Это наиболее простой способ организации памяти. Система на этапе загрузки разбивает всю память на несколько разделов фиксированной величины. Новые процессы размещаются по этим разделам. В этом случае происходит разбивка физического адресного пространства. Связывание физического и логического адресов процесса происходит на этапе его загрузки в раздел или на этапе компиляции. Можно организовать как глобальную очередь, так очередь процессов для каждого из разделов. Оценка размера поступившего процесса, выборка подходящего для него раздела, загрузка процесса в раздел, настройка адресов осуществляется подсистемой управления памятью.
Среди недостатков такой системы выделяют следующие.
Число одновременно выполняемых процессов ограничено числом разделов.
Большая внутренняя фрагментация. Возникает в случае, когда процесс не полностью занимает выделенный ему раздел или наоборот, некоторые разделы очень малы по сравнению с пользовательским приложением.
В качестве примера работы схемы с фиксированным разделом можно привести работу менеджера памяти однозадачной ОС. В память попадает один пользовательский процесс. По такому принципу работала ОС MS-DOS. Ограничить область памяти, в которой расположена ОС, помогает граничный регистр. Он хранит адрес границы ОС.
Оверлейная структура. Как было сказано выше, процесс может занимать больше места, чем выделенное ему адресное пространство (может быть даже больше, чем целый раздел). В такой ситуации можно воспользоваться структурой с перекрытием (overlay). При такой организации в памяти содержатся только те инструкции программы, которые необходимы в текущий момент. Реализовывать подобную схему имеет смысл в ситуации, когда логическое адресное пространство мало. Коды ветвей хранятся на диске в качестве абсолютных образов памяти. Драйвер считывает их при необходимости. Совокупность исполняемых программных файлов дополняется файлом, чаще всего, с расширением. odl Такое расширение связано с названием языка для описания оверлейной структуры – overlay description language. В приведенном примере на рисунке 1.6 текст фала может выглядеть как:
A-(В, С)
С-(D, E)
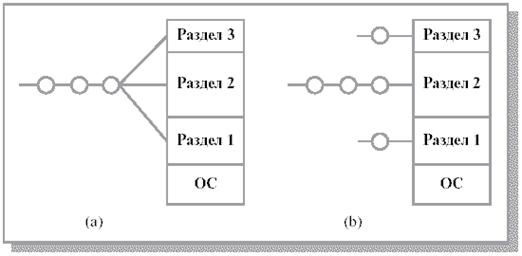
Рис. 1.5. Система управления памятью с фиксированными разделами. (а) – с общей очередью процессов, (b) – с отдельными очередями процессов [2]
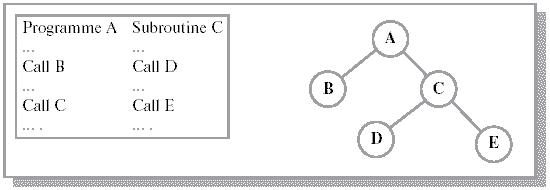
Рис. 1.6. Оверлейная структура организации памяти [2]
Динамическое распределение памяти. Если память не в состоянии хранить все пользовательские процессы, то не обойтись без свопинга
(swapping). Swapping – перемещение процессов из главной памяти целиком на диск и обратно. Частично выгружать можно процессы в случае со страничной организацией памяти (об этом будет сказано несколько слов дальше). Процесс, который был выгружен, можно вернуть обратно в память в то же самое адресное пространство или в другое (это будет зависеть от метода связывания). Сам свопинг с непосредственного отношения к управлению памятью не имеет. Его относят к подсистеме планирования процессов. Применение свопинга неизбежно увеличивает время переключения контекста. Несколько улучшить этот показатель можно, если на диске выделить специальное пространство для свопинга. В таком случае обмен будет идти блоками большего размера, это быстрее, чем через обычную файловую систему.
Схема с переменными разделами. Изначально память не разделена. Каждый поступающий процесс получает столько места, сколько ему необходимо. После выгрузки процесса память освобождается.
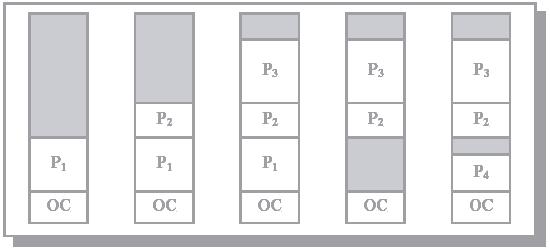
Рис. 1.7 Динамика распределения памяти между процессами (серым цветом обозначена неиспользуемая память) [2]
При поступлении процесса возникает проблема, куда, в какой раздел поместить процесс? Применяют одно из трех решений.
First fit. Первый подходящий. Процесс помещается в первый подходящий по размеру раздел.
Best fit. Наиболее подходящий. Процесс помещается в раздел, в котором останется меньше всего свободного места после размещения.
Worst fit. Наименее подходящий. Процесс помещается в самый большой раздел. Хитрость решения в том, что после размещения в разделе, возможно, там останется место для еще одного процесса.
В ходе исследований было показано, что лучше со своей задачей справляются первый и второй способы. Причем первый делает это несколько быстрее. Работа происходит следующим образом: анализ запроса на выделение участка памяти, выбор среди доступных участков в соответствии со стратегией, загрузка процесса в выбранный раздел, изменение таблиц свободных и занятых областей. Такая же корректировка необходима и при выгрузке процесса из памяти. Связать адреса можно на этапе загрузки или выполнения. Такой метод более гибок по сравнению с методом фиксированных разделов. Но и ему свойственна фрагментация. Она вызвана тем, что остается много неиспользованных участков, которые не выделяются ни одному из процессов. Даже если работать по принципу Best fit, фрагментация все равно будет. Причем, не исключено, что этот метод даст наихудшие показатели в этой области, т. к. он оставляет очень много маленьких несвязанных блоков памяти. По статистике пропадает около 1/3 памяти. Решить эту проблему от части помогает дефрагментация – перемещение занятых частей памяти в одну ее часть, а свободных – в другую. Тут срабатывает тот факт, что в отличие от занятой памяти, свободную можно объединять. Но эта операция связана с большими накладными расходами (влечет за собой операции выгрузки и загрузки в память).
Страничная память. В современных ОС процесс в оперативной памяти целиком непрерывным блоком располагается очень редко. Наиболее проста и распространена страничная организация памяти. Логическое и физическое адресные пространства представляются в виде страниц (блоков) одинакового размера. В таком случае образуются логические страницы (page), а соответствующие им страницы физической памяти называют страничными кадрами (page frames). Страницы и страничные кадры имеют фиксированную длину (как правило, степень числа 2). Страницы не могут перекрываться. Один кадр содержит одну страницу данных. В таком случае внешней фрагментации не будет, а внутренняя фрагментация будет определяться свободной частью последней страницы процесса. Логический адрес в такой системе представляет собой упорядоченную пару (p, d), где p – номер страницы, а d – смещение в рамках страницы р. Подобная разбивка проделывается операционной системой, так что ни пользователь, ни программист этого не замечают. Адрес двумерный только для ОС, для всех остальных он линеен. В такой схеме процесс может быть загружен целиком, даже если для него нет непрерывной области кадров. По сути вся эта система сводится к системе отображения логических страниц в физические и представляет собой таблицу страниц, хранимую в оперативной памяти.
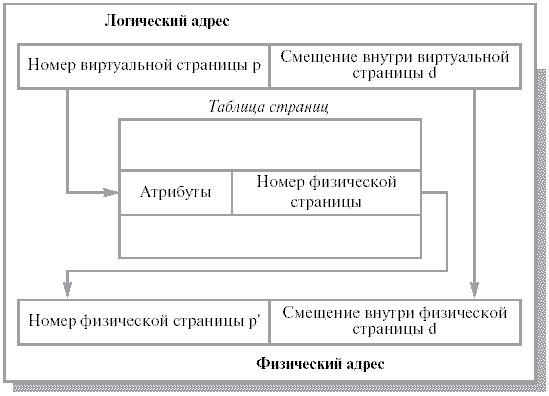
Рис. 1.8. Связь логического и физического адресов
при страничной организации памяти [2]
Если процессу необходим логический адрес (p, d), то механизм отображения ищет номер страницы р в таблице страниц. Определив, что эта страница находится в страничном кадре p’, формирует реальный адрес (p’ , d). Таблица страниц (page table) адресуется при помощи специального регистра процессора. С ее помощью можно определить номер кадра, исходя из логического адреса. В принципе, на ее основе, благодаря атрибутам, хранимым в строке таблицы страниц, возможно организовать контроль и защиту конкретной страницы. Важной особенностью является то, что процессу пользователя чужая память недоступна (это следствие того, что для пользователя память представляется линейным пространством). Т. е. нельзя адресовать память за пределами своей таблицы страниц. Поддержка структуры таблицы кадров позволяет ОС управлять физической памятью. В этой таблице существует одна запись на каждый физический кадр. Отображение адресов чаще всего реализуется аппаратно. Для ссылки на таблицу используется специальный регистр.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
