

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис. 2.2. Трехмерный тор [6]
Для фирмы Terra, как не сложно догадаться, была создана Unix-подобная операционная система. В ней использовалась BSD-версия Unix и микроядро, которое было разработано самостоятельно.
3.3.7. Технология Hyper-Threading
В первой половине 2002 года была представлена технология Hyper-Threading на процессоре Intel Xeon. Эта разработка позволяла обрабатывать данные в многопоточном режиме. Команды пересылки данных разбивались на параллельные потоки за счет архитектурного дублирования регистров микропроцессорных схем. Т. е. один процессор мог обрабатывать данные в таком режиме, как работают два процессора со своими потоками команд и наборами данных. Сейчас возможен выпуск полностью многопоточных процессоров, аналогичных архитектуре Terra MTA.
3.4. Требования к памяти высокопроизводительных ЭВМ
Исходя из задач, решаемых суперЭВМ, требования к памяти не только выше, чем у обычных ЭВМ, но их еще и больше. Т. к. приложения для высокопроизводительных ЭВМ должны работать с большим количеством данных, охватывать большой объем ресурсов, обработка происходит длительное время (это связано с длительным циклом обработки), то память должна отвечать следующим критериям:
Иметь максимальный объем памяти.
Обеспечивать возможность асинхронного ввода-вывода.
Иметь возможность организовать массивное хранилище данных.
Обеспечивать высокоскоростной ввод-вывод.
Иметь возможность передачи данных удаленным системам.
Преобразовывать данные для различных технических средств.
3.5. Коммуникационная сеть высокопроизводительных ЭВМ
Одним из важнейших элементов архитектуры высокопроизводительных ЭВМ является коммуникационная сеть. Благодаря ей можно связать процессоры между собой, с памятью и другими устройствами. Существуют две основные топологии сетей – статические и динамические.
Как только к сетевым устройствам был добавлен переключатель, появилась возможность организовывать многокаскадные сети.
3.5.1. Статические и динамические топологии и маршрутизация коммуникационных систем
Основным отличием статических топологий от динамических является то, что все соединения в такой сети фиксированы. У динамических топологий в межпроцессорных соединениях используются переключатели. Говоря о топологиях вообще (о локальных сетях) можно выделить следующие (см. рис.2.3.):
Шина (1) – обмен происходит через единственную шину. Она, как правило становится узким местом.
Звезда(2) – обмен информацией идет через концентратор.
Кольцо(3) – информация запускается в кольцо и циркулирует по нему до тех пор, пока не придет к нужному адресату (сигнал идет в одном направлении).
Многокаскадные и многосвязные сети (они являются комбинацией предыдущих).
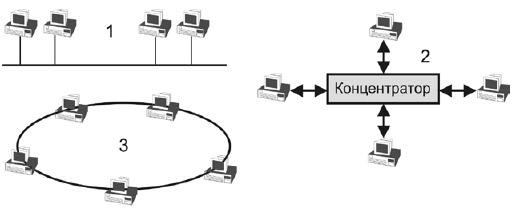
Рис. 2.3. Сетевые топологии [7]
Рассмотрим случай, когда узлы соединены в по схеме на рис.2.3. Для выбора маршрута передачи данных необходимо выполнить смещение по оси X, затем –Y и в конце – Z. Сетевые маршрутизаторы (аппаратное устройство, находящееся в месте соединения коммуникационных линий, направляющее пакет данных) должны определять путь перемещения пакета данных. Для удобства, каждому узлу присваивают уникальный физический номер, который определяет его положение. Вполне возможен случай, что несколько узлов будут держаться в резерве (так было сделано с компьютером CRAY T3D).
3.5.2. Многокаскадные сети и методы коммутации
Основой многокаскадных систем (возможные соединения показаны на рис. 2.4, 2.5), как было сказано ранее, являются переключатели (коммутаторы). Они помещаются между процессорами или другими узлами. При передаче информации переключатели устанавливаются таким образом, чтобы получилось необходимое соединение. В принципе, возможен вариант, когда один из маршрутов заблокирует все остальные маршруты. Это может иметь неблагоприятные последствия, но иногда такую возможность вносят специально. Чтобы связать все элементы между собой, необходимо построить матричный коммутатор (например, использовать топологию «звезда»). При такой реализации любой из процессоров может обратиться к любому модулю памяти. Может возникнуть конфликт, когда несколько процессоров обратятся к одному модулю памяти (вот тут на помощь может прийти система блокировки). При расширении сети ощутимо возрастает число переключателей. Очевидно, что для системы из N процессоров и N модулей памяти необходимо 2×N переключателей.
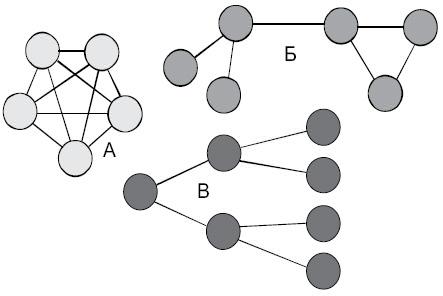
Рис. 2.4. Возможные связи в коммуникационных сетях.
А – каждый узел соединен с каждым, Б – смешанная система,
В – иерархическая система связи [7]
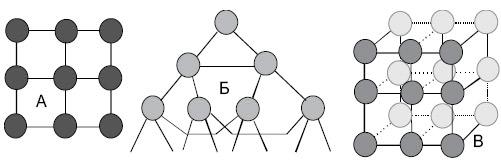
Рис. 2.5. Возможные топологии в современных вычислительных системах.
А – решетка, Б – гипердерево, В – куб [7]
3.6. Классификация архитектур параллельных компьютеров
Все, что было сказано в п. 2, может быть использовано как классификатор архитектур. Высокопроизводительные ЭВМ можно разделять по способам обработки параллельных данных, по организации памяти, по топологии связи между узлами, даже по способам выполнения арифметических операций. Попытки прийти к единой классификации предпринимались очень давно и продолжаются до сих пор. На данный момент наиболее распространена классификация Флина, предложенная еще в 1966г. Он разделил все архитектуры (в том числе и не высокопроизводительные) по потокам, т. е. по последовательности элементов (команд, данных), обрабатываемых процессором. Всего было выделено 4 класса:
SISD - Single Instruction Single Data – один поток данных, одна инструкция;
MISD - Multiple Instruction Single Data – один поток данных, несколько инструкций;
SIMD - Single Instruction Multiple Data – несколько потоков данных, одна инструкция;
MIMD - Multiple Instruction Multiple Data – несколько потоков данных, несколько инструкций.
Наиболее просто эта классификация запоминается (к ней мы будем возвращаться в следующих пунктах) в виде следующей схемы:
Таблица 2.2.
Классификация архитектур параллельных компьютеров Флина
(схема для запоминания)
Одиночный поток команд (Single Instruction) | Множество потоков команд (Multiple Instruction) | |
Одиночный поток данных (Single Data) | SISD | MISD |
Множество потоков данных (Multiple Data) | SIMD | MIMD |
Остановимся на каждом типе несколько подробнее.
SISD (single instruction stream / single data stream). К этому классу относят последовательные компьютеры с одним процессором, который может обрабатывать только один поток последовательно обрабатываемых инструкций.
MISD (multiple instruction stream / single data stream). По определению такие системы должны выполнять несколько действий над одним потоком данных. Ни одна, созданная до настоящего момента, машина не попала в этот класс. Можно предположить, что к этому классу относят машины, которые работают с базой данных. По сути – база данных, над ней выполняют множество команд.
SIMD (single instruction stream / multiple data stream). Организовать такую систему можно, только имея множество процессоров. Они будут выполнять одну инструкцию на несколькими потоками данных. Подклассом такого рода систем являются векторные компьютеры. Подобно скалярным процессорам, идет обработка массивов сходных данных. Подробно об этом написано в п. 2.3.4.
MIMD (multiple instruction stream / multiple data stream). Основное отличие от многопроцессорных SISD заключается в том, что MIMD-системы параллельно работают со связанными командами и данными. Это позволяет значительно ускорить процесс выполнения одной большой задачи. На самом деле, в этот класс попадает достаточно много систем. В этом классе окажутся вместе и четырехпроцессорный SX-5 (NEC) и тысячепроцессорный CRAY T3E. Однако, пока никто не предложил более удобной классификации. Учитывая темп развития современной техники, вполне возможно, что она появится в самом ближайшем будущем.
Приведенная классификация лишь помогает понять особенности работы архитектуры, но не позволяет «рассмотреть» детали (как в примере с MIMD-архитектурой).
4. Типы архитектур высокопроизводительных вычислительных систем
4.1. SIMD архитектура (с разделяемой и распределенной памятью)
Чаще всего, при упоминании архитектуры SIMD, понимают матричные процессоры. Эти процессоры имеют общее управляющее устройство, которое генерирует поток команд. Также в составе есть несколько процессорных элементов, которые работают параллельно и каждый обрабатывает свой поток данных. По сути, общая производительность системы должна равняться сумме производительностей, входящих в нее элементов. Но чтобы приблизится к этой величине необходимо применять ряд технических решений. В частности, необходима организация связи между процессорными элементами для полной их загрузки. Пример такой связи приведен на рис. 3.1.
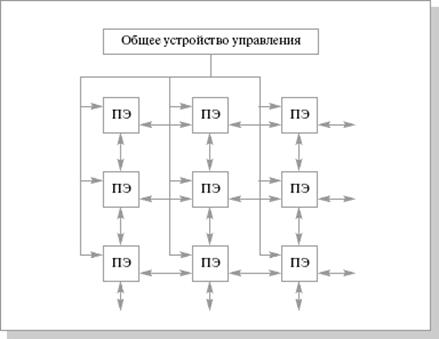
Рис. 3.1. Структура матричной вычислительной системы SOLOMON (60-е годы) [8]
В этом процессоре была реализована многомодальность. В каждом процессорном элементе существовал специальный регистр (регистр моды), которой имел четыре состояния. Мода попадала в этот регистр от устройства управления. В ходе выполнения команд моды передаются в коде операции и сравниваются со значением регистра. Если значения совпадают, то операция выполняется. В других случаях операция не выполняется, но процессорный элемент может передать свои операнды соседнему элементу. Такое решение позволяет выделять строки или столбцы процессорных элементов. Это очень удобно при работе с матрицами.
4.2. MIMD архитектура с разделяемой и распределенной памятью
Вторым по быстродействию устройством в компьютерах (после процессора) является оперативная память. Это связано с несколькими факторами. Во-первых, само время цикла работы с памятью tmem больше времени цикла работы центрального процессора tcp. Во вторых, при обращении к памяти она будет занята в течение времени tcp+tmem. Для уменьшения подобных задержек существует два возможных варианта. Организовать работу на основе разделяемой памяти, когда есть одна большая память и все процессоры имеют одинаковый доступ к ней. Или работать с распределенной памятью, выделив каждому процессору свою оперативную память (локальную) и запретить доступ к ней со стороны других процессоров. Разрабатывать программу, не зная какой тип памяти будет использоваться на данном параллельном компьютере, - бесполезное занятие. Так например, что делать при перемножении двух матриц? Если вы работаете по первому варианту, то можно один раз задать структуру данных и разместить ее в памяти. А если реализована разделяемая память, то необходимо создать копии матриц на каждом процессоре, т. е. послать всем процессорам сообщение с данными о матрицах.
Наиболее просто реализовать разделяемую память следующим образом – соединить одной шиной все процессоры, в конце поставив оперативную память. Конечно, такой вариант не идеален из-за постоянных конфликтов между процессорами. Если одни из процессоров начнет принимать или передавать данные, то доступ к оперативной памяти для остальных процессоров будет закрыт. Этот конфликт приводит к тому, что появляется предел производительности. Увеличение числа процессоров не будет приводить к увеличению производительности – шина станет узким местом. Однако, и это научились обходить. Достаточно ввести систему кэш-памяти для хранения команд. К каждому процессору добавляют локальную кэш-память. Причем, каждая следующая необходимая процессору команда будет с большой вероятностью находится там. Соответственно, уменьшается число обращений к шине уменьшится, а это позволит добавить в систему еще несколько процессоров. Проблема кэш-памяти – это ее локальность. Если двум процессорам понадобилось из общей памяти значение С1, то это значение скопируется в обе кэш-памяти. Один из процессоров меняет значение переменной и отправляет обратно в общую память. В это время второй процессор работает, совершенно ничего не подозревая, со старым значением С1. Такое несоответствие влечет необходимость постоянного обновления данных в кэш-памяти всех процессоров. Можно реализовать разделяемую память на нескольких физических модулях. Для процессоров эти устройства будут представлены как единое (подробнее в п.3.3). Но для правильной работы необходимы переключатели. Если обращений к одному и тому же дискретному модулю от разных процессоров не много, то быстродействие возрастет.
Для организации распределенной памяти, как было сказано выше, необходимо подключить собственную оперативную память каждому процессору. При такой архитектуре нет необходимости использовать общую шину и переключатели, т. е. исчезают конфликты, связанные с этими устройствами. Но взамен тех проблем появляются новые. Они связаны с корректной организацией обмена информацией между процессорами. Проще организовать такой обмен при помощи сообщений, в которых будут содержаться данные. На формирование, обработку, получение и отправление таких пакетов уходит время, что, естественно, сказывается на производительности.
Оба варианта организации работ с памятью с успехом применяются, что и нашло отражение в SMP и MPP системах.
SMP (symmetric multiprocessing) – симметричная мультипроцессорная архитектура. Архитектура с общей разделяемой памятью. При такой организации все процессоры имеют одинаковые права на доступ к памяти и одинаковую адресацию для всех ячеек памяти (отсюда и название – симметричная). Такой способ очень удобен при обмене данными между процессорами. Основой в SMP-системе является высокоскоростная шина, к слотам которой можно подключить процессорные элементы (ПЭ), подсистему ввода/вывода (I/O). Работа контролируется операционной системой (ОС). Наиболее часто применяется такая система в серверах.
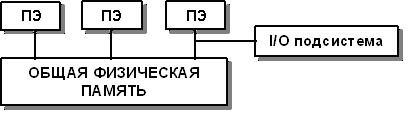
Рис. 3.2. Схематичный вид SMP-архитектуры [9]
За счет SMP-архитектуры можно получить простую и универсальную систему для программирования. В этой системе нет ограничений на модель программирования (можно организовать модель параллельных ветвей с независимыми процессорами или модель с межпроцессорным обменом). Кроме того можно получить доступ сразу ко всему объему памяти, возможность использовать средства автоматического распараллеливания (зачастую они оказываются достаточно эффективными), облегчить эксплуатацию системы, понизив ее цену.
Но поскольку система использует общую память, то ее недостатки напрямую связаны с недостатками систем с распределенной памятью, включающими плохую масштабируемость, частые конфликты между процессорными элементами, ограниченную пропускную способность системной шины. Так возможно использовать не более 32 процессоров (как следствие предыдущих трех недостатков).
Альтернативой SMP стала MPP-архитектура.
MPP(massive parallel processing) – массивно-параллельная архитектура. Как не сложно догадаться, эта архитектура основана на физически разделенной памяти. Такую систему можно строить на основе отдельных модулей, состоящих из процессорного элемента (ПЭ), локальной операционной памяти (ОП), двух коммуникационных процессоров (роутеры) или сетевого адаптера. Возможно подключение периферийных устройств. Наличие сразу двух сетевых адаптеров связано с тем, что один из них работает на передачу команд, другой – на передачу данных. В принципе, каждый модуль может выступать как самостоятельная, независимая ЭВМ. Доступ к ОП имеет только ПЭ из того же модуля. Между собой модули соединены коммуникационными каналами, по которым и происходит обмен информацией. Организовать работу MPP-систему можно двумя способами:
С управляющей машиной. В этом случае один из модулей работает в качестве основного, контролирующего все остальные. Именно на главном модуле будет стоять полновесная операционная система и программное обеспечение. На остальных модулях можно использовать урезанные варианты ОС и ПО, которые позволят модулю выполнять работу только его ветви распараллеленного приложения.
Равноправные модули. Каждый модуль имеет полноценные ОС и ПО.
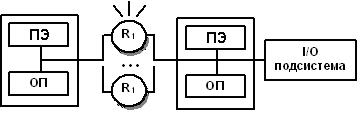
Рис. 3.3. Схематичный вид MPP-архитектуры [9]
В отличие от SMP-систем, MPP легко масштабируется. Именно это является главным преимуществом. Число процессоров в таких системах может достигать нескольких тысяч.
Но MPP не лишена недостатков:
Меньшая, по сравнению с SMP, скорость межпроцессорного обмена. Это связано с тем, что необходима специальная техника программирования для корректного обмена информацией между процессорами.
Ограниченность объема памяти каждого из процессоров.
Может возникнуть ситуация, и это не редкость, когда часть оборудования не будет загружена полностью.
В качестве примеров MPP-систем можно привести такие суперкомпьютеры как Hitachi SR8000, CRAY T3E (эту систему можно масштабировать до 2048 процессоров).
4.3. Комбинированные системы
Самым логичным решением после изучение SMP и MPP-систем было бы создать систему, объединяющую все достоинства и той и другой архитектуры. Так появилась гибридная система NUMA (Nonuniform memory access) – система с неоднородным доступом к памяти.
Память организована следующим образом – она физически является распределенной по различным частям системы, но процессоры видят ее как единую, с единым адресным пространством. NUMA-системы состоят из однородных базовых модулей, которые объединены при помощи высокоскоростного коммутатора. Сохраняется единое адресное пространство, доступ к памяти других процессоров (из других модулей) поддерживается на аппаратном уровне. Для доступа к локальной памяти требуется значительно меньшее время чем при доступе к удаленной (принадлежащей другому модулю).
NUMA-архитектура представляет собой MPP-архитектуру, где в качестве отдельных элементов использованы SMP узлы. Чтобы легче было понять, что же имелось ввиду в последнем предложении, приведем схему компьютера с комбинированной организацией памяти.
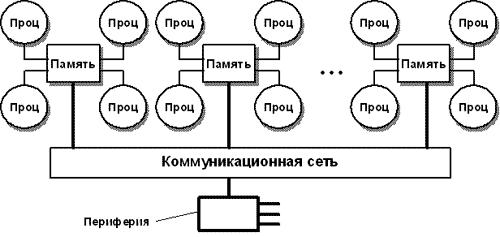
Рис. 3.4. Структурная схема вычислительной системы с комбинированной организацией памяти [9]
При подобной организации доступа к памяти очень важно, чтобы все процессоры получали одинаковые значение одних и тех же переменных в любой момент времени. Эта проблема называется когерентность кэш-памяти. Она появляется как следствие использования разделяемой памяти. Т. к. кэш-память принадлежит конкретному процессору, то она недоступна для остальных процессоров (даже для тех, которые находятся в его модуле). Именно поэтому необходимо проводить синхронизацию памяти. Применение нашли два варианта.
Отслеживать шинные запросы (Snoopy Bus Protocol). Кэши отслеживают переменные, которые передаются к любому из процессоров и, при необходимости, делают себе копии этих переменных;
Или выделить специальную область в памяти, в которой будет проверятся достоверность всех копий используемых переменных.
4.4. Мультипроцессорные и мультикомпьютерные системы
Мультипроцессорные и мультикомпьютерные системы представляют собой комбинации систем, которые рассматривались ранее. В этом пункте приведены современные разработки в этой области. Называть их суперЭВМ наверное нельзя, но от этого они не теряют своих возможностей в производительности. Вполне возможно, что скоро они будут такими же обыкновенными и легко доступными, как это произошло с двуядерными системами.
4.5. Кластеры ПЭВМ и рабочих станций
Под кластером будем понимать два и более компьютеров, которые объединены коммуникационной сетью. Объединение возможно на основе шинной архитектуры или на основе коммутатора. Несколько машин представляются пользователю как единое техническое решение. Узлами кластера (под узлом понимают один из компьютеров) могут выступать любые ЭВМ, вплоть до обычных. Использование кластера позволяет защитить систему от сбоев. Так, например, если из строя выходит один из узлов, то решение его задачи возьмет на себя другой узел. Корректно организованный кластер можно легко масштабировать. Кластер является наиболее дешевой вычислительной единицей, особенно, если он построен на стандартных комплектующих (процессоры, коммутаторы, диски и т. п.). Кластеры можно организовать на различных уровнях компьютерной системы, включая аппаратную часть, операционные системы, системы управления и прочие приложения. Чем больше уровней системы будет объединено в кластерную систему, тем надежнее будет система, тем легче будет ее масштабировать, тем легче будет управлять ею.
Условно разделить кластеры можно на два класса. Это деление было предложено Язеком Радаевским и Дугласом Эдлайном.
К первому классу относятся кластеры, полностью построенные из стандартных деталей. Такие детали легкодоступны, просты в обслуживании, взаимозаменяемы и, что самое главное, стоят не так дорого как уникальные комплектующие.
Во второй класс попадают системы, при создании которых были использованы эксклюзивные, нераспространенные детали. Производительность таких кластеров заметно выше систем из первого класса, но далеко не у всех есть возможность приобрести комплектующие (зачастую, чем реже встречается деталь, тем выше ее стоимость).
Ввиду того, что кластер сравнительно легко собирается, различных конфигураций может быть очень много. Есть ряд задач, под которые наиболее часто собирают кластеры:
Системы высокой надежности;
Высокопроизводительные системы;
Многопоточные системы.
Естественно, такое деление весьма условно. Если решать неимоверно сложную параллельную задачу, то не обойтись без высокопроизводительного кластера. И конечно же, никто не хочет чтоб система умерла за два шага до получения конечного ответа, поэтому вопрос надежности встанет особенно остро. Точно так же обстоит дело с многопоточными кластерами. Вот и получается, что кластерные системы могут относиться к этим типам лишь в большей или меньшей степени. Потому что при создании в каждой кластерной системе будут устройства, относящиеся ко всем функциональным типам.
Для параллельных вычислений (как было сказано выше) используют высокопроизводительные системы. Такие кластеры собирают из большого числа компьютеров. Создание подобного кластера очень сложный процесс. На каждом следующем шаге необходимо не только подключить очередной узел, но использовать и управлять всеми, подключенными ранее. Проще всего это делать, когда на всех узлах одна операционная система (это позволяет избегать конфликтов между разными операционными системами). Реализовать такую схему можно только для сравнительно небольших систем.
Применение многопоточной архитектуры рационально в том случае, когда необходимо обеспечить одинаковый доступ к ресурсам. Такие системы можно произвольно наращивать.
Впервые, как это бывает со всеми компьютерными технологиями, создать кластер попробовали на оборонном объекте в США. В 1994 году был создан 16-ти узловой кластер. На его основе сейчас строятся практически все кластеры. Значительно сократить расходы на этот кластер позволило то, что под него практически не разрабатывалось программное обеспечение. А большинство использованных программ были из разряда free ware (свободное распространение). Практика бесплатного программного обеспечения с успехом применяется до сих пор.
Слабым звеном в кластере может стать его архитектура (способ соединения процессоров друг с другом). Существенным является такой параметр, как расстояние между процессорами. Именно из-за влияния этого показателя при увеличении числа процессоров в N раз, производительность в N раз не возрастет (при условии, что система идеальна). Предположим, что у нас есть 16 равноправных процессоров. Первое, что приходит на ум после линейного соединение (одномерное), это соединить их в решетку (двумерное) чтобы получить схему на рис. 3.5.
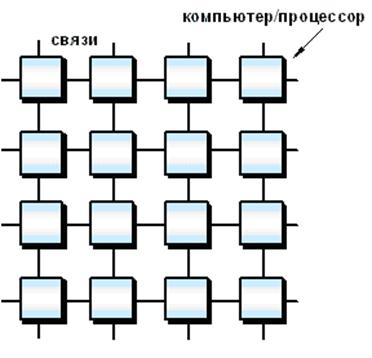
Рис. 3.5. Топология связи, сетка 4х4 [9]
Максимальное расстояние между процессорами равно 6 (количество связей между процессорами, разделяющих самые удаленные процессоры). Как правило, при расстоянии большим 4 система не может функционировать оптимально. Таким образом, двумерная схема тоже не эффективна. Что же остается? Нужна фигура, которая имеет максимальный объем при минимальной площади поверхности. Таковым является шар, но построить узловую структуру в форме шара затруднительно. Приходится строить систему в виде куба, а точнее гиперкуба (при числе процессоров больше 8). Размерность гиперкуба определяется числом процессоров, входящих в кластер. В нашем случае, при использовании 16 процессоров, используется 4-х мерный куб. Получить его можно из обычного куба путем его смещения еще в одном направлении, затем соединить вершины (рис. 3.6, 3.7).
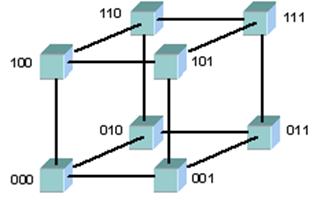
Рис. 3.6. Топология 3-х мерный куб [9]
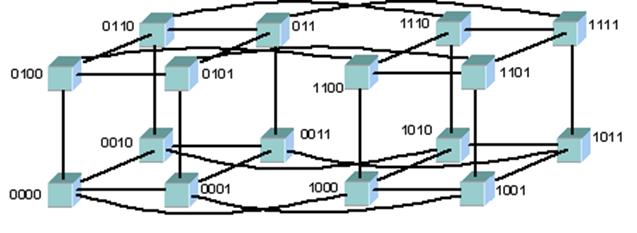
Рис. 3.7. Топология 4-хмерный куб [9]
Гиперкубы (являются второй по эффективности архитектурой, однако ее проще всего представить. Помимо гиперкубов можно встретить трехмерный тор, «кольцо», «звезда» (рис. 3.8) и т. д.
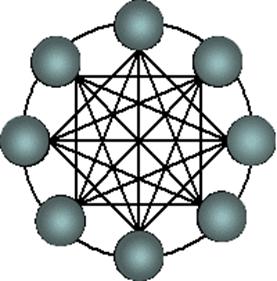
Рис. 3.8. Архитектура кольца с полной связью по хордам (Chordal ring) [9]
Одной из самых эффективных является архитектура «толстого дерева» (Fat Tree, рис. 3.9-3.10). Ее предложил Лейзерсон в 1985 году. Внутренние узлы скомпонованы в сеть, а процессоры локализованы в деревьях. Общение поддеревьев между собой происходит без обращения к более высоким уровням сети.
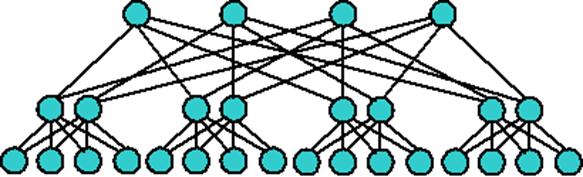
Рис. 3.9. Архитектура Fat Tree [9]
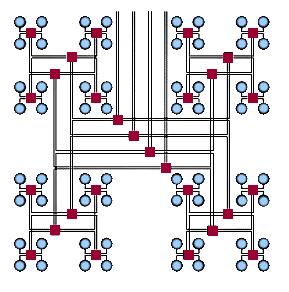
Рис. 3.10 Архитектура Fat Tree (вид сверху) [9]
Так как архитектура, в которую соединен кластер, оказывает большее влияние на производительность, чем тип процессоров, то возможно наиболее дешевым вариантом будет создание кластера из большего числа дешевых компьютеров, а не из меньшего числа дорогих. Поддерживать работу кластера можно при помощи бесплатного программного обеспечения, найти которое сейчас не составляет большого труда. Создание такой системы обходится не так уж дорого, но в таких системах велики накладные расходы на взаимодействие параллельных процессов между собой. Последний фактор значительно уменьшает количество потенциально решаемых задач.
4.6. Особенности параллельного программирования
При написании программы под параллельную обработку возникает ряд проблем, которые, мягко говоря, неочевидны. Далее описаны возможные варианты уменьшения такого рода ошибок.
Итак, ваша программа работает в обычном режиме, вдруг она вылетает с ошибкой, что произошло несвоевременное обращение к оперативной памяти по какому-то невоспроизводимому адресу. А в чем же собственно проблема? Для этого представим, что наша программа обрабатывает много разных величин, по большому количеству формул, но, мало того, обрабатываемые величины связаны между собой. При классическом подходе к параллельному программированию всю программу разложить на несколько процессоров мы должны вручную. Очень показателен рис. 3.11.
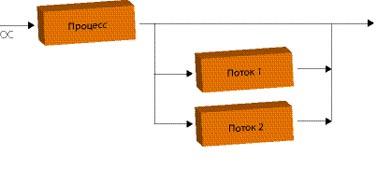
Рис.3.11. Распараллеливание одного процесса на несколько потоков [10]
На рисунке все это выглядит очень просто. На самом деле материнский поток при помощи различных вызовов должен сформировать несколько новых потоков (например, в Unix-системах после порождения новых потоков основной процесс приостанавливается ОС, а в ОС возникает два объекта – новый поток, запущенный по команде материнского, и последующий, продолжающий работу главного, но не являющийся собственно процессом). Вместо
…
Выполнить Действие1();
Выполнить Действие2();
…
Мы получим:
…
Запустить Поток (Действие1);
Запустить Поток (Действие2);
…
Т. е. обсчет объектов происходит одновременно. На самом деле, чаще встречается конструкция Запустить Поток (действие для Объекта1); Запустить Поток (действие для Объекта2), т. к. проделывается много однотипных операций над несколькими объектами.
Но такая организация может свести на нет все преимущества параллельного кода. Это связано с тем, что запуск нового потока и переключение между потоками (если процессоры не могут обработать все потоки одновременно) очень дорогие операции. Тогда пользуются следующим решением. Запускают необходимые (именно необходимые, тщательно подобранные по количеству, чтобы не было лишних переключений) потоки заранее, а после, главный поток в указанных местах передает текущее задание этим потокам. В результате получаем код вида:
…
Запустить Поток(Поток1);
Запустить Поток(Поток2);
…
Отправить на Обработку Потоку(Поток1, Действие над Объектом1);
Отправить на Обработку Потоку(Поток2, Действие над Объектом2);
…
В такой ситуации уже на этапе разработки нужно оперировать очень громоздкими и сложными конструкциями. Во-первых, их очень сложно написать. Во-вторых, их еще сложнее отладить.
На помощь может прийти такой компилятор как OpenMP. Это достаточно универсальное средство. OpenMP не привязывается к особенностям ОС. В случае непонимания другими компиляторами его можно просто игнорировать. Недостатком является очень жесткая модель программирования. В основе OpenMP лежит идея использования специальных компиляторов, ориентированных на параллельное программирование. В коде программы вставляются специальные метки, которые указывают какую часть кода выполнять последовательно, а какую параллельно. В итоге код программы приобретает следующий вид (рис. 3.12):
…
#Выполнить Код Параллельно
Действие1;
…
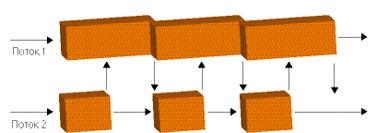
Рис.3.12. Пример работы программы [10]
Но OpenMP не поможет при таких проблемах, как, например, балансировка загрузки потоков. Вполне возможны ситуации, когда два из трех потоков справятся со своей задачей гораздо раньше, чем третий, и будут простаивать, ожидая его результаты. Вот и получается, что если 80% кода можно распараллелить, а 20% - нет. То получить прирост в производительности при подключении второго ядра более чем в 40% не получится. И это только процессор, а если взять такие ресурсы как оперативная память, которые вообще разделить нельзя, то ускорить программу относительно одноядерного процессора на двуядерном в два раза вряд ли удастся.
Возвращаясь от аппаратной части к программной, обратим внимание еще на один момент. Допустим, у нас есть одна величина, которую используют два потока. Первый поток изменяет ее, но в этот же момент в другом потоке она тоже должна быть изменена. Что же получим на выходе? Все зависит от того, какой из потоков запишет в память последним «верное» значение. А представим себе, что один из потоков удалил нашу злосчастную величину, сократив на нее что-нибудь другое (или сделав любую другую операцию, приводящую к стиранию объекта из памяти). Как в такой ситуации должен вести себя другой поток, который объект обсчитал и хочет внести изменения, а вносить некуда, объект удален. Конечно же, громко заявить об ошибке, попутно убив всю программу.
Разрешить такого рода недоразумения помогают объекты синхронизации. Они позволяют временно заблокировать изменение одного из объектов, которые могут быть использованы двумя потоками одновременно (рис. 3.13). Т. е. отдаем объект в пользование одному из потоков, а всех остальных претендентов на него ставим в очередь. Если этого не сделать, то, как было сказано ранее, программа может обрушиться. Причем обрушиться она может не в момент конфликта, а через некоторое время, когда «неудачный» код уже не отловить. Причем смерть программы может быть каждый раз в другом месте и в другое время.
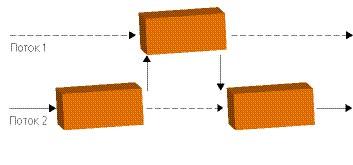
Рис. 3.13. Взаимодействие потоков [10]
Как мы выяснили в предыдущем абзаце, мало объектов синхронизации – программа сломается. Но кто бы мог подумать, что большое количество объектов синхронизации тоже приведет к краху нашей бедной программы? А связано это вот с чем. Пусть у нас есть какой-нибудь объект, который хотят заполучить все потоки. Т. к. всем потокам сразу принадлежать объект не может, то он отдается одному из них. Остальные терпеливо выстраиваются в очередь. И что же тогда останется от параллельности в таком коде? Тогда мы выдаем блокировку только на время, в течение которого будет происходить расчет. Вот мы и подошли к очередной проблеме. Нам необходимо изменить состояние двух объектов. Нам удалось просчитать как оно изменится, нам даже удалось изменить первый объект. Но при подходе ко второму объекту программа зависла. Почему? Потому что второй объект заблокирован, потому что он должен внести изменения в первый объект. Блокировку на себя он не отдаст, пока не изменит тот самый первый объект, обрабатываемый основным кодом. Вот так и будет стоять программа, потому что заблокированы все необходимые объекты. Или вот подобная ситуация. Первый поток заблокировал объект, обработал, и забыл снять блокировку. После этого другому потоку понадобилось проверить состояние объекта, он натыкается на блокировку и отказывается работать дальше. Поэтому важно помнить, что никогда не стоит пытаться обладать двумя объектами одновременно. А также, очень важно всегда проверять, что все однажды взятые объекты своевременно разблокированы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
