

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сегментная и сегментно-страничная организация памяти. Основное отличие сегмента от страницы в том, что сегмент имеет переменный размер. Сегмент имеет двумерный адрес, но теперь он двумерный и для ОС, и для программистов. В адрес входят два поля – номер сегмента, смещение внутри сегмента. Логическое адресное пространство представлено в виде набора сегментов. У каждого сегмента есть такие атрибуты как имя, размер, уровень привилегий, флаги присутствия и т. д.
Каждый сегмент – это линейная последовательность адресов, начинающихся с 0. Размер сегмента ограничен разрядностью процессора. Как правило, в таблице сегментов, кроме физического адреса начала сегмента содержится и его длина. Если сегменты поддерживаются аппаратно, то процессор может уже на этом уровне разрешать/запрещать доступ к памяти. Это значительно упрощает реализацию системы защиты информации. Аппаратная поддержка развита очень слабо.
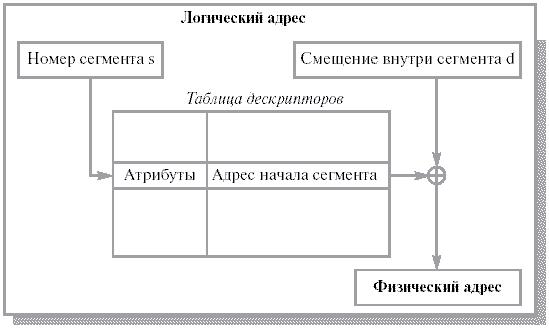
Рис. 1.9. Преобразование логического адреса при сегментной организации памяти [2]
Хранение больших сегментов в памяти весьма затруднительно. Решением такой задачи стала сегментно-страничная организация памяти. При такой реализации памяти осуществляется двухуровневая трансляция виртуального адреса в физический. Теперь логический адрес состоит из трех полей: номер сегмента логической памяти, номер страницы внутри сегмента, смещение внутри страницы. Для отображений необходимо уже две таблицы. Одна таблица сегментов для связи номера сегмента с таблицей страниц, другая – таблица страниц (отдельная для каждого сегмента).
При сегментно-страничной организации памяти можно организовать совместное использование данных и программного кода различными задачами. Для этого достаточно отобразить различные логические блоки памяти разных процессов в один блок физической памяти, где хранится разделяемая часть кода (данных).
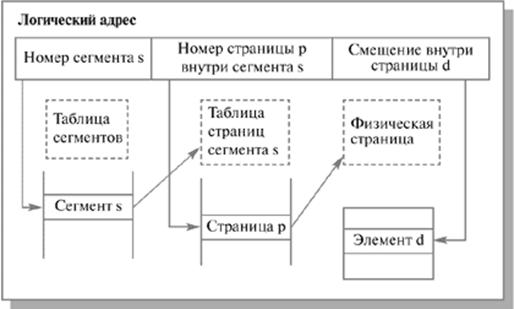
Рис. 1.10 Схема формирования физического адреса при сегментно-страничной организации памяти [2]
2.4. Выполнение команд
При написании программы используют язык программирования высокого уровня или Assembler. Написанную программу с помощью транслятора переводят в машинный язык. Как было сказано ранее, программа – это последовательность машинных команд. Команда состоит из кода команды и операндов (обрабатываемых данных). Некоторые команды могут и не содержать операндов (например, команды начала или конца модуля программы). В качестве операндов могут выступать адреса в оперативной памяти, имена регистров, непосредственно данные и т. д. При запуске программы системный загрузчик отправляет программу (или исполняемый модуль). Далее процессор выполняет ее.
2.5. Требования к коммуникационным линиям
Представить себе ЭВМ, не имеющую возможности подключения к коммуникационным линиям очень сложно. Поэтому требования к этим самым линиям очень высоки. Даже если мы объединим несколько вычислительных систем, не предоставляя им возможности выхода в глобальную сеть, мы должны настроить сеть таким образом, чтобы она обеспечивала:
Высокую скорость передачи. При передаче большого объема данных между сверхбыстрыми ЭВМ медленное соединение неизбежно станет узким местом.
Отсутствие потерь. При передаче большого объема данных (а при создании вычислительных комплексов это неизбежно) вероятны потери данных. Т. е. вы передаете число 2 (0010 – в двоичной системе счисления), теряется один бит, и при получении у нас число 001, а это уже 1 (в десятичной системе счисления). Естественно существуют контрольные суммы и тому подобные проверки. Но для ускорения работы, лучше свести потери к минимуму.
Помехозащищенность. Случай аналогичный предыдущему, но тут вместо потери одного бита можно принять неправильный бит (или того хуже, принять лишний – если большой уровень шума). 0=> 0
Надежность. Под надежностью можно понимать как надежность всей системы (случайный сбой не должен приводить к последствиям, устранять которые будут несколько дней), так и надежность каждого компонента системы (вплоть до сетевой карты отдельно взятой ЭВМ).
Масштабируемость. Если вы захотите подключить к выполнению задачи еще одну вычислительную машину, то переделывать из-за этого всю архитектуру комплекса – непозволительная роскошь.
Легкий доступ ко всем ЭВМ. В любой момент можно подключиться к любой считающей машине. Любая машина может получить данные с любой другой.
2.6. Устройства ввода-вывода
При упоминании устройств ввода-вывода на ум сразу приходят клавиатура, мышь и монитор. Это те основные средства, с помощью которых происходит взаимодействие с ЭВМ. Конечно, список этих устройств можно расширить принтером, сканером – это, то чем пользовался практически каждый. Можно к этим же устройствам отнести и более экзотические средства, такие как плоттер, манипулятор, трэк-болл и прочие. Но служат они для одних и тех же целей. По большому счету, для вычислительных систем необходимы только монитор и клавиатура (если ЭВМ работает под управление ОС семейства Linux, то можно обойтись и без мыши). Каких-то особых требований к устройствам ввода-вывода не предъявляют, чаще всего их выбирают по цене или каким-то внешним параметрам.
3. Методы повышения производительности традиционных ЭВМ
В Кембридже в 1949 году компьютер EDSAC мог выполнить 100 арифметических операций в секунду. Время такта составляло 2 микросекунды. У одного из узлов современной суперЭВМ Hewlett-Packard V2600 время одного такта составляет 1,8 наносекунды. При этом пиковая производительность примерно 77 миллиардов арифметических операций. Получается, что при выигрыше в быстродействии в 1000 раз, увеличение производительности составило 700 000 000 раз. За счет чего? Ответ прост – за счет использования новых архитектур. Основной является параллельная обработка данных.
Но все не так просто. А какой тип процессоров выбрать, какую память надо взять? И это далеко не полный список вопросов. Чтобы разобраться во всем многообразии возможных решений рассмотрим возможные методы такого ускорения.
3.1. Распараллеливание расчетов
Самое простое предположение, что Р процессоров выполнят задачу в Р раз быстрее, чем один, срабатывает только в идеальном случае. Обычно, дела обстоят не так уж хорошо, что иллюстрирует закон Амдала:
![]() , (2.1)
, (2.1)
где S – ускорение работы программы на P процессорах; f – доля непараллельного кода в программе.
Эту формулу можно применять как для моделей с общей памятью, так и для модели передачи сообщений. Но для разных моделей понятие величина f представляет разные показатели. Для модели общей памяти эту долю образуют операторы, которые выполняются только в главной нити программы. В модели передачи сообщений непараллельная часть – это часть операторов, которые дублируются всеми процессорами. Напрямую, просто взглянув на код программы, оценить величину f практически невозможно. Это позволяет сделать только просчет на различном числе процессоров. Для наглядности можно привести следующую таблицу:
Таблица 2.1.
Ускорение работы программы в зависимости от
доли непараллельного кода [3]
Число процессоров | Доля последовательных вычислений % | ||||
50 | 25 | 10 | 5 | 2 | |
Ускорение работы программы | |||||
4 | 1.60 | 2.28 | 3.07 | 3.48 | 3.77 |
8 | 1.78 | 2.91 | 4.71 | 5.93 | 7.02 |
16 | 1.88 | 3.36 | 6.40 | 9.14 | 12.31 |
32 | 1.94 | 3.66 | 7.80 | 12.55 | 19.75 |
512 | 1.99 | 3.97 | 9.83 | 19.28 | 45.63 |
Как видно из таблицы, если доля последовательного кода составляет 2%, то более чем в 50 раз ускорить процесс нельзя. Но, чтобы получить такое ускорение, запускать программу на 1024 (и более) процессорах ни к чему. Приемлемым может оказаться выполнение задачи и на 32 процессорах. Закон Амдала всего лишь устанавливает максимальное число процессоров, на которых будет выполняться программа с заданной эффективностью, при указанной доле непараллельного кода. Причем, в этой формуле не учитываются потери производительности при обмене информацией между процессорами. Поэтому, в реальности ситуация будет еще хуже.
Не стоит думать, что распараллеливание – единственный метод увеличения скорости работы программы. Достаточно всего лишь оптимизировать код, и даже на однопроцессорной ЭВМ можно добиться существенного ускорения.
3.2. Конвейерная обработка данных и команд
Предположим, что мы хотим сложить два числа, представленных в форме с плавающей запятой. Для этого нам потребуется выполнить операции сравнения порядков, выравнивания порядков, сложения мантисс и т. д. Первые ЭВМ выполняли все эти операции для каждой пары аргументов, одна за другой, пока не получали конечное число. Затем, следующая пара слагаемых.
А что, если выделить отдельные этапы общей операции? Каждый этап, закончив свою работу, передает свой результат следующему, одновременно получая новую порцию данных на входе. Получаем выигрыш в скорости, за счет совмещения ранее разнесенных по времени операций. Если в исходной большой операции можно выделить 5 подопераций, каждая из которых длится единицу времени, то на неделимом последовательном устройстве 100 пар аргументов обработается за 500 единиц времени. Если каждую подоперацию выделим в отдельную часть конвейерного устройства, то на 5-м шаге у нас будут первые 5 пар аргументов в разной стадии обработки. Таким образом, весь набор мы обработаем за 5+99=104 единицы времени – практически пятикратное ускорение (очевидно, что оно зависит от числа ступеней конвейера).
Простым выходом было бы заменить весь конвейер обычным параллелизмом. Т. е. взять 5 устройств и обработать на них 100 пар аргументов. Но, в таком случае мы увеличим объем аппаратуры, соответственно, и ее стоимость.
Обработку команды разделяют на такие этапы:
выборка команды;
дешифровка команды;
выборка операндов;
выполнение команды;
сохранение результатов.
Нетрудно заметить, что каждый из этапов выполняется один раз и строго по завершению предыдущего этапа. А раз так, то, после передачи результатов на следующий этап, можно переходить к новым, пришедшим с предыдущего. Если каждую из операций выделить в отдельную часть устройства и расположить в порядке выполнения, то получим конвейер. Каждая часть общего устройства называется ступенью конвейера, а общее количество ступеней – его длинной.
Наряду с конвейером команд можно выделить конвейер данных. Вместе они позволяют достичь очень высокой производительности для счетных задач. Максимально используются возможности такой обработки в высокопроизводительных вычислительных конвейерных системах фирмы CRAY. В этих машинах установлен конвейер арифметических и логических операций и конвейер команд. Также применяется обработка информации несколькими устройствами. Пиковая производительность может составлять 12 GFLOPS.
Сейчас созданы однокристальные векторно-конвейерные процессоры. Их основой является скалярный процессор и 8 одинаковых векторных устройств. Суммарная производительность составляет 64 GFLOPS. На основе таких устройств работает система SX-6 (NEC).
3.3. Высокопроизводительные процессоры
Одним из основных элементов ЭВМ, определяющих ее производительность является процессор. Рассмотрим особенности устройства различных процессоров, позволяющие реализовать высокую производительность.
3.3.1. Суперскалярные процессоры
В процессорах этого типа реализованы как параллельное выполнение команд, так и конвейерная обработка. Если на обычном конвейере параллельная обработка возможна в случае, когда команды находятся на разных стадиях обработки, то суперскалярные процессоры позволяют обрабатывать несколько команд в одном сегменте конвейера. В этом случае. несколько команд могут выполниться одновременно в течение одного такта.
Такая работа стала возможна благодаря использованию нескольких, параллельно работающих конвейеров, а также устройств, позволяющих определить независимость команд. Устройства интерпретации команд (определяющие зависит ли команда от других) снабжены собственной логикой.
Чаще всего в суперскалярных процессорах увеличивают количество целочисленных конвейеров. Это связано с тем, что 80% команд в коде прикладных программ – целочисленные, около 15% - команды условного перехода и очень малый процент – команды с плавающей запятой.
Учитывая, что работают несколько конвейеров, мы получим те же конфликты, которые можно получить при работе с одним. Для их решение применяют алгоритмы внеочередной выборки и завершения команд, условного выполнения команд, прогнозирования переходов.
В суперскалярных процессорах распараллеливание команд заложено на аппаратном уровне. Программы для такого типа процессоров должны быть совместимы на уровне исполняемых файлов.
Параллельные программы можно разделить на статические, динамические и смешанные. По сложившемуся мнению, статические способы реализации программ являются предпочтительными. Это связано с тем, что при анализе кода на стадии компиляции удается выделить и спланировать параллелизм на более глубоком уровне. Однако, если необходимо учитывать текущее состояние программы и распределения ресурсов, то без динамической реализации обойтись нельзя.
Особенности суперскалярных процессоров, кроме своих плюсов, имеют очевидные минусы:
сложная реализация аппаратной части;
ограниченность окна выполнения. Это заметно уменьшает возможности определения потенциально параллельных программ.
Среди представителей суперскалярных процессоров выделяют Pentium, PowerPC, K6/K7, Alpha. В качестве особенностей одного из суперскалярных процессоров фирмы CRAY можно отметить то, что он имеет 136 (!) процессоров. Среди них четыре процессора Dec-Alpha EV5 (300 Mhz) с локальной памятью и чипом маршрутизации. Процессоры Alpha – суперскалярные процессоры, позволяющие обрабатывать два числа с плавающей запятой за цикл работы конвейера.
3.3.2. Процессоры RISC с сокращенным набором команд
Идеей создания процессора RISC (Reduced Instruction Set Computer – компьютер с сокращенным набором команд) появившейся в 70-е годы ХХ века было то, что он «воспринимал» минимальный набор команд. Создание таких процессоров было следствием известного правила «80/20»: 80% кода типовой программы использует 20% простейших машинных команд ( ряд сложных команд быстрее выполняются, если разбить их на много простых). К отличительным особенностям RISC-процессоров относят:
Сокращенный набор команд (обычно не более 100).
Фиксированная длина машинных инструкций.
Простой формат команды.
Простая адресация.
Выполнение большинства команд происходит за один такт.
Команды выполняют только простые действия.
Операндами могут быть только регистры.
Большое количество регистров общего назначения.
Несколько жестких многоступенчатых конвейеров.
Большая по объему раздельная кэш-память.
Наличие оптимизирующих компиляторов (они имеют возможность анализировать исходный код и менять последовательность команд).
Для третьего поколения этих процессоров характерно следующее:
Процессор является 64-х разрядным, суперскалярным.
Наличие встроенных конвейерных блоков арифметики с плавающей запятой.
Наличие многоуровневой кэш-памяти.
Реализовывать внеочередное выполнение команд позволяют алгоритмы прогнозирования ветвления, а также переназначение регистров.
Увеличение быстродействия достигается повышением тактовой частоты и усложнением схемы кристалла. В первом направлении работает фирма DEC (процессоры Alpha). Структура процессора Alpha 21064 представлена на рис. 2.1.
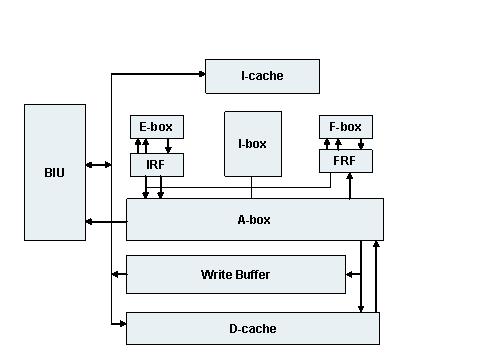
Рис. 2.1 Структурная схема процессора Alpha 21064 [4]
Функциональные блоки процессора Alpha 21064 [1]:
I-cache - кэш команд.
IRF - регистровый файл целочисленной арифметики.
F-box - устройство арифметики с плавающей точкой.
E-box - устройство целочисленной арифметики (7 ступеней конвейера).
I-box - командное устройство (управляет кэш команд, выборкой и дешифрацией команд).
A-box - устройство управления загрузкой/сохранением данных. Управляет процессом обмена данными м/у IRF, FRF, кэш данных и внешней памятью.
Write Buffer - буфер обратной записи.
D-cache - КЭШ данных.
BIU - интерфейсный блок, с помощью которого подключаются внешняя кэшпамять, размером 128 Кб-8 Мб.
Одной из последних разработок, сделанных на базе этого процессора, является процессор Alpha 21264. Он может читать до четырех инструкций за одни такт, а исполнять – до шести инструкций. Есть возможность выполнять команды с изменением очередности (Out-of-Order). Эффективность этого алгоритма зависит от количества инструкций, которые может обрабатывать процессор для поиска оптимального порядка следования команд. Для сравнения, процессоры фирмы Intel (Pentium Pro, Xeon) способны одновременно работать с 40 командами, Hewlett-Packard (PA-8000) – 56 команд, Alpha – 80!
Для большей эффективности внеочередной обработки команд, в процессоры Alpha добавлены еще 48 целочисленных регистров и 40 регистров для данных с плавающей запятой. При обработке инструкции не нужно перегружать результат в целевой регистр, вместо этого происходит переименование временного регистра (Register Renaming). Точно также работают и остальные процессоры, но в процессорах Alpha есть существенная особенность, каждый их 80 целочисленных регистров продублирован. Это позволяет существенно повысить частоту процессора.
Ряд технических решений представлен и в процессорах PA-8000. Их отличительной особенностью является большой набор средств для внеочередного выполнения команд. Они позволяют аппаратно планировать загрузку ковейеров. В состав процессора от Hewlett-Packard входят:
Два АЛУ для целочисленных операций.
Два устройства для выполнения операций сдвига.
Два устройства для сложения чисел с плавающей запятой.
Два устройства деления.
Два устройства для выполнения операций записи/загрузки.
Современные RISC-процессоры чаще всего применяют в качестве рабочих станций высшего класса, персональных рабочих станций, серверов.
Как следует из вышесказанного RISC-процессоры это не «надархитектурное « свойство, а просто способ выполнения.
3.3.3. Процессоры со сверхдлинным командным словом
Суперскалярные процессоры со сверхдлинным командным словом-
VLIW (Very Long Instruction Word) в процессе работы выявляют параллелизм команд во время трансляции. Транслятор, анализируя программу, выделяет операции, которые можно выполнять параллельно, и строит из них «большие» команды. Как только «большая» команда поступает на выполнение, обычные команды из нее выполняются параллельно. Такая реализация ведет к ряду недостатков (нет совместимости на уровне бинарных файлов, необходим канал с большой разрядностью, увеличивается исполняемый код).
Архитектура VLIW – одна из реализаций внутреннего параллелизма в микропроцессорах. Быстродействие можно повышать за счет увеличения тактовой частоты или за счет количества операций, выполняемых за один такт. Первый способ можно реализовать при использовании «быстрых» технологий (использовать вместо кремния арсенид галлия) и глубокой конвейеризации (задействовать все логические элементы кристалла). Чтобы реализовать второй способ, необходимо разместить на одном чипе несколько функциональных модулей и обеспечить надежность при параллельном исполнении инструкций.
Говоря о надежности, имеется ввиду правильность результата. Если необходимо выполнить следующие действия А=В+С, В=Е+Н. Очевидно что результат первого выражения зависит от результата второго. При планировании порядка вычислений необходимо учитывать такие нюансы. Если не будет подобного контроля, то получить верный результат вычисления можно лишь с какой-то вероятностью.
VLIW-архитектура передает планирование программному обеспечению. Т. е. на этапе компиляции происходит поиск независимых инструкций, составление из них длинных инструкций, которые затем обрабатываются одновременно. Если компилятору попадаются связанные данные, то ему необходимо найти возможность развязать их. Это можно сделать с помощью переупорядочивания программы (перемещение программных модулей). Для большего распараллеливания программы VLIW-процессорам можно дать возможность просматривать операции из разных базовых блоков. В дальнейшем VLIW-процессоры можно дополнить небольшим аппаратным устройством, которое будет собирать статистические данные при циклической работе с переменными. Естественно, что глубоко просматривать программный код можно и на RISC-процессорах, но соотношение «эффективность/цена» намного выше у VLIW.
Примечание. Фирма Intel решила эту проблему на аппаратном уровне. Но размеры планировщика вычислений растут по мере увеличения количества функциональных модулей. На данном этапе развития техники, число обрабатываемых за цикл операций для суперскалярных машин составляет 5-6.
Описав VLIW-процессоры едва ли не идеальным решением для всех задач, ни разу не было сказано о недостатках таких систем. Первым является то, что эффективность практически полностью ложится на компилятор, а потому, он должен максимально соответствовать всем особенностям архитектуры процессора. Так например, при выпуске нового процессора с другим количеством обрабатывающих модулей (или с тем же количеством, но с другим быстродействием), нам придется заново компилировать все старое программное обеспечение заново. Конечно, можно как фирма Intel сразу ввести ограничения на то, что в системе будет использоваться трехкомандное слово. В таком случае программное обеспечение (для любой модификации этой системы) сначала пишется на промежуточном языке. А перевод в машинный код производится уже на ЭВМ заказчика. Но такой подход не всегда оправдывает себя, потому что, зачастую необходимо, объяснять компилятору что необходимо делать на этой конкретной машине (вполне возможно, что и в этой конкретной операционной системе). Нельзя забывать и о потерях в скорости относительно программного обеспечения, которое изначально писалось под такую платформу. Вторым явным недостатком является то, что оптимизация обеспечивается для статической программы. Предсказать поведение компилятора в непредвиденной ситуации (когда происходит ожидание действия человека) практически невозможно.
Предложение среди разработчиков программного обеспечения настолько велико, что большинство производителей отказываются от «чистого VLIW».
3.3.4. Векторные процессоры
Главной особенностью векторных процессоров является то, что они могут обрабатывать не одно значение, а сразу массив (вектор) значений. Т. е. за один цикл своей работы такой процессор, например, может попарно сложить элементы двух массивов одинаковой длины и размерности и присвоить это значение соответствующим элементам конечного массива. Такое возможно, т. к. каждый операнд хранится не в обычном, а в векторном регистре. В то время как векторный процессор выполняет одну команду, последовательный процессор будет выполнять несколько операций сложения элементов массивов.
За счет подобной реализации должна увеличиться производительность. Должна она увеличится и из-за того, что уменьшается поток команд, а значит в процессор будет поступать больше данных. Но весь прирост можно легко потерять. Это связано с тем, как передаются команды и операнды в процессор. Реализовать передачу можно двумя способами:
Из памяти в память;
Из регистра в регистр.
В первом способе данные из оперативной памяти загружаются в АЛУ, результат возвращается в оперативную память. При реализации второго способа, используют векторные регистры. Операнды загружаются в эти самые регистры, затем в АЛУ, результат также попадает в векторный регистр. Работа «из памяти в память» позволяет обрабатывать векторы произвольной длины (очень важно, чтобы скорость работы процессора была строго согласована со скоростью работы оперативной памяти). Но, существует время задержки между инициализацией команды и появлением первого результата (в компьютере CYBER 200 время запуска составляло 100 тактов, при этом терялась половина производительности). Применение такой схемы оправдано, если не нужно постоянно перезагружать конвейер.
Системы, работающие по схеме «из регистра в регистр» имеют намного меньшее время загрузки. Это позволяет получить хорошие показатели по быстродействию. Но в такой схеме существует ограничение на длину вектора. Если вектор длинный, то его приходится разбивать на части меньшей длины. Такая разбивка сказывается на быстродействии. Тем не менее, именно такая схема сейчас наиболее востребована. Наиболее известными представителями в этой области являются фирмы CRAY, NEC, Fujitsu, Hitachi.
3.3.5. Процессоры для параллельных компьютеров
Обычно выделяют несколько уровней параллелизма:
Параллелизм заданий;
Параллелизм на уровне программы;
Параллелизм команд;
Параллелизм на уровне машинных слов и арифметических операций.
Для первого уровня характерно то, что у каждого процессора имеется свое, независимое от других процессоров, задание.
На втором уровне распределяются уже не задания, а модули программы. Каждая часть программы может выполняться на отдельном процессоре.
Параллелизм команд реализуется на низком уровне (например, организация конвейера).
До последнего уровня доходят не так часто. Например, сложение двух операндов выполняется одновременным сложением всех их двоичных разрядов.
Первый и второй уровень сейчас реализован даже на обычных ЭВМ. Только для третьего и четвертого уровня необходимы новые элементы и особая архитектура процессоров, которые были описаны выше.
3.3.6. Процессоры с многопоточной архитектурой
MTA –Multi Threaded Architecture – многопоточная архитектура. Всерьез о создании такой системы задумалась фирма Terra. В качестве основных особенностей выделялись:
Высокая эффективность распараллеливания начиная с третьего уровня (см. п.2.3.5.).
Простота распараллеливания и переноса программ.
Применять подобные системы планировалось
в следующих областях [5]:
задачи моделирования;
автомобильная и аэрокосмическая промышленность;
сейсмический анализ (например, в нефтегазовой промышленности);
трехмерные задачи в системах САПР;
вычислительная химия (в том числе исследования белка, составление лекарств и др.);
задачи национальной безопасности (криптография);
предсказание погоды;
предоставление информации по запросу;
сложные задачи виртуальной реальности;
приложения сверхбольших данных.
Для решения своих задач нашли применение следующие архитектурные особенности. Однородная общая оперативная память. Нет иерархического построения памяти. Отказ от кэш-памяти данных. За счет этого удалось сократить накладные расходы при распараллеливании, т. к. необходимость сопоставления кэшей различных процессоров исчезла сама собой (эта идея была реализована ранее фирмой Hitachi).
Другое преимущество заключается в том, что переключение между задачами после выполнения команды происходит быстро, опять же, без накладных расходов. Это позволяет процессорам быть все время занятыми независимо от задержек оперативной памяти или задержек синхронизации. Для поддержания большой занятости процессоров емкость пула (хранилища) задач сделана больше, чем число доступных аппаратных потоков.
Поток может быть создан и удален без вмешательства операционной системы, с помощью обычных непривилегированных команд. Этим уменьшаются потери на управление потоками.
Зачастую, узким местом становится оперативная память. Однако, MTA допускает обращения к памяти в каждом такте, даже в задачах целочисленной сортировки (в таких задачах основное ограничение накладывает пропускная способность оперативной памяти).
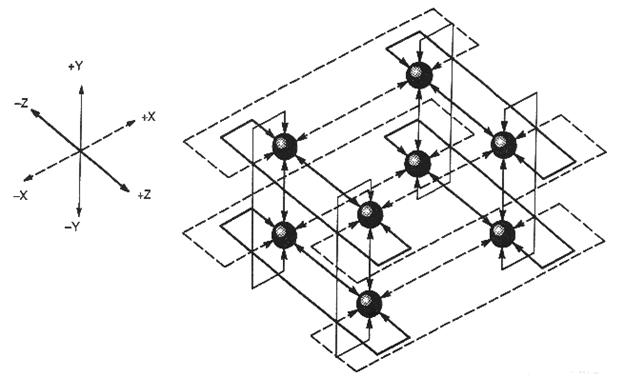
Сердцевиной MTA-компьютера является трехмерная сеть с коммутацией пакетов. Соединение тороидальное (см. рис. 2.2).
К каждому узлу присоединяют ресурсы (процессор и оперативную память). Задержка составляет 3 такта на узел. Максимальная задержка составляет 4,5*(р)1/2, где р – число процессоров. Число устройств памяти в два или в четыре раза больше числа процессоров. Обращения к оперативной памяти распределяются среди всех банков устройств памяти. Такое случайное обращение поддерживает одинаковые величины задержек при обращении к оперативной памяти.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
