

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Одной из проблем при отладке параллельного кода, является то, что один шаг процесса может сопровождаться десятками шагов другого процесса. Ситуации, возникающие в таких шагах зачастую уникальны. Они связаны со случайным совпадением в слабосвязанных между собой потоков. Такие проблемы могут больше никогда не появится в программе. И, как это бывает во всех измерениях, наличие наблюдателей (отладочных средств) вносит коррективы в результат, т. к. немного изменяет внешнюю среду.
Несмотря на все проблемы, связанные с параллельным программированием, отказаться от многоядерных процессоров не удастся. Тем более, что все производители процессоров заваливают нас недорогими продуктами. Скоро параллельное программирование станет таким же обычным, каким сейчас стало непараллельное.
5. Потоковые параллельные вычисления для физического моделирования
5.1. Общие принципы распараллеливания расчётов
Задачи вычислительного моделирования физических систем очень часто связаны с независимым применением одного и того же набора операций (одного и того же алгоритма обработки) к большому количеству объектов одинакового типа.
 Например, в молекулярной динамике на каждом временном шаге необходимо рассчитывать силы, действующие на каждую из частиц, а затем определять ускорения, скорости и перемещения частиц, соответствующие этим силам. Ещё более распространённый метод Монте-Карло предполагает независимую обработку большого количества однотипных случайных событий. Очевидно, что решение подобных задач можно очень существенно ускорить путём распараллеливания расчётов.
Например, в молекулярной динамике на каждом временном шаге необходимо рассчитывать силы, действующие на каждую из частиц, а затем определять ускорения, скорости и перемещения частиц, соответствующие этим силам. Ещё более распространённый метод Монте-Карло предполагает независимую обработку большого количества однотипных случайных событий. Очевидно, что решение подобных задач можно очень существенно ускорить путём распараллеливания расчётов.
Пусть есть некоторый набор однотипных данных (N элементов), которые требуется обработать в соответствии с заданным алгоритмом. Блок-схема последовательных вычислений, без какого-либо распараллеливания, будет иметь общий вид, показанный на рис. 4.1. Из этой блок-схемы видно, что возможны 3 типа распараллеливания расчётов [11]:
· Распараллеливание по данным. Если операции 1 - m (рис. 4.1) над каждым i-м элементом не зависят от исхода операций над остальными элементами, то эти элементы не обязательно обрабатывать последовательно. Расчёты можно распределить между несколькими вычислительными блоками (процессорами, конвейерами, машинами), как это показано на рис. 4.2. Именно такое распараллеливание характерно для физического моделирования.

Рис. 4.2. Распараллеливание по данным
· Распараллеливание по инструкциям. Может оказаться, что некоторые инструкции из набора операций 1 – m независимы друг от друга, и тогда, при наличии нескольких вычислительных блоков, эти инструкции могут быть исполнены параллельно. Схема распараллеливания по инструкциям показана на рис. 4.3. Такое распараллеливание аппаратно реализовано в современных центральных процессорах общего назначения, поскольку оно эффективно при исполнении программ, интенсивно обменивающихся разнородной информацией с другими программами и с пользователями ПК.
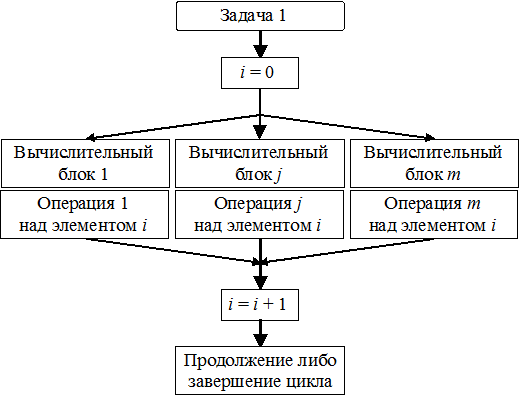
Рис. 4.3. Распараллеливание по инструкциям
· Распараллеливание по задачам. Возможно, если задачи 1 - k (рис. 4.1) независимы друг от друга. Особенно актуально для сетевых серверов и других вычислительных систем, выполняющих одновременно несколько функций либо обслуживающих многих пользователей.
5.2. Обмен данными между процессором и памятью
Моделирование физических систем обычно связано с обработкой больших массивов данных (например, как в молекулярной динамике, - с расчётом траекторий большого количества частиц). Эти данные хранятся в памяти, доступной процессору (оперативная память компьютера, видеопамять, кэш). Двумя основными характеристиками, определяющими эффективность взаимодействия процессора с памятью, являются латентность и пропускная способность.
· Латентность – это время доступа к памяти, т. е. время ожидания процессором данных после запроса. Латентностью определяется производительность вычислений при решении задач, требующих частого обращения к произвольным, неупорядоченным ячейкам памяти. Такой обмен с памятью характерен для «кибернетических» задач, связанных со сложным управлением потоком команд, обработкой уникальных входных сигналов. В числе этих задач интерактивные приложения, – приложения, управляемые пользователем в ходе исполнения, - которые обычны для персональных компьютеров. Современные интерактивные приложения обычно обмениваются с пользователем и другими приложениями большим количеством разнородной информации.
· Недостаточная латентность памяти ограничивает возможности процессоров, работающих на высокой частоте, поскольку они не успевают получать данные для обработки.
· Пропускная способность (ПС) характеризует объём данных, которыми процессор может обменяться с памятью за единицу времени. Высокая пропускная способность оказывается важнее латентности в задачах, позволяющих организовать считывание данных из последовательных ячеек памяти непрерывным потоком.
· Высокую пропускную способность памяти можно эффективно использовать в задачах физического моделирования, которые связаны с применением сравнительно несложных алгоритмов обработки к большим массивам данных.
В последние годы пропускная способность памяти (ПС памяти) увеличивается существенно быстрее, чем уменьшается латентность. В табл. 4.1. приведены современные времена удвоения ПС памяти различных типов [12]. В последнем столбце табл. 4.1. даны величины уменьшения латентности памяти тех же типов за то же время (т. е. за время удвоения ПС). Видно, что во всех случаях латентность улучшалась гораздо менее чем в два раза, то есть – существенно медленнее, чем возрастала пропускная способность. Такая тенденция указывает на перспективность разработки алгоритмов физического моделирования, ориентированных скорее на потоковую обработку данных, эффективность которой определяется пропускной способностью памяти, чем на произвольный доступ к памяти. Эффективность потоковой обработки данных в большей мере определяется пропускной способностью памяти, чем латентностью, а эффективность произвольного доступа – наоборот.
Из табл. 4.1. видно, что пропускная способность кэша процессоров и оперативной памяти (которые задействованы при физическом моделировании на ПК) удваивается за 2-3 года. Можно ожидать, что и в ближайшем будущем эта тенденция сохранится.
Таблица 4.1.
Динамика улучшения пропускной способности и
латентности памяти [12]
Тип памяти | Время удвоения ПС, | Улучшение латентности за то же время, разы |
Кэш процессоров | 1.7 | 1.3 |
Оперативная память (DRAM) | 2.9 | 1.2 |
Доступ к данным по сетям | 2.1 | 1.3 |
Дисковая память | 2.8 | 1.3 |
5.3. Графические процессоры как вычислительные системы для поточно-параллельных расчётов
5.3.1. Вычислительные возможности центральных процессоров общего назначения и графических процессоров
Со времени своего появления в начале 1980-х годов персональные компьютеры (ПК) развивались в основном как машины для выполнения «кибернетических» программ - сложных по структуре, обрабатывающих большое количество условий, интенсивно взаимодействующих с пользователем (интерактивных), но обычно не связанных с потоковой обработкой большого количества данных. Центральные процессоры ПК (CPU) оптимизировались для решения именно таких задач, так что характеризовались:
· Большим количеством транзисторов для управления ветвлениями программы и сравнительно малым количеством транзисторов для вычислений;
· Архитектурой, оптимизированной для программ со сложным потоком управления (т. е., с обработкой разнородных команд и данных, максимальная интерактивность);
· Памятью, оптимизированной под минимальную латентность.
В начале своей истории ПК не были достаточно мощными для быстрой обработки больших массивов данных, так что CPU вообще не поддерживали поточно-параллельных вычислений. Затем эти процессоры стали суперскалярными – в них была реализована возможность одновременного применения некоторых математических операций к нескольким числам (расширения SSE, 3DNow!). Тем не менее, поддержка поточно-параллельных вычислений центральными процессорами ПК и сейчас сильно ограничена.
Вместе с тем, возможность проведения эффективных поточно-параллельных вычислений на ПК существует, она была реализована для обработки изображения и звука. Поскольку центральные процессоры ПК не оптимизированы для решения таких задач, стали развиваться звуковые карты и видеокарты, снабжённые собственными потоковыми процессорами и собственной памятью, оптимизированной под максимальную пропускную способность.
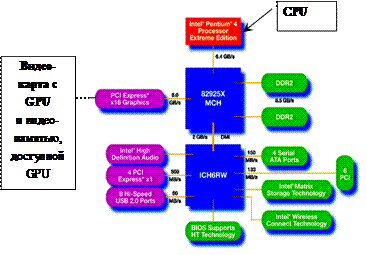
Рис. 4.4. Архитектура ПК с одним центральным процессором и видеокартой
На рис. 4.4 для иллюстрации показана архитектура персонального компьютера с одним центральным процессором и видеокартой с графическим процессором [13]. Видеокарта – это подсистема ПК, включающая в себя графический процессор (GPU) и специализированную оперативную память, с которой этот графический процессор может обмениваться данными. Эту специальную память называют видеопамятью. Центральный процессор также имеет доступ к видеопамяти, а кроме того – может загружать в GPU программы для исполнения и запустить исполнение этих программ. Схематичная модель взаимодействия центрального и графического процессоров с памятью (а посредством памяти – и между собой) показана на рис. 4.5.
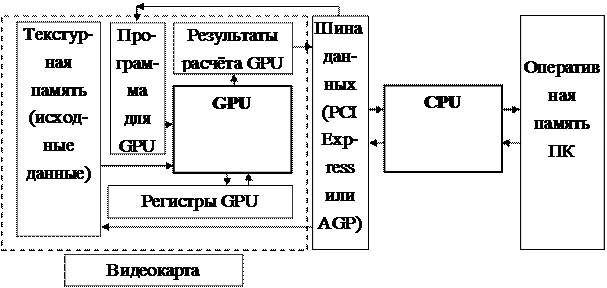
Рис. 4.5. Взаимодействие центрального и графического процессоров с памятью
Графические процессоры (GPU), используемые в видеокартах, ориентировались на следующие характеристики:
· Память оптимизирована под максимальную пропускную способность;
· Большая часть транзисторов – вычислители;
· Латентность скрывается вычислениями во время запросов к памяти (за счет потоковой обработки);
· Управляющие блоки разделяются между вычислителями (обработка ветвлений менее эффективна);
· Архитектура оптимизирована для программ с большим объемом вычислений (максимальная скорость вычислений).
Современные графические процессоры допускают достаточно сложное программирование (см., например, [13]), так что могут быть использованы не только для отображения графики, но и для других расчётов. Задачи, хорошо распараллеливаемые по данным, на них можно решать во много раз быстрее, чем на центральных процессорах ПК.
5.3.2. Графический конвейер
Первые графические процессоры были предназначены для решения только одной задачи – построения изображений (включая проекции 3-мерных сцен) на дисплее. При этом использовался графический конвейер (см., например, [14]), показанный на рис. 4.6.
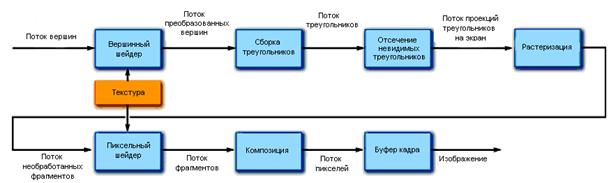

Рис. 4.6. Графический конвейер
Входными данными для графического конвейера являются:
· координаты вершин, задающих положение изображаемых плоскостей в трёхмерном пространстве;
· текстуры, представляющие собой массивы с данными о цветах этих плоскостей.
Графический конвейер осуществлял проектирование вершин треугольников, образующих поверхности в 3-мерном пространстве «за» плоскостью экрана на эту плоскость экрана, а затем – нанесение на эти треугольники необходимых цветов (текстур). Для проектирования вершин использовались линейные преобразования координат (т. е., матричные операции), а для нанесения необходимого рисунка на поверхности треугольников – различные алгоритмы наложения цветов видимых объектов и учёта освещённости.
Стандартные процедуры проектирования вершин и расчёта цветов на видеокартах автоматизированы, однако этих стандартных процедур недостаточно для реализации всех эффектов, используемых для отображения 3D-сцен. Поэтому появилась возможность произвольного программирования этапов проектирования вершин и закрашивания треугольников для получения уникальных эффектов. Процедуру, осуществляющую «пользовательские» действия на этапе проектирования вершин называют вершинным шейдером, а на этапе закрашивания треугольников (т. е. – определения цветов пикселей на экране) – пиксельным шейдером. Поскольку в эти процедуры может быть записан произвольный код (реализуемый операциями, доступными графическому процессору), они могут быть использованы не только для вывода графики, но и для других расчётов, на чём и основана возможность использования видеокарт при физико-математическом моделировании.
5.3.3. История программируемости графических процессоров
Первые графические процессоры для ПК, появившиеся в 1995 году (GPU 3DFX Voodoo), не были программируемыми, они только линейно отображали треугольники на плоскость экрана. Затем GPU стали использовать для трассировки лучей – расчета освещенности поверхностей, а также других графических эффектов, для чего и потребовалась программируемость графического конвейера. Следующая хронология (см., например, [15]) показывает, как постепенно увеличивались возможности программирования различных типов GPU для обработки трёхмерной графики и выполнения пользовательских алгоритмов.
· 1995 год, первые графические процессоры (S3 ViRGE, ATI Rage - ATI Radeon 7500, Matrox Mystique, 3dfx Voodoo)
Были разработаны как специализированные процессоры для ускорения операций с двух - и трёхмерной графикой, в частности – для отображения на плоскости экрана трёхмерных сцен. В качестве исходных данных принимали координаты вершин треугольников, образующих трёхмерные поверхности, цвета вершин, а также положение экрана и источников света относительно этой 3D-сцены. Такие GPU автоматически выполняли
· проектирование треугольников на плоскость экрана,
· интерполяционную закраску изображений этих треугольников по цветам вершин,
· нанесение заданных текстур (узоров) на изображение,
· расчёт освещённости без учёта теней, а также
· отсечение невидимых поверхностей при помощи специального буфера глубины (Z-буфера).
Программировать эти графические процессоры самостоятельно было невозможно.
· 1999 год. Графические процессоры (серия NVIDIA GeForce) начинают работать с 32-битными вещественными числами, т. е. – с вещественными числами одинарной точности (7-8 значащих цифр)
Одинарной точности в принципе достаточно для моделирования физических систем, при условии применения агоритмов, корректирующих вычислительную погрешность, и проведения расчётов, критичных к точности, на центральном процессоре. Предыдущие GPU работали с числами «половинной» точности (16-битными числами), чего было заведомо недостаточно для точного физического моделирования.
С другой стороны, 32-битная точность была реализована ещё не полностью, промежуточные вычисления проводились с «половинной» точностью. Кроме того, первые процессоры серии GeForce по-прежнему не были программируемыми.
· 2001 год. Появление возможности пользовательского программирования процедур проектирования треугольников на плоскость экрана, расчёта освещённости и цвета отображаемых поверхностей.
От английского слова shade, имеющего значения «отбрасывать тень» и «заштриховывать», программы для графических процессоров стали называть шейдерами. Шейдеры позволяли выполнять над данными такие операции, как сложение, умножение, деление, вычисление квадратного корня, тригонометрических функций, экспоненты.
Шейдеры позволили реализовывать на GPU алгоритмы, не обязательно предназначенные для обработки графики. Таким образом, появилась возможность программирования GPU для решения различных задач, в том числе и задач физического моделирования.
Совокупность возможностей программирования, обеспечиваемых графическим процессором, принято называть шейдерной моделью. Первым программируемым GPU соответствовала шейдерная модель 1.0, имевшая серьёзные ограничения: длина шейдера не превосходила 20 команд, вычисления производились с «фиксированной» точкой (без использования порядковых множителей), ветвления алгоритмов не поддерживались.
Писать шейдеры сначала нужно было на специальном ассемблере. Позже появились высокоуровневые шейдерные языки программирования, такие как HLSL.
Пример GPU с шейдерной моделью 1.0 – серии NVidia GeForce 3-5.
· 2003 год. Полная реализация 32-битной точности при всех операциях с данными. Поддержка новыми графическими процессорами (NVIDIA GeForce FX, ATI Radeon 8500 - X800) шейдерной модели 2.0.
Шейдерная модель 2.0 (SM2) позволяла составлять программы длиной до 512 инструкций, а также использовать 22 регистра (быстрые ячейки памяти, расположенные прямо на процессоре) с произвольным доступом к памяти (то есть, с возможностью чтения и записи данных в произвольном порядке)
· 2004 год. Появление шейдерной модели 3.0 (GPU NVIDIA GeForce серий 6 и 7, ATI Radeon X1500 – X1950),
В шейдерной модели 3.0 (SM3) появились возможность программирования циклов (до 255 итераций) и динамическое ветвление (применение условных операторов). Максимальная длина программы выросла до 1024 инструкций, количество регистров увеличилось до 32.
· 2007 год. Графические процессоры с шейдерной моделью 4.0 (NVIDIA GeForce 8, AMD HD3). Фактический отказ от обязательной структуры программы в виде графического конвейера в пользу произвольной структуры программ.
Во всех предыдущих графических процессорах раздельно использовались вершинные и пиксельные конвейеры, решавшие различные задачи (при обработке графики – проектирование вершин и закрашивание треугольников, соответственно). Эти конвейеры нельзя было автоматически объединить для параллельной обработки одного и того же потока данных. Конвейеры GPU шейдерной модели 4.0 являются универсальными, они все могут быть объединены для обработки одного потока данных.
В шейдерной модели 4.0 впервые реализована поддержка 32-битных целых чисел, доступны 4096 регистров, возможны 65536 инструкций, расширены возможности произвольного взаимодействия графического процессора с памятью.
· 2008 год. В рамках шейдерной модели 4.0 появляется поддержка вещественных чисел двойной точности (64-битные числа, 15-16 значащих цифр). Примеры GPU - серии AMD HD4, NVIDIA GeForce 200.
5.3.4. Требования к алгоритмам для GPU, поддерживающих шейдерную модель 3.0
Результаты расчётов на GPU не обязательно сразу выводятся на экран, их можно записывать в оперативную память компьютера и в дальнейшем использовать произвольным образом. Это позволяет программировать графические процессоры для расчётов, не связанных с отображением графики, в частности – для моделирования физических процессов.
Как уже отмечено в предыдущем разделе, совокупность возможностей графического процессора, доступных программисту, называют шейдерной моделью. Первой шейдерной моделью была модель 1.0, современные графические процессоры поддерживают шейдерные модели 3.0 либо 4.0. GPU старших шейдерных моделей могут исполнять программы, написанные для предыдущих моделей, причём более эффективно, за счёт оптимизации взаимодействия с памятью и увеличением количества конвейеров.
В настоящей работе мы рассмотрим программирование графических процессоров с использованием шейдерной модели 3.0 (Shader Model 3.0 (SM3)). Эта модель достаточна для того, чтобы в полной мере реализовать поточно-параллельную обработку однотипных данных.
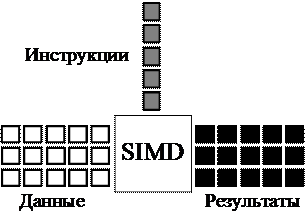
Рис. 4.7. Принцип поточно-параллельной обработки данных (SIMD)
Модель 4.0 позволила бы оптимизировать некоторые алгоритмы за счёт произвольного (а не поточного) доступа к исходным данным (см., например, [13]), но эта возможность уже не имеет прямого отношения к поточно-параллельному программированию, так что здесь мы её не рассматриваем.
Принцип программирования, реализованный в SM3, известен под аббревиатурой SIMD, от англ. Single Instruction – Multiple Data, т. е. Одна Инструкция – Множество Данных. Название принципа отражает тот факт, что GPU применяет одну и ту же последовательность инструкций одновременно ко многим элементам из входного потока данных. Принцип SIMD схематично показан на рис. 4.7. Можно сказать, что графический процессор преобразует поток данных в поток результатов, используя шейдеры как функцию преобразования.
Поскольку модель SM3 разработана для программирования графического конвейера, она требует представления вычислительной задачи в форме задачи обработки 3D-графики, следующим ниже образом.
· Исходные данные, предназначенные для потоковой обработки, должны быть представлены в виде массива однотипных объектов (в общем случае – 4-мерных векторов из вещественных чисел). Таких массивов может быть несколько.
· Допустимо использование дополнительных массивов, содержащих параметры обработки данных (см. реализацию молекулярной динамики ниже).
· К каждому из элементов входных массивов при потоковой обработке должен применяться один и тот же алгоритм, не зависящий от результатов обработки других элементов (этот алгоритм называют вычислительным ядром, на рис. 4.1 вычислительное ядро образовано операциями 1 – m).
· Массивы исходных данных передаются как информация, предназначенная для закрашивания треугольников при обработке графики. Алгоритм обработки этих данных нужно записать в пиксельный шейдер вместо алгоритма расчёта цветов треугольников. Порядок обработки такой информации показан на рис. 4.8.
· Ячейки массива исходных данных нужно представить как элементы поверхности треугольников, для которых рассчитываются цвета (рис. 4.8). Вместо границ циклов перебора исходных данных (таких, как цикл по i на рис. 4.1) автоматически используются границы отображаемых треугольников. Даже если в программируемой задаче физического моделирования никаких треугольников нет, потребуется задать границы треугольников в соответствии с диапазоном изменения входных данных.
· Вычислительное ядро программируется как содержание пиксельного шейдера – специальной процедуры в тексте программы для графического процессора (см. примеры в следующем разделе).
· Результатом расчёта должен быть один массив 4-мерных векторов, совпадающий по размеру с массивами входных данных. После завершения расчёта элементы этого массива автоматически записываются в область видеопамяти (памяти GPU, см. рис. 4.5), которую называют рендер-целью. Принцип формирования массива результатов показан на рис. 4.7.
· Центральный процессор компьютера имеет доступ к видеопамяти, включая ту область, где хранится рендер-цель. С использованием той части программы, которая исполняется на центральном процессоре, рендер-цель должна быть скопирована в оперативную память компьютера для дальнейшей обработки.
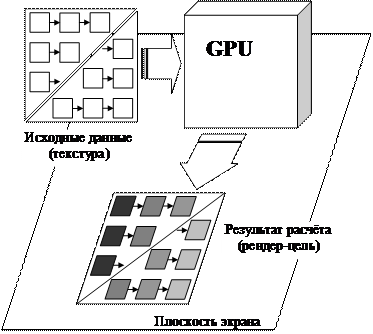
Рис. 4.8. Представление исходных данных, алгоритма их обработки и массива результатов в форме закрашивания треугольников. Стрелочки показывают, как происходил бы перебор данных на CPU, при замене треугольников циклами. Поскольку рендер-цель не обязательно выводить на экран, вместо расчёта цветов к исходным данным можно применить произвольный алгоритм обработки, например – реализующий физическое моделирование

Рис. 4.9. Соответствие между массивами результатов и исходных данных
5.3.5. Возможности GPU в рамках шейдерной модели 3.0 и взаимодействие GPU с памятью
Ведущими разработчиками и производителями графических процессоров в настоящее время являются компании NVIDIA и ATI (c 2007 года – подразделение компании AMD). Лучшие из графические процессоров этих компаний, поддерживавших шейдерную модель 3.0, по достижимой производительности физического моделирования уже были сравнимы с кластерами из нескольких десятков процессоров. В качестве примера характеристики некоторых из этих процессоров [16] приведены в табл. 4.2.
Таблица 4.2.
Характеристики графических процессоров, поддерживающих шейдеры модели 3.0
GPU | пиксельные | вершинные конвейеры |
ATI Radeon X1900 XT | 48 | 8 |
NVIDIA GeForce 7800 GTX | 24 | 8 |
ATI Radeon X1650 XT | 24 | 8 |
Графические процессоры с шейдерной моделью 3.0 поддерживают использование при программирование операций, приведённых ниже.
· Ряд математических операций с вещественными числами (см. Приложение 1). Целочисленные типы не поддерживаются.
· Последовательное и произвольное чтение данных из видеопамяти. Произвольной записи в видеопамять нет.
· Возможны циклы, длиной до 255 итераций.
· Возможны ветвления алгоритма в результате проверки условий, с использованием операторов условного перехода.
Взаимодействие GPU с памятью отчасти проиллюстрировано на рис. 4.5. В шейдерной модели 3.0 доступ GPU к памяти характеризуется следующими возможностями:
· Графическому процессору не доступны дисковая память и оперативная память компьютера. Поэтому перед началом вычислений исходные данные должны быть скопированы в видеопамять центральным процессором.
· Графическому процессору доступна видеопамять – специализированная память, обычно расположенная на видеокарте. У GPU нет доступа к оперативной и дисковой памяти.
· Поскольку оперативная память компьютера графическому процессору недоступна, перед началом вычислений исходные данные должны быть скопированы в видеопамять центральным процессором. Он же затем копирует массив результатов из видеопамяти обратно в оперативную память.
· Графическому процессору доступно как потоковое, так и произвольное чтение данных из видеопамяти.
· Единственный вариант записи в видеопамять - это автоматическое формирование массива результатов (рендер-цели). Произвольная запись в видеопамять невозможна.
· Графический процессор может использовать регистры - ячейки памяти, расположенные прямо на процессоре и характеризующиеся очень малой латентностью (быстрым доступом к данным):
· есть чтение из констант-регистров, которые могут хранить постоянные величины, не изменяющиеся в ходе обработки всех данных;
· есть чтение и запись во временные регистры, данные в которых не сохраняются при переходе к следующим элементам потока данных.
· Вершинные процессоры могут записывать до 12-и 4-векторов из 32-битных чисел.
· Пиксельные процессоры могут записывать до 4-х 4-векторов из 32-битных чисел.
· Нет работы с динамически размещаемыми структурами данных.
· Суммарное кол-во инструкций в программе - не более 65536 (у графических процессоров NVIDIA).
Таким образом, возможностей шейдерной модели 3.0 достаточно для эффективной реализации «чистой» поточно-параллельной обработки данных, но вот возможности произвольной работы с памятью, а также применения ветвлений и циклов ограничены.
5.3.6. Проблема одинарной точности
Как отмечено выше, шейдеры модели 3.0 могут работать только с вещественными числами одинарной (32-битной) точности, содержащими 7-8 значащих цифр. В некоторых задачах, включая молекулярную динамику, это приводит к недопустимому накоплению погрешности округления. Эта проблема решается, если удаётся выделить критичные участки алгоритма, на которых необходимы высокая производительность и распараллеливание вычислений, при сравнительно больших допустимых погрешностях округления.
Наши исследования показали, что в молекулярной динамике на GPU c одинарной точностью можно рассчитывать силы, действующие на каждую из частиц, тогда как интегрирование уравнений движения (которое на порядки менее ресурсоёмко, но более критично к накоплению погрешности округления) проводить на CPU с двойной точностью. При этом оказывается, что результаты вычислений мало отличаются от результатов, получающихся при проведении всех расчётов с двойной точностью (64-битные числа, 15-16 значащих цифр).
5.4. Средства программирования графических процессоров
5.4.1. Общая структура программы для физического моделирования на графическом процессоре
Для того чтобы графический процессор мог исполнить программу, она должна быть откомпилирована в машинные коды и записана в оперативную память компьютера, откуда драйвер графического процессора передаёт её на исполнение. Для шейдеров модели 3.0 существуют языки программирования высокого уровня (Cg, HLSL, GLSL), на этих языках программы можно писать в форме текстовых файлов, которые затем компилируются в машинные коды автоматически. Примеры шейдеров, приведённые ниже, будут написаны на языке HLSL.
Вместе с тем, шейдерная модель 3.0 не позволяет создавать для графических процессоров полнофункциональные программы, которые включали бы в себя загрузку данных из оперативной памяти компьютера или с дисковых накопителей, а также обеспечивали бы пользовательский интерфейс. Эти задачи, а также те компоненты вычислительного алгоритма, где нет поточно-параллельных расчётов, должен исполнять центральный процессор ПК, для чего необходима программа на «обычном» языке высокого уровня (C#, C++, Visual Basic и др.).
Для того чтобы из программы, написанной на «обычном» языке высокого уровня, было проще прямо обращаться к драйверу видеокарты (а через него – к графическому процессору) существуют стандартные библиотеки специальных процедур, наиболее распространённые из которых - API DirectX и OpenGL. Процедуры из этих библиотек обеспечивают такие операции, как
· Выделение памяти для массива вершин треугольников, образующих 3D-сцену (при программировании графики) либо задающих границы циклов (при математическом моделировании);

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
