

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 1 Статистическая сводка, группировка и ряды распределения
Статистическая сводка – научная обработка материалов наблюдения для получения сводных обобщающих характеристик.
Работа по сводке информации делится на следующие этапы:
- формулировка задач сводки на основе целей статистического исследования;
- формирование групп и подгрупп, определение группировочных признаков, числа групп и величины интервала;
- проверка полноты и качества собранного материала, подсчет различных итогов и исчисление необходимых показателей для характеристики всей совокупности и ее частей.
Сводка проводится по специальной программе, которая составляется в соответствии с задачами исследования, с учетом формы организации и техники обработки данных. Программа статистической сводки оформляется в виде таблицы, основным содержанием которой является перечень групп, на которые делится изучаемая совокупность. В программе также указываются способы сводки данных.
Группировка – это процесс образования однородных групп в результате деления статистической совокупности на части. Данные группы образуются или посредством деления совокупности на части, характеризующиеся внутренней однородностью, или благодаря объединению в группы единиц совокупности по типичным признакам. Признаки, по которым производится распределение единиц изучаемой совокупности на группы, называются группировочными признаками или основанием группировки. Задачи группировок: образование социально-экономических типов явлений; изучение строения явлений и структурных изменений, происходящих в них; выявление связи между изучаемыми признаками.
Основные этапы процесса группировки:
- определение группировочного признака;
- установление количества групп;
- расчет величины интервала.
Для расчета интервала необходимо знать размах колеблемости значений изучаемого признака и количество групп, которые необходимо сформировать. Величина равного интервала определяется по формуле 1.1
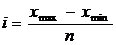 , (1.1)
, (1.1)
где Xmax – максимальное значение признака в совокупности;
Xmin – минимальное значение признака в совокупности;
n – количество групп, которые необходимо сформировать.
При построении интервалов значение признака указывается «от» и «до», например группа рабочих по стажу 1-5 лет. Каждая группа имеет минимальное и максимальное значение признака.
Статистическая таблица – это форма наиболее краткого и рационального изложения цифровых данных об изучаемой статистической совокупности. В таблице наглядно проявляется связь между признаками изучаемого явления.
В статистике для изучения степени неравномерности распределения определенного суммарного показателя между единицами отдельных групп вариационного ряда используется кривая Лоренца и рассчитанный на ее основе коэффициент Джини.
Для количественного измерения степени концентрации имеется ряд показателей. Наиболее часто используется для этой цели коэффициент Джини (G), который рассчитывается по формуле 1.2
![]() (1.2)
(1.2)
Коэффициент Лоренца (L) рассчитывается как полусумма разностей по всем группам доли единиц совокупности (частостей wi) и доли изучаемого суммарного показателя (dyi), т. е. по формуле 1.3
![]() (1.3)
(1.3)
Если w и d выражены в процента, то в знаменателе следует принимать 200.
Тема 2 Средние величины и показатели вариации
Средняя величина – это обобщающий показатель, который выражает величину признака, отнесенную к единице совокупности.
Средние величины делятся на две группы:
- степенные средние – это средняя арифметическая, геометрическая, гармоническая, хронологическая;
- структурные средние – это мода и медиана.
Степенные средние
Средняя арифметическая - применяется в тех случаях, когда объем варьирующего признака для всей совокупности определяется путем суммирования значений признака отдельных единиц. Средняя арифметическая бывает двух видов: простая и взвешенная. Простая средняя определяется по формуле 2.1
![]() , (2.1)
, (2.1)
где Х1 - Хn – отдельные значения признака;
n – количество признаков.
Взвешенная средняя рассчитывается следующим образом по формуле 2.2
![]() , (2.2)
, (2.2)
где Х – отдельное значение признака;
f – повторяемость отдельных вариант.
Средняя гармоническая - используется в том случае, если отсутствуют частоты, но известны варианты, а также объем признака. Формула для расчета 2.3
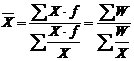 (2.3)
(2.3)
Средняя хронологическая - применяется в том случае, когда данные представлены по состоянию на конкретный момент времени и рассчитывается по формуле 2.4
![]() (2.4)
(2.4)
Средняя геометрическая - применяется для определения средних темпов роста, прироста и определяется по формуле 2.5
![]() (2.5)
(2.5)
Структурные средние.
Мода – значение признака, которое чаще всего встречается в совокупности, обозначается Мо. В вариационном ряду мода определяется как варианта с наибольшей частотой.
В интервально-вариационном ряду модой приближенно считают модальный интервал, который имеет наибольшую частоту. Затем в пределах данного интервала находят то значение признака, которое является модой по следующей формуле 2.6
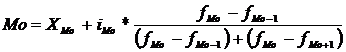 , (2.6)
, (2.6)
где XMo – минимальное значение модального интервала;
iMo – величина модального интервала;
fMo – частота модального интервала;
fMo-1 – частота интервала, предшествующего модальному;
fMo+1 – частота интервала, следующего за модальным.
Медиана – величина, которая делит совокупность на две равные части, обозначается Ме. Причем одна часть имеет значение варьирующего признака меньше медианы, а другая – больше. В вариационном ряду с нечетным количеством элементов медиана определяется как серединное значение ряда. При четном количестве элементов ряда медиана определяется как полусумма двух серединных значений.
В интервально-вариационном ряду медиана определяется следующим образом:
- все индивидуальные значения признака располагаются по возрастанию или убыванию;
- в данном упорядоченном ряду определяются накопленные (кумулятивные) частоты;
- по данным о накопленных частотах находим медианный интервал.
Кумулятивные частоты образуются путем постепенного суммирования частот, начиная от интервала с наименьшим значением признака. Таким образом, накопленные частоты характеризуют порядковый номер элементов, т. е. на каком месте находятся величины в ряду. После того, как определен медианный интервал, находим значение медианы по следующей формуле 2.7
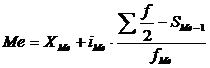 , (2.7)
, (2.7)
где XMe – минимальное значение медианного интервала;
iMe – величина медианного интервала;
![]() – сумма всех частот;
– сумма всех частот;
SMe-1 – накопленные частоты интервала, предшествующего медианному;
fMe – частота медианного интервала.
Показатели вариации.
Вариация (изменение, колеблемость) признака возникает в результате воздействия на него различных факторов.
Изучения колеблемости признака можно провести при помощи:
- построения графика рассеивания;
- расчет показателей вариации.
Размах вариации – абсолютная разность между минимальным и максимальным значениями признака из имеющихся в совокупности и определяется по формуле 2.8
![]() (2.8)
(2.8)
Среднее линейное отклонение – используется для определения среднего отклонения отдельных значений признака от средней арифметической. Оно определяется как простое и взвешенное по формулам 2.9 и 2.10 соответственно
![]() (2.9)
(2.9)
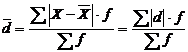 (2.10)
(2.10)
Дисперсия – средний квадрат отклонений отдельных значений признака от средней арифметической и рассчитывается для простого ряда по формуле 2.11 и для взвешенного по формуле 2.12
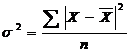 (2.11)
(2.11)
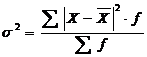 (2.12)
(2.12)
Среднее квадратическое отклонение – определяется как корень квадратный из дисперсии для простого ряда рассчитывается по формуле 2.13, для взвешенного по формуле 2.14
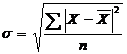 (2.13)
(2.13)
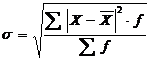 (2.14)
(2.14)
Коэффициент вариации – отношение среднего квадратического отклонения и средней арифметической, который рассчитывается по формуле 2.15
![]() (2.15)
(2.15)
Тема 3 Выборочное наблюдение
Выборочное наблюдение – одно из наиболее современных видов статистического наблюдения. Выборочное наблюдение – это такое наблюдение, при котором обследованию подвергается часть единиц изучаемой совокупности, отобранных на основе научно разработанных принципов, обеспечивающих получение достаточного количества достоверных данных, для того чтобы охарактеризовать всю совокупность в целом.
Средние и относительные показатели, полученные на основе выборочных данных, должны достаточно полно воспроизводить или репрезентатировать соответствующие показатели совокупности в целом.
Статистическое исследование может осуществляться по данным несплошного наблюдения, основная цель которого состоит в получении характеристик изучаемой совокупности по обследованной ее части. Одним из наиболее распространенных в статистике методов, применяющих несплошное наблюдение, является выборочный метод.
Под выборочным понимается метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее части на основе положений случайного отбора. При выборочном методе обследованию подвергается сравнительно небольшая часть всей изучаемой совокупности (обычно до 5 — 10 %, реже до 15 — 25 %). При этом подлежащая изучению статистическая совокупность, из которой производится отбор части единиц, называется генеральной совокупностью. Отобранная из генеральной совокупности некоторая часть единиц, подвергающаяся обследованию, называется выборочной совокупностью или просто выборкой.
Значение выборочного метода состоит в том, что при минимальной численности обследуемых единиц проведение исследования осуществляется в более короткие сроки и с минимальными затратами труда и средств. Это повышает оперативность статистической информации, уменьшает ошибки регистрации.
В проведении ряда исследований выборочный метод является единственно возможным, например, при контроле качества продукции (товара), если проверка сопровождается уничтожением или разложением на составные части обследуемых образцов (определение сахаристости фруктов, клейковины печеного хлеба, установление носкости обуви, прочности тканей на разрыв и т. д.).
В генеральной совокупности доля единиц, обладающих изучаемым признаком, называется генеральной долей (обозначается р), а средняя величина изучаемого варьирующего признака – генеральной средней (обозначается ![]() ).
).
В выборочной совокупности долю изучаемого признака называют выборочной долей, или частостью (обозначается ![]() ), а среднюю величину в выборке — выборочной средней (обозначается
), а среднюю величину в выборке — выборочной средней (обозначается ![]() ).
).
При решении задач, прежде всего, устанавливаются характеристики выборочной совокупности. Выборочная доля, или частость (![]() ) определяется из отношения единиц, обладающих изучаемым признаком (m), к общей численности единиц выборочной совокупности (n) и рассчитывается по формуле 3.1
) определяется из отношения единиц, обладающих изучаемым признаком (m), к общей численности единиц выборочной совокупности (n) и рассчитывается по формуле 3.1
![]() (3.1)
(3.1)
Ошибка выборки – это объективно возникающее расхождение между характеристиками выборки и генеральной совокупности. Она зависит от ряда факторов: степени вариации изучаемого признака, численности выборки, методом отбора единиц в выборочную совокупность, принятого уровня достоверности результата исследования.
Определение ошибки выборочной средней. При случайном повторном отборе средняя ошибка выборочной средней рассчитывается по формуле 3.2
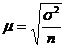 , (3.2)
, (3.2)
![]() где
где ![]() — средняя ошибка выборочной средней;
— средняя ошибка выборочной средней;
![]() — дисперсия выборочной совокупности;
— дисперсия выборочной совокупности;
n — численность выборки.
При бесповторном отборе она рассчитывается по формуле 3.3
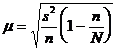 , (3.3)
, (3.3)
где N — численность генеральной совокупности.
Определение ошибки выборочной доли. При повторном отборе средняя ошибка выборочной доли рассчитывается по формуле 3.4
![]()
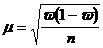 , (3.4)
, (3.4)
где ![]() — выборочная доля единиц, обладающих изучаемым признаком;
— выборочная доля единиц, обладающих изучаемым признаком;
![]() — число единиц, обладающих изучаемым признаком;
— число единиц, обладающих изучаемым признаком;
![]() — численность выборки.
— численность выборки.
При бесповторном способе отбора средняя ошибка выборочной доли определяется по формуле 3.5
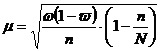 (3.5)
(3.5)
Предельная ошибка выборки ![]() связана со средней ошибкой выборки
связана со средней ошибкой выборки ![]() выражением, которое представлено формулой 3.6
выражением, которое представлено формулой 3.6
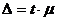 (3.6)
(3.6)
При этом t как коэффициент кратности средней ошибки выборки зависит от значения вероятности Р, с которой гарантируется величина предельной ошибки выборки.
Предельная ошибка выборки при бесповторном отборе определяется по следующим формулам 3.7 и 3.8
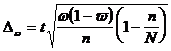 , (3.7)
, (3.7)
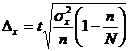 . (3.8)
. (3.8)
Предельная ошибка выборки при повторном отборе определяется по формулам 3.9 и 3.10
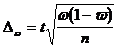 , (3.9)
, (3.9)
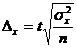 . (3.10)
. (3.10)
Малая выборка. При контроле качества товаров в экономических исследованиях эксперимент может проводиться на основе малой выборки.
Под малой выборкой понимается несплошное статистическое обследование, при котором выборочная совокупность образуется из сравнительно небольшого числа единиц генеральной совокупности. Объем малой выборки обычно не превышает 30 единиц и может доходить до 4 – 5 единиц.
Средняя ошибка малой выборки ![]() вычисляется по формуле 3.11
вычисляется по формуле 3.11
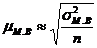 , (3.11)
, (3.11)
где 
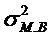 — дисперсия малой выборки.
— дисперсия малой выборки.
При определении дисперсии ![]() число степеней свободы равно n-1 и рассчитывается дисперсия по формуле 3.12
число степеней свободы равно n-1 и рассчитывается дисперсия по формуле 3.12
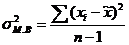 (3.12)
(3.12)
Предельная ошибка малой выборки ![]() определяется по формуле
определяется по формуле![]()
При этом значение коэффициента доверия t зависит не только от заданной доверительной вероятности, но и от численности единиц выборки n. Для отдельных значений t и n доверительная вероятность малой выборки определяется по специальным таблицам Стьюдента, в которых даны распределения стандартизированных отклонений.
Для определения средней ошибки типической выборки используются следующие формулы для расчёта.
Повторный отбор, формулы 3.13 и 3.14
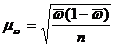 (3.13)
(3.13)
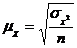 (3.14)
(3.14)
Бесповторный отбор, формулы 3.15 и 3.16
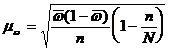 (3.15)
(3.15)
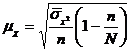 (3.16)
(3.16)
Дисперсия определяется по следующим формулам 3.17 и 3.18
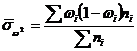 (3.17)
(3.17)
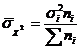 (3.18)
(3.18)
При одноступенчатой выборке каждая отобранная единица сразу же подвергается изучению по заданному признаку. Так обстоит дело при собственно-случайной и серийной выборке.
При многоступенчатой выборке производят подбор из генеральной совокупности отдельных групп, а из групп выбираются отдельные единицы. Так производится типическая выборка с механическим способом отбора единиц в выборочную совокупность.
Комбинированная выборка может быть двухступенчатой. При этом генеральная совокупность сначала разбивается на группы. Затем производят отбор групп, а внутри последних осуществляется отбор отдельных единиц.
Тема 4 Ряды динамики
Одной из важнейших задач статистики является изучение процессов и явлений во времени. Это осуществляется с помощью построения и анализа рядов динамики.
Ряд динамики – ряд, расположенный в хронологической последовательности числовых значений статистического показателя, характеризующих изменения общественных явлений во времени.
Для изучения интенсивности изменения уровней ряда динамики во времени исчисляются следующие показатели динамики.
Абсолютный прирост базисный определяется по формуле 4.1, цепной по формуле 4.2
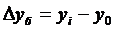 (4.1)
(4.1)
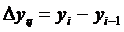 (4.2)
(4.2)
Коэффициент роста базисный определяется по формуле 4.3, цепной по формуле 4.4
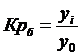 (4.3)
(4.3)
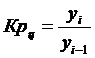 (4.4)
(4.4)
Темп роста базисный определяется по формуле 4.5, цепной по формуле 4.6
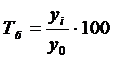 (4.5)
(4.5)
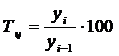 (4.6)
(4.6)
Темп прироста базисный определяется по формуле 4.7, цепной по
формуле 4.8
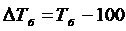 (4.7)
(4.7)
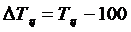 (4.8)
(4.8)
Абсолютное значение 1 % прироста, ![]() , определяется по формуле 4.9
, определяется по формуле 4.9
или 4.10
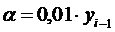 (4.9)
(4.9)
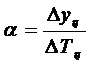 (4.10)
(4.10)
Условные обозначения следующие:
у - значения показателя в динамическом ряду;
![]() - базисный уровень, принятый за постоянную базу сравнения (часто начальный уровень
- базисный уровень, принятый за постоянную базу сравнения (часто начальный уровень![]() );
);
![]() - уровень любого последующего периода (кроме первого), называемый уровнем текущего периода;
- уровень любого последующего периода (кроме первого), называемый уровнем текущего периода;
![]() - уровень любого периода предшествующего текущему периоду;
- уровень любого периода предшествующего текущему периоду;
n – число уровней ряда.
Определение тенденции в рядах динамики.
Сущность статистики как науки заключается, прежде всего, в изучении закономерностей развития явлений. В некоторых случаях тенденция развития явления четко и ясно отражается уровнями ряда динамики, т. е. наблюдается либо увеличение, либо уменьшение в течение всего периода времени. Однако чаще встречаются такие ряды, в которых явление изменяется хаотически в разные периоды времени: то возрастает, то убывает, либо не изменяется. В таких случаях принято говорить лишь об определении общей тенденции развития явления.
Процесс выявление основной тенденции развития явления (тренд) называется выравниванием временного ряда.
В статистике выделяют следующие методы выравнивания рядов динамики:
- укрупнение интервалов в ряду динамики – это один из наиболее простых способов выявления тренда. Сущность данного метода заключается в том, что исходный ряд преобразуется и заменяется новым рядом, в котором уровни относятся к более длительным по продолжительности периодам времени.
- смыкание рядов динамики. Данный метод применяется в том случае, если уровни ряда не подлежат сопоставлению в связи с организационными изменениями в течение определенного промежутка времени. Суть метода состоит в объединении рядов динамики, уровни которых предварительно выражаются в относительных величинах, причем за базу сравнения принимается год, в котором произошло изменение.
- метод скользящей средней. Данный метод заключается в расчете среднего значения признака за несколько лет. Для расчета скользящей средней необходимо провести укрупнение интервала уровней ряда динамики, причем интервалы должны состоять из одинакового числа уровней, обычно нечетного. Данный этап называется расчетом скользящей суммы. Далее необходимо по каждой сумме рассчитать среднюю.
- аналитическое выравнивание ряда динамики. Данный метод предполагает построение количественной модели, которая бы выражала общую тенденцию изменения уровней ряда динамики во времени. Суть метода заключается в расчете новых значений уровней рядя динамики и замене ими исходных значений уровней ряда. Затем по полученным данным строится кривая, которая отражает общую тенденцию изменения явления во времени. Аналитическое выравнивание динамического ряда проводится по формуле 4.11 уравнения прямой
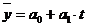 , (4.11)
, (4.11)
где t – порядковый номер периодов или момента времени.
Параметры а0 и а1 находятся по формуле наименьших квадратов при помощи построения системы уравнений
![]()
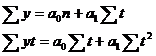
Для определения параметров уравнения упростим расчет и произведем отсчет времени так, чтобы сумма показателей времени равнялась нулю, т. е. St = 0. Для этого уровень, находящийся в центре ряда принимаем за условное начало отсчета времени и придаем ему нулевое значение (если ряд имеет нечетное количество элементов). Даты времени или периода стоящие выше этого значения обозначаются натуральными числами со знаком «-» начиная с единицы (-1, -2 и т. д.), а значения стоящие ниже – со знаком «+» (1, 2 и т. д.). Лишь в данном случае сумма значений показателей времени будет равна нулю, а система уравнений примет следующий вид
![]()
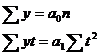
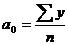
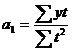
где у – уровень ряда;
n – количество лет;
t – порядковый номер периодов или момента времени.
Тема 5 Индексы
Индекс – относительный показатель соизмерения двух величин. С помощью индексов изучается динамика сложного явления; устанавливаются плановые задания по производству продукции, снижению себестоимости, росту производительности труда; контролируется выполнение плана.
Индексы подразделяются на индивидуальные и общие.
Индивидуальные индексы применяются в том случае, если определяется изменение каждого фактора в отдельности. Для его расчета необходимо значение фактора в отчетном периоде разделить на значение фактора в базисном периоде.
Например, индивидуальный индекс физического объема можно определить по формуле 5.1
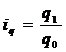 (5.1)
(5.1)
где q1 и q0 – соответственно: физический объем продукции в отчетном и базисном периоде.
Аналогичным образом можно определить индивидуальные индексы цен (p), себестоимости (z), производительности труда (w) и т. д.
Общий индекс применяется в том случае, когда необходимо определить изменение определенного фактора в среднем.
Агрегатные индексы выполнения плана
- индекс выполнения плана объема продукции рассчитывается по
формуле 5.2
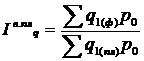 (5.2)
(5.2)
где q1 (пл) и q1 (ф) – объем продукции в натуральном выражении в отчетном
периоде фактически и по плану.
- индекс выполнения плана цен рассчитывается по формуле 5.3
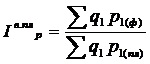 (5.3)
(5.3)
где р1 (пл) и р1 (ф) – цена продукции в отчетном периоде фактически и по плану.
- индекс выполнения плана себестоимости продукции рассчитывается по формуле 5.4
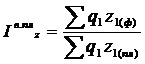 (5.4)
(5.4)
где z1 (пл) и z1 (ф) – себестоимость единицы продукции в отчетном периоде фактически и по плану.
- индекс выполнения плана производительности труда рассчитывается по формуле 5.5
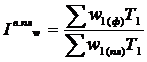 (5.5)
(5.5)
где w1 (пл) и w1 (ф) - производительность труда (в денежном выражении в единицу
времени) в отчетном периоде фактически и по плану.
Т1 - общие затраты времени на выработку продукции отчетного периода (человеко-часы, человеко-дни, среднесписочная численность рабочих)
Агрегатные индексы динамики.
- индекс динамики физического объема продукции рассчитывается по формуле 5.6
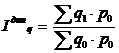 (5.6)
(5.6)
- индекс динамики цен рассчитывается по формуле 5.7
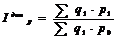 (5.7)
(5.7)
- индекс динамики себестоимости продукции рассчитывается по
формуле 5.8
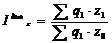 (5.8)
(5.8)
- индекс динамики производительности труда рассчитывается по
формуле 5.9
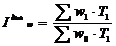 (5.9)
(5.9)
С помощью агрегатного индекса можно получить не только относительный показатель изменения явления, но и абсолютное изменение величины явления, исчисляемое как разность между числителем и знаменателем агрегатного индекса.
При вычислении агрегатного индекса динамики абсолютное изменение величины явления покажет:
- абсолютный прирост (снижение) объема продукции в неизменных ценах, который определяется по формуле 5.10
![]() (5.10)
(5.10)
- абсолютную величину экономии (дополнительных затрат) в результате изменения цен на продукцию при неизменном объеме можно рассчитать по формуле 5.11
![]() (5.11)
(5.11)
- абсолютную величину экономии (дополнительных затрат) в расходах в результате изменения себестоимости единицы продукции при неизменном объеме можно рассчитать по формуле 5.12
![]() (5.12)
(5.12)
- абсолютный прирост (снижение) производительности труда при неизменных затратах можно рассчитать по формуле 5.13
![]() (5.13)
(5.13)
Тема 6 Статистическое изучение взаимосвязи социально-экономических явлений
Корреляция – это статистическая зависимость между случайными величинами, не имеющими строго функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой.
Варианты взаимосвязи:
1. Парная корреляция – связь между 2 признаками (результативным и фактическим или двумя фактическими);
2. Частная корреляция;
3. Множественная корреляция.
Корреляционный анализ имеет своей задачей количественное определение тесноты связи между двумя признаками (при парной связи) и между результативным и множеством факторных признаков (при многофакторной связи).
Парная корреляция характеризует связь между двумя признаками: результативным и факторным. Аналитическая связь между ними описывается уравнениями: прямой, гиперболы, параболы.
Изучение связи между тремя и более связанными между собой признаками носит название множественной (многофакторной) регрессии.
Измерение тесноты и направление связи является важной задачей изучения и количественного измерения взаимосвязи социально-экономических явлений.
Линейный коэффициент корреляции был впервые введен Пирсоном и характеризует тесноту и направление связи между двумя коррелируемыми признаками в случае наличия между ними линейной зависимости. Линейный коэффициент корреляции определяется по формуле 6.1
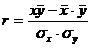 (6.1)
(6.1)
Важной задачей статистики является изучение методики статистической оценки социальных явлений, которая осложняется тем, что многие социальные явления не имеют количественной оценки.
При наличии соотношения между вариацией качественных признаков говорят об их ассоциации, взаимосвязанности. Для оценки связи в этом случае используют ряд показателей.
Когда каждый из качественных признаков составляет более чем из двух групп, то для определения тесноты связи возможно применение коэффициента взаимной сопряженности Пирсона и Чупрова.
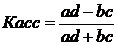 (6.2)
(6.2)
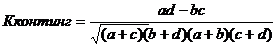 (6.3)
(6.3)
Таблица для вычисления коэффициентов ассоциации и контингенции
a | b | a+b |
c | d | c+d |
a+c | b+d | a+b+c+d |
Коэффициент контингенции всегда меньше коэффициента ассоциации; связь считается подтвержденной если Касс³0,5 а Кконтинг³3.
Когда каждый из качественных признаков состоит более чем из двух групп, то для определения тесноты связи возможно применение коэффициента взаимной сопряженности Пирсона и Чупрова.
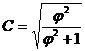 , (6.4)
, (6.4)
где j2–показатель взаимной сопряженности.
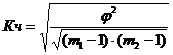 (6.5)
(6.5)
Чем ближе величины показатели к единице, тем связь теснее.
Для определения корреляционно-регрессионной связи решается уравнение прямой
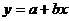 .
.
После соответствующих преобразований данное уравнение можно представить в виде системы уравнений
![]()
Тема 7 Статистика населения и трудовых ресурсов
Население как предмет изучения в статистике представляет собой совокупность людей, проживающих на определенной территории и непрерывно возобновляющихся за счет рождений и смертей.
Объектом статистического наблюдения в статистике могут быть разные совокупности: население в целом ( постоянное, наличное), определенные группы населения ( трудоспособное население, безработные, пенсионеры и т. д., мужское и женское население, городское и сельское и др.), молодые или пожилые семьи, родившиеся или умершие. Объект и единица наблюдения выбираются в зависимости от цели исследования.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
