
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
f |
|
Рис. 14. Бимодальное распределение
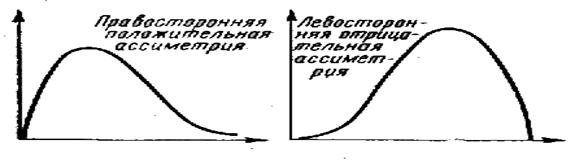
- во втором случае - значения могут быть сконцентрированы больше в левой части кривой, что вскрывает тенденцию к ухудшению показателей у большинства обследуемых.
При концентрации значений в правой части кривой наблюдалась бы тенденция к улучшению показателей у большинства обследуемых (рис. 15).
|
|
Рис. 15. Виды асимметрий
О наличии отклонений в распределении судят по величине диапазона размаха или разброса данных, т. е. по разнице между максимальным и минимальным значениями.
Так, если в обследуемой группе диапазон распределения до воздействия составлял
21 – 10 = 11,
Обследуемая группа (до воздействия) | ||||||||||||||
10 | 11 | 12 | 13 | 14 | 14 | 15 | 15 | 15 | 15 | 17 | 17 | 19 | 20 | 21 |
то после воздействия составил 25 – 8 = 17.
Обследуемая группа (после воздействия) | |||||||||||||||||
8 | 10 | 11 | 12 | 13 | 14 | 14 | 15 | 15 | 15 | 15 | 17 | 17 | 19 | 20 | 21 | 23 | 25 |
Это позволяет предположить, что воздействие по-разному сказалось на результатах: у одних обследуемых они улучшились, а у других ухудшились.
Для более точного подсчета разброса полученных значений рассчитывают среднее откло-нение (Х - ![]() ), обозначаемое буквой d. Чем меньше это среднее отклонение, тем больше резуль-татов измерений сконцентрированы относительно их среднего значения, и выборка считается однородной.
), обозначаемое буквой d. Чем меньше это среднее отклонение, тем больше резуль-татов измерений сконцентрированы относительно их среднего значения, и выборка считается однородной.
1. Сначала вычисляют среднее арифметическое значение (![]() ). Так, например, для следую-щего ряда среднее арифметическое для данной выборки будет равно:
). Так, например, для следую-щего ряда среднее арифметическое для данной выборки будет равно: ![]()
2. Затем вычисляют отклонение каждого значения от средней, для чего сумму абсолютных значений делят на число членов ряда:
D = ![]()
Каждое из отклонений (d) характеризуется степенью расхождения показателей переменной со средним арифметическим. Общая формула среднего отклонения выглядит следующим образом:
Среднее отклонение (d) = ![]()
Где - S (сигма) - сумма абсолютных значений разности средних отклонений (Х - 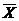 ),
),
d – абсолютное значение каждого индивидуального отклонения от средней, n - число членов ряда.
Однако среднее отклонение при достаточно большом разбросе значений переменной, при равномерном распределении оценок или при проведении оценок экспертами, стоящими на различных теоретических позициях, лишь приблизительно (усредненно) свидетельствует о разбросе полученных результатов измерений переменной.
В практике анализа полученных данных чаще всего пользуются наиболее информативным показателем разброса – стандартное (σ) или среднее квадратическое отклонение (ошибка), которое вычисляется по следующим формулам:
| или | σ = | или | σ = |
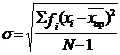
Причем в данных формулах деление осуществляется не на объем выборки (N), а на величину (N - 1). В исследованиях на малых выборках для измерений не слишком репрезентативных вводится поправка (N < 100). Для выборок больше 100 деление необходимо производить на n.
Наиболее важным свойством стандартного отклонения является то, что 68% результатов обследования располагаются в пределах одного стандартного отклонения, 95% в пределах двух стандартных отклонений и 99,7% - в пределах трех стандартных отклонений. Это уже опреде-ленная основа для дифференциации выявленных психологических показателей.
Более точно этот разброс (кучность оценок) учитывается при вычислении дисперсии (слово «дисперсия» означает «рассеивание»).
Дисперсия - величина, показывающая, сколь велики отклонения рассматриваемых данных от средней арифметической. Она представляет собой среднее значение квадрата отклонений рас-сматриваемых данных от средней арифметической и обозначается d 2 /сигма квадрат/.
Для определения дисперсии (![]() ) необходимо: найти отклонение каждого разряда наблю-даемых данных от средней арифметической; найденные отклонения умножить на частоту попадания наблюдаемых данных в соответствующий разряд; найти сумму полученных значений; найденную сумму разделить на число наблюдений: для больших выборок – n, для выборок меньших (n < 100) - /n - 1/
) необходимо: найти отклонение каждого разряда наблю-даемых данных от средней арифметической; найденные отклонения умножить на частоту попадания наблюдаемых данных в соответствующий разряд; найти сумму полученных значений; найденную сумму разделить на число наблюдений: для больших выборок – n, для выборок меньших (n < 100) - /n - 1/
![]() =
= ![]() ;
;
На практике, однако, чаще используют другой показатель - стандартное отклонение
(σ) - показатель, представляющий собой квадратный корень из дисперсии.
σ = 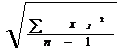
где xi - каждое наблюдаемое значение признака,
n – 1 - количество наблюдений (для малых выборок уменьшается на 1).
Наиболее распространенными показателями при описании эмпирических распределений являются коэффициент асимметрии и показатель эксцесса (горбатости).
Коэффициент асимметрии (А) дает численную меру скошенности статистических распре-делений и вычисляется по формуле:
|
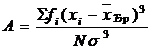
Для распределений симметричных этот коэффициент равен нулю, значение А положительно при правосторонней скошенности и отрицательно - при левосторонней.
Эксцесс - Е - это количественная мера “горбатости” симметричного распределения, т. е. некоторой плавности (крутости, остро - или туповершинности) верхней части распределения:
![]()
Величина эксцесса в нормальном распределении равняется нулю, при положительном значении Е кривые называются островершинными, при отрицательном - туповершинными. В нормальных распределениях Е и А равны нулю.
Часто приходится оценивать и другие показатели: определять принадлежат ли исследуемые выборочные распределения переменных к одной генеральной совокупности и, следовательно, можно ли распространить выявленные зависимости и тенденции на всю генеральную совокуп-ность, из которой исследователем взята данная выборка[24].
На практике это делается различными способами: а) наложением кривых распределения друг на друга и определения различий в трех видах показателей меры симметрии или центральной тенденции: средней арифметической (![]() ), моды (Мо) и медианы (Ме); б) подтверждением или опровержением выдвинутой гипотезы, которую нужно будет затем проверить статистическими методами: нуль-гипотезы (Н0) или альтернативной гипотезы (Н1); в) использованием статисти-ческих методов проверки и оценки гипотез, (F - критерий Фишера, критерий X2, z-критерий,
), моды (Мо) и медианы (Ме); б) подтверждением или опровержением выдвинутой гипотезы, которую нужно будет затем проверить статистическими методами: нуль-гипотезы (Н0) или альтернативной гипотезы (Н1); в) использованием статисти-ческих методов проверки и оценки гипотез, (F - критерий Фишера, критерий X2, z-критерий,
t-критерий Стьюдента и др.), г) проведением корреляционного анализа.
Корреляции - это связь между статистическими величинами по различным признакам. Коэффициент корреляции - математический показатель силы связи между двумя сопоставляе-мыми статистическими признаками (переменными) в целях предсказания возможных изменений одного, если известна тенденция изменения другого.
При К=1 наблюдается прямо пропорциональная зависимость, при К = -1 связь обратно пропорциональна, при К = 0 связи нет.
Этими параметрами распределения психодиагност пользуется при статистической обработке результатов выявления и интерпретации результатов.
3.3. Измерительные и оценочные шкалы
Результаты обследования профессиональных способностей испытуемых заносятся в спе-циальные шкалы, позволяющие в последующем применить психометрический инструментарий для научно обоснованного вывода о предпочтениях того или иного кандидата на вакантную должность.
Измерение - это преобразование определенных свойств и качеств в известные, легко поддаю-щиеся интерпретации и обработке единицы, называемые числами. Измерение есть приписывание чисел свойствам и качествам субъектов и объектов в соответствии с определенными правилами. Шкала - это форма фиксации совокупности признаков изучаемого объекта с упорядочиванием их в определенную числовую систему.
I. Измерительные шкалы – форма фиксации и способ упорядочения совокупности признаков изучаемых психологических явлений или процессов, в определенную числовую систему. Применение шкал связывается с необходимостью качественной и количественной оценки
(с задачей последующего сравнения) определенных признаков и переменных.
Признаки и переменные - это измеряемые психологические явления. Такими явлениями могут быть: время решения задачи, количество допущенных ошибок, уровень тревожности, показатель интеллектуальной лабильности, показатель социометрического статуса и др.
Измерения в психологических исследованиях не являются самоцелью, это способ получения новой дополнительной информации, а она нужна для описания изучаемых психологических явлений или процессов, предсказания направлений и тенденций их возможного изменения.
Последовательность работы психолога, исследующего конкретные психологические явления или процессы по статистической обработке эмпирического материала, систематизации и анализу эмпирических (опытных) данных, представляется следующей: прежде всего, необходимо четко выделять исследуемые свойства, качества (например, дать точное определение той или иной исследуемой черты характера, профессионально важного качества человека); выбрать надежно различимые градации (признаки) этих свойств, т. е. установить единицы измерения данного свойства; осуществить приписывание исследуемым качествам или их свойствам чисел (принятых за единицу измерения), которые позволят либо классифицировать, упорядочить измеряемые объекты по указанным свойствам, либо ранжировать их по степени выраженности этих свойств. Для этого используются различные статистические величины: условные баллы, ранги значимости исследуемых величин, факторные «веса» и пр.; измерить на основе избранных единиц счета изучаемое свойство или качество; провести статистическую обработку полученных психологи-ческих показателей.
Результаты статистического материала, собранного по предмету обследования, должны быть соответствующим образом проанализированы с методологических и психологических позиций. Для этого необходимо установить тип измерительной шкалы и допустимые преобразования входящих в нее статистических значений.
В основу классификации измерительных шкал положен признак метрической детерминиро-ванности американского психолога . В соответствии с этим признаком измеритель-ные шкалы принято подразделять на неметрические (шкалы наименований, шкалы порядка) и метрические (шкалы интервалов, шкалы отношений).
Шкалы качественных признаков.
1. В шкале наименований (другое название — номинативной) при фиксации качественной информации допустимым является установление соответствующего признака тому или иному классу. Примером номинативной шкалы является дихотомическая шкала, состоящая всего из двух ячеек, например: эксперт "проголосовал "за" или "против". Признак, который изменяется по дихотомической шкале наименований, называется альтернативным. Более сложный вариант номинативной шкалы - классификация из трех и более ячеек, например: "выбор кандидатуры
А - кандидатуры Б - кандидатуры В - кандидатуры Г". При этом между группами признаков может устанавливаться статистическая связь (корреляционный анализ). Однако взаимосвязь между измеряемыми признаками может отсутствовать (табл. 11).
Таблица 11
Пример шкалы наименований
Руководители | Стиль руководства | ||
авторитарный | демократический | либеральный | |
Иванов | + | ||
Петров | + | ||
Сидоров | + |
Для анализа связи данных, измеренных по шкале наименований, чаще всего применяются следующие коэффициенты корреляции: а) коэффициенты 2 × 2 (4-х) клеточной сопряженности (коэффициент контингенции Q; коэффициент ассоциации Φ); б) коэффициенты m x n (много-клеточной) сопряженности (коэффициент взаимной сопряжённости Пирсона С; коэффициент взаимной сопряженности Чупрова К).
При выявлении распределений в классах возможно определение абсолютных и относи-тельных частот встречаемости признаков, определение моды и медианы.
1. В шкале порядков допустимо расчленение совокупности признаков на элементы, связан-ные отношениями: «больше-меньше» (табл. 12).
Таблица 12
Пример шкалы порядков
Результат по тесту | Сильные стороны | Ранг | Обратный ранг | Слабые стороны | |
А | 10 | Способность управлять собой | 3 | 5 | Неумение управлять собой |
Б | 5 | Четкие личностные ценности | 4 | 4 | Размытость личностных ценностей |
В | 11 | Четкие личные цели | 2 | 6 | Смутные личные цели |
Г | 1 | Продолжающееся саморазвитие | 7 | 1 | Остановившееся само-развитие |
Д | 13 | Хорошие навыки решения проблем | 1 | 7 | Недостаточность таких навыков |
Е | 3 | Творческий подход | 6 | 2 | Недостаток творческого подхода |
Ж | 4 | Умение влиять на окру-жающих | 5 | 3 | Неумение влиять на окру-жающих |
Оценки экспертов чаще всего оформляются в порядковой шкале, т. к., например, при экспертном опросе специалисту легче отвечать на вопросы качественного, сравнительного харак-тера (Иванов предпочтительнее Петрова), чем количественного. При статистической обработке эмпирического материала возможны определение медианы распределения, вычисление коэффи-циентов ранговой корреляции.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
