

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица 3
Металл | Фон | Пластик | Керамика |
1 | 2 3 | 3 | 4 |
|
|
|
|
|
|
|
|
|
|
|
|
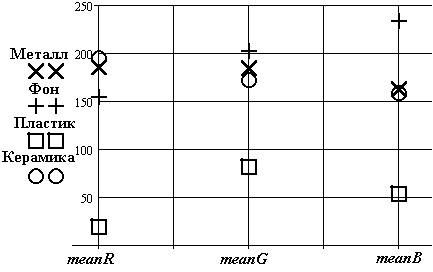
Рис.17. Оценка величин математического ожидания
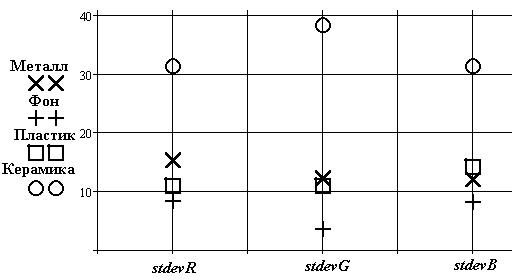
Рис.18. Оценка величин среднеквадратического отклонения
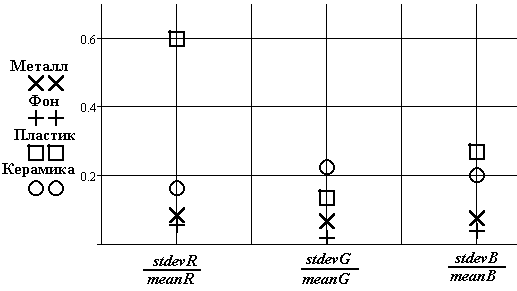
Рис.19. Оценка относительных величин среднеквадратического отклонения
Абсолютные значения сигналов редко на практике используются в качестве координат пространства исходов. Они зависят от множества факторов – освещенности и т. п. Поэтому рассмотрим более стабильные параметры, для чего разделим цветовые компоненты сигналов на суммарный сигнал на объекте и определим доверительные интервалы существования объектов в пространстве исходов.
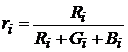 ;
;
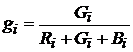 ;
;
где ![]() - 1-4 порядковый номер объекта.
- 1-4 порядковый номер объекта.
На рис. 20 и рис. 21 приведены графики доверительных зон по ![]() и
и ![]() компонентам раздельно.
компонентам раздельно.
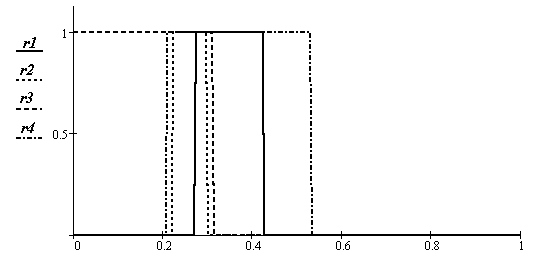
Рис.20. Оценка доверительных интервалов нормированного красного
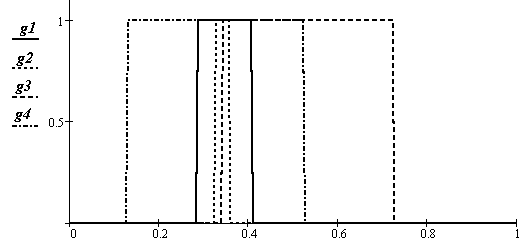
Рис.21. Оценка доверительных интервалов нормированного зеленого
Интегральные зоны показаны на рис. 22 и рис. 23. На первом из них не учитывается понижение вероятности появления обеих признаков на краю зон, в этом случае описание зон существования объектов имеет вид прямоугольников. Более правильное их представление – упрощенными эллипсоидами рассеяния показано на втором рисунке. Номера параметров соответствуют номерам объектов в таблицах 2, 3.
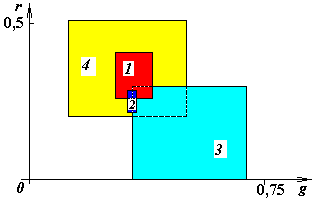
Рис.22. Оценка доверительных интервалов с предположением равномерной вероятности появления признака у объекта по всему доверительному интервалу
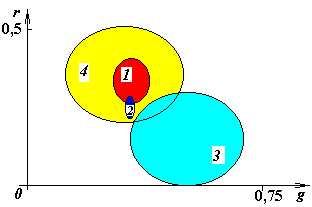
Рис.23. Оценка доверительных интервалов при понижающейся к границе интервала вероятности появления признака у объекта
Приведенный пример пробного, прикидочного исследования признаков объектов не свободен от ряда упрощений и неточностей.
Рассмотрим их в ходе рекомендуемой методики проведения исследований положения объектов, классов в пространствах признаков и ситуаций.
1. Определитесь с целью исследования – формализуйте задачу. Это важный этап, он может привести к, так называемым, системным ошибкам в постановке и решении задачи. Исправить последствия этих ошибок чрезвычайно сложно, практически решение задачи придется начинать заново. В рассматриваемом примере мы ставим задачу распознавания четырех объектов по RGB описаниям их пикселей с телекамеры низкого качества.
2. Наберите достаточный статистический материал об объектах рассматриваемых классов. Мы ограничились выборкой 600 слитных точек с объектов. Практически взято по одному зашумленному сегменту без фильтрации (результат хорошо виден на примере объекта №4 - керамический корпус в сегменте соседствует с металлической пластиной). Такой выбор возможен только при поверхностном анализе. В практике распознавания объектов по их изображениям число точек включаемых в анализ превышает сотни тысяч, а главное их необходимо брать с различных объектов исследуемого класса, в различных условиях наблюдения и освещения. Практическая рекомендация – информация с одного экземпляра объекта только одно измерение, пусть при этом проанализировано несколько тысяч пикселей. Корреляция между параметрами точек на объекте достаточно велика и это делает отсчеты зависимыми.
3. Постройте гистограммы и по их виду сделайте оценку формы функций распределения, рассчитайте рабочие функционалы, планируемые в алфавит признаков. Стремитесь использовать мало зависящие от внешних условий параметры. Мы выбрали в признаков ![]() ,
, ![]() ,
, ![]() описания и их среднеквадратичные отклонения, для справки вычислили относительные величины.
описания и их среднеквадратичные отклонения, для справки вычислили относительные величины.
4. Постройте доверительные интервалы существования объектов классов в пространстве признаков. Современные компьютеры, математические пакеты позволяют проводить довольно большие объемы исследований в короткие сроки. Наиболее просто для визуального анализа отобразить положение классов в пространстве двух признаков.
5. Если области существования классов пересекаются увеличьте количество признаков измените существующие. На рис. 22 объекты классов практически не различимы по выбранным признакам.
На рис. 24 представлены области существования классов по измененным признакам. В качестве последних выбраны выражения
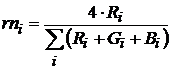 ,
,
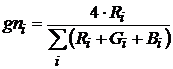 ,
,
что практически означает нормировку по интегральному световому потоку со всех объектов. На рис. 24 представлен результат – класс пластиковых корпусов (№3) в данном пространстве резко выделен и различим.
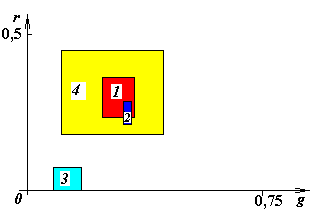
Рис.24. Оценка доверительных интервалов с предположением равномерной вероятности появления признака у объекта по всему доверительному интервалу и нормировкой по общему световому фону
Необходимо учитывать то, что формализованные алгоритмы стандартных расчетов даже на объемных массивах данных в тысячи пикселей выполняются в миллисекунды, поэтому рабочий алфавит признаков может содержать несколько десятков компонентов. Все полученные значения ожидаемых оценок случайных величин – каждый столбик гистограммы, оценки центральных моментов сами по себе случайные величины. Для корректного использования они должны удовлетворять определенным требованиям, вернее стремиться соответствовать им:
Ÿ При увеличении числа испытаний они должны стремиться к истинной величине параметра, с ростом объема данных ![]() разница между искомым значением и расчетным -
разница между искомым значением и расчетным - ![]() должна становиться сколь угодно малым числом (
должна становиться сколь угодно малым числом (![]() при
при 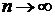 ). Такие оценки получили название состоятельных.
). Такие оценки получили название состоятельных.
Ÿ Оценка считается несмещенной, если она не содержит систематических составляющих погрешности Оценка должна быть эффективной т. е. обеспечивать минимальный разброс в оценке искомой величины в заданном объеме исследований.
Первое требование не всегда можно обеспечить так как эргодических случайных описаний образов на практике не так много. Окружающий нас мир непрерывно развивается и практически все свойства объектов имеют определенную тенденцию изменения значений (тренд). Поэтому наибольший вес в анализе имеют “свежие” данные.
Важной спецификой в анализе исходных данных в принятии решений является и очень большой объем возможной информации, можно потратить жизнь изучая специфику изображений определенного класса, например, бровей на лице человека, выбирая все большее количество объектов. Это с одной стороны.
С другой стороны достаточно в течении нескольких часов проанализировать несколько десятков реализаций, что бы вложить стартовый материал в систему распознавания лиц форму бровных дуг в рабочий алфавит.
В развивающейся интеллектуальной системе компоненты алфавита признаков непрерывно корректируются, при этом вес последней информации, как правило, выше веса данных более ранних.
Аппаратное вычисление параметров закона распределения, плотности распределения одна из традиционных основных составных частей математической статистики. Специфика ПР и РО конкретизирует решение данной задачи. При анализе статистического ряда 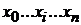 рекомендуется следующая последовательность действий:
рекомендуется следующая последовательность действий:
Ÿ определение математического ожидания ![]() ;
;
Ÿ определение среднеквадратичного отклонения ![]() ;
;
Ÿ прореживание статистического ряда;
Ÿ задание метрики оси абсцисс и числа каналов;
Ÿ подсчет чисел событий попавших в каналы;
Ÿ при близости полученной гистограммы к известным законам
распределений заменяют исследуемую гистограмму известной кривой распределения.
Отметим специфику некоторых из перечисленных операций.
При прореживании статистического ряда удаляются недостоверные отсчеты с номером ![]() , таких что
, таких что 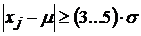 , на практике не редко их не удаляют, а перемещают в ближайшую точку доверительного интервала, это позволяет сохранить метрику сетки последовательных отсчетов, что важно при проведении корреляционных, спектральных исследований.
, на практике не редко их не удаляют, а перемещают в ближайшую точку доверительного интервала, это позволяет сохранить метрику сетки последовательных отсчетов, что важно при проведении корреляционных, спектральных исследований.
Количество каналов анализа задается исходя из соображений по - требуемой компактности описания конкретного класса, реального объема выборки, потерь от недостоверного определения формы функции плотности вероятности.
Вычислительная нагрузка возрастает в квадратичной степени или более резко от увеличения объема описания классов. Конкретный вид зависимости определяется сложностью алгоритмов распознавания.
Число событий попавших в канал является в каждом эксперименте случайной величиной и величина ее доверительного интервала зависит от числа событий принимающих участие в эксперименте, а положение его еще и от параметров, вида функции плотности распределения вероятности исследуемого события.
При малом числе испытаний определение доверительного интервала наиболее корректно через биноминальный закон распределения - закон Пуассона.
На рис. 25, 26, 27 приведены графики плотностей распределения этого закона для различных длин каналов анализа и различных чисел опытов. События не зависимы.
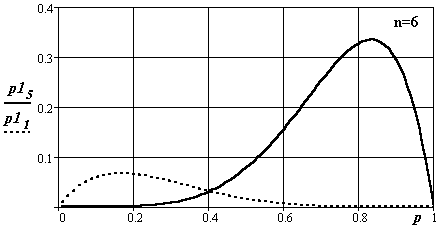
Рис.25. Вид плотности распределения вероятности появления событий в каналепри числе опытов 6 для длин интервалов подсчета 5 и 1
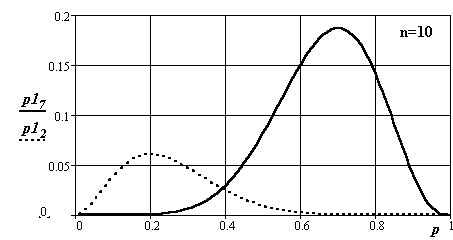
Рис.26. Вид плотности распределения вероятности появления событий в канале
при числе опытов 10 для длин интервалов подсчета 2 и 7
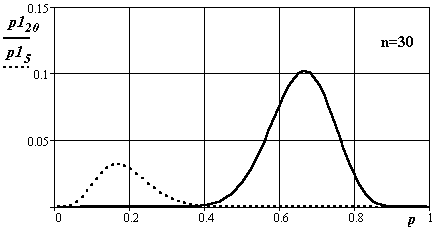
Рис.27. Вид плотности распределения вероятности появления событий в канале при числе опытов 30 для длин интервалов подсчета 20 и 5
Исследуемый процесс подчинен равномерному закону распределения и может принимать значения от 0 до n. Индексы при p1. Величина отношения значения индекса к n – искомая вероятность.
Во всех случаях математические ожидания, полученные в экспериментах, совпадают с искомыми. С ростом числа экспериментов дисперсии определения оценок плотности вероятности уменьшаются. Изменяется и вид кривых распределения – они становятся симметричней и приближаются по форме к нормальному распределению.
Реально при n > 10 целесообразнее в силу его простаты и распространенности пользоваться графиками нормального закона.
Центральная предельная теорема (ЦПТ) в теории оценок говорит о том, что при большом числе случайных явлений их средние характеристики перестают зависеть от каждого отдельного явления и получают устойчивость т. е. перестают быть случайными. Пользуясь ими можно распознавать случайные явления и предсказывать поведение случайных процессов. Для сумм случайных отсъемов, фигурирующих в оценках функций распределения и их параметров можно записать:
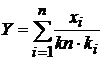 ,
,
где ![]() -
- ![]() номера отсчетов,
номера отсчетов, ![]() ,
, ![]() - нормировочный, и весовой коэффициенты учета отсчета в итоговой сумме.
- нормировочный, и весовой коэффициенты учета отсчета в итоговой сумме.
![]() .
.
Математическое ожидание и дисперсия случайной величины для независимых по ЦПТ равны:
![]() ,
,
![]() ,
,
Для ![]() и
и 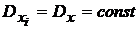
![]() ,
,
![]() ,
,
![]() ,
,
а среднее квадратичное отклонение оценки величины ![]() уменьшается с ростом
уменьшается с ростом ![]()
![]() .
.
Усреднение лежит в основе подавляющего числа исследований в вообще и определения зон существования классов в пространстве признаков.
На первый взгляд различные по величине ![]() отсчеты не так уж часты. Но в практике интеллектуальных систем при самообучении новая информация и та, что отражает накопленный опыт соседствуют рядом. Новая информация имеет большую достоверность, чем предыдущие отсчеты того же объема. Тем не менее оценка на основании накопленного опыта, в следствии интеграции качественно большего объема данных, характеризуется высокой достоверностью. При этом дисперсии могут разнятся на несколько порядков. Однако накопленный опыт не содержит детальной предыстории. Один из простейших выходов из ситуации, но довольно рациональный, это эволюционная корректировка данных, например, с
отсчеты не так уж часты. Но в практике интеллектуальных систем при самообучении новая информация и та, что отражает накопленный опыт соседствуют рядом. Новая информация имеет большую достоверность, чем предыдущие отсчеты того же объема. Тем не менее оценка на основании накопленного опыта, в следствии интеграции качественно большего объема данных, характеризуется высокой достоверностью. При этом дисперсии могут разнятся на несколько порядков. Однако накопленный опыт не содержит детальной предыстории. Один из простейших выходов из ситуации, но довольно рациональный, это эволюционная корректировка данных, например, с
![]() .
.
Изложенный подход используется при определении всех параметров законов распределения и его вида.
При определении дисперсии уменьшают делитель на единицу, отображая тот факт, что число независимых данных при расчете дисперсии меньше на единицу общего количества отсчетов.
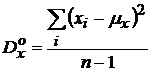 .
.
Эта оценка не смещенная. Дисперсия оценки величины дисперсии
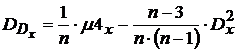 ,
,
где ![]() - четвертый центральный момент, зависящий от вида закона распределения, для нормального закона распределения
- четвертый центральный момент, зависящий от вида закона распределения, для нормального закона распределения 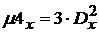 и
и 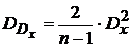 , для равномерного
, для равномерного 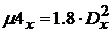 и
и 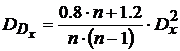 .
.
Если вид закона распределения не известен то используют методику определения величины доверительного интервала через параметры закона распределения Стьюдента. В этом случае абстрагируются от параметров закона распределения, а ориентируются только на число опытов и заданную из вне вероятность появления события в доверительном интервале. Величина доверительного интервала тогда
![]() ,
,
где 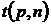 - коэффициент Стьюдента. Данный коэффициент находится из одноименного закона распределения исходя из заданной величины вероятности попадания в доверительный интервал. Вид плотности распределения для числа степеней свободы
- коэффициент Стьюдента. Данный коэффициент находится из одноименного закона распределения исходя из заданной величины вероятности попадания в доверительный интервал. Вид плотности распределения для числа степеней свободы ![]()
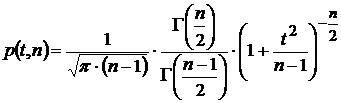 ,
,
где ![]() - гамма функция. Интегральное распределение задает величину доверительного интервала.
- гамма функция. Интегральное распределение задает величину доверительного интервала.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
