

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
На рис. 28, 29 показано влияние заданной величины вероятности промаха от числа опытов и значения коэффициента.
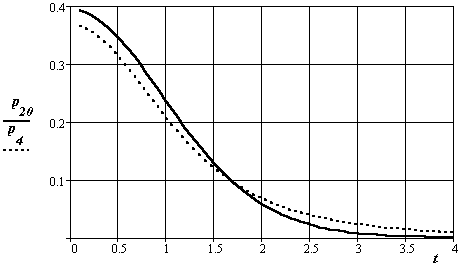
Рис.28. Вид плотности распределения вероятности Стьюдента в зависимости от величины коэффициента и числа опытов (индекс 20 и 4)
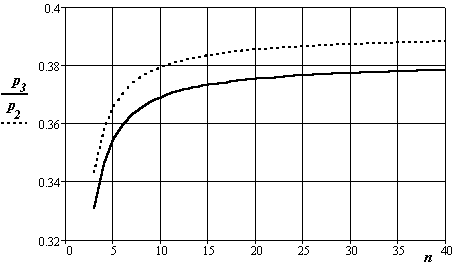
Рис.29. Изменение участка распределения вероятности Стьюдента в зависимости от величины коэффициента (индекс 3 и 2) и числа опытов
Графики повторно показывают практическое снижение влияния числа опытов на вид закона распределения величины оценки доверительного интервала при числе независимых отсчетов более 10.
Гистограмма оценивает вероятность появления события в определенной зоне пространства признаков.
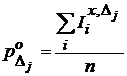 ,
,
где ![]() - индекс появления события на участке
- индекс появления события на участке ![]() в отсчете
в отсчете ![]() , он равен 1 при появлении события на участке и нулю если был промах. Данная оценка не смещенная. Ее дисперсия
, он равен 1 при появлении события на участке и нулю если был промах. Данная оценка не смещенная. Ее дисперсия
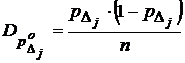 .
.
Выше приведенные выражения работают строго только для независимых отсчетов, отстоящих друг от друга на расстоянии большим, чем радиус корреляции.
Корреляционный анализ случайных величин является одним из важных разделов математической статистики. Он широко используется уже в течение многих десятилетий. Большие возможности применения корреляционных представлений в физических и технических науках открылись с возникновением корреляционного анализа случайных функций, которое можно отнести к 1920г., когда Тэйлор ввел понятие корреляционной функции. Очень важное значение имело установление в 30-х годах Н. Винером и связи между корреляционными и спектральными характеристиками случайных процессов. Разработка теории информации, сформировавшейся к концу 40-х годов, показала, что количество информации, заключенной в сигнале, существенно зависит от корреляционных свойств.
Реально встречающиеся случайные функции очень часто можно считать нормальными, а каждая нормальная случайная функция может быть полностью описана в рамках корреляционной теории. В то время и для случайных функций, не являющихся нормальными, эта теория дает ответ на целый ряд важных вопросов. Выделим два направления по использованию аппарата корреляционного анализа:
Ÿ применение корреляционных функций и их параметров в качестве характеристик идентифицирующих сигналы,
Ÿ применение корреляционных функций в качестве характеристик идентифицирующих системы передачи информации.
К первому из указанных направлений можно отнести исследования, относящиеся к распространению волн, в том числе радиоволн, звуковых волн, исследование шумов различной физической природы, статистических свойств изображений; анализ отдельных звуков речи и слогов; применение в геофизике и метеорологии; применение в биологических и медицинских исследованиях и т. д.
Во второй группе ведущее место занимает экспериментальное определение корреляционных характеристик объектов; оно позволяет выяснить динамические свойства объектов по данным их нормальной работы без применения каких-либо искусственных возмущений и играет весьма важную роль при проектировании систем. К этой же группе относятся корреляционные методы снижения влияния искажений, вносимых при передаче сигнала, оценки качества переходных процессов в линейных системах; исследования акустических характеристик помещений, измерения звукоизоляции и звукопоглощения; определения частото-контрастных характеристик систем наблюдения.
Уже приведенный здесь беглый перечень дает представление о значении и достаточно широком распространении корреляционного анализа.
В курсе наибольшее внимание уделяется распознаванию объектов по форме и параметрам взаимно корреляционных функций между исследуемым объектом и эталонами классов.
Величина корреляционной функции может быть представлена следующим образом:
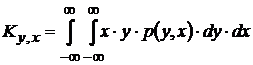 ,
,
или расширив пространство исходов временными осями процессов (![]() ,
, ![]() ) получим
) получим
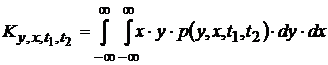 .
.
Положив ![]() , получим автокорреляционную функцию процесса
, получим автокорреляционную функцию процесса ![]() . Таким образом, автокорреляционную функцию можно рассматривать как частный вид взаимной корреляционной функции.
. Таким образом, автокорреляционную функцию можно рассматривать как частный вид взаимной корреляционной функции.
Автокорреляционные и корреляционные функции зависят как от степени взаимосвязанности случайных процессов, так и от дисперсии этих процессов. Для того чтобы получить меру взаимосвязанности, абстрагированную от величин дисперсии, производят нормирование корреляционных функций. Нормированные корреляционные функции называют коэффициентами корреляции:
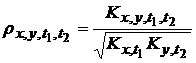 .
.
В практике широко используется представление описаний классов в производных пространствах. Наиболее широко рассматриваются поиск отличительных признаков объектов в области пространственных частот. На рис. 30 представлены модуль частотного спектра изображения рамки и на рис. 31 его сечение. Видны четко участки преобладающих частот, которые можно использовать как признаки.
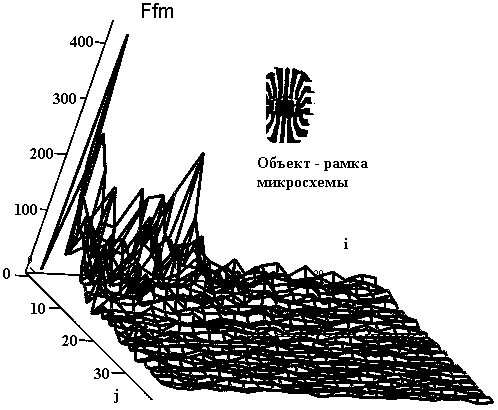
Рис. 30. Фурье образ R составляющей сегмента рамки
С учетом корреляционных соотношений и понятий верхних и нижних частот (временных для случайных процессов, пространственных для объектов в 3 мерном пространстве) уточним понятия оценки дисперсии параметров случайной величины.
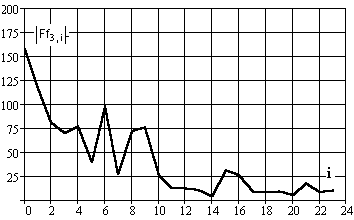
Рис. 31. Сечение Фурье образа R составляющей сегмента рамки
Для оценки математического ожидания, получаемой накоплением данных за временной интервал ![]()
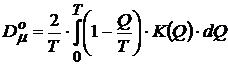 .
.
Здесь связь с корреляционной функцией. Довольно часто
![]() ,
,
где ![]() ,
, ![]() ,
, ![]() параметры характеризующие размах, скорость спада частоту колебаний корреляционной функции.
параметры характеризующие размах, скорость спада частоту колебаний корреляционной функции.
Для вычисления ![]() с погрешностью менее 5% от
с погрешностью менее 5% от ![]() необходимо интегрировать данные не менее
необходимо интегрировать данные не менее
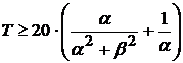 .
.
Например: при ![]() =0,2
=0,2 ![]() ,
, 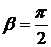
![]()
![]() 102 с.
102 с.
Реально данные поступают дискретно с интервалом ![]() (во времени, в геометрическом пространстве и т. п.)
(во времени, в геометрическом пространстве и т. п.)
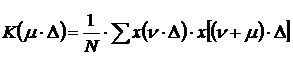 ,
,
где ![]() =1, 2, ... и
=1, 2, ... и ![]() =1, 2, ... слагаемые номера отсчета.
=1, 2, ... слагаемые номера отсчета.
Для 2% точности вычисления корреляционной функции необходимо
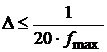 , часто выбирают
, часто выбирают 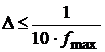 , или
, или 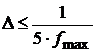 ,
,
где ![]() - максимальная частота важная для анализа и учета.
- максимальная частота важная для анализа и учета.
2.4. Распознавание в математической статистике
Два раздела математической статистики тесно связаны с процедурой распознавания:
Ÿ определения вида и параметров функциональной зависимости между случайными событиями и их сочетаниями;
Ÿ проверка статистических гипотез, в ходе которой выбирается вид закона распределения наиболее подходящий для описания исследуемого события, определяются его параметры и устанавливается степень согласия принятых решений с реальным объектом.
Статической называют зависимость, при которой изменение одной из величин влечет изменение распределения другой. В частности, статистическая зависимость появляется в том, что при изменении одной из величин изменяется среднее значение другой; в этом случае статическую зависимость называют корреляционной.
Зависимость между двумя и более случайными событиями из множеств ![]() ,
, ![]() можно представить в общем виде
можно представить в общем виде
![]() ,
,
где ![]() - множество параметров
- множество параметров 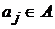 .
.
Рассмотрим простейший случай. Пусть реальные отсчеты в ![]() - том эксперименте порождают наборы результатов
- том эксперименте порождают наборы результатов ![]() и
и ![]() (
(![]() ), между которыми предполагается наличие связи
), между которыми предполагается наличие связи 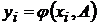 .
.
Будем искать такие ![]() , которые минимизируют функционалы отклонений (ошибок) предсказания величины
, которые минимизируют функционалы отклонений (ошибок) предсказания величины ![]() по значениям
по значениям ![]() .
.
В качестве рабочего функционала ошибки примем сумму квадратов отклонений
![]() .
.
Будем искать решение в точках экстремума для чего дифференцируем выражение по компонентам вектора ![]() .
.
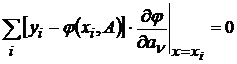 ,
,
где ![]() =1...
=1...![]() .
.
Это ![]() нелинейных уравнений и в общем случае они аналитически не решаются.
нелинейных уравнений и в общем случае они аналитически не решаются.
Для поиска линейной зависимости между двумя величинами решение существует.
![]() ,
,
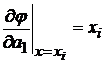 ,
,
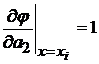 ,
,
![]() ,
,
![]() .
.
Решая систему уравнений находим
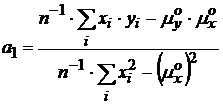 ,
,
![]() ,
,
где ![]() - оценки математических ожиданий.
- оценки математических ожиданий.
Задавая исходный участок по ![]() не большим по размеру и расширяя его с проверкой постоянства параметров
не большим по размеру и расширяя его с проверкой постоянства параметров ![]() (через их положение в доверительном интервале оценок) можно получить кусочно-линейную оценку функциональной зависимости для большинства случаев анализа компонентов пространства признаков. При нарушении постоянства
(через их положение в доверительном интервале оценок) можно получить кусочно-линейную оценку функциональной зависимости для большинства случаев анализа компонентов пространства признаков. При нарушении постоянства ![]() (при выходе за пределы доверительного интервала) вводится новый участок.
(при выходе за пределы доверительного интервала) вводится новый участок.
Реально аналитические выражения существуют и для квадратичного вида зависимости.
Проверка статистических гипотез предполагает оценку вероятности и достоверности принадлежности закона распределения рассматриваемой случайной величины одному из известных. При этом такие понятия, как доверительный интервал оценки плотности распределения вероятности по полученной гистограмме работает и в этом случае.
Совокупность известных и включенных в описание гистограмм составляют набор классов.
Проведенные исследования добавляют в рассмотрение новую гистограмму, которая может быть отнесена к известному классу.
Такой подход стандартен в составление описания классов, т. е. часть описания класса может быть заменена ссылкой - именным индексом на известные описания свойств одного из классов.
Для примера воспользуемся генератором случайных чисел и сгенерируем вектор из 1000 чисел. Найдем разницу в оценке гистограммы реализации ![]() (рис. 32) и теоретического распределения
(рис. 32) и теоретического распределения ![]()
(рис. 33).
|
|
Рис. 32. Нормированная гистограмма вектора из 1000 чисел, распределенных по нормальному закону |
Рис. 33. Плотность распределения с параметрами исследуемого вектора |
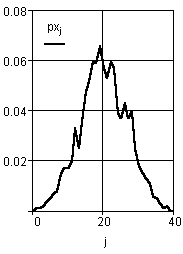
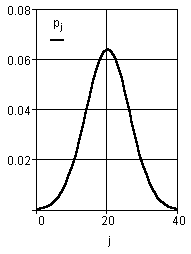
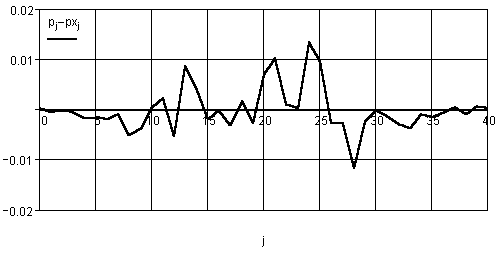
Рис. 34. Погрешность отнесения гистограммы реального вектора к теоретическому закону
График разности приведен на рис. 34. Вычислим интегральную оценку ошибки по формуле
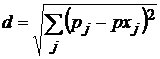 .
.
Расчетная величина ![]() 0,03.
0,03.
Из приведенного примера можно сделать вывод о том, что реальная погрешность представления гистограммы случайного вектора чисел теоретической гистограммой или одной из известных всегда будет иметь место.
Методика определения подходит или нет один из имеющихся в базе данных классов гистограмм для исследуемого класса может быть представлена последовательностью следующих шагов:
1. Вычисляем нормированную гистограмму исследуемого вектора данных (нормировка заключается в делении чисел в каналах на общее число учтенных реализаций).
2. Генерируем известные графики распределений.
3. Определяем разность между гистограммой исследуемого вектора и известными.
4. Определяем метрику риска или потери полезности и вычисляем интегральный параметр ошибки.
5. По ![]() (где -
(где - ![]() индекс класса) данного параметра выбираем искомый класс
индекс класса) данного параметра выбираем искомый класс ![]() .
.
6. Проверяем на допустимость ошибки, если ошибка не допустима формируем описание исследуемого класса с новой формой функции распределения, внося ее в базу данных распределений.
Если ошибка допустима проверяем гипотезу статистической достоверности принадлежности реализации случайной величины к известным по форме и параметрам законам распределения.
Для проверки формы функции обычно используют критерии согласия Пирсона или Колмогорова. Проверка гипотез о значении параметра функции распределения заслуживает в нашей теме более детального рассмотрения.
Для простоты, задачу о параметре ![]() функции распределения
функции распределения ![]()
![]() - мерной случайной величины
- мерной случайной величины ![]() (
(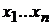 ) рассмотрим, как проверку двух гипотез
) рассмотрим, как проверку двух гипотез ![]() и
и ![]() .
.
При этом 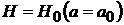 и
и ![]() .
.
Все пространство исходов разбивается на две не пересекающиеся области ![]() ,
, ![]() , в которых наиболее целесообразны решения
, в которых наиболее целесообразны решения ![]() и
и ![]() . Пространство решений полное т. е.
. Пространство решений полное т. е. ![]() .
.
При распознавании образов под искомым параметром понимается, как правило, физическая величина, например, выход изделия в брак, наличие или отсутствие примеси, сигнал или шум в локации и т. д.
Отношение правдоподобия или коэффициент правдоподобия определяется по формуле
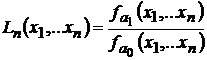 ,
,
где ![]() вероятность того, что при конкретной реализации
вероятность того, что при конкретной реализации ![]() имеет место событие
имеет место событие ![]() .
.
Вывод о событии ![]() делается если
делается если ![]() , где
, где ![]() - порог принятия решения.
- порог принятия решения.
Реально величина порога зависит от многих факторов и прежде всего от допустимой вероятности принятия не правильного решения.
Ошибка первого рода - принимается решение ![]() , а это
, а это ![]() , обозначим вероятность такого решения.
, обозначим вероятность такого решения.
Ошибка второго рода - принимается решение ![]() , а это
, а это ![]() , обозначим вероятность такого решения
, обозначим вероятность такого решения ![]() .
.
Часто данные ошибки имеют символьное описание, например в локации пропуск цели, ложная тревога или в промышленности риск изготовителя (отбраковано хорошее изделие), риск потребителя (получен брак). Очевидно продолжение испытаний (рост ![]() ) приводит при слабо коррелированных
) приводит при слабо коррелированных ![]() к понижению
к понижению ![]() и
и ![]() . Т. е. порог принятия решения в общем случае является функцией платы за ошибочные решения, допустимой вероятности ошибки первого или второго рода и числа испытаний
. Т. е. порог принятия решения в общем случае является функцией платы за ошибочные решения, допустимой вероятности ошибки первого или второго рода и числа испытаний ![]() ,
, ![]() ,
, 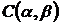 . Задание такого порога при ограничении на
. Задание такого порога при ограничении на ![]() или
или ![]() позволяет минимизировать
позволяет минимизировать ![]() . При заданном
. При заданном ![]() минимизировать
минимизировать ![]() или
или ![]() .
.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
