

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Однако главной целью исследователей, работающих в области анализа выражений лица, является разработка математической модели лица и его микродвижений, которая бы достаточно точно отражала реальную мимику лица.
То, что человеческое лицо является совершенным сигнальным устройством, и с него можно "считать" много полезной информации о его обладателе, является общеизвестным фактом. И хотя анализ лицевых выражений и определение таких характеристик объекта, как пол, раса, возраст и им подобных, можно было бы объединить в одну проблему, имеется разница в подходах. Кроме того, к задачам последнего типа можно отнести и определение характеристик непосредственно самого изображения лица, например степени симметрии лица, относительно вертикальной оси.
Разработанные для определения характеристик подходы могут быть использованы и для решения других задач. Так, например, Вискотт для определения по изображению человека таких признаков, как пол, наличие бороды и очков, использует метод сопоставления графов. В нескольких сотнях экспериментов процент корректного распознавания различных характеристик человеческого лица составил от 83 до 96%. Алгоритмы определения пола, основанные на нейронных сетях, демонстрируют схожие результаты распознавания - 87,5% и 91,9% .
Определение же оси симметрии лица для Эшме, Санкура и Ана-рима является лишь одной из подзадач по предобработке исходного изображения. В дальнейшем они используют эту информацию для корректировки работы алгоритма поиска координат черт лица.
Рассматривается проблема выбора ограниченного набора собственных векторов и его применения в распознавании пола и других признаков человека.
В ряде решений перед процедурой распознавания проводят плавную трансформацию изображений 3D объектов на примере лица человека.
Задача плавной трансформации может быть разбита на три подзадачи. Первая - выделение и установление точек соответствия между двумя заданными изображениями либо объектами. Это наиболее сложная часть данного процесса. Вторая - определение или конструирование морфологической функции, отображающей множество точек, выделенных на предыдущем этапе из первого изображения, в такое же множество, выделенное для второго изображения. И третья подзадача - это плавное изменение значений пикселей двух изображений с целью создания нескольких промежуточных изображений.
Разработки в данной области представляют собой частные случаи решения более общей задачи машинной графики по плавной трансформации изображения одного объекта в изображение другого. И хоть имеется множество программных продуктов, позволяющих добиваться высококачественных видеоэффектов (телевизионная реклама, музыкальные клипы и т. д.), исследования в данной области продолжаются. Их основная цель - разработка более гибких, простых и быстрых алгоритмов, а также изучение возможности их применения в других задачах, связанных с анализом изображений лиц. Кроме того, одной из наиболее исследуемых проблем в данной области является поиск эффективного алгоритма определения характерных черт изображения, которые и обусловливают выбор точек соответствия. Особенно актуален этот вопрос при необходимости трансформации одной в другую двух заданных последовательностей изображений. В настоящее время скорость работы систем, трансформирующих изображение друг в друга, достаточно высока и осуществляется в реальном времени.
Задача поиска лиц в толпе – обнаружение осуществляется "вырезанием" из кадра областей, близких по признакам к изображениям лиц.
Данная задача является, по сути первым этапом полностью автоматизированного процесса распознавания человека в случае, когда идентификация личности происходит по изображениям, при создании которых данная цель не преследовалась либо возможности съемки были ограниченными (непрофессионально сделанные изображения, съемка скрытой камерой, видео кадры и т. п.).
После этого вырезанные области сравниваются с эталонами лица человека. Автоматическое выделение области лица на фотографии является одним из обязательных шагов по нормализации изображений, общая достоверность распознавания превышает 97%, что говорит о приемлемом качестве.
К данному классу исследований можно отнести и работу By, Чена и Яшиды, результатом которой явилось построение системы проверки лиц; т. е. системы, которая устанавливает, действительно ли фрагмент изображения является человеческим лицом или же представлены просто похожие на него объекты. Когда данная система получает предполагаемое изображение лица, то из изображения сначала выделяются контуры. Затем система устанавливает приблизительные регионы поиска черт лица путем выявления зон, где средняя плотность горизонтальных краев высока. При помощи метода интегральных проекций уточняются координаты каждой зоны. Полученные данные проверяются сравнением с геометрической моделью лица и в итоге определяется, является ли данная часть изображения действительно лицом или нет.
Одна из наиболее интересных и требующих эффективного решения задач - это автоматическое определение точных координат ряда характерных антропометрических точек (уголки глаз, кончик носа, уголки губ и т. д.). Отличительной особенностью данной задачи является существенное различие изображений таких элементов лица, как глаз, нос, рот, которым эти точки принадлежат. Иными словами, проблема состоит в том, что характеристики изображения каждого участка человеческого лица (глаз, носа, контура лица и т. д.) настолько различны, что для решения всей задачи в целом приходится разрабатывать отдельный подход к выделению каждой черты лица. Точность выделения указанных участков лица существенно влияет на достоверность распознавания всей системы в целом.
Как правило, каждый метод включает два этапа: определение прямоугольных окон поиска и нахождение точных координат характерных точек внутри выделенных фрагментов. Приведем несколько конкретных примеров.
Для получения координат окон для поиска носа и рта Брунелли и Поджио применяют метод интегральных проекций. Из исходного изображения лица получают две интегральные проекции - горизонтальную и вертикальную. Делается это следующим образом: пусть I(x, y) - исходное изображение, тогда вертикальная и горизонтальные проекции изображения 1(х, у ) в квадрате с угловыми координатами [x1,y1] и [х2,у2] определяется
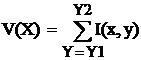 ,
, 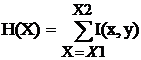 .
.
Вертикальные координаты областей носа и рта находятся с помощью антропометрических отношений частей лица человека, в то время как горизонтальные координаты получают путем анализа гистограмм интегральных проекций. На втором этапе по пикам вертикального градиента на горизонтальной проекции находят местоположение носа, а по впадинам - местоположение рта, так как линия между губами выглядит на изображениях очень темной. Границы носа оцениваются при помощи наибольших правых и левых пиков, а координаты характерных точек рта определяются подобным способом на вертикальной проекции.
Области изображений глаз Брунелли и Поджио находят принципиально другим способом - при помощи метода сравнения с эталоном.
Нахождение на изображении бровей и их толщины выполняется так же, как для носа и рта. Поиск ограничен окном, расположенным чуть выше глаз (расположение глаз уже должно быть определено), и производится с помощью вертикальной интегральной проекции. В алгоритме ищутся пики градиента интенсивности в двух противоположных направлениях. Пары пиков над одним глазом сравниваются с парами над другим и наиболее схожие выбираются как соответствующие друг другу.
При нахождении нижней границы безбородого лица (скулы, подбородок и т. д.) используют специальную эллиптическую систему координат (эллипс в данной системе представляется прямой) и таким образом им удается минимизировать вычислительные затраты на определение нижнего контура лица.
Определение черт лица с использованием геометрических моделей устраняет трудности распознавания, вызванные эмоциональным выражением и ориентацией лица. Предварительно проводят высокочастотную фильтрацию, которая подчеркивает контуры. После чего производится бинаризация, далее пиксели бинарного изображения группируются и опознаются. Ищутся глаза, которые должны находиться на одной линии, близкой к горизонтальной и расстояние между глазами приблизительно равно двум длинам глаза.
Учитывая эти, а также и другие признаки, проверяют все пары регионов и выбирают одну пару, соответствующую упомянутым условиям. После чего, основываясь на антропометрической статистике, находят относительное местоположение рта и других частей лица. Скорость работы данного алгоритма на рабочей станции SUN-20, составила около 5 с, на один портрет, причем более 70% времени тратилось на предварительную обработку.
Более быстро для определения контуров глаз и губ работает процедура, основанная на комбинации изменяющихся эталонов с генетическими алгоритмами. Эшме, Санкур и Анарим сначала находят ось симметрии лица, затем производят предобработку (выравнивание и модифицированная бинаризация), после чего вычисляют центры масс темных областей. Исходя из априорных знаний, производят отбор получившихся регионов, вычисляют энергетические поля оставшихся областей, значения которых потом используются при проверке так называемых "хромосом" на близость с соответствующей областью.
Хромосома представляет собой код нескольких величин, описывающих форму глаза или рта. Определяют также правило спаривания хромосом, после применения, которого исходные величины, представляемые каждой хромосомой, либо увеличиваются, либо уменьшаются, либо остаются неизменными. Первоначально генерируются 100 случайных хромосом, являющих собой по сути 100 разных по форме и размеру видов эталона глаза или рта. После каждой операции спаривания части хромосомы - гены - подставляются в специальные функции подгонки, которые некоторым образом изменяют сравниваемый эталон предварительно полученной области глаза или рта.
После каждой итерации выбираются четыре наиболее подходящие к оригиналу хромосомы, и все остальные делятся на четыре группы, каждая из которых затем спаривается с одной из четырех главных хромосом. После каждой итерации 10% слабых генов убирается и хромосомы пополняются случайными новыми. Таким образом, добиваются постепенного и точного сжатия эталона вокруг области глаза или рта.
И все таки лицо трехмерный объект и наиболее информативными являются 3D изображения лиц. При этом порождается множество задач распознавания трехмерных описаний моделей. На рис. 88 приведено изображение лица человека освещенное матрицей элементарных осветителей простой формы. Лучи идут под углом к прибору наблюдения. В результате формируется более сложное описание несущее информацию о глубине расположения элементов лица. Например, освещение этим же осветителем менее рельефного объекта показывает эллипсоидность его формы (рис. 89). Элементарный осветитель может иметь более сложную форму (рис. 90 – изображение площадки светодиода, направляемое на объект).
|
|
|
Рис. 88. Лицо освещенное матрицей простых зондов |
Рис. 89. Эллипсовидный объект |
Рис. 90. Сложный зонд |



Тогда в форме отклика присутствует информация (рис. 91) о углах нормали к зондируемому участку поверхности (определение деформации в направлениях ![]() ,
, ![]() позволяет получить числовые параметры углов наклона участка поверхности).
позволяет получить числовые параметры углов наклона участка поверхности).
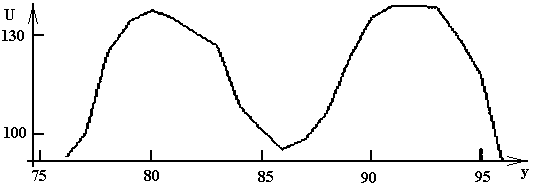
Рис. 90. Сигнал от изображения сложного зонда
Но наибольшее количество успешно проведенных работ посвящено идентификации человека по изображению его лица. Практика использования фотографий в паспортной, пропускной системах доказывают принципиальную возможность определения принадлежности снимка конкретному человеку (классу).
Обычно эту задачу рассматривают в соответствии с предназначением систем идентификации: режима реального времени и поиска изображений опознаваемого объекта в больших базах данных. Таким образом, существующие разработки можно разделить на два класса:
1. Системы идентификации объекта по фотографии в большой (00) базе изображений.
2. Системы идентификации объекта в режиме реального времени (системы наблюдения служб безопасности, обеспечения доступа небольшой группе 10-100 изображений и закрытия его для посторонних).
Как правило, системы, реализующие решение задач первого класса, возвращают ранжированный набор изображений, наиболее похожих на искомое, и выбор окончательного решения предоставляется эксперту. Номер в группе обычно соответствует степени близости выбранного изображения и сравниваемого.
Следует отметить, что по статистике в реальной базе данных, содержащей портретов, 417 человек будут иметь двойников. Так как базы содержат сотни тысяч изображений, то существующие системы работать в режиме реального времени не в состоянии. Цель - решение задачи за разумное время. Обычно допустима реакция в течении нескольких часов.
В системах второго класса изображение лица человека используется как ключ, подтверждающий либо опровергающий введенные для идентификации данные для настройки таких систем часто используется несколько фотографий одного человека. Цель - решение задачи в течение нескольких секунд, т. е. в реальном режиме времени.
С практической точки зрения разработка систем для решения задач второго типа более проста и требует меньших усилий, чем для решения задачи первого типа. Кроме того, методы первого класса, могут быть с успехом применены и в системах, работающих в режимах реального времени и реализующих решения задачи второго класса. В принципе сама процедура опознавания часто схожа.
Исходные процедуры подготовки изображений.
1.Определение размера и ориентации 3D объекта на фотографии и последующее масштабирование. Так как фотографии для распознавания могут быть непрофессиональными, то размеры лица и его ориентация на снимке могут достаточно сильно варьироваться от одного изображения к другому.
Методы обработки по-разному чувствительны к малым и существенным изменениям размеров лица и его ориентации, однако если лицо на портрете слишком мало (10х12 пикселей, например) и (или) сильно повернуто в сторону, то человека достаточно сложно распознать. В этом случае выходной набор аналогов имеет внушительный размер.
Практика показывает распознавание будет успешным, если область лица представлена зоной размерами не менее 80х120 пикселей, а отклонение лица от горизонтальной и вертикальной осей лежит в пределах ![]() 30° и
30° и ![]() 45° соответственно. Рекомендуемое минимальное разрешение составляет 2 мм на пиксель.
45° соответственно. Рекомендуемое минимальное разрешение составляет 2 мм на пиксель.
2. Корректировка освещенности. Яркость и четкость изображения очень сильно зависят от условий освещения в момент съемки. Плохие характеристики портрета могут привести к сбоям в алгоритмах бинаризации и группировки, и, следовательно, общий коэффициент распознавания системы также значительно снизится. Необходимо предусматривать дополнительные алгоритмы фильтрации для уменьшения возможного отрицательного эффекта.
3. Оценка открытость лица на изображении. Участки лица закрытые другими предметами, такими, как шляпы, очки или волосы должны быть отмечены как не определенные, чтобы посторонние предметы не вносили шумов распознавания. Большинство систем распознавания не могут справиться с этой проблемой успешно. В зависимости от того, на каком участке лица основывается непосредственно сам алгоритм распознавания, а чаще всего это глаза, выдвигается условие к входящим изображениям об обязательной доступности требуемого фрагмента для полного анализа.
После выполнения операций подготовки изображений переходят к поиску аналогов. На рис. 92 представлены часто упоминаемые методы анализа схожести.
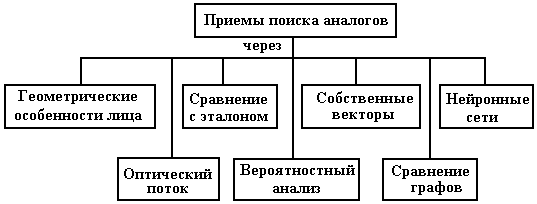
Рис. 92. Классификация часто встречающихся методов сравнения лиц
Наиболее распространена операция оценки геометрических особенностей лиц или анализ совокупностей антропометрических точек.
В криминалистической экспертизе данный подход применяется уже на протяжении нескольких десятков лет и по праву считается самым надежным при идентификации объекта по фотопортрету.
Тот факт, что люди существенно различаются своей внешностью и, в частности, чертами лица, очевиден. Так, например, расположение глаз и их мельчайшие характеристики различаются даже у близнецов. Поэтому не удивительно, что исторически первый поход к решению проблемы автоматической идентификации человека по изображению его лица был основан на выделении и сравнении некоторых антропометрических характеристик лица.
Основная проблема - выбор совокупности характерных точек, однозначно описывающих конкретное человеческое лицо. При этом необходимо учитывать следующие требования: точки на лице или черты лица, на которых основывается идентификация, не должны закрываться прической, бородой, маской и т. п.; для обеспечения независимости процесса распознавания от масштаба изображения целесообразно описывать систему идентификационных точек в отношениях между ними; выбранная система точек должна обеспечивать относительную устойчивость процесса распознавания при незначительном изменении ракурса съемки (легкий поворот головы, наклон, изменение выражения лица и т. д.); количество характерных точек системы, удовлетворяющей вышеизложенным требованиям, должно быть минимальным, так как вычислительная стоимость алгоритмов обычно пропорциональна их количеству.
К настоящему времени имеется много работ, посвященных исследованиям распознавания с помощью различных совокупностей характерных точек и анализу эффективности работы систем, построенных на их основе.
Использование лишних параметров может не только затормозить работу алгоритма, но иногда и снизить точность распознавания. Так, в одной из первых работ по распознаванию людей при использовании набора из 16 параметров лица, среди которых были соотношения между расстояниями, площадями и даже определялись углы между выбранными комбинациями точек, эффективность распознавания колебалась от 45 до 75% в зависимости от используемого набора параметров. Причем лучшие результаты были получены, когда некоторые параметры не учитывались.
Наиболее часто упоминаемые точки и геометрические характеристики:
Ÿ толщина бровей над центрами зрачков;
Ÿ приблизительное (грубое) описание арки брови над левым глазом;
Ÿ вертикальная координата местоположения носа и его ширина;
Ÿ вертикальная координата местоположения рта, ширина и высота верхней и нижней губ;
Ÿ одиннадцать радиусов, описывающих форму подбородка;
Ÿ ширина лица на уровне кончика носа;
Ÿ ширина лица посередине между линией уровня глаз и кончиком носа.
Применяя к описанным подобным образом лицам классификатор Байеса добились 90% распознавания на базе данных в 47 человек. Однако метод сравнения с эталоном при тестировании на той же самой базе изображений дал точность распознавания 100%.
Для настоящего обзора представляет интерес приведенная в описании система характерных точек и получаемых на их основе расстояний (рис. 93), а также ее устойчивость к незначительным изменениям условий съемки (поворот, мимика, освещение и т. д.).

Рис. 93. Проекции лица человека: фронтальная и профильная
Ориентация фронтальной проекции определяется линией, перпендикулярной воображаемой оси, проходящей через центр ушей человека. Допустимо, чтобы фронтальная проекция голова имела небольшой наклон вперед. Как следует из рис. 93, фронтальные проекции идентификационных точек обозначены:
Ÿ центр зрачка (15а и15b),
Ÿ кончик носа (20), который определяется как центральная точка между носовыми отверстиями,
Ÿ центр рта (25) - как точка пересечения линии, разделяющей верхнюю и нижнюю губы объекта, и перпендикуляра, опущенного из точки, определяющей кончик носа объекта,
Ÿ левый угол левого глаза, обозначенный точкой З0а,
Ÿ правый угол правого глаза – З0Ь; нижние точки окончания мочек ушей - 35а и 35b.
При желании могут быть использованы и другие характерные точки лица, например крайняя точка правого угла левого глаза и пр.
Указанные точки на фронтальной проекции лица позволяют определять характерные лицевые параметры последнего. Отмечается, что в данном контексте термины "лицевые параметры" и "длина лицевого параметра" идентичны и означают расстояние между соответствующими идентификационными точками на лице. На рис. 94 показаны выбранные параметры, которые означают следующее:
Ÿ REN (1) - расстояние между центром сетчатки правого глаза и центром кончика носа;
Ÿ REM (2) - расстояние между центром сетчатки правого глаза и центром ротового отверстия;
Ÿ LER (3) - расстояние между центрами сетчатки глаз;
Ÿ LEN (4) - расстояние между центром сетчатки левого глаза и центром кончика носа;
Ÿ LEM (5) - расстояние между центром сетчатки левого глаза и центром ротового отверстия;
Ÿ DMN (6) - расстояние между центром ротового отверстия и кончиком носа.
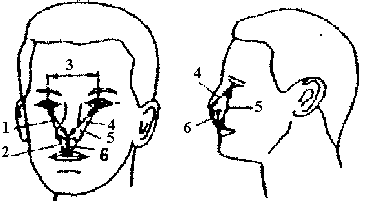
Рис. 94. Идентификационные параметры на фронтальной и профильной проекциях
Все выбранные и отмеченные выше параметры приняты в качестве основных, поскольку на них не влияют такие факторы, как прическа, макияж, наличие ювелирных украшений и пр.
Используя шесть отобранных параметров можно составить до 30 соотношений между ними, которые могут использоваться в качестве признаков. При этом 15 из них будут прямыми, а 15 - обратными соотношениями.
Основной причиной введения в качестве идентификационной единицы отношения параметров является тот факт, что это отношение является величиной постоянной, не зависящей от расстояния, с которого делается фотография человека, а по фотографии невозможно определить размеры головы и ее участков.
Для установления идентичности человека чаще других используются следующие отношения параметров:
LEN/LER; LEM/LER; REN/LER; REM/LER; DMN/LER, кроме того, в качестве дополнительных были выбраны усредненные отношения:
(LEN/LER+REN/LER)/2 и (LEM/LER+REM/LER)/2.
Проведены исследования эффективности использования признаков. Испытуемые просто опускали свои пропуска в считывающее устройство, находясь в стандартном положении. Типичная точность системы распознавания составила 98%.
Следующим, наиболее проработанным после метода анализа антропометрических характеристик лица можно назвать метод собственных векторов (чаще его называют методом главных (принципиальных) компонент лиц). Он является примером того, как математические методы (метод анализа главных компонент), успешно применявшиеся в других областях, оказались эффективно адаптированными к распознаванию людей по их портретам.
Любое цифровое изображение может быть представлено в виде вектора в пространстве признаков. Если изображение описывается wXh пикселями, размерность простейшего векторного пространства, к которому данный вектор принадлежит, будет равна произведению w на h и, соответственно, базис подобного векторного пространства будет состоять из wx h векторов.
Однако в связи с тем, что все человеческие лица схожи между собой (овальная форма с носом, ртом, глазами и т. д.), все векторы, описывающие изображения лиц, будут размещаться в узко ограниченной области данного векторного пространства. Поэтому при решении задачи распознавания людей по портрету описание и хранение всего векторного пространства не рационально.
Таким образом, встает вопрос построения пространства меньшей размерности, в котором изображения человеческих лиц описываются более компактно. Одним из вариантов является пространство, базисными векторами которого служат главные компоненты всех содержащихся в нем изображений лиц. Размерность такого пространства заранее определить невозможно, но она намного меньше размерности векторного пространства всех изображений.
Главной целью метода анализа главных компонент является значительное уменьшение размерности пространства признаков таким образом, чтобы оно как можно лучше описывало "типичные" образы, принадлежащие множеству портретов. В случае применения данного метода для идентификации лиц такими образами будут служить обучающие изображения.
Иными словами, при помощи анализа главных компонент удается выявить всевозможные изменчивости в обучающем наборе изображений лиц и описать эту изменчивость при помощи нескольких переменных. Эти переменные представляют собой wx h - размерные векторы, которые называются собственными. Если преобразовать подобные векторы в изображения, то получаемые файлы будут отражать главные компоненты представленного обучающего множества (также называемые собственные лица).
За счет снижения размерности пространства базисных векторов, в котором находятся изображения повышается скорость и достоверность распознавания.
Полученный на основе представительной обучающей выборки набор собственных векторов или лиц (рис. 95) используется при кодировании всех остальных изображений, которые представляются для хранения в базе взвешенной комбинацией этих собственных векторов (рис. 96). Иными словами, используя ограниченное количество собственных векторов, можно получить улучшенную аппроксимацию к входному изображению, которая затем хранится в базе данных в виде вектора весов, служащим одновременно ключом поиска.

Рис. 95. Набор из пяти собственных векторов
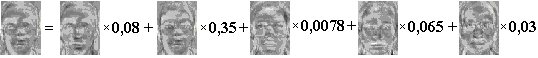
Рис. 96. Описание исследуемого изображения
Математика обоснования полноты набора собственных векторов его минимизации является сегодня интенсивно развивающимся научным направлением. Эксперименты показывают достижение точности распознавания в 99%. Такой подход особенно интересен в охранных системах, когда набор собственных векторов можно составить автоматически по набору допущенных лиц.
Рис. 97 иллюстрирует процесс кодировки и дешифрования описания нового лица.
Пусть некоторый объект определен как вектор 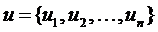 в n-мерном пространстве. Например, U может быть изображением, а в качестве компонент ui могут выступать пиксели. В этом случае n равно числу пикселей изображения.
в n-мерном пространстве. Например, U может быть изображением, а в качестве компонент ui могут выступать пиксели. В этом случае n равно числу пикселей изображения.
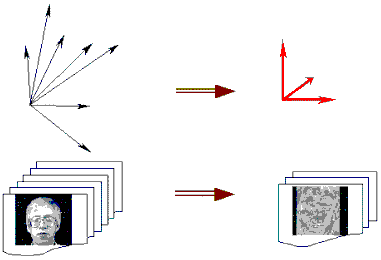
Рис. 97. Уменьшение размерности исходного вектора переносом в базу собственных векторов
Пусть есть группа объектов ![]() , где i = 1…m. Тогда средний объект группы
, где i = 1…m. Тогда средний объект группы 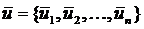 определяется следующим образом:
определяется следующим образом:
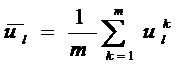 ,
,
где l = 1...n.
Ковариационной матрицей для данной группы изображений будет симметричная квадратная матрица ![]() с элементами
с элементами ![]() , вычисляемыми по формуле:
, вычисляемыми по формуле:
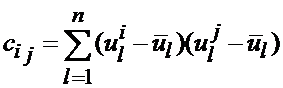 .
.
Базис собственных объектов ![]() , где
, где ![]() будем рассчитывать из соотношения
будем рассчитывать из соотношения
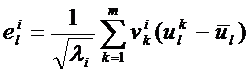 ,
,
где ![]() и
и 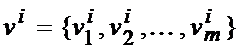 собственные значения ковариационной матрицы и соответствующие им собственные вектора.
собственные значения ковариационной матрицы и соответствующие им собственные вектора.
Таким образом, по входной последовательности объектов произвольной природы определяется базис из собственных объектов, и любой другой объект из этой последовательности может быть представлен в виде вектора весовых коэффициентов, являющимися координатами данного объекта в полученном базисе собственных объектов.
Формула для нахождения координат разложения объекта u:
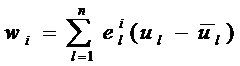 .
.
Объект u может быть восстановлен в любом подпространстверазмерностью m1 пространства собственных векторов по формуле:
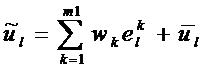 .
.
Тюрк и Г. Тентланд провели комплексное исследование данного метода на базе данных, состоящей из портретов 16 человек, изображения которых были получены при различных условиях освещения, при съемке с различных расстояний, при разных поворотах головы - всего 2500 фотографий. Однако полученные изображения были одинаковы по таким параметрам, как мимика, детали лица (борода, очки и т. д.). При изменении освещения, ракурса съемки и масштаба точность распознавания составила 95, 85 и 64% соответственно. Кроме того, середина лица выделялась для уменьшения негативного эффекта от возможных изменений в прическе и фоне. По скорости работы реализованная на рабочей станции SUN 3/160 система приближалась к режиму реального времени.
Подобно предыдущему методу в вероятностных моделях также используется обучающий набор. При этом формируются два класса из всех вариантов представления объектов: внутри объектной и внешней изменчивости, т. е. отбираются признаки, по которым все портреты делятся на два класса: 1) портрет данного человека, 2) все другие портреты. Функции плотности вероятности для каждого класса оцениваются при помощи упомянутого выше обучающего множества и впоследствии используются для вычисления меры схожести, которая таким образом основывается на полученных опытным путем вероятностях. Кроме того, для получения более точных результатов иногда используется вероятностная модель некоторого физического процесса, при помощи которой и формируется окончательная мера схожести двух изображений.
При распознавании лиц определяют два класса изменений изображений лиц: внутри объектный Qi (различные выражения лица одного человека) и вне объектный QE (разница во внешности двух различных индивидуумов). Тогда мера схожести в терминах теории вероятности может быть выражена следующим образом:
S(Ii, l2)=P(d(Ii, l2)6 Qi)=P(Oi|d(Ii, l2)),
где P(Qi|d(Ii, l2)) - вероятность, полученной по правилу Байеса на основе опытов с использованием оценки подобия P(d(Ii, l2)l ^i) и P(d(Ii, l2)| Оi)" вычисленных из обучающих данных с использованием эффективного под пространственного метода оценки плотности многомерных данных.
Кроме того, используют новое представление для различий в сравниваемых изображениях d(Ii, l2), которое сочетается как с пространственными (X, Y), так и яркостными (I) компонентами в унифицированной XYI структуре (не похожей на предыдущие подходы, которые по существу обрабатывали форму и структуру независимо). В частности, Ii моделируется трехмерной деформируемой физической поверхностью (или множеством) в XYI-пространстве деформируемом в соответствии с привлекаемыми "физическими силами", прилагаемыми поверхностью I..
Динамика подобных систем эффективно решается при использовании "аналитических методов вибрации", получая трехмерное поле соответствия для искривления Ii в 1г. Дополнительную используют параметрическое представление d(Ii, Iz)= U, где U - это спектр модальных амплитуд окончательной деформации. Это множество методов подгонки для соответствия изображений может рассматриваться в более общей формулировке, которая, в отличие от оптического потока, не требует постоянной оценки яркости.
В методе сопоставления с эталоном процесс распознавания разбивается на части, соответствующие отдельным чертам лица.
Каждая фотография, поступающая на вход распознающей системы, должна представлять собой фронтальное изображение лица человека с определенным для конкретной базы данных количеством масок, представляющих основные для идентификации регионы лица (например, глаза, нос, рот и нижняя часть лица). Кроме того, расположения данных масок должны быть одинаково нормализованы (например, относительно положения глаз) для всех изображений в базе данных.
Во время процесса распознавания, когда части входного изображения по очереди сравниваются с частями изображения, хранящегося в базе, используется вектор, отражающий результат сравнения в баллах (один балл за каждую совпавшую черту лица) и вычисляемый путем нормализованной взаимной корреляции (впрочем, методы сравнения могут быть разными). После чего входное изображение классифицируется в соответствии с максимально набранными баллами. Имеются также некоторые разновидности данного подхода, например с изменяющимися в процессе сравнения эталонами.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
