

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· --clone – передача этого параметра включает использование алгоритма борьбы с попадание в локальный минимум.
При использовании опции --test, все опции, относящиеся к обучению новой сети, будут проигнорированы. Для задания числа и размерности скрытых слоев, соответствующую опцию можно указать несколько раз, при этом будут учитываться все переданные числа. Размерность выходного слоя рассчитывается автоматически по размерности выходного вектора, полученной из файла, переданного с опцией target_file.
4.2 Результаты обучения нейронной сети
Для обучения выборка была разделена на тренировочную, валидационную и тестовую часть в соотношение 0.7, 0.15, 0.15. Использовался режим адаптивной скорости обучения с параметрами 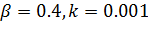 . Параметр
. Параметр ![]() принимал значения 0.05. Сеть обучается 1000 эпох, после нахождения минимума валидационной ошибки происходит откат на 50 эпох, скорости обучения весов при этом увеличиваются на 5 и 10.
принимал значения 0.05. Сеть обучается 1000 эпох, после нахождения минимума валидационной ошибки происходит откат на 50 эпох, скорости обучения весов при этом увеличиваются на 5 и 10.
Тестируются нейронной сети с количеством скрытых слоев от 0 до 2 включительно. Количество нейронов в каждом слое последовательно увеличивается от 10 до 100 с шагом в 10.
При обучении сети без скрытого слоя на тестовой выборке была получена среднеквадратичная ошибка равная 0.3064935. При этом точно указан класс для 50% тестовых образцов, с погрешностью ![]() класс - для 93.9% тестовых образцов. Данные о классификации образцов в ходе тестирования нейронной сети приведены в таблице Таблица 3.
класс - для 93.9% тестовых образцов. Данные о классификации образцов в ходе тестирования нейронной сети приведены в таблице Таблица 3.
Таблица 3
Результаты тестирования сети без скрытого слоя
Целевой класс | 0 | 0 | 2 | 3 | 0 | 0 | 0 |
0 | 1 | 23 | 11 | 0 | 0 | 0 | |
0 | 0 | 148 | 115 | 1 | 0 | 0 | |
0 | 1 | 79 | 231 | 20 | 0 | 0 | |
0 | 0 | 8 | 108 | 22 | 0 | 0 | |
0 | 0 | 0 | 18 | 7 | 0 | 0 | |
0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Точность, % | 0 | 3 | 56 | 70 | 16 | 0 | 0 |
Выданный сетью класс |
При обучении сети с одним скрытым слоем наилучшие результаты были получены при количестве нейронов в слое равном 40. В этой сети величина средней квадратичной ошибки на тестовых примерах равна 0.2896. При этом точно указан класс для 57% тестовых образцов, с погрешностью ![]() класс - для 94.6% тестовых образцов. Данные о классификации образцов в ходе тестирования нейронной сети приведены в таблице Таблица 4.
класс - для 94.6% тестовых образцов. Данные о классификации образцов в ходе тестирования нейронной сети приведены в таблице Таблица 4.
Таблица 4
Результаты тестирования сети с одним скрытым слоем
Целевой класс | 0 | 0 | 2 | 3 | 0 | 0 | 0 |
0 | 1 | 23 | 11 | 0 | 0 | 0 | |
0 | 2 | 186 | 71 | 5 | 0 | 0 | |
0 | 1 | 85 | 220 | 24 | 1 | 0 | |
0 | 0 | 6 | 85 | 46 | 1 | 0 | |
0 | 0 | 0 | 13 | 11 | 1 | 0 | |
0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Точность, % | 0 | 3 | 70 | 66 | 33 | 4 | 0 |
Выданный сетью класс |
При обучении сети с двумя скрытыми слоями наилучшие результаты были получены при количестве нейронов в слоях равном 50 в первом скрытом и 40 во втором скрытом слое. В этой сети величина средней квадратичной ошибки на тестовых примерах равна 0.278. При этом точно указан класс для 58% тестовых образцов, с погрешностью ![]() класс - для 95.6% тестовых образцов. Данные о классификации образцов в ходе тестирования нейронной сети приведены в таблице Таблица 5.
класс - для 95.6% тестовых образцов. Данные о классификации образцов в ходе тестирования нейронной сети приведены в таблице Таблица 5.
Таблица 5
Результаты тестирования сети с двумя скрытыми слоями
Целевой класс | 0 | 0 | 4 | 1 | 0 | 0 | 0 |
0 | 0 | 28 | 6 | 1 | 0 | 0 | |
1 | 0 | 174 | 87 | 2 | 0 | 0 | |
0 | 0 | 71 | 238 | 22 | 0 | 0 | |
0 | 0 | 3 | 82 | 53 | 0 | 0 | |
0 | 0 | 1 | 15 | 9 | 0 | 0 | |
0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Точность, % | 0 | 0 | 66 | 72 | 38 | 0 | 0 |
Выданный сетью класс |
На рисунке Рис. 13 показан график изменения валидационной ошибки сети при обучении для сетей, показавших наилучший результат в ходе тестирования. На нем показано, что сеть с одним скрытым слоем в ходе обучения достигла наименьшей ошибки валидации. Несмотря на это, при тестировании сеть с двумя скрытыми слоями показала лучший результат.
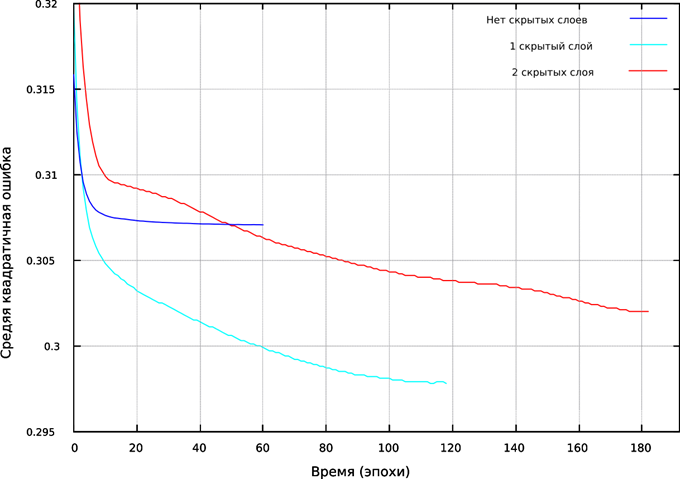
Рис. 13. График изменения валидационной ошибки в ходе обучения
5 Анализ результатов
После обучения была получена нейронная сеть, способная в 58% процентах случаях точно классифицировать входной образ, и в 95.6% классифицировать с точностью ![]() класс. На графикеРис. 13 показано, что скорость обучения нейронной сети без скрытых слоев на определенном этапе резко падает до 0, в то время как наличие одного или двух скрытых слоев позволяет производить обучение дальше.
класс. На графикеРис. 13 показано, что скорость обучения нейронной сети без скрытых слоев на определенном этапе резко падает до 0, в то время как наличие одного или двух скрытых слоев позволяет производить обучение дальше.
Добавление в сеть скрытого слоя привело к увеличению качества распознавания объектов обученной сетью. Следовательно, можно предположить, что в данной задаче классы являются линейно-неразделимыми.
Тестирование показала низкую, от 0% до 4%, точность классификации объектов, принадлежащим к крайним двум слева и двум справа классам. Возможно, это является следствием небольшого количества примеров, принадлежащих этим классам. Точность определения 5 класса изменяется от 16% до 38% в зависимости от количества скрытых слоев в сети. При этом, точность классификации объектов, принадлежащим классам 3 и 4, принимает значение от 56% до 72%.
Добавление второго скрытого слоя в сеть не дало сильного улучшения точности классификации, но сильно уменьшило скорость обучения сети.
Заключение
Была рассмотрена задача построения нейросетевого классификатора, позволяющего по химическому составу определить качество вина.
Изучены различные математические модели классификаторов, в том числе нейронные сети и машины опорных векторов. Каждая модель оценена с точки зрения ее применимости к решению поставленной задачи. В результате решено строить классификатор на основе нейронной сети.
Рассмотрены теоретические основы нейронных сетей. При этом приведены описания различных нейросетевых парадигм, которые могут быть использованы для решения задачи классификации. Вследствие невозможности утверждать, что классы в задаче являются линейно-разделимыми, принято решение отказаться от использования однослойных сетей. Выбор между сетью радиально-базисных функций и многослойным персептроном сделан в пользу последнего из-за меньшей вычислительной сложности при сравнимом результате.
На основе многослойной сети прямого распространения, обучаемой с помощью алгоритма обратного распространения, построен классификатор. Методы предварительной обработки данных и кодирования классов выбраны с учетом особенной поставленной задачи. Задана топология сети и метод начальной инициализации параметров. Определена структура классификатора, и его функциональные возможности. Классификатор реализован на языке программирования С++.
Полученные результаты обучения нейронной сети показывают, что после обучения сеть оказалась способной производить классификацию винно-водочной продукции. По результатам тестирования, классификатор показал наличие принципиальной возможности определения качества винно-водочной продукции с помощью классификатора, построенного на основе многослойной нейронной сети прямого распространения, и обученной модифицированным алгоритмом обратного распространения. Но точность этой классификации на данном этапе исследования остается недостаточной для реального применения на производственном предприятии. Требуются дополнительные исследования, направленные на повышение точности распознавание качества вин.
Для дальнейшего исследования в области применимости нейронных сетей для классификации вин, возможно рассмотреть RBF-сети. В данной работе использовалась сеть с сигмоидной функцией активации. Возможно, ее изменение поможет улучшить точность. Также представляет интерес использование кластерных нейронных сетей и изучение зависимости между полученными сетью кластерами и классами вин, заданными в исходных данных. Другим направлением дальнейших исследований может быть попытка уменьшить размерность данных, например, с помощью метода главных компонент.
Список использованных источников
1. Нейронные сети – М. : Издательский дом «Вильямс», 2006 – 1104 с.
2. Bishop C. M. Neural network for pattern recognition – New York: Oxford University Press, 1995 – 482 pp.
3. Broomnhead D. S. and Lowe D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Nctworks – London, 1988 URL: http://www. dtic. mil/cgi-bin/GetTRDoc? AD=ADA196234 (дата обращения 14.04.2015)
4. Fausett L. Fundamentals of neural network – New Jersey: Prentice-Hall, 1994 – XVII pp. +492 pp.
5. G. Thimm, E. Fiesler High Order and Multilayer Perceptron Initialization // IEEE Transactions on Neural Networks. 1996, №94-07
6. Hagan M. T., Demuth H. B., Beale M. Neural network design – USA: PWS Publishing Company, 1996 – 733 pp.
7. Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning – Springer Verlag, 2009 – 764 pp.
8. N. H. Beltran, M. A. Duarte-Mermoud, M. A. Bustos, S. A. Salah, E. A. Loyola, A. I. Pena-Neira, J. W. Jalocha. Feature extraction and classification of Chilean wines // Journal of Food Engineering. 2006, Т. 75 вып. 1, с. 1–10
9. Paulo Cortez, Antonio Cerdeira, Fernando Almeida, Telmo Matos, Jose Reis. Modeling wine preferences by data mining from physicochemical properties – Portugal, University of Minho, 2008
10. Rojas R. Neural Networks. A Systematic Introduction – Berlin: Springer, 1996 – 509 pp.
11. S. R. pport Vector Machines for Classification and Regression – University of Southampton, 1998
12. S. Vlassides, J. Ferrier, and D. Block. Using Historical Data for Bioprocess Optimization: Modeling Wine Characteristics Using Artificial Neural Networks and Archived Process Information // Biotechnology and Bioengineering. 2001, №73(1), c. 55-68
13. Tim Jones M. Al Application Programming – Massachusetts: CHARLES RIVER MEDIA, INC, 2003 – 311pp.
14. Yann LeCun, Leon Bottou, Genevieve B. Orr, Klaus-Robert Muller. Efficient BackProp. URL: http://yann. /exdb/publis/pdf/lecun-98b. pdf (дата обращения 22.05.2015)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
