

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Различные алгоритмы обучения можно условно разделить на две группы: обучение с учителем и обучение без учителя.
В случае обучения с учителем подразумевается наличие некоторой известной информации об окружающей среде, а именно наличие некоторой выборки, состоящей из пар вида ![]() , где
, где ![]() – это единичный набор входных данных, а
– это единичный набор входных данных, а ![]() – информация, описывающая, как сеть должна реагировать на введенные данные. Возможны разные варианты того, что из себя представляет
– информация, описывающая, как сеть должна реагировать на введенные данные. Возможны разные варианты того, что из себя представляет ![]() .
.
В одном случае, ![]() представляет собой описание ожидаемого выхода нейронной сети. Тогда пара
представляет собой описание ожидаемого выхода нейронной сети. Тогда пара ![]() называется примером. Многие алгоритмы обучения в этом случае используют некоторую оценку разности между требуемым и полученным ответами нейронной сети. Эта оценка используется для определения того, насколько сильно необходимо изменить структуру сети. Часто пытаются достигнуть того, чтобы за один процесс корректировки весов для обрабатываемого в данный момент примера уменьшить величину ошибку до нуля или близко к нему [10].
называется примером. Многие алгоритмы обучения в этом случае используют некоторую оценку разности между требуемым и полученным ответами нейронной сети. Эта оценка используется для определения того, насколько сильно необходимо изменить структуру сети. Часто пытаются достигнуть того, чтобы за один процесс корректировки весов для обрабатываемого в данный момент примера уменьшить величину ошибку до нуля или близко к нему [10].
В другом случае, исследователю для некоторого набора входных данных известна лишь некоторая процедура, сообщающая, является ли ответ нейронной сети правильным или нет. Главным отличием является то, что невозможно оценить, насколько далеко от правильного ответа находится ответ нейронной сети.
Есть возможность, что в результате обучения, сеть просто приспособится к вводимым в ней примерам, и, получив на вход пример, не использовавшийся в ходе обучения, выдаст неадекватный результат. Чтобы избежать этого, для самого обучения используется только часть всех доступных примеров. Неиспользованная часть примеров применяется для оценки качества получившейся нейронной сети.
В случае если набора примеров нет, а известны только входные данные, можно использовать обучение без учителя. В данном случае, нейронная сеть должна выдавать для каждого примера некоторое “наилучшее значение”, величина которого определяется конкретным алгоритмом обучения. В качестве примера можно рассмотреть задачу кластеризации точек на плоскости. Она показана на рисункеРис. 10.
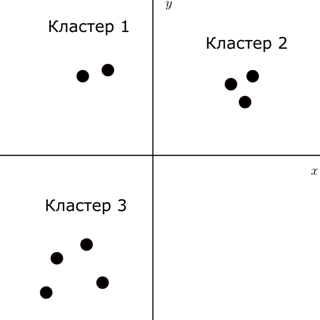
Рис. 10. Задача кластеризации
Для решения данной задачи, необходимо обучить сеть таким образом, что бы она выдавала одинаковый ответ для точек, входящих в один и тот же кластер. Изначально, исследователю недоступна информация о том, какая точку какому кластеру соответствует. В общем случае количество кластеров также неизвестно. Следовательно, в процессе обучения, сеть должна сама неким образом модифицировать свою структуру для решения поставленной задачи. Обычно стараются достигнуть того, чтобы на наборы входных данных, расположенных достаточно близко друг к другу, сеть выдавала одинаковый ответ [10].
В ходе обучения, с учителем или без, исследователю необходимо определить, каким образом он будет модифицировать значения весов синаптических связей. К решению этого вопроса есть два основных похода: детерминированный и стохастический [1].
В детерминированном подходе величины, на которые будут изменены веса, определяются с помощью детерминированного алгоритма. Обычно это алгоритм, основанный на анализе текущей структуры сети и ее параметров, и на разнице между ожидаемой реакцией сети на некие данные и реальной.
При использовании стохастического подхода корректировка весов производится случайным образом. То есть, исследователь пропускает через сеть некоторый набор входных данных и сравнивает выход сети с желаемым. Если разница слишком велика, то веса связей изменяются случайным образом, затем этот же набор данных снова пропускается через сеть. Если величина ошибки уменьшилась, то новые значения весов сохраняются, иначе отбрасываются.
В ходе обучения сети с учителем может возникнуть проблема переобучения. Переобученная сеть будет способна давать точный ответ при вводе в нее примеров, использовавшихся при обучении. Но при попытке использовать сеть на новых данных будет получен неадекватный результат. Одним из признаков переобученной сети являются слишком большие весовые коэффициенты. Для того чтобы избежать этого, можно разделить набор примеров для тренировки на две части, и тренировать сеть только на одной части. Другую часть использовать при этом для проверки степени качества работы сети, и останавливать обучение в случае роста величины ошибки [7].
2.4.1 Алгоритм обучения Хэба
Хэбб в 1949 году предложил алгоритм изменения весовых коэффициентов при синаптических связях, основанный на следующем правиле: “Если аксон в клетке А близок к передаче возбуждения клетке Б, и постоянно и неоднократно принимает участие в процессе возбуждения клетки Б, то в одной или обеих клетках происходит некоторый процесс роста или метаболических изменений, в результате чего эффективность клетки А в процессе возбуждения клетки Б повышается”. Данный алгоритм может быть использован в сетях с различной конфигурацией.
Правило Хэбба говорит, что если два нейрона, связанных синаптической связью, активируются одновременно, то связь между ними усиливается. В математическом виде изменение веса можно записать следующим образом:
| (11) |
где, соответственно, 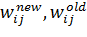 – новое и старое значение веса при связи, соединяющей i-й элемент входного вектора и j-й нейрон,
– новое и старое значение веса при связи, соединяющей i-й элемент входного вектора и j-й нейрон,  - некоторая константа, задающая скорость изменения весов (или, другими словами, скорость обучения),
- некоторая константа, задающая скорость изменения весов (или, другими словами, скорость обучения), ![]() - некоторая функция от i-го значения входного вектора,
- некоторая функция от i-го значения входного вектора, ![]() - некоторая функция от выходного значения j-го вектора. Можно заметить, что в формуле (11) нигде не присутствует значение целевого вектора. Это позволяет использовать этот метод для обучения без учителя, когда даны лишь входные вектора, а целевые неизвестны. Функции
- некоторая функция от выходного значения j-го вектора. Можно заметить, что в формуле (11) нигде не присутствует значение целевого вектора. Это позволяет использовать этот метод для обучения без учителя, когда даны лишь входные вектора, а целевые неизвестны. Функции ![]() , а также константа
, а также константа ![]() подбираются самим исследователем.
подбираются самим исследователем.
Модифицируем метод Хэбба для случая наличия пар, состоящих из входного вектора и желаемого результата. Рассмотрим однослойную сеть прямого распространения с функцией активации первого слоя  . Пусть вектор
. Пусть вектор ![]() описывает вход сети,
описывает вход сети, ![]() описывает реальный выход сети, желаемый выход описывает вектор
описывает реальный выход сети, желаемый выход описывает вектор 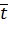 , а
, а ![]() - матрица весовых коэффициентов. Тогда выход одного нейрона будет описываться следующей формулой:
- матрица весовых коэффициентов. Тогда выход одного нейрона будет описываться следующей формулой:
| (12) |
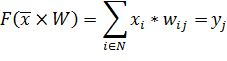
где N – размерность вектора ![]() , j – индекс нейрона. Если известны целевые вектора, то можно модифицировать алгоритм Хэбба. Примем
, j – индекс нейрона. Если известны целевые вектора, то можно модифицировать алгоритм Хэбба. Примем 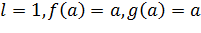 . Тогда формула для вычисления изменения весов примет следующий вид:
. Тогда формула для вычисления изменения весов примет следующий вид:
| (13) |
Если изначально значения матрицы весов равны нулю, то после обучения на n примерах мы получим следующие веса:
| (14) |
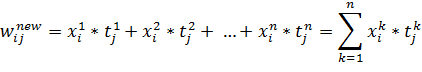
Предположим, что входные векторы ортонормированны, то есть:
| (15) |
| (16) |
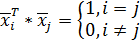
Проведем обучение сети и подадим на вход один из участвовавших в обучении входных векторов ![]() , q – номер примера. Получим следующую формулу, описывающую элемент выходного вектора сети:
, q – номер примера. Получим следующую формулу, описывающую элемент выходного вектора сети:
| (17) |
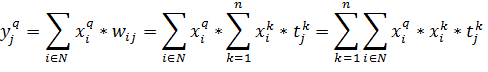
Так как 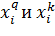 это элементы ортогональных векторов
это элементы ортогональных векторов 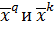 , то:
, то:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
