

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Обучение продолжается до тех пор, пока персептрон не перестанет совершать ошибки. Согласно теореме о сходимости обучения персептрона, если существует такой набор значений весов синаптических связей, который позволит персептрону выдавать верный результат на все обучающие примеры, то такой набор будет найден, и, более того, это произойдет за конечное число шагов [4].
Так как результатом работы нейрона в ассоциативном слое является 0 или 1, и веса между сенсорным слоем и ассоциативным не меняются в ходе обучения, то при построении классификатора можно упростить сеть, если вектор признаков объекта уже является бинарным. Тогда входной слой может играть роль ассоциативного слоя. Пример структуры сети для решения задачи об определении принадлежности объектов к одному классу приведен на рисункеРис. 7.
Хотя после своего появления в 1960-х годах, персептроны привлекли много внимания, и на них возлагались большие надежды, дальнейшее изучение показало, что набор проблем, который можно решить с их помощью, является крайне ограниченным. В то время, как персептрон успешно решал одни задачи, решение других, которые казались на первый взгляд ничуть не сложнее, оказалось для него невозможным.
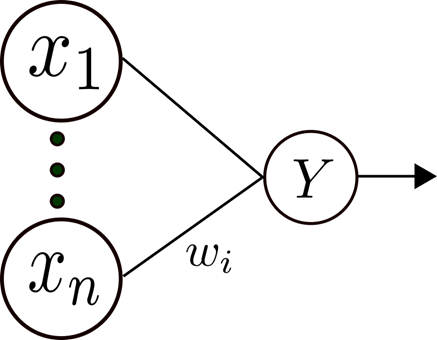
Рис. 7. Простейший классификатор на основе персептрона
Классическим примером является проблема реализации с помощью персептрона функции “исключающего или”, известная как проблема отделимости [13]. Это является следствием того, что однослойный персептрон способен решать задачу классификации только для линейно-разделенных наборов признаков.
Столкнувшись с проблемой линейно-неразделенных данных, в некоторых случаях можно попытаться преобразовать входные данные. Целью является нахождение такой функции, чтобы преобразованные величины были линейно-разделенными. В таком случае, задав соответствующие ассоциативные элементы, можно построить персептрон для решения данной задачи. Но, соответственно возникает вопрос, как выбрать необходимое преобразование. Ответ на этот вопрос не всегда возможно получить, и зависит он от конкретной задачи [2].
Однако то, что связи между входным слоем и ассоциативным фиксированы, и не могут быть адаптированы в ходе обучения под конкретную задачу, представляет собой большую проблему. Вследствие этого, при увеличении размерности входных данных, необходимое число нейронов, занимающихся предварительным преобразованием, и сложность соответствующих функций, растет крайне быстро. Минский и Паперт в своей книге “Персептроны” (1969) рассматривают разные структуры персептрона, в зависимости от использовавшегося в них преобразования входных данных. И в каждом случае они находят примеры проблем, которые не могут быть решены персептроном приведенной структуры [2].
Из рассмотренных ограничений персептрона следует, что необходимо сконструировать сеть с адаптивными весами между входным и ассоциативным слоями. Это приводит нас к рассмотрению многослойных сетей.
2.3.2 Многослойные сети прямого распространения
Одним из самых распространенных типов нейронных сетей являются многослойные сети. В основе структуры данного типа сетей лежит понятие слоя, рассмотренное ранее. Причем входы нейронов слоя связаны с выходами нейронов одного или нескольких других слоев.
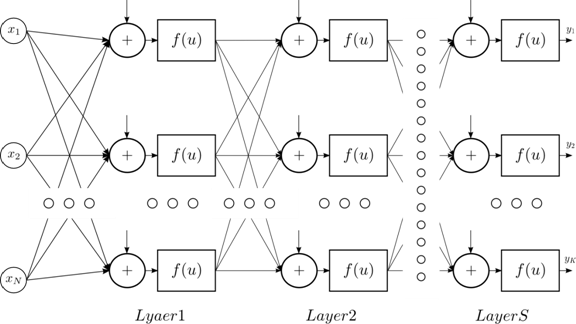
Рис. 8. Многослойная нейронная сеть
Набор “виртуальных” нейронов, с помощью которых в нейронную сеть подаются входные данные, называют входным слоем. Слой нейронов, чьи выходы считаются выходом сети, называется выходным слоем. Остальные слои нейронной сети имеют название скрытых слоев. В различной литературе входной слой может участвовать или не участвовать в подсчете общего количества слоев нейронной сети. Здесь и далее, входной слой не будет учитываться при указании количества слоев сети.
На рисункеРис. 8 указан пример двухслойной сети, у которой выход первого, скрытого, слоя соединен с входом второго, выходного, слоя. Для обозначения весов связей между выходами и входами нейронами двух слоев удобно использовать матрицы. Пусть вход слоя соединен с выходом слоя с i нейронами, а в самом слое содержится j нейронов. Тогда связь между слоями будет описывать матрица ![]() размера
размера 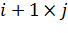 , составленная из коэффициентов
, составленная из коэффициентов ![]() , равных весу при синаптической связи, соединяющей выход i-го нейрона предыдущего слоя, с входом j-го нейрона описываемого слоя. При этом величины
, равных весу при синаптической связи, соединяющей выход i-го нейрона предыдущего слоя, с входом j-го нейрона описываемого слоя. При этом величины ![]() используют для описания смещения j-го нейрона. Если теперь задать вектор входных значений X размера j+1, в котором
используют для описания смещения j-го нейрона. Если теперь задать вектор входных значений X размера j+1, в котором ![]() описывает входное значение j-го нейрона, а
описывает входное значение j-го нейрона, а ![]() служит для описания смещения и поэтому равен 1, то можно получить вектор
служит для описания смещения и поэтому равен 1, то можно получить вектор ![]() , составленный из значений активации нейронов.
, составленный из значений активации нейронов.
| (6) |
Если соответствующим образом определить функцию активации ![]() , принимающую на вход вектор U, то получим формулу (7) для выхода слоя в матричной форме.
, принимающую на вход вектор U, то получим формулу (7) для выхода слоя в матричной форме.
| (7) |
Многослойные сети прямого распространения, обучаемые методом обратного распространения ошибки, как правило, успешно решают задачи классификации и аппроксимации функции с любой, заранее заданной, точностью [6].
2.3.3 Сеть радиально-базисных функций
В 1988 году Брумхед и Лоу представили архитектуру нейронной сети, основанной на использование радиально-базисных функций в качестве функций активации. Радиально-базисные функции – это класс функций, значение которых зависит от расстояния от центральной точки и монотонно возрастает или убывает при увеличении этого расстояния.
Одной из самых распространенных функций из этого класса является функция Гаусса:
| (8) |
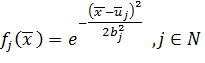
Эта формула определяет выход j-го нейрона в сети из N нейронов, когда на вход сети подается пример, описываемый вектором ![]() .
. ![]() описывает центр для j-го нейрона,
описывает центр для j-го нейрона, ![]() - параметр, контролирующий гладкость функции.
- параметр, контролирующий гладкость функции.
Радиально-базисные функции могут быть использованы в сетях самого широкого класса, но, говоря о RBF-сетях, обычно подразумевают сеть определенной архитектуры. Данная сеть имеет один скрытый слой с нелинейной функцией активации, и выходной слой с линейной функцией активации. Схема данной сети приведена на рисунке Рис. 9.
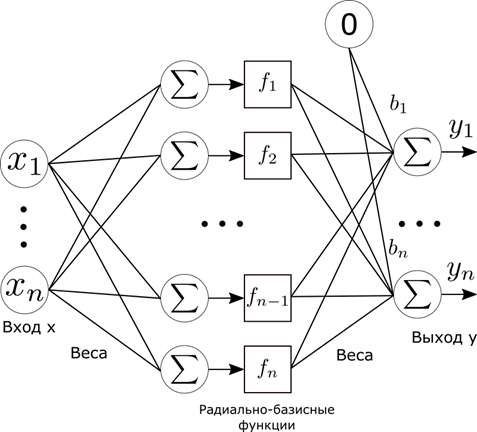
Рис. 9. Сеть радиально-базисных функций
Выходом такой сети является линейная комбинация значений выходов скрытого слоя.
| (9) |
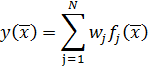
Радиально-базисные сети позволяют достигнуть глобального минимума при оптимизации квадратичной функции ошибки [3]:
| (10) |
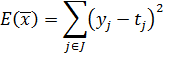
Радиально-базисные сети оказались весьма эффективны в решении задачи точной интерполяции функции в многомерном пространстве. Данная интерполяция названа точной в том смысле, что при подаче в сеть входного вектора данных из обучающего набора, сеть должна возвращать в точности ожидаемый результат.
2.4 Обучение нейронной сети
Важным свойством нейронных сетей является их способность к обучению. Основываясь на данных, полученных из окружающей среды, нейронная сеть способна изменить себя с целью повышения своей эффективности.
В контексте искусственных нейронных сетей, под обучением можно понимать как настройку весовых коэффициентов сети, так и изменение ее структуры с целью повышения эффективности поставленной задачи. Возможность сети самой искать связи между предоставляемыми входными данными и выходными целями делает их более привлекательными по сравнению с системами, в которых правила решения задачи задаются вручную.
Обучение сети является итеративным процессом. В ходе одной итерации сети выполняются следующие пункты:
1. Получение информации из внешней среды посредством стимулов;
2. Изменение параметров или структуры сети;
3. Реакция сети на внешние стимулы теперь отличается от того, что было раньше;
Существует множество различных алгоритмов обучения нейронных сетей, и каждый алгоритм требует выполнения определенных условий насчет структуры нейронной сети. Так же, в зависимости от исследуемой проблемы, одни алгоритмы обучения могут показать лучший результат, чем другие [1].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
