

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
| (18) |
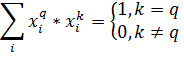
Тогда в качестве выходного значения получим:
| (19) |
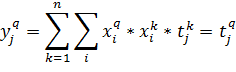
То есть выход сети в точности равен целевому значению. Рассмотрим случай, когда входные вектора не являются ортогональными, а только нормированными. Тогда результат работы сети будет выглядеть следующим образом:
| (20) |
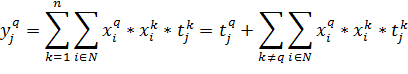
То есть сеть будет выдавать результат с ошибкой равной последнему слагаемому.
2.4.2 Метод наименьшей квадратичной ошибки
В 1960 году Бернард Уидроу и Мартин Хоф представили нейронную сеть ADALINE, а также алгоритм ее обучения, названный ими LMS (Least Mean Square) – алгоритм. Это итеративный алгоритм обучения нейронной сети. Он известен также как дельта-правило или алгоритм обучения Уидроу - Хофа [4].
В ходе работы, данный алгоритм пытается уменьшить величину ошибки между реальным и ожидаемым выходами сети. На каждой итерации обрабатывается один тренировочный набор данных, после чего следует оценка ошибки и попытка ее уменьшения путем корректировки весовых коэффициентов.
Структура сети ADALINE похожа на структуру однослойного персептрона, за исключением функции активации. Здесь используется линейная функция активации. Схема сети представлена на рисунке Рис. 11. Она содержит в себе один слой из S нейронов. Размерность входного вектора равна R.

Рис. 11 Нейронная сеть ADALINE
Алгоритм LMS является одним из алгоритмов обучения с учителем, и требует наличия набора пар ![]() , сотоящих из вектора входных данных и вектора, описывающего ожидаемый выход сеть. Для оценки разницы между ожидаемым и реальным выходами сети используется сумма квадратов отклонений
, сотоящих из вектора входных данных и вектора, описывающего ожидаемый выход сеть. Для оценки разницы между ожидаемым и реальным выходами сети используется сумма квадратов отклонений ![]() .
.
| (21) |
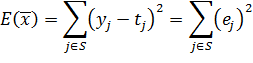
где, соответственно ![]() – реальный выход j-го нейрона сети, а
– реальный выход j-го нейрона сети, а ![]() - ожидаемый выход j-го нейрона.
- ожидаемый выход j-го нейрона.
Тогда, учитывая, каким образом нейронная сеть преобразовывает входные данные в выходные, можно записать:
| (22) |
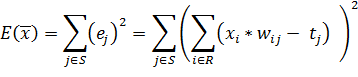
Градиент функции показывает направление ее наибольшего роста. Следовательно, двигаясь в обратную сторону, можно производить минимизацию функции ошибки. Тогда, на каждой итерации алгоритма обучения для уменьшения величины ошибки можно производить корректировку весов по следующей формуле:
| (23) |
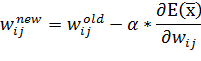
Коэффициент ![]() задает скорость изменения весовых коэффициентов. Выразим формулу для частной производной:
задает скорость изменения весовых коэффициентов. Выразим формулу для частной производной:
| (24) |
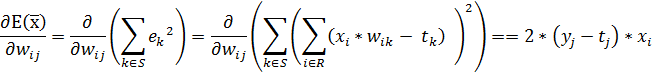
Коэффициент ![]() подбирается экспериментально или выбирается исследователем исходя из каких-то соображений относительно специфики конкретной задачи. Можно лишь сказать, что если
подбирается экспериментально или выбирается исследователем исходя из каких-то соображений относительно специфики конкретной задачи. Можно лишь сказать, что если ![]() слишком мало, то обучение будет идти слишком медленно. При достаточно большой скорости изменения коэффициентов, в ходе обучения есть вероятность в результате одного изменения “перепрыгивать" через минимум. К тому же, как показывает практика, метод LMS требует значительного времени для обучения нейронной сети.
слишком мало, то обучение будет идти слишком медленно. При достаточно большой скорости изменения коэффициентов, в ходе обучения есть вероятность в результате одного изменения “перепрыгивать" через минимум. К тому же, как показывает практика, метод LMS требует значительного времени для обучения нейронной сети.
Так как функция ошибки является квадратичной функцией от элементов входного вектора, то можно показать, что наличие одного уникального решения задачи обучения при решении определенной задачи полностью зависит от характеристик входных данных [6].
Таким образом, процесс обучения выглядит следующим образом:
1. Для каждого примера из обучающей выборки:
а) Пропустить через нейронную сеть пример из обучающего набора;
б) Для примера вычислить функцию квадратичной ошибки и скорректировать веса.
2. Повторять пункт 1 необходимо до тех пор, пока не будут выполнены условия для завершения обучения. Таким условием может стать уменьшение среднего значения квадратичной ошибки или превышение количества итераций некоторого заранее заданного числа.
Формулы, используемые для изменения весовых коэффициентов при синаптических связях между входным слоем и выходным, имеют следующий вид:
| (25) |
| (26) |
В дальнейшем, на основе этого метода был создан метод обратного распространения ошибки, который можно использовать для нейронной сети прямого распространения с произвольным числом слоев и с произвольными функциями активации, при условии, что они являются непрерывными и дифференцируемыми.
2.4.3 Алгоритм обратного распространения ошибки
Это метод поиска минимума функции ошибки, производимый в пространстве весовых коэффициентов синаптических связей, и основанный на градиентном спуске. В качестве результата процесса обучения выступает набор весовых коэффициентов, минимизирующий функцию ошибки.
Алгоритм позволяет тренировать многослойные сети прямого распространения. Он включат в себя три фазы:
а) Провести через сеть обучающий пример. Это фаза прямого распространения;
б) Вычислить значение ошибки между полученным выходом сети и ожидаемым, и на ее основе вычислить значения ошибок для каждого предыдущего слоя, вплоть до входного. Эта фаза обратного распространения ошибки;
в) Произвести единовременную корректировку всех весов, основываясь на их текущем значении, значении ошибки, соответствующей рассматриваемому нейрону и активационному значению нейрона.
Обучение с помощью алгоритма обратного распространения ошибки может потребовать значительных вычислительных средств и времени, но получившаяся в итоге сеть работает крайне быстро. Для реализации и использования уже обученной сети необходима только первая фаза алгоритма.
Так же, как и в методе наименьшей квадратичной ошибки, необходимо рассчитать производную функции ошибки, только теперь уже для произвольной функции активации. Функция ошибки для сети с J выходами задается аналогичным способом:
| (27) |
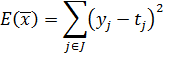
где ![]() - реальный выход j-го нейрона сети,
- реальный выход j-го нейрона сети, ![]() - ожидаемый выход j-го нейрона. Пусть
- ожидаемый выход j-го нейрона. Пусть ![]() - функция активации нейронов в выходном слое, тогда значение j-го выходного нейрона будет определяться следующим способом:
- функция активации нейронов в выходном слое, тогда значение j-го выходного нейрона будет определяться следующим способом:
| (28) |
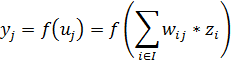
![]() - веса при связях, соединяющие i-й нейрон предыдущего слоя и j-й нейрон выходного слоя,
- веса при связях, соединяющие i-й нейрон предыдущего слоя и j-й нейрон выходного слоя, ![]() - выходное значение i – го нейрона предыдущего слоя, I – число нейронов в предыдущем слое. Найдем производную функции ошибки вдоль синаптической связи
- выходное значение i – го нейрона предыдущего слоя, I – число нейронов в предыдущем слое. Найдем производную функции ошибки вдоль синаптической связи ![]() :
:
| (29) |
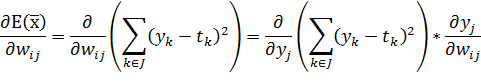
Подобное преобразование возможно, так как ![]() не зависит от
не зависит от ![]() . Рассмотрим первый множитель:
. Рассмотрим первый множитель:
| (30) |
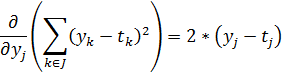
Учтем, как выражается ![]() через активационную функцию, и рассмотрим второй множитель:
через активационную функцию, и рассмотрим второй множитель:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
