

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
| (31) |
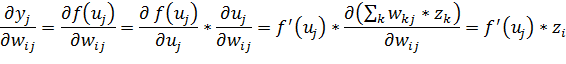
Конечный вид производной:
| (32) |
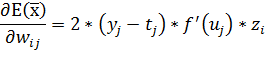
Легко видеть, что если выход сети равен ожидаемому значению, то значение производной функции ошибки обращается в ноль.
На основе производной вычисляется величина изменения веса ![]() в ходе обучения:
в ходе обучения:
| (33) |
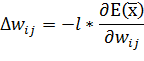
В ходе первой фазы алгоритма, набор данных ![]() из обучающей выборки пропускается через сеть. Последовательно обходится каждый слой сети, начиная с входного слоя и заканчивая выходным. Каждый нейрон вычисляет свой вход и выход, и распространяет его дальше по синаптическим связям.
из обучающей выборки пропускается через сеть. Последовательно обходится каждый слой сети, начиная с входного слоя и заканчивая выходным. Каждый нейрон вычисляет свой вход и выход, и распространяет его дальше по синаптическим связям.
На втором шаге, на основе вектора ![]() , полученного из сети, и целевого вектора
, полученного из сети, и целевого вектора  , соответствующего входным данным, для каждого нейрона выходного слоя вычисляется значение ошибки
, соответствующего входным данным, для каждого нейрона выходного слоя вычисляется значение ошибки ![]() . Эти значения используются для распространения ошибки на все нейроны предыдущего слоя (последнего из скрытых слоев) и для изменения весов связей между скрытым слоем и выходным слоем. Затем для каждого предыдущего слоя рассчитываются значения
. Эти значения используются для распространения ошибки на все нейроны предыдущего слоя (последнего из скрытых слоев) и для изменения весов связей между скрытым слоем и выходным слоем. Затем для каждого предыдущего слоя рассчитываются значения ![]() для соответствующих нейронов. Слои обходятся в порядке, обратном порядку обхода в первой фазе алгоритма.
для соответствующих нейронов. Слои обходятся в порядке, обратном порядку обхода в первой фазе алгоритма.
Рассмотрим произвольный скрытый слой с функцией активации ![]() . Пусть в нем находится I нейронов, а в следующем слое находится
. Пусть в нем находится I нейронов, а в следующем слое находится 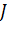 неронов. Рассмотрим i-й нейрон. Он связан со всеми нейронами следующего слоя, и для каждого из них уже подсчитано соответствующее значение ошибки
неронов. Рассмотрим i-й нейрон. Он связан со всеми нейронами следующего слоя, и для каждого из них уже подсчитано соответствующее значение ошибки ![]() . Также, в ходе фазы прямого распространения было вычислено значение входа нейрона
. Также, в ходе фазы прямого распространения было вычислено значение входа нейрона ![]() . Тогда для i-го нейрона значение
. Тогда для i-го нейрона значение ![]() будет рассчитываться по следующей формуле:
будет рассчитываться по следующей формуле:
| (34) |
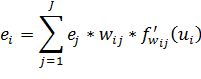
Нет необходимости считать значения ошибок для входного слоя, но веса, связывающие входной слой и скрытый, также будут модифицированы на следующем шаге алгоритма.
После того, как значения ошибок для всех нейронов всех слоев вычислены, можно приступать к корректировке весовых коэффициентов. Значение веса ![]() , соответствующее синаптической связи, соединяющей i-й нейрон скрытого слоя с j-м нейроном следующего слоя, изменяется по следующей формуле:
, соответствующее синаптической связи, соединяющей i-й нейрон скрытого слоя с j-м нейроном следующего слоя, изменяется по следующей формуле:
| (35) |
![]() – это значение сигнала, которое было передано по синаптической связи между i-м нейроном скрытого слоя и j-м нейроном выходного слоя, или, другими словами, выходное значение i-го нейрона,
– это значение сигнала, которое было передано по синаптической связи между i-м нейроном скрытого слоя и j-м нейроном выходного слоя, или, другими словами, выходное значение i-го нейрона, 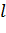 - скорость обучения, она задает скорость изменения весов. Для связей, соединяющих входной слой с первым скрытым слоем, формула примет следующий вид:
- скорость обучения, она задает скорость изменения весов. Для связей, соединяющих входной слой с первым скрытым слоем, формула примет следующий вид:
| (36) |
где ![]() - это i-й компонент входного вектора
- это i-й компонент входного вектора ![]() .
.
Обучение нейронной сети с помощью алгоритма обратного распространения ошибки является вычислительно сложной задачей. Несмотря на распространение высокоскоростных вычислительных систем, обучение сети может занять несколько часов или дней. По этой причине, необходимо рассмотреть некоторые модификации исходного алгоритма, позволяющие увеличить скорость обучения.
Все возможные способы ускорения алгоритма можно разбить на две категории. В первую категорию входят эвристические алгоритмы, основанные на некоторых предположениях относительно метода обучения. Во второй группе находятся алгоритмы численной оптимизации скорости обучения.
2.4.3.1 Метод моментов
Одним из способов увеличения скорости обучения, является использование для модификации весов значения не только текущего градиента ошибки, но и предыдущего. В некоторых случаях это позволяет получить значительное уменьшение времени, затрачиваемого на тренировку.
Другое преимущество этого метода можно обнаружить, если в наборе примеров для тренировки есть несколько примеров, которые значительно отличаются от основной массы данных. В таком случае можно предположить, что они являются ошибочными. Такие данные могут появляться, например, вследствие наложения шума. Если не использовать данную модификацию алгоритма, то для того, чтобы избежать деструктивного влияния на сеть этих примеров, исследователь может установить низкую скорость обучения, но это замедлит весь процесс обучения [4].
Рассмотрим, как изменятся формулы для расчета величины изменения весов. Для начала, необходимо сохранить значения весов, которые использовались для одного или нескольких предыдущих тренировочных примеров. Тогда, для случая использования только одного предыдущего значения весов, формула будет выглядеть следующим образом:
| (37) |
Где, соответственно, ![]() - значение веса на t-м шаге, – скорость обучения,
- значение веса на t-м шаге, – скорость обучения, 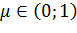 - заданная исследователем константа.
- заданная исследователем константа.
В случае если несколько подряд идущих тренировочных примеров требуют изменения весов в одном направлении, то метод моментов позволяет менять веса на большую величину, даже при небольшой заданной скорости обучения. Следовательно, это делает возможным установку небольшой скорости обучения, что позволит избежать резкого изменения весов сети при встрече с примером, который вызовет большое значение ошибки.
Дополнительным плюсом данной модификации метода является то, что изменения весов идут не в направлении градиента, а в направлении комбинации текущего и нескольких предыдущих градиентов. Это снижает вероятность того, что в результате обучения будет, достигнут локальный, а не глобальный минимум.
Недостатком этого метода является то, что в некоторых случаях изменение весов может производиться в направление увеличения значения ошибки. Также, величина скорости обучения в любом случае будет задавать максимальную величину, на которую могут быть изменены веса за один раз [4].
2.4.3.2 Пакетное обновление весов
В некоторых случаях выгодным является пакетное обновление весов. В этой модификации алгоритма веса обновляются не сразу. Вместо этого, находится среднее значение величины изменения весов для нескольких наборов данных, которое и используется для изменения весов.
К сожалению, подобная схема обновления весов иногда приводит к увеличению шанса оказаться в локальном минимуме функции ошибки [4].
2.4.3.3 Адаптивная скорость обучения
Так как одним из главных факторов, от которых зависит время, необходимое для обучения нейронной сети, является коэффициент скорости обучения, то интерес представляют алгоритмы, позволяющие изменять его по ходу обучения. Одним из наиболее развиваемых методов является дельта-бар-дельта алгоритм.
В основе этого метода лежит идея позволить каждому весовому коэффициенту ![]() иметь собственную скорость обучения, а также использование эвристических правил для изменения этой скорости в ходе обучения сети:
иметь собственную скорость обучения, а также использование эвристических правил для изменения этой скорости в ходе обучения сети:
· если для несколько подряд идущих тренировочных образцов изменение веса при некоторой синаптической связи происходит в одну и ту же сторону, то скорость обучения, соответствующая этой связи, увеличивается;
· если изменение веса происходит каждый раз в другую сторону, то соответствующий коэффициент уменьшается.
Как показывает практика, применение подобной модификации алгоритма обратного распространения ошибки, как правило, приводит к увеличению скорости обучения [4]. Этот алгоритм, в ходе своей работы, будет изменять веса на большие величины, если значение минимума функции ошибки находится далеко от текущего положения. При приближении к минимуму, величина, на которую будут изменяться веса в ходе обучения, будет уменьшаться [14].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
