

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Обновления весов между двумя слоями на шаге t+1 проходят по следующей формуле:
| (38) |
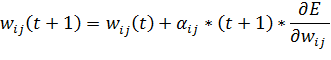
Формула отличается от стандартной, используемой в оригинальном методе обратного распространения ошибки, только коэффициентом скорости обучения. Как видно из формулы, перед обновлением весов необходимо получить значение коэффициента 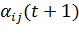 .
.
В ходе обучения, для каждой синаптической связи подсчитывается значение производной вдоль нее:
| (39) |
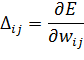
Для определения нового коэффициента обучения необходимо знание ![]() на текущем и предыдущем шагах обучения.
на текущем и предыдущем шагах обучения.
| (40) |
Значение параметра ![]() определяется исследователем исходя из его собственных соображений. Определение значения скорости обучения происходит по следующей формуле:
определяется исследователем исходя из его собственных соображений. Определение значения скорости обучения происходит по следующей формуле:
| (41) |
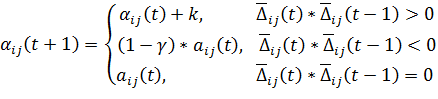
Величины ![]() должны быть заданы исследователем.
должны быть заданы исследователем.
2.4.4 Методы задания начальных значений весов
От того, как будут заданы начальные значения весов, зависит, с какой скоростью будет обучаться сеть, и достигнет ли она глобального минимума функции ошибки, или только локального.
Величина, на которую будут обновлены веса при обучении алгоритмом обратного распространения ошибки, зависит как от значения самой функции активации, вычисленного для данного входа нейрона, так и значения производной функции активации в данной точке. Следовательно, значения весов должны выбираться, исходя из свойств функции активации и свойств ее производной. Например, если выбрать слишком большие веса, то в случае использования сигмоиды в качестве функции активации, ее значение постоянно будет близко к единице, а значение производной – к нулю. Если же выбрать слишком маленькие начальные веса, то величина входного сигнала для скрытого или выходного слоя может оказаться слишком маленькой, что может сильно замедлить обучение [4].
Во многих случаях для задания начальных весов достаточно использовать случайные значения из симметричного относительно нуля интервала, например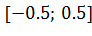 , или другого, подходящего под конкретную задачу.
, или другого, подходящего под конкретную задачу.
2.5 Кодирование классов
При использовании нейронных сетей для решения задачи классификации, необходимо решить, каким образом представить классы в понятном для сети виде. Один из возможных решений является нумерация классов в некотором порядке и кодирование каждого класса в виде вектора, элементы которого задаются формулой (42).
| (42) |
Где ![]() – i-й элемент вектора, j – номер класса,
– i-й элемент вектора, j – номер класса, ![]() - символ Кронекера [2].
- символ Кронекера [2].
2.6 Выводы по разделу
Рассмотрены описанные в данном разделе нейросетевые парадигмы с точки зрения их применимости к решению задач классификации винно-водочных изделий.
Так как нет оснований делать предположение о линейной разделимости классов, следовательно, стоит отказаться от использования однослойного персептрона. Тогда для построения классификатора необходимо использовать многослойный персептрон, радиально-базисную сеть или метод опорных векторов.
Радиально-базисная сеть способна классифицировать образы с точностью, равной точности многослойного персептрона, но часто это требует большего количества элементов [1].
Рассматриваемая задача содержит достаточно большого количества доступных примеров, что является необходимым требованием для успешного решения задачи классификации с помощью многослойного персептрона, обучаемого алгоритмом обратного распространения ошибки [1].
Основываясь на приведенных особенностях применения различных методов, в данной работе для решения задачи классификации было решено использовать многослойный персептрон, обучаемый методом обратного распространения ошибки. Также будут рассмотрены модификации метода обучения, позволяющие улучшить качество полученной в результате сети.
3 Построение классификатора
3.1 Постановка задачи
Исходный набор данных содержит 4898 примеров для белых вин и 1599 примеров для красных вин. Каждый пример состоит из 11 атрибутов и номера класса. Атрибуты характеризуют следующие химические параметры вина:
1. Летучая кислотность;
2. Активная кислотность;
3. Содержание лимонной кислоты;
4. Остаточный сахар;
5. Хлориды;
6. Количество свободной двуокиси серы;
7. Общее количество двуокиси серы;
8. Плотность;
9. Общая кислотность;
10. Количество сульфатов;
11. Содержание алкоголя.
Целевым параметром является численно выраженное качество вина, которое для известных примеров принимает значение от 3 до 9 включительно.
Необходимо разработать нейросетевой классификатор, позволяющий по набору входных признаков определить класс качества вина.
3.2 Нормировка данных
Большое значение некоторой переменной входного вектора не означает, что она оказывает такое же большое влияние на определение результата.
Следовательно, необходимо привести все данные к некоторому единому знаменателю. Для каждого признака из входного вектора ![]() , независимо от других признаков, вычисляется среднее значение и значение стандартного отклонения:
, независимо от других признаков, вычисляется среднее значение и значение стандартного отклонения:
| (43) |
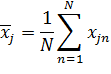
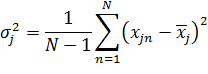
где j - номер признака, ![]() - общее число примеров. Затем выполняется следующее линейное преобразование:
- общее число примеров. Затем выполняется следующее линейное преобразование:
| (44) |
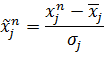
У преобразованных признаков значение математического ожидания равно 0, а значение стандартного отклонения равно 1. В таблице Таблица 1 показаны характеристики исходных данных.
Таблица 1
Характеристики исходных данных
Признак, № | Максимальное значение | Минимальное значение | Математическое ожидание | Стандартное отклонение |
1 | 15.9 | 3.8 | 7.2153 | 1.2964 |
2 | 1.58 | 0.08 | 0.33967 | 0.16464 |
3 | 1.66 | 0.0 | 0.31863 | 0.14532 |
4 | 65.8 | 0.6 | 5.4432 | 4.7578 |
5 | 0.611 | 0.009 | 0.056034 | 0.035034 |
6 | 289.0 | 1.0 | 30.525 | 17.749 |
7 | 440.0 | 6.0 | 115.74 | 56.522 |
8 | 1.039 | 0.98711 | 0.9947 | 0.0029987 |
9 | 4.01 | 2.72 | 3.2185 | 0.16079 |
10 | 2.0 | 0.22 | 0.53127 | 0.14881 |
11 | 14.9 | 8.0 | 10.492 | 1.1927 |
Так как это линейное преобразование, то оно могло бы быть проведено первым слоем сети прямого распространения, но тогда возникает вопрос о том, какие изначальные значения весов необходимо использовать, чтобы учесть разность в порядках значений разных признаков. При использовании нормализованных данных, для всех весов можно задать начальное значение порядка единицы.
В таблице Таблица 2 показаны характеристики преобразованных данных. У всех признаков стандартное отклонение равно 1, а математическое ожидание равно 0.
Таблица 2
Характеристики преобразованных данных
Признак, № | Максимальное значение | Минимальное значение |
1 | 6.6989 | -2.6344, |
2 | 7.5338 | -1.5772, |
3 | 9.2306 | -2.1927, |
4 | 12.686 | -1.018, |
5 | 15.841 | -1.3425, |
6 | 14.562 | -1.6635, |
7 | 5.7368 | -1.9416, |
8 | 14.768 | -2.53, |
9 | 4.9227 | -3.1004, |
10 | 9.8701 | -2.0918, |
11 | 3.6959 | -2.0892 |
3.3 Кодирование классов
Целевой параметр качества для элементов выборки меняется от 3 до 9, то есть в выборке отсутствует информация о винах со значением качества ниже 3 или выше 9. Поэтому было принято решение задать 7 классов. Класс под номером 1 будет соответствовать значению качества равному 3, а класс с номером 7 будет соответствовать значению качества равному 9. Для кодирования будем использовать способ задания класса в виде вектора с 1 на позиции с номером класса, и с 0 на остальных позициях.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
