

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Суть регрессионного анализа сводится к установлению вида уравнения регрессии.
Для составления регрессионного уравнения определяют вид зависимости: прямая, гипербола, парабола, логистическая кривая и прочие. Чтобы предварительно определить наличие взаимосвязи между величинами строят так называемое корреляционное поле (см. рис. 3.1)
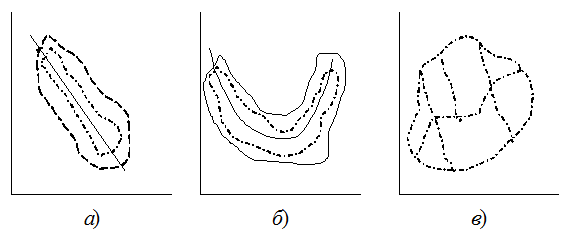
а) – Линейная обратная; б) - Гиперболическая в) - Стохастическая;
Рисунок 3.1. Корреляционное поле
![]() (3.1)
(3.1)
Численное значение коэффициентов регрессионной модели определяют методом наименьших квадратов, который требует, чтобы:
![]() (5.2)
(5.2)
или 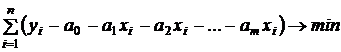 (5.3)
(5.3)
Чтобы найти решение необходимо найти экстремумы функции, а для этого ее необходимо продифференцировать по количеству коэффициентов, т. е. т+1 (раз):
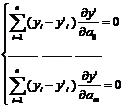 . (5.4)
. (5.4)
В общем случае систему решить нельзя, а иногда параметры 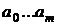 входят нелинейно, то решение сложно громоздко. Например, для линейной регрессии от одного фактора:
входят нелинейно, то решение сложно громоздко. Например, для линейной регрессии от одного фактора:
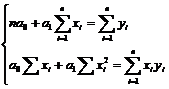 , (5.5)
, (5.5)
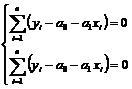 , (5.6)
, (5.6)
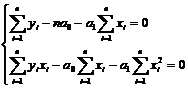 , (5.7)
, (5.7)
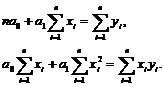 (5.8); (5.9)
(5.8); (5.9)
Параметр а1 в уравнении регрессии (коэффициент регрессии) геометрически представляет наклон линии регрессии на графике и физически указывает меру, в которой изменяется переменная результирующего признака у от фактора х. что касается свободного параметра а0, то придать ему физический смысл невозможно.
3. Методы установления законов распределения
При решении задач на АТ необходимо обрабатывать большое количество экспериментов или статистических данных для проверки гипотез о подчинении их определенному закону распределения. Только при очень большом числе наблюдений элементы случайности сглаживаются и случайные явления в полной мере обнаруживает присущую ему закономерность.
Обычно число наблюдений ограничено важно подобрать такую кривую распределения, чтобы выразить лишь существенные, но не случайные черты данных. Такая задача называется задачей выравнивания статистических данных. Решение задачи о наилучшем выравнивании является неопределенной и зависит от того, что считать наилучшим. Поэтому, при установлении законов распределения используются следующие приемы.
1. Часто принципиальный характер кривой известен из теоретических соображений, связанных с существом задачи, или из аналитических задач, а из опыта (эксперимента) нужно определить лишь входящие в закон численные параметры.
2. В некоторых случаях теоретическую кривую выбирают, учитывая внешний вид статистического распределения (гистограммы).
3. Иногда полезно использовать систему кривых Джонсона или Пирсона, каждая из которых, в общем случае, зависит от четырех параметров, а ее выбор можно осуществить с помощью специально разработанных графиков.
4. При использовании ЭВМ, при заданных статистических данных определить несколько законов распределения и выбрать наилучший (?!). В качестве критерия: 1 – наилучшее согласие теоретического и эмпирического распределений; 2 – минимум параметров; 3 – необходимость (и возможность) дальнейшего использования.
Методы определения параметров закона распределения:
- метод моментов: параметры теоретической кривой должны быть равны соответствующим статистическим характеристикам (самый распространенный метод);
- метод наименьших квадратов: сумма квадратов отклонений теоретической кривой от эмпирических данных должны быть минимальны;
- метод наибольшего правдоподобия: пусть плотность вероятности f(t) случайной величины Т зависит от параметра а (например – среднее), которое нужно определить на основании значений ![]() . Функция правдоподобия
. Функция правдоподобия
![]() (3.1)
(3.1)
Значение а определяется по правилам дифференциального исчисления.
Этот метод дает оценки, имеющие min дисперсию и наилучшим образом использовать имеющуюся информацию. Однако на практике он требует решения сложных систем уравнений.
4. Последовательность построения законов распределения
Вычислительная схема определения численных характеристик закона распределения случайных величин в предположении, что закон известен, выполняет несколько этапов:
1 – представление экспериментных или статистических данных рода или, графических, - в виде гистограммы,. для непрерывных случайных величин или полигона - для дискретных;
2 – определение параметров закона распределения;
3 – проверка согласия теоретического или статистического распределения по критериям согласия Пирсона или Колмогорова;
4 – построение графика теоретической кривой распределения (если это необходимо).
Пример. Имеются статистические данные случайной величины Т: 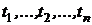 . Для наглядности и компактности данные преобразуют в статистический ряд. В случае непрерывных случайных величин определяют размах
. Для наглядности и компактности данные преобразуют в статистический ряд. В случае непрерывных случайных величин определяют размах ![]() . Затем делят R на интервалы или «разряды» с шириной, равной h. При этом обычно h определяют из соотношения:
. Затем делят R на интервалы или «разряды» с шириной, равной h. При этом обычно h определяют из соотношения:
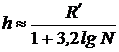 , (3.2)
, (3.2)
где N – размер выборки (количество наблюдений или данных). Соответственно получают 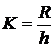 интервалов и подсчитывают количество значений Т, попадающих в i-ый интервал (mi).
интервалов и подсчитывают количество значений Т, попадающих в i-ый интервал (mi).
Полученные числа делят на общее число наблюдений:
![]() (3.3)
(3.3)
и получают относительную частоту (частость), соответствующую данному (i) интервалу. Поделив ri на ширину интервала hi, получают эмпирическую плотность:
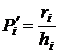 (3.4)
(3.4)
Для дискретной случайной величины, принимающей значения 1,2,3,…,N, подсчитывают значения 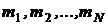 и определяют частости ri. Сумма частостей равна 1.
и определяют частости ri. Сумма частостей равна 1.
Обычно из физических соображений уменьшают tmin и увеличивают tmax до значений, близким и целочисленным. (как можно меньше значащих цифр). Аналогичным образом поступают и в отношении h.
Равенство h для всех интервалов удобно, но не всегда приемлемо. Известно, что количество значений в интервале (частота) должно быть не менее 5 (это тоже не догма). Если оказывается так, что это условие для какого-либо интервала не выполняется, то объединяют его смежным (справа или слева – смотря на обстоятельства).
Важно (!) определить, к каком интервалу отнести наблюдение, если оно попадает на границу между интервалами. В этом случае принято добавлять к каждому из смежных интервалов оп 0,5.
Для наглядности статистические данные оформляют в виде гистограммы по частотам или частостям (предпочтительней). пользуясь данными статистического ряда, можно приближенно построить функцию (интеграл) F(t) распределения случайной величины Т. Обычно достаточно построить ее по граничным точкам или серединному интервалу (лучше), используя значения ri или p`ihi
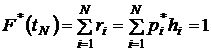 (3.5)
(3.5)
Пример. Распределение длин участков дороги с постоянным уклоном.
Данные (м): 36,160,290,160,183,96,132,146,258,68,95,211,95,111,80,120,240,270,60,219,60,938,140,153,104,156,140,170,140,50,75,50,255,300,180,80,171,120,118,96,58,116,305,180,960,137,108,192,108,95,360,90,324,184,236,424.
Min=36. max=960 lg 56=1,748 h=140 N`=6.6
Таблица 3.1. Статистическая обработка длин участков
№ интервала | Граница интервала | Встречаемость (обозначается точками на каждое наблюдение) | Частота | Частость | Ширина интервала (только для непрерывных случайных величин) | Эмпирическая | |
плотность (только для непрерывных случайных величин) | функция | ||||||
| 0-140 | * * | 27,5 | 0,491 | 140 | 0,00351 | 0,491 |
| 140-280 | * * : | 21,5 | 0,384 | 140 | 0,00274 | 0,875 |
3 | 280-420 | : : | 4 | 0,071 | 140 | 0,00051 | 0,946 |
4 | 420-560 |
| 1 | 0,018 | 140 | 0,00013 | 0,964 |
| 560-700 | - | - | - | 140 | - | 0,964 |
6 | 700-840 | - | - | - | 140 480 | 0,00009 | 0,964 |
7 | 840-980 | : | 2 | 0,036 | 140 | 0,00026 | 1,000 |
Всего | 56 | 1,000 | - | - | - |
5. Критерии согласия

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
