
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В первой процедуре оценку текущего отсчета s(n) определяют как сумму р предшествующих отсчетов. Порядок предсказания р выбирают равным 8-12. Определение коэффициентов предсказания ![]()
![]() фильтра-анализатора производят в блоке формантного анализа из условия минимизации среднеквадратичного значения ошибки предсказания (т. е. первого остаточного сигнала) на интервале сегмента. Вычисленные значения коэффициентов предсказания используют в фильтре удаления формант кодера, на выходе которого получают сигнал
фильтра-анализатора производят в блоке формантного анализа из условия минимизации среднеквадратичного значения ошибки предсказания (т. е. первого остаточного сигнала) на интервале сегмента. Вычисленные значения коэффициентов предсказания используют в фильтре удаления формант кодера, на выходе которого получают сигнал ![]()
![]() , свободный от квазипериодических составляющих — формант. Информацию о формантах несут переданные на приемный конец параметры фильтра
, свободный от квазипериодических составляющих — формант. Информацию о формантах несут переданные на приемный конец параметры фильтра ![]()
![]() , либо связанные с ними коэффициенты частичной корреляции (коэффициенты отражения).
, либо связанные с ними коэффициенты частичной корреляции (коэффициенты отражения).
Во второй процедуре с учетом того, что основной тон характеризуется всего двумя параметрами — амплитудой и периодом, передаточная функция фильтра удаления основного тона ![]()
![]() описывается более простым по сравнению с выражением
описывается более простым по сравнению с выражением
![]() (29)
(29)
где g — единственный коэффициент предсказания, характеризующий амплитуду основного тона. Задержка d определяет период основного тона, её значение обычно заключается в пределах от 20 до 160 интервалов дискретизации сигнала, что соответствует диапазону частот основного тона 50...400 Гц. Известно, что значение основного тона для разных голосов может изменяться почти в 10 раз — от 2 до 18 мс. Это обстоятельство создает немало трудностей при оценке основного тона, так как слух очень чувствителен к его искажениям. Методов измерения основного тона известно очень много, и вместе с тем метод, не требующий чрезмерной задержки, пока не найден.
Несмотря на относительную простоту выражения (29), анализ и удаление основного тона является более сложной процедурой по сравнению с формантным анализом. Это обусловлено существенно большим периодом ОТ и сложностью выявления корреляции между отсчетами на большом временном интервале. Кроме того, период и амплитуда основного тона очень важны для точного восстановления речи. Именно поэтому на этапе долговременного анализа сегмент речи разделяют на 4 подсегмента по 5 мс, содержащие по 40 отсчетов. Параметры g и d определяют для каждого подсегмента по отдельности и используют в фильтре удаления основного тона. Их также передают на приемный конец в декодер, где используют при синтезе речевого сигнала.
Решаемая задача третьей процедуры — при минимальном объеме информации о сигнале возбуждения обеспечить приемлемое качество восстановленного сигнала. Для достижения этого обработку второго остаточного сигнала производят отдельно для каждого подсегмента из 40 отсчетов. Суть аппроксимации состоит в том, что второй остаточный сигнал моделируют в виде определенного числа импульсов на интервале подсегмента. Представление сигнала возбуждения в виде последовательности импульсов с неравномерно распределенными интервалами и различными амплитудами позволяет более точно учесть особенности возбуждения голосового тракта человека.
Переданные по каналу связи параметры аппроксимации второго остаточного сигнала, параметры основного тона g и d, коэффициенты формантного фильтра ![]()
![]() поступают на соответствующие блоки декодера (рис. 27). В любом случае по каналу связи вместо самой речи передают так или иначе выделенные и квантованные параметры кратковременного и долговременного предсказания, амплитуду и период основного тона, параметры возбуждения. В декодере липредора по принятым параметрам восстанавливают сигнал возбуждения, пропускают его через синтезирующий фильтр и восстанавливают речь.
поступают на соответствующие блоки декодера (рис. 27). В любом случае по каналу связи вместо самой речи передают так или иначе выделенные и квантованные параметры кратковременного и долговременного предсказания, амплитуду и период основного тона, параметры возбуждения. В декодере липредора по принятым параметрам восстанавливают сигнал возбуждения, пропускают его через синтезирующий фильтр и восстанавливают речь.
Синтез сигнала начинают с восстановления второго остаточного сигнала ![]()
![]() , выполняемого генератором возбуждения. Восстановленный сигнал несколько отличается от второго остаточного сигнала
, выполняемого генератором возбуждения. Восстановленный сигнал несколько отличается от второго остаточного сигнала ![]()
![]() в кодере из-за погрешности аппроксимации. Восстановленный сигнал
в кодере из-за погрешности аппроксимации. Восстановленный сигнал ![]()
![]() пропускают через фильтр восстановления основного тона, передаточную характеристику которого
пропускают через фильтр восстановления основного тона, передаточную характеристику которого ![]()
![]() устанавливают обратной характеристике (29) фильтра удаления основного тона кодера:
устанавливают обратной характеристике (29) фильтра удаления основного тона кодера:
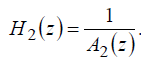 (30)
(30)
На выходе этого фильтра получают восстановленный первый остаточный сигнал ![]()
![]() , который включает основной тон. Наконец, фильтр восстановления формант с передаточной функцией H(z) восстанавливает формантные составляющие сигнала.
, который включает основной тон. Наконец, фильтр восстановления формант с передаточной функцией H(z) восстанавливает формантные составляющие сигнала.
Восстановленный сигнал достаточно близок к исходному сигналу на входе кодера s(n). Выполнив цифро-аналоговое преобразование и пропустив сигнал через ФНЧ, получают восстановленный аналоговый сигнал. Все процедуры обработки сигнала в кодере и декодере выполняются цифровыми методами. Показанные на рис. 27 модули липредера фактически являются блоками программного обеспечения.
6. Формантные вокодеры.
В формантных вокодерах спектральная огибающая речевого сигнала аппроксимируется комбинацией нескольких простых резонансных кривых. Принципы построения форматного вокодера во многом аналогичны принципам естественного речеобразования и приёма речи. Поскольку речевой тракт представляет собой комплекс резонаторов, резонансные частоты и добротности которых изменяются в процессе речи в соответствии с сигналами, идущими из центральной нервной системы, то и в формантном вокодере происходит выделение из речевого сигнала управляющих сигналов (сигнал-параметров), которые на приёме воздействуют на резонансные контуры и воспроизводят требуемую огибающую спектра. Основными параметрами форманты являются частота, уровень и ширина её спектра на уровне —3 дБ. Гласные звуки полностью характеризуются формантами. Ряд согласных звуков, особенно взрывных, характеризуются не самими формантами, а формантными переходами, т. е. тенденцией и скоростью изменения формант, а для глухих согласных вместо формант лучше пользоваться различного порядка моментами частотного спектра. В данном параграфе все рассуждения относить к формантам, понимая под формантой некоторую обобщенную характеристику, определяемую амплитудой, частотой и занимаемой полосой спектра, т. е. величинами, зависящими от спектральных моментов нулевого, первого и второго порядков, а также их изменениями во времени.
В существующих формантных вокодерах из речи выделяются не более трех-четырех формант, если не считать введения в некоторые вокодеры специальных устройств для определения моментов спектра в области частот выше 4000 Гц, предназначенных главным образом для анализа щелевых звуков. При управлении тремя параметрами резонансных контуров (резонансной частотой, амплитудой колебаний и добротностью) можно наиболее точно по сравнению с другими параметрическими методами приближения воспроизвести на выходе вокодера спектральную огибающую. С учётом двух параметров основного тона (частоты и уровня) и даже четырёх формант (каждая с тремя параметрами) необходимо передать 14 сигналов (сигнал-параметров), не считая сигнала тон-шум. Следовательно, по числу сигналов формантный вокодер тогда будет соответствовать 12-канальному полосному вокодеру. А так как для передачи формантных параметров необходимы полосы более узкие, чем для полосных вокодеров, в отношении занимаемой ширины канала преимущество будут иметь формантные вокодеры по сравнению с полосными. К этому надо добавить, что при небольшом ущербе для индивидуальности звучания можно ограничиться передачей только частот и амплитуд трех формант. Так и сделано в большинстве разработок формантных вокодеров.
Основными характеристиками формантных параметров являются их диапазоны и скорость изменения во времени. Так, для каждой из формантных частот важно знать распределение ее по частотному диапазону или по крайней мере диапазон, в котором она почти всегда находится в течение передачи звуков речи. Для уровней каждой из формант важно знать их распределение по динамическому диапазону. Это — статические характеристики, но важна передача и динамических характеристик формант: знака и скорости изменения частоты форманты, знака к скорости изменения её уровня.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
