
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
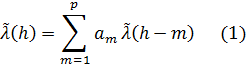
Где ![]()
![]() – речевой сигнал в предшествующие моменты опробывания,
– речевой сигнал в предшествующие моменты опробывания, ![]()
![]() – коэффициенты предсказания,
– коэффициенты предсказания, ![]()
![]() .
.
Интервалы времени между моментами опробываний определяются частотой дискретизации ![]()
![]() . В момент
. В момент ![]()
![]() , когда известны не только
, когда известны не только ![]()
![]() , но и истинное значение речевого сигнала
, но и истинное значение речевого сигнала ![]()
![]() , можно определить ошибку предсказания:
, можно определить ошибку предсказания:
![]()
Затем подобрать коэффициенты предсказания ![]()
![]() таким образом, чтобы ошибка предсказания была минимальной. Обычно в качестве критерия минимизации используется минимум среднеквадратической ошибки. В этом случае требуется определить такие значения
таким образом, чтобы ошибка предсказания была минимальной. Обычно в качестве критерия минимизации используется минимум среднеквадратической ошибки. В этом случае требуется определить такие значения ![]()
![]() , при которых
, при которых ![]()
![]() . Задача минимизации сводится к решению системы линейных уравнений относительно
. Задача минимизации сводится к решению системы линейных уравнений относительно ![]()
![]() . Вычисление ошибки предсказания, согласно (2), равносильно применению цифрового фильтра, имитирующего речевой тракт. Поэтому преобразования, соответствующие (2), называют инверсной фильтрацией. Усреднение ошибки предсказания производится на интервале
. Вычисление ошибки предсказания, согласно (2), равносильно применению цифрового фильтра, имитирующего речевой тракт. Поэтому преобразования, соответствующие (2), называют инверсной фильтрацией. Усреднение ошибки предсказания производится на интервале ![]()
![]() , выборок, образующих кадр (сегмент речевого сигнала). Желательно, чтобы длительность кадра соответствовала длительности анализируемого звука речи, однако технически выполнить это достаточно сложно. Поэтому обычно принимают
, выборок, образующих кадр (сегмент речевого сигнала). Желательно, чтобы длительность кадра соответствовала длительности анализируемого звука речи, однако технически выполнить это достаточно сложно. Поэтому обычно принимают ![]()
![]() , что при
, что при ![]()
![]() соответствует длине кадра
соответствует длине кадра ![]()
![]() .
.
Удовлетворительного качества синтезируемых речевых сигналов можно достичь при использовании не менее десяти коэффициентов предсказания ![]()
![]() , что в (1) соответствует
, что в (1) соответствует ![]()
![]() . Учитывая это, в анализаторе ЛПК-вокодера необходимо решение 100–200 линейных уравнений с 10–12 неизвестными.
. Учитывая это, в анализаторе ЛПК-вокодера необходимо решение 100–200 линейных уравнений с 10–12 неизвестными.
По каналу связи передаются коэффициенты предсказания. Их значения используются в качестве параметров в рекурсивном цифровом фильтре, на вход которого подаются сигналы возбуждения. В качестве сигналов возбуждения в ЛПК-вокодере используются такие же сигналы, которые имеют место на выходе генераторов речевого спектра в обычных полосных вокодерах. При воспроизведении вокализованных звуков – это последовательности импульсов основного тона, а при воспроизведении невокализованных звуков — это случайная последовательность импульсов, формируемых генератором шума.
Вместо коэффициентов предсказания в большинстве вариантов схем ЛПК-
вокодеров предусматривается получение эквивалентного набора величин, называемых коэффициентами отражения ![]()
![]() . Эти параметры менее чувствительны к квантованию, чем коэффициенты предсказания
. Эти параметры менее чувствительны к квантованию, чем коэффициенты предсказания ![]()
![]() . Наборы параметров
. Наборы параметров ![]()
![]() и
и ![]()
![]() связаны между собой набором стандартных рекуррентных соотношений. Подробнее модель речевого сигнала на основе линейного предсказания будет описана ниже в разделе описания липредеров.
связаны между собой набором стандартных рекуррентных соотношений. Подробнее модель речевого сигнала на основе линейного предсказания будет описана ниже в разделе описания липредеров.
Таким образом, качество (разборчивость, натуральность) синтезированной речи зависит от числа спектральных каналов, на которые разделяется в анализаторе спектр речевого сигнала. Так, 16-канальный полосный вокодер позволяет воспроизвести спектральную огибающую сигнала с точностью до ширины частотных групп слуха, в пределах которых ухо не замечает перемещения максимума спектра. При этом достигаемая скорость передачи составляет 3 (бита) х 50 (Гц) х 16 (каналов) = 2,4 кбит/с. Число каналов (фильтров) и ширина полосы пропускания частот могут варьироваться, в соответствие с этим будет меняться и качество воспроизведения звука. Полосные вокодеры обеспечивают высокую разборчивость речи (до 85 % разборчивости слогов), но натуральность ее, как и в других системах вокодеров, оставляет желать лучшего.
К основным недостаткам полосных вокодеров, ухудшающим разборчивость синтезированной речи, относят появление больших интерференционных искажений огибающей спектра, возникающих из-за несогласованности ФЧХ полосных фильтров, а также искажения спектральной картины в формантной области, связанные с попаданием форманты в межфильтровую зону.
2. Ортогональные вокодеры.
Принцип действия ортогональных вокодеров базируется на возможности представления спектральной огибающей речевого сигнала в виде суммы ортогональных функций. В этих случаях, в отличие от других вокодеров, спектральная огибающая на приёме воспроизводится не по отдельным ординатам, а в виде суммы тех же ортогональных функций, т. е.:
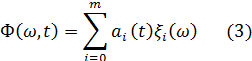
Где ![]()
![]() – i-ый член ортогонального ряда;
– i-ый член ортогонального ряда; ![]()
![]() – его коэффициент. При этом согласно условиям ортогональности:
– его коэффициент. При этом согласно условиям ортогональности:
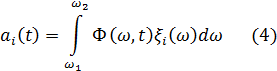
где ![]()
![]() – интервал разложения спектральной огибающей, т. е. передаваемый диапазон частот.
– интервал разложения спектральной огибающей, т. е. передаваемый диапазон частот.
Применение теории приближения функций позволяет подобрать наиболее
подходящие ортогональные функции для представления спектральных огибающих эталонного речевого сигнала, создаваемого на выходе микрофонов хорошего качества, хотя бы в телефонной полосе частот.
Ориентируясь на такой речевой сигнал, можно легко установить, что количество функций, «подходящих» для приближения, ограничено. Подходящими, очевидно, будут функции, которые при наименьшем числе членов суммы будут давать наибольшую точность приближения. Кроме того, при выборе приближающих функций важно иметь в виду и возможность простого аппаратурного выделения их из речевого сигнала и воссоздания на приёмном конце.
К настоящему времени наиболее полно разработан метод представления спектральной огибающей в виде суммы гармонических функций. На основе гармонического представления разработан гармонический вокодер. Через канал связи передаются коэффициенты разложения в тригонометрический ряд усредненной за 25—20 мс спектральной огибающей речевого сигнала. По этим коэффициентам на приёмной стороне осуществляется восстановление спектральной огибающей. Число коэффициентов зависит от требуемой точности воспроизведения спектральной огибающей.
При реализации вокодера в цифровом варианте коэффициенты ряда Фурье можно вычислить прямым применением формулы (4). В обычном варианте можно использовать матричную схему пересчета ординат спектра в коэффициенты ряда Фурье согласно выражениям:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
