
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
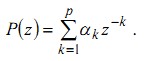
(19)
Разность между истинным (известным точно) s(n) и предсказанным ![]()
![]() значениями отсчета определяет погрешность (остаток) предсказания
значениями отсчета определяет погрешность (остаток) предсказания
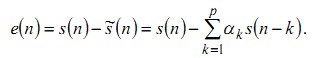
(20)
Из выражения (20) видно, что погрешность предсказания представляет собой сигнал на выходе системы с передаточной функцией.
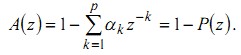
(21)
Сравнение формул (17) и (20) показывает, что если сигнал точно удовлетворяет модели (17) и ak = ?k то e(n) = Gu(n) . Таким образом, фильтр погрешности, предсказания A(z) является обратным фильтром для системы H(z) , соответствующей уравнению (16), т. е.
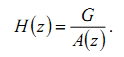 (22)
(22)
Выражение (22) можно трактовать следующим образом: линейная система с переменными параметрами (фактически — модель фильтра голосового тракта) H(z) возбуждается импульсной последовательностью для вокализованных звуков и шумом для невокализованных (см. рис. 22). При этом сигнал возбуждения формируется адаптивным фильтром-анализатором A(z) (21), адаптация которого осуществляется путем изменения коэффициентов линейного предсказания.
Таким образом, в процессе параметрического представления речевого сигнала в системе кодер/декодер используются два цифровых фильтра: в кодере источника в фильтре-анализаторе A(z) определяются коэффициенты предсказания, а в декодере на основе этих коэффициентов с помощью цифрового фильтра H(z) синтезируется эквивалент голосового тракта. Посредством возбуждения этого «эквивалента тракта» формируется синтезированная речь. Заметим, что фильтр-анализатор и фильтр-синтезатор являются рекурсивными, поскольку значение сигнала на их выходах определяется лишь предшествующими отсчетами речевого сигнала.
Прямое z-преобразование последовательности s(n) определяется уравнением:
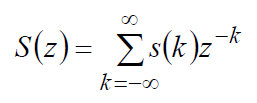 (23)
(23)
А в результате z-преобразования разностного уравнения (20) имеем:
![]() (24)
(24)
где R(z) — z-преобразование выборки (отсчета) ошибки предсказания e(n) на
выходе фильтра-анализатора, имеющего передаточную функцию (21).
Поскольку амплитудно-частотная характеристика фильтра-анализатора A(z) обратна частотной характеристике голосового тракта (следовательно, обратна и огибающей спектра входного сигнала), такой фильтр называется инверсным. Его блок-схема показана на рис. 23. Значения коэффициентов предсказания ![]()
![]() , являются параметрами этого фильтра. Они остаются постоянными на интервале анализируемого сегмента речи (как правило, 20 мс), поскольку линейный предсказатель перенастраивается (т. е. адаптируется) не под каждый речевой отсчет, а под их последовательность. Поэтому ошибка минимизируется на протяжении всего сегмента.
, являются параметрами этого фильтра. Они остаются постоянными на интервале анализируемого сегмента речи (как правило, 20 мс), поскольку линейный предсказатель перенастраивается (т. е. адаптируется) не под каждый речевой отсчет, а под их последовательность. Поэтому ошибка минимизируется на протяжении всего сегмента.
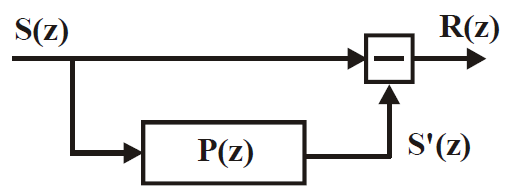
Рисунок 23 - Блок-схема фильтра-анализатора
Инверсный фильтр применяется в кодере для устранения избыточности речевого сигнала. Пропуская через этот фильтр исходный сигнал на выходе получаем сигнал остатка предсказания e(n) (иначе — первый остаточный сигнал). Этот «остаток» содержит периодическую составляющую речевого сигнала, соответствующую основному тону, поскольку в нем устранены внутренние корреляционные связи. В то же время согласно модели речеобразования выходной сигнал инверсного фильтра с оптимально подобранными параметрами будет представлять собой сигнал возбуждения e(n) = Gu(n), R(z), подобный (с точностью до ошибок, определяемых конечностью порядка предсказания р и погрешностью оценки коэффициентов предсказания) сигналу возбуждения u(n) на входе фильтра голосового тракта на рис. 22.
Синтезирующий фильтр находится в декодере и осуществляет формирование речевого сигнала. «Нужная» настройка этого фильтра обеспечивается передачей на приемную сторону коэффициентов предсказателя P(z), используемых в этот момент в кодере, а на вход синтезирующего фильтра подается сигнал возбуждения R(z). Очевидно, что он должен быть максимально «похож» на сигнал остатка предсказания, полученный в кодере.
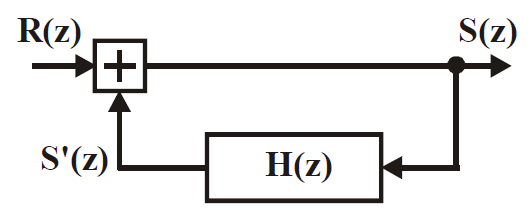
Рисунок 23 - Модель фильтра синтезатора
Модель фильтра-синтезатора (рис. 23) определяется уравнением (22), описывающим модель фильтра голосового тракта. Передаточная функция фильтра-синтезатора H(z) является обратной передаточной характеристике фильтра-анализатора с точностью до скалярного коэффициента усиления G. Это следует из выражения (24):
![]() (25)
(25)
Такая запись уравнения модели речеобразования поясняет механизм получения синтезированного сигнала S(z) на выходе фильтра при воздействии на его вход сигнала возбуждения R(z).
При выполнении анализа к весьма ответственным решениям относится выбор порядка фильтра линейного предсказания (предиктора) р. При кодировании выборки речи обычно берутся с частотой 8кГц, что обеспечивает значение верхней граничной частоты спектра речевого сигнала 4кГц. В полосе 4 кГц максимальное число выделяемых формант обычно равно четырем, что требует применения фильтра как минимум 8-го порядка. Обычно используется 10-полюсный фильтр. Поэтому в таких системах резонансы формант и форма основного спектра моделируются точно. В особо точных схемах используются фильтры более высокого порядка. На рис. 24 показаны огибающие спектров сигналов, синтезированные с помощью фильтров для разных р:
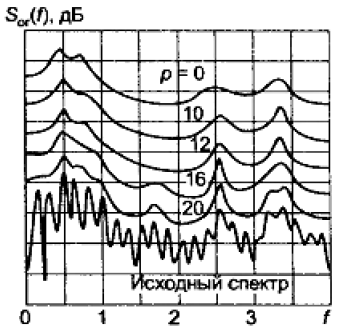
Рисунок 24 – Графики огибающих спектра сигнала
Это свидетельствует о том, что линейное предсказание можно рассматривать как метод кратковременной спектральной оценки речевого сигнала.
Основная задача анализа на основе линейного предсказания заключается в непосредственном определении параметров ![]()
![]() по речевому сигналу с целью получения хороших оценок его спектральных свойств путем использования уравнения (22). Поскольку свойства речевого сигнала изменяются во времени, коэффициенты предсказания должны оцениваться на коротких сегментах речи.
по речевому сигналу с целью получения хороших оценок его спектральных свойств путем использования уравнения (22). Поскольку свойства речевого сигнала изменяются во времени, коэффициенты предсказания должны оцениваться на коротких сегментах речи.
Основным подходом является определение параметров предсказания таким образом, чтобы минимизировать дисперсию погрешности предсказания на коротком сегменте сигнала. При этом предполагается, что полученные параметры являются параметрами системной функции H(z) в модели речеобразования.
Подобный подход приводит к полезным результатам. Во-первых, если ![]()
![]() , тогда
, тогда ![]()
![]() . Для вокализованной речи это означает, что e(n)
. Для вокализованной речи это означает, что e(n)
будет состоять из последовательности импульсов с частотой основного тона, и e(n) будет весьма мало почти все время. Поэтому в данном случае минимизация погрешности предсказания позволит получить требуемые коэффициенты.
Во-вторых, подобная минимизация приводит к линейной системе уравнений, решение которых сравнительно легко приводит к получению параметров предсказания. Кроме того, полученные параметры составляют весьма плодотворную основу для точного описания сигнала.
Для определения коэффициентов предсказания ![]()
![]() необходимо решить систему р линейных уравнений с р неизвестными коэффициентами. Для этого частные производные от
необходимо решить систему р линейных уравнений с р неизвестными коэффициентами. Для этого частные производные от ![]()
![]() по
по ![]()
![]() приравниваются нулю, в результате чего получается система линейных уравнений:
приравниваются нулю, в результате чего получается система линейных уравнений:
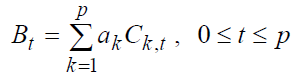 (26)
(26)
где коэффициенты Bt, Ct, k будут рассмотрены ниже.
Система из р линейных уравнений с р неизвестными коэффициентами ![]()
![]() и методы её решения оказываются несколько различными в зависимости от того, на каком сегменте речевого сигнала выполняется поиск коэффициентов предсказания. Если предположить, что сигнал равен нулю вне некоторого интервала(сегмента) 0 ? n ? N-1, то его удобно записать как
и методы её решения оказываются несколько различными в зависимости от того, на каком сегменте речевого сигнала выполняется поиск коэффициентов предсказания. Если предположить, что сигнал равен нулю вне некоторого интервала(сегмента) 0 ? n ? N-1, то его удобно записать как ![]()
![]() где
где ![]()
![]() — окно конечной длительности, например Хемминга, равное нулю вне интервала, m — номер рассматриваемого сегмента сигнала. Длительность окна выбирается равной 10...30 мс, т. е. нескольким периодам основного тона. Тогда для определения коэффициентов предсказания необходимо решить систему уравнений (26), где кратковременная автокорреляционная функция речевого сигнала:
— окно конечной длительности, например Хемминга, равное нулю вне интервала, m — номер рассматриваемого сегмента сигнала. Длительность окна выбирается равной 10...30 мс, т. е. нескольким периодам основного тона. Тогда для определения коэффициентов предсказания необходимо решить систему уравнений (26), где кратковременная автокорреляционная функция речевого сигнала:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
