
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
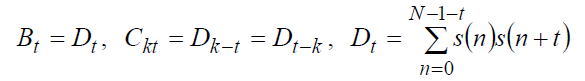 (27)
(27)
Матрица С размером р?р является теплицевой, т. е. симметричной и такой, что элементы на любой диагонали равны между собой, что может быть использовано для получения эффективного алгоритма решения системы уравнений (26). Это первый из методов линейного предсказания, называемый автокорреляционным.
Сегмент речевого сигнала можно определить без умножения на прямоугольное окно. Можно считать, что речевой сигнал не равен нулю вне рассматриваемого сегмента, а сегмент определяется интервалом, на котором вычисляется средний квадрат погрешности. Тогда коэффициенты уравнения (26) вычисляются как:
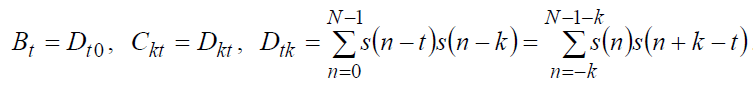 (28)
(28)
Для вычисления Ckt для всех требуемых значений: t и k необходимо использовать значения s(n) на интервале, то есть без ограничения последовательности отсчетов окном конечной длительности. Таким образом, вычисление Ckt приводит не к автокорреляционной, а к взаимокорреляционной функции между двумя очень сходными, но не одинаковыми сегментами речевого сигнала конечной длительности. Матрица С размером р?р является квазикорреляционной симметричной, но не теплицевой. Метод анализа, основанный на изложенном выше способе вычисления Ckt, называется ковариационным, поскольку матрица обладает свойствами ковариационной матрицы.
Полученные тем или иным методом значения коэффициентов фильтра предсказания ![]()
![]() передаются по линии связи. При этом для обеспечения приемлемой точности восстановления значений речевого сигнала в приемнике оказалось необходимым использовать от 8 до 10 битов для цифрового представлениякаждого коэффициента. Поэтому вместо этих коэффициентов обычно передают так называемые коэффициенты отражения, или коэффициенты частичной корреляции (partial correlation, PARCOR) — коэффициенты
передаются по линии связи. При этом для обеспечения приемлемой точности восстановления значений речевого сигнала в приемнике оказалось необходимым использовать от 8 до 10 битов для цифрового представлениякаждого коэффициента. Поэтому вместо этих коэффициентов обычно передают так называемые коэффициенты отражения, или коэффициенты частичной корреляции (partial correlation, PARCOR) — коэффициенты ![]()
![]() , число которых равно числу коэффициентов предсказания
, число которых равно числу коэффициентов предсказания ![]()
![]() , и которые связаны с ними взаимно однозначными нелинейными функциональными соотношениями. Коэффициенты отражения
, и которые связаны с ними взаимно однозначными нелинейными функциональными соотношениями. Коэффициенты отражения ![]()
![]() в силу своих статистических характеристик (они имеют меньший динамический диапазон) требуют для кодирования всего 6 битов на каждый коэффициент. Это приводит к более экономичному использованию линии связи. Например, если порядок фильтра предсказания p = 10 , то общее число битов, выделяемых для одного сегмента, равно 72, включая по 6 битов для кодирования значений коэффициента усиления и периода основного тона. Можно подсчитать при этом, что если значения параметров фильтра будут пересчитываться каждые 15 или 30 мс, то результирующая скорость окажется равной 4800 или 2400 бит/с.
в силу своих статистических характеристик (они имеют меньший динамический диапазон) требуют для кодирования всего 6 битов на каждый коэффициент. Это приводит к более экономичному использованию линии связи. Например, если порядок фильтра предсказания p = 10 , то общее число битов, выделяемых для одного сегмента, равно 72, включая по 6 битов для кодирования значений коэффициента усиления и периода основного тона. Можно подсчитать при этом, что если значения параметров фильтра будут пересчитываться каждые 15 или 30 мс, то результирующая скорость окажется равной 4800 или 2400 бит/с.
Кодирование коэффициентов отражения может быть улучшено дополнительно путем применения неравномерного квантования, когда до кодирования значения этих коэффициентов подвергаются нелинейному преобразованию, которое уменьшает чувствительность коэффициентов отражения к ошибкам квантования. В качестве такого преобразования обычно выбирают обратный гиперболический тангенс или так называемое логарифмическое отношение площадей:
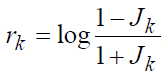
Синтезирующий фильтр H(z) имеет ту же структуру, что и фильтр-анализатор (инверсный) и определяется тем же набором параметров (коэффициентов предсказания ![]()
![]() , или коэффициентов отражения
, или коэффициентов отражения ![]()
![]() , или логарифмических отношений площадей
, или логарифмических отношений площадей ![]()
![]() ), но входы и выходы в анализирующем и синтезирующем фильтрах меняются местами. Если на вход синтезирующего фильтра подать сигнал возбуждения, то на его выходе будет получен речевой сигнал.
), но входы и выходы в анализирующем и синтезирующем фильтрах меняются местами. Если на вход синтезирующего фильтра подать сигнал возбуждения, то на его выходе будет получен речевой сигнал.
На основе вышеизложенного функционируют вокодеры с линейным предсказанием (липредеры, LPC-вокодеры). Первые реализации кодеков с линейным предсказанием были предназначены для передачи данных на низких скоростях — 2,4 и 4,8 кбит/с. На скорости 2,4 кбит/с обеспечивался приемлемый уровень разборчивости речи, однако качество, естественность и узнаваемость речи были неудовлетворительны. Поскольку этот метод сильно зависит от точного воспроизведения человеческой речи, его реализации, как правило, не подходят для сигналов неречевого происхождения.
Различные варианты алгоритмов кодирования отличаются набором передаваемых параметров фильтра, методом формирования сигнала возбуждения и рядом других деталей. Обобщённая блок-схема кодера и декодера изображена на рис. 25.
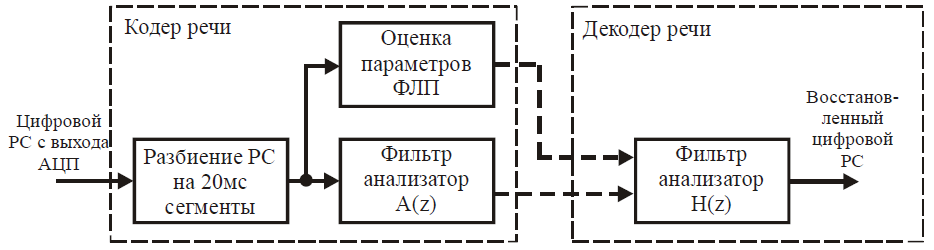
Рисунок 25 – Обобщённая блок-схема кодера/декодера
Обобщённая процедура кодирования речи сводится к следующему алгоритму:
выполняется аналого-цифровое преобразование речевого сигнала; оцифрованный сигнал речи «нарезается» на сегменты длительностью 20 (реже 30) мс; для каждого сегмента вычисляются параметры фильтра линейного предсказания и параметры сигнала возбуждения; вычисляется остаток предсказания как выходной сигнал фильтра с передаточной характеристикой A(z) с параметрами, полученными из оценки для данного сегмента; этот остаток может выступать как сигнал возбуждения на приёмной стороне; параметры фильтра и параметры сигнала возбуждения кодируются по какому-либо закону и передаются в канал связи.При декодировании речи принятый или сгенерированный сигнал возбуждения пропускается через синтезирующий фильтр известной структуры, параметры которого переданы одновременно с сигналом возбуждения. Сигнал на вход анализирующего фильтра поступает непосредственно с выхода АЦП, а выходной сигнал синтезирующего фильтра попадает на вход ЦАП. Такое описание объясняет принцип действия вокодера, но не является технически подробным. Практические схемы заметно сложнее, и это связано в основном со следующими двумя моментами.
Во-первых, речевой сигнал обладает двумя видами внутренних корреляционных связей — кратковременной и долговременной избыточностью, поэтому в подавляющем большинстве современных речевых кодеков используется два предсказателя: кратковременный (STP) и долговременный (LTP) (рис. 26).
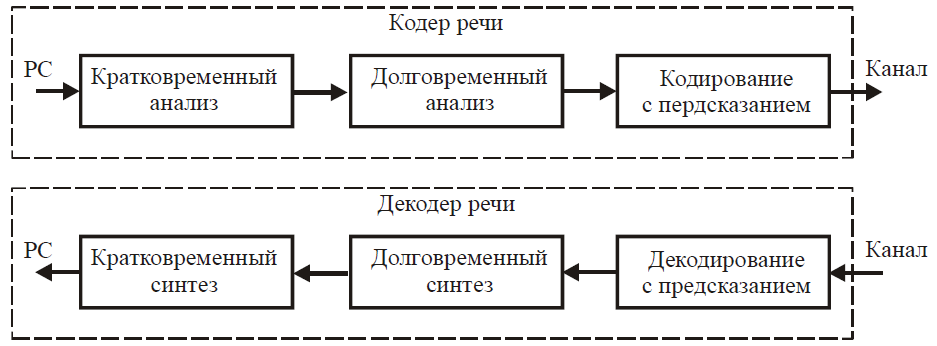
Рисунок 26 – Предсказатели речевых кодеков
Первый предсказатель (STP), учитывающий кратковременную избыточность речевого сигнала, связан с корреляциями между близко расположенными отсчетами сигнала. Осуществляя кратковременный анализ, он определяет огибающую спектра и имеет передаточную функцию 1/A(z), где выражение A(z) определяется соотношением (26). Краткосрочный предсказатель STP является основным фильтром анализа линейного предсказания. Адаптивное изменение параметров этого фильтра необходимо для отражения изменений спектра речевого сигнала. Период адаптации при этом обычно составляет 20...30 мс, а порядок предсказания p обычно выбирается равным 8-12.
Второй, долговременный, предсказатель (LTP) моделирует долгосрочную корреляцию речевого сигнала. Осуществляя долговременный анализ, он определяет точную структуру речевого сигнала и связан с корреляцией двух отрезков сигнала между собой, реально — двух соседних периодов основного тона.
Этот фильтр, который ещё называют тоновым, также является адаптивным и обычно имеет малый (по сравнению с STP) период адаптации — каждые 5...10мс. Период основного тона речи изменяется в широких пределах. На практике обеспечивается формирование частоты основного тона в пределах от приблизительно 55 до 500 Гц. Сочетание двух предсказателей с разными характеристиками позволяет в значительной мере устранить остаточную избыточность и приблизить остаток предсказания по своим статистическим характеристикам к дискретному белому шуму. При этом на приемную сторону передаются параметры сигнала возбуждения (остаток предсказания) и параметры обоих (STP и LTP) предсказателей.
Во-вторых, использование остатка предсказания в качестве сигнала возбуждения оказывается недостаточно эффективным, так как требует для кодирования слишком большого числа битов. Поэтому практическое применение находят более экономичные (по загрузке канала связи, но отнюдь не по вычислительным затратам) методы формирования сигнала возбуждения.
Таким образом, предсказатель распадается на кратковременный и долговременный предсказатели. Они размещаются один за другим, причем лучшие результаты получаются при размещении долговременного предсказателя после кратковременного. Делается это для устранения периодичности, которая еще сохраняется в сигнале остатка кратковременного предсказания. Таким путем происходит сглаживание динамических изменений в сигнале остатка.
Рассмотрим структурную схему вокодера с линейным предсказанием (липредера) более подробно (рис. 27):

Рисунок 27 – Структурная схема липредера
На подготовительном этапе выполняют аналого-цифровое преобразование речевого сигнала и сегментацию цифрового потока: для последующей обработки выбирают отсчеты сигнала на интервале длительностью 20 мс, что при частоте дискретизации 8 кГц обеспечивает в каждом сегменте 160 обрабатываемых отсчетов. После сегментации отсчетов речевого сигнала в кодере последовательно выполняются следующие три процедуры:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
