
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
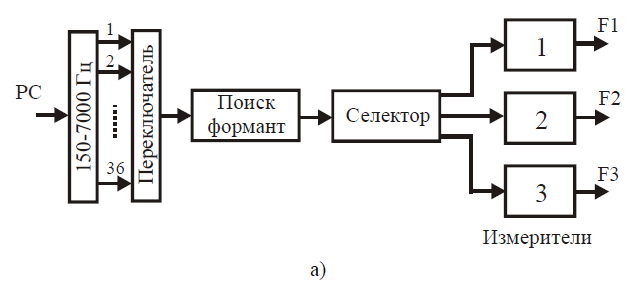
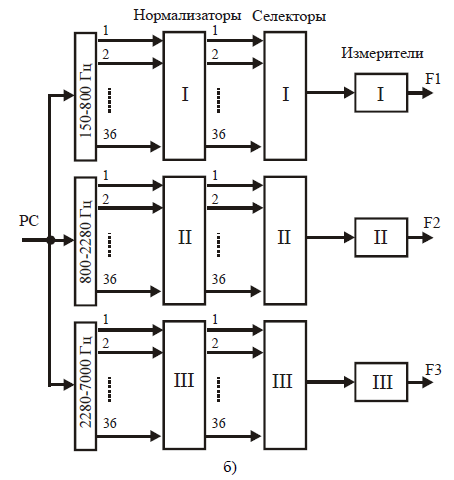
Рисунок 28 – Способы измерения формантных частот
Второй способ (рис. 28б) заключается в группировании узкополосных фильтров по трём формантным областям I, II, III (150— 800, 800—2280 и 2280—7000 Гц). В каждой области путем переключения фильтров находят максимум спектра. При этом для звонких звуков третья форманта отыскивалась в диапазоне 2280— 3100 Гц, а для глухих — в диапазоне 3000—7000 Гц. Этот способ оказался более точным по сравнению с первым, хотя и несколько более сложным. Для увеличения точности измерения при переключении фильтров применяется электронная схема искателя максимального напряжения, получающегося на выходах полосных фильтров. Для устойчивости работы селекторов перед каждым из них включается нормализующее устройство, в задачу которого входит усреднение напряжений всех фильтров данной группы и выдача в селектор только разности между напряжением в каждом канале и средним. На один выход селектора поступает импульс напряжения в начале каждого интервала опроса, а на другой — в момент появления максимального напряжения на его входе за данный интервал времени опроса. В измерителе создается импульс напряжения с длительностью, пропорциональной времени между этими двумя импульсами. После некоторого сглаживания в фильтре НЧ с частотой среза 10 Гц напряжение на выходе анализатора будет пропорционально текущей частоте форманты.
Для дальнейшего повышения точности выделения формант границы диапазона формант были сделаны переменными в пределах ширины полосы смежных фильтров. В этом случае определение формантных частот происходит последовательно: сначала определяется местоположение самого низкочастотного максимума, после чего определяется вторая формантная частота, а затем уже третья.
Сравним методы параллельного и последовательного анализа. Первые не дают высокой точности определения частоты формант, но зато их ошибка почти не зависит от разницы в голосах и частоты основного тона. Таким образом, их показания имеют меньший разброс. Вторая группа методов для голосов с хорошей дикцией и низким основным тоном даёт высокую точность, однако у них большой разброс в показаниях для разных голосов.
Одним из точных методов измерения формант в реальном времени является кепстральный, аналогичный методу выделения частоты основного тона, но без второго преобразования Фурье. Для получения частот формант сегменты речевого сигнала последовательно подаются на анализатор спектра со сканированием по частоте. Поэтому выходной сигнал анализатора для каждого сегмента разворачивается во времени. Этот сигнал пропускают через логарифматор.
Для звонкого звука зависимость имеет вид всплесков, имеющих максимумы на частотах каждой из гармоник основного тона, а для глухого звука эта зависимость будет иметь максимумы и минимумы на частотах формант и антиформант соответственно (конечно, в этом случае могут быть и ложные максимумы и минимумы, не соответствующие им). Если соединить между собой вершины всплесков, соответствующих частотам гармоник спектра, то максимумы этой огибающей будут соответствовать формантным частотам с вышесказанной оговоркой. Соединяя между собой максимумы огибающей спектра следующих друг за другом сегментов речевого сигнала, получают траекторию для каждой формантной частоты. При этом легко исключить ложные форманты и учесть близко расположенные формантные частоты.
Если анализируется аналоговый сигнал, то пороговое устройство, включенное после логарифматора, отмечает каждый всплеск, и компаратор сравнивает амплитуду всплеска с амплитудой предыдущего всплеска в этом сегменте.
Если амплитуда всплеска начинает уменьшаться, то запоминается время, прошедшее с момента начала анализа данного сегмента. Оно должно быть пропорционально формантной частоте. Так получают отсчеты возможных формантных частот. Сравнивая их с соответствующими данными для предыдущих сегментов, уточняют значения формантных частот и исключают из них ложные, получая в результате их траекторию. Конечно, в случае близости формант разных порядков по частоте возможны ошибки, но всё же эта траектория, как правило, даёт возможность исключения ложных формант с точностью 3-5%. При цифровом методе сигнал с анализатора спектра подвергается дискретизации во времени и квантуется по уровню, и затем подвергается обработке по той же программе, что и для аналогового сигнала.
Анализ речи на основе линейного предсказания при использовании его доли оценивания формантных частот вокализованного сигнала имеет как преимущества, так и недостатки. Форманты можно оценить по коэффициентам предсказания двумя способами. Первый состоит в факторизации полинома предсказания на основе полученных корней и вынесении решения о том, какие из корней описывают форманты, а какие — форму спектра. Другой способ заключается в оценивании спектра и использовании метода выделения максимумов.
Особое преимущество, присущее методу линейного предсказания в формантном анализе, состоит в том, что как центральные частоты формант, так и их полосы можно оценивать достаточно точно с помощью факторизации полинома предсказателя. Поскольку порядок полинома р выбирается заранее, количество комплексно-сопряженных полюсов составляет р/2. Таким образом, упомянутая выше проблема классификации корней полинома с целью определения того, какие из корней описывают форманты, в данном случае оказывается значительно менее сложной, чем при использовании сходных методов, например кепстрального сглаживания. Кроме того, побочные полюсы легко устраняются вследствие того, что полоса соответствующих им формант оказывается во много раз больше, чем можно ожидать для обычного речевого сигнала.
Недостатком метода линейного предсказания является использование для описания спектра сигнала полюсной модели. Так, хотя для носовых звуков и получается неплохое описание спектра полюсной моделью, совпадение корней полинома и действительных формантных частот неочевидно. Совершенно неясно, чему соответствуют получающиеся корни; нулям и полюсам носовой полости или искомым резонансным частотам. Другая трудность заключается в том, что хотя оценки ширины формант можно определить с использованием полученных корней, однако непонятно, как они соотносятся с истинными формантами. Это объясняется тем, что полученная оценка зависит от расположения и длительности интервала анализа и метода анализа.
С учетом этих достоинств и недостатков предложен ряд методов оценивания формантных частот с использованием линейного предсказания как на основе метода выделения максимумов в спектре, так и на основе факторизации полинома предсказателя. После выбора совокупности формантных параметров устанавливается соответствие между формантными параметрами и номерами формант, как и во всех других методах анализа. Сюда входят и требования непрерывности формант, необходимости предыскажений для исключения взаимного поглощения одной форманты другой и использования методов обострения пиков в спектре с помощью перемещения старшего параметра линейного предсказания к границе единичной окружности.
Более удачным оказался метод анализ через синтез, предложенный в нача-
ле 1960-х годов. Этот метод весьма широко применяется в современных системах низкоскоростного кодирования речи. Его суть заключается в сравнении кратковременного спектра речевого сигнала с генерируемым спектром, последовательно изменяющимся по заложенной в алгоритм стратегии, приводящей к наилучшему согласованию со спектром исходного сигнала. Успешность во многом зависит от выбранной стратегии приближения.
Как ранее упоминалось, в существующих формантных вокодерах из речи выделяются не более трех-четырех формант; в некоторых вокодерах определяется наличие спектра в области частот выше 4000 Гц, что необходимо для анализа щелевых и фрикативных звуков, определяющих разборчивость фонем в, ф, з, е, ж, ш, х, щ. При небольшом ущербе для индивидуальности звучания ограничиваются передачей параметров только трех формант, а также интонационных параметров «тон-шум» и основной тон. В этом случае число сигналов-параметров будет равно 8.
Структурная схема формантного вокодера показана на рис. 29:
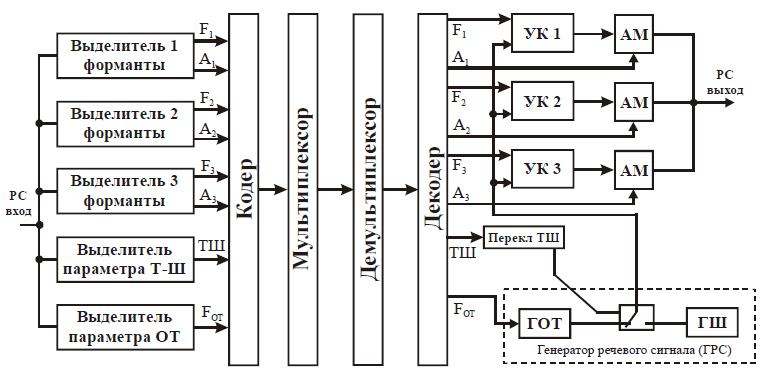
Рисунок 29 – Структурная схема формантного вокодера
На передающей стороне в анализаторе вокодера выделяются структурные сигналы-параметры первых трех формант ( A1, F1, A2 ,F2 , A3, F3 ), а также интонационные параметры (Т-Ш и FOT). В качестве оценки амплитуды форманты используется её усредненный уровень, выделяемый с помощью полосовых фильтров, выпрямителей и ФНЧ (рис. 30).

Для выделения формантных частот применяются метод ро-метра, а также методы дискриминаторный и фильтрационный. Синтезатор формантного вокодера (рис. 29) состоит из трех управляемых резонансных контуров (УК) с плавной перестройкой их частоты под приходящий параметр. На модуляторах происходит взаимодействие резонансного и колебательного процессов в зависимости от уровня соответствующего сигналапараметра A1, A2 или A3 . Считается, что с помощью формантного вокодера можно получать достаточно высококачественный синтез речи, как по разборчивости, так и по натуральности — даже при скорости цифрового потока порядка 1200 бит/с. При этом коэффициент компрессии формантного вокодера не менее чем вдвое выше, чем полосного.
Современные вокодеры обеспечивают достаточно хорошее качество речи при скорости передачи 4800...2400 бит/с и качество речи, пригодное для ведения служебных переговоров, при скорости передачи 1200...2400 бит/с. Формантные и полосные вокодеры находят применение также при цифровой передаче телефонных сигналов по КВ-каналам радиосвязи.
Оценка качества воспроизведения речи, алгоритмы кодирования и декодирования
Вначале кратко рассмотрим основные методы оценки качества воспроизведения речи при цифровой передаче. Критерии и методы оценки качества воспроизведения речи подразделяются на объективные и субъективные. Объективные используют некоторые формализованные параметры, которые позволяют судить о степени близости или различия переданного и восстановленного на приёмной стороне речевого сигнала. Однако, поскольку человек, как получатель информации, является ключевым элементом любой системы передачи речевого сигнала, качество сигнала может оцениваться по его субъективному восприятию речи. Измеряемое качество должно удовлетворять пользователя, поэтому очень важно должным образом управляемое субъективное тестирование. Так как число тестов должно быть велико, чтобы результаты были статистически обоснованы, субъективные тесты очень дороги и используются ограниченно. Одним из используемых субъективных измерений является MOS (Mean Opinion Scores) — средняя экспертная оценка. Это субъективное измерение для оценки качества передачи речи. Шкала средней экспертной оценки содержит 5 баллов. От 1 балла – неудовлетворительно, до 5 баллов – превосходно. Так при скорости передачи 1200 бит/сек с помощью липредера с многополосным возбуждением MOS колеблется от 2.6 до 2.8, а при скорости передачи 2400 бит/сек – от 2.9 до 3.1. Хотя качество речевого сигнала по большей части связано со скоростью передачи, более сложные алгоритмы кодирования-декодирования способны достичь более высоких отношений качества к скорости передачи.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
