
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Дискретизация (рис. 5) — это получение мгновенных значений сигнала (отсчетов) через определенные промежутки времени (т. е. с определенной частотой — частотой дискретизации):
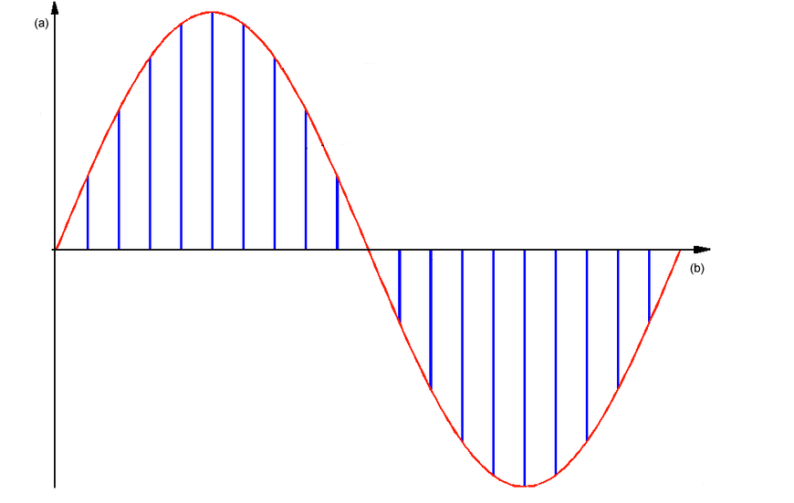
Рисунок 5 – Пример дискретизации по времени
Квантование (рис. 6) — это «округление» полученных мгновенных значений до ближайших заранее заданных уровней. Число уровней квантования, обычно, равно или кратно целой степени числа 2. Номер уровня кодируется двоичными словами длиной 3, 4, 5 и т. д. бит.
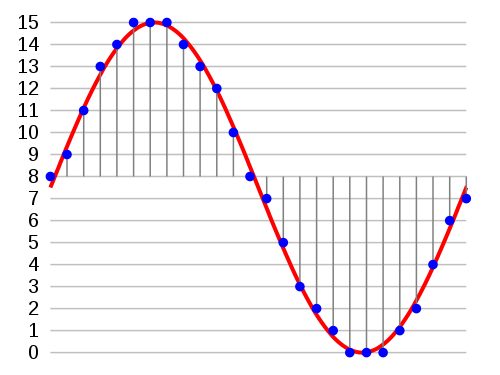
Рисунок 6 – Пример квантования
Кодирование — это представление значений полученных уровней в виде какого-либо кода (например, двоичного).
У ИКМ существуют две разновидности:
Дифференциальная импульсно-кодовая модуляция (ДИКМ), при которой сигнал кодируется в виде разности между текущим и предыдущим измеренными значениями. Для звуковых данных такой тип модуляции уменьшает требуемое количество бит на отсчёт примерно на 25 %. Адаптивная ДИКМ (АДИКМ) — разновидность ДИКМ с переменным шагом квантования. Изменение шага позволяет уменьшить требования к полосе пропускания при заданном соотношении сигнала и шума.Вокодеры. Назначение и виды
Вокодером называют устройство кодирования-декодирования речевого (голосового) сигнала. Вокодеры делят по принципу действия на два больших
класса: речеэлементные и параметрические.
Речеэлементные вокодеры на передающем конце распознают, какие элементы речи произнесены (например, фонемы), а на приёмном конце эти элементы воссоздаются по правилам речеобразования или извлекаются из памяти устройства. В таких вокодерах приходится решать задачу распознавания элементов речи.
Параметрические вокодеры выделяют из речевого сигнала два комплекса параметров: параметры, характеризующие спектральную огибающую сигнала (фильтровую функцию), и параметры, характеризующие сам источник звуковых колебаний (генераторную функцию). Параметрические вокодеры можно подразделить в зависимости от выделяемых параметров, которые в свою очередь зависят от выбранной модели представления речевого сигнала. Основными видами параметрических вокодеров являются:
? полосовые (канальные);
? формантные;
? ортогональные;
? корреляционные;
? гомоморфные;
? линейного предсказания (липредеры).
Рассмотрим обобщённую блок-схему параметрического вокодера, изображённую на рисунке 7:
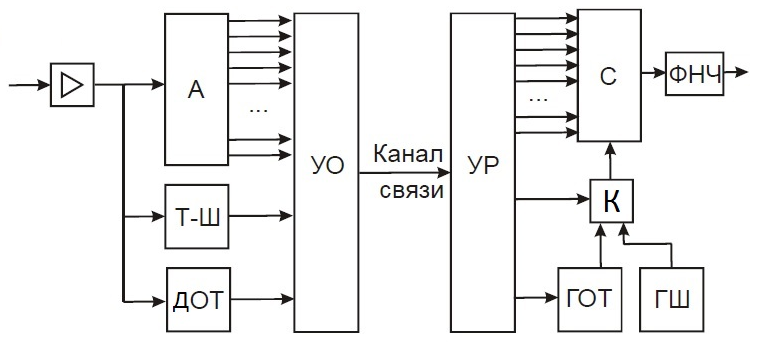
Рисунок 7 – Блок-схема параметрического вокодера
На схеме: А – анализатор входного сигнала, который на основе сегмента входной реализации речевого сигнала находит параметры, подлежащие передаче. Устройство Т-Ш (обнаружитель «Тон-шум») осуществляет различение типа сегмента сигнала – вокализованный он, или фрикативный, а ДОТ – детектор основного тона (блок оценки параметров основного тона) в случае, если сегмент относится к вокализованному типу. УО – устройство объединения сигналов для передачи через канал связи, УР – устройство разделения сигналов, переданных через канал. На приёмной стороне на основе принятых параметров происходит синтез речевого сигнала. Для этого используются ГОТ – генератор основного тона, ГШ – генератор шума, К – ключ. С – синтезатор, в котором воссоздаётся речевой сигнал.
1. Полосовые (канальные) вокодеры.
В полосовых вокодерах спектр речи делится на 7-20 полос (каналов) с помощью полосовых фильтров. Анализатор определяет величину средней интенсивности речевого сигнала в каждой полосе. Эти величины передаются через канал связи. Чем большее число каналов используется в вокодере, тем больше натуральность и разборчивость речи. Блок-схема полосного вокодера изображена на рисунке 8:
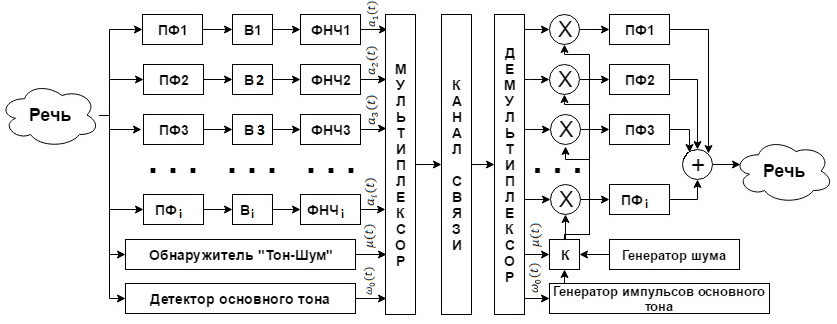
Рисунок 8 – Блок-схема полосового вокодера
Речевой сигнал поступает на гребёнку i полосовых фильтров (ПФ1 – ПФi). К выходам полосовых фильтров подключены выпрямители (детекторы) и сглаживающие фильтры НЧ. Тем самым получаем сигналы ![]()
![]() , характеризующие амплитуду речевого сигнала в заданной полосе частот и являющиеся медленно меняющимися по сравнению с исходным речевым сигналом. Кроме того, на передающем конце речевой сигнал поступает на детектор основного тона. На его выходе формируется сигнал, характеризующий частоту основного тона
, характеризующие амплитуду речевого сигнала в заданной полосе частот и являющиеся медленно меняющимися по сравнению с исходным речевым сигналом. Кроме того, на передающем конце речевой сигнал поступает на детектор основного тона. На его выходе формируется сигнал, характеризующий частоту основного тона ![]()
![]() . Обнаружитель «Тон-шум» определяет характер речевого сигнала: вокализованный или фрикативный. Для вокализованных звуков состав спектра звуков речи дискретный, и характер сигнала определяется как «тон». Для невокализованных звуков (например, шипящие) состав спектра звуков речи
. Обнаружитель «Тон-шум» определяет характер речевого сигнала: вокализованный или фрикативный. Для вокализованных звуков состав спектра звуков речи дискретный, и характер сигнала определяется как «тон». Для невокализованных звуков (например, шипящие) состав спектра звуков речи
непрерывный: характер сигнала «шумовой». Формируемый на выходе обнаружителя сигнал обозначим:
![]()
![]()
Следует заметить, что обнаружитель «Тон-шум» и детектор основного тона должны взаимодействовать друг с другом. Если сегмент речевого сигнала идентифицирован как шумовой, то нет смысла осуществлять оценку частоты основного тона, и ![]()
![]() .
.
В результате через канал связи передаются: частота основного тона ![]()
![]() , тип сигнала
, тип сигнала ![]()
![]() , средние интенсивности сигнала в выбранных полосах частот
, средние интенсивности сигнала в выбранных полосах частот ![]()
![]() . В мультиплексоре перечисленные сигналы объединяются и преобразуются в форму, приемлемую для передачи по каналу связи. На приёмной стороне выполняется разделение сигналов посредством демультиплексора и преобразование их в форму, необходимую для работы синтезатора речевого сигнала.
. В мультиплексоре перечисленные сигналы объединяются и преобразуются в форму, приемлемую для передачи по каналу связи. На приёмной стороне выполняется разделение сигналов посредством демультиплексора и преобразование их в форму, необходимую для работы синтезатора речевого сигнала.
Синтезатор речевого сигнала на приёмной стороне имеет в своём составе
генератор речевого сигнала, состоящий из генератора импульсов основного тона и генератора шума. Генератор импульсов используется как источник тональных сигналов для вокализованных звуков и управляется сигналом ![]()
![]() таким образом, что частота следования импульсов равна частоте основного тона речевого сигнала на передающем конце. Генератор шума используется как источник шумовых сигналов для невокализованных участков речи. Переключатель тон/шум управляется сигналом
таким образом, что частота следования импульсов равна частоте основного тона речевого сигнала на передающем конце. Генератор шума используется как источник шумовых сигналов для невокализованных участков речи. Переключатель тон/шум управляется сигналом ![]()
![]() .
.
Сигнал с ключа поступает на гребёнку полосовых фильтров, таких же, какие использовались на передающем конце, а с их выходов – на умножители. Модулируемыми колебаниями здесь являются выходы полосовых фильтров, а модулирующими – сигналы![]()
![]() . С выходов умножителей сигналы поступают на ещё одну гребёнку полосовых фильтров, служащих для уменьшения влияний побочных продуктов модуляции, возникающих умножителях. Совокупность схем и узлов преобразования сигнала в пределах каждой из частотных полос называется спектральным каналом полосного вокодера. Выходные сигналы спектральных каналов суммируются в выходном усилителе и формируют выходной речевой сигнал.
. С выходов умножителей сигналы поступают на ещё одну гребёнку полосовых фильтров, служащих для уменьшения влияний побочных продуктов модуляции, возникающих умножителях. Совокупность схем и узлов преобразования сигнала в пределах каждой из частотных полос называется спектральным каналом полосного вокодера. Выходные сигналы спектральных каналов суммируются в выходном усилителе и формируют выходной речевой сигнал.
При выборе характеристик полосовых фильтров исходят из того, что с увеличением крутизны затухания вне полосы пропускания повышается точность измерения спектров. Однако при этом повышается время переходных процессов в полосовом фильтре, что искажает быстрые спектральные изменения и приводит к реверберации синтезированной речи. Поэтому имеет смысл применение полосовых фильтров, имеющих с одной стороны хорошую разрешающую способность, а с другой – монотонную импульсную характеристику без всплесков.
Полоса пропускания ФНЧ должна обеспечить передачу временных изменений сигналов в спектральных каналах и при этом достаточно сильно подавить колебания гармоник основного тона.
Количество каналов полосного вокодера можно выбирать из соотношения
разборчивости и скорости передачи речи. Так, если использовать от 16 до 20 спектральных каналов, то их ширина сравнима с шириной частотных групп слуха, следовательно вокодер будет обладать достаточной разборчивостью.
Обычно схемы полосных вокодеров дополняют устройствами линейного
предсказания. Тем самым получают полосные вокодеры с линейным предсказанием или ЛПК-вокодеры. С помощью алгоритмов линейного предсказания при анализе в передающем устройстве определяются коэффициенты предсказания, а в приёмном устройстве на основе этих коэффициентов с помощью рекурсивного цифрового фильтра синтезируется эквивалент голосового тракта.
Суть метода линейного предсказания заключается в том, что прогнозируемая величина речевого сигнала ![]()
![]() в момент опробывания
в момент опробывания ![]()
![]() определяется как линейно взвешенная сумма предшествующих отсчётов:
определяется как линейно взвешенная сумма предшествующих отсчётов:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
