
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Другие субъективные измерения включают искажение качества (QDU —
Quantization Distortion Units), которое определяется как искажения, вносимые
одной парой кодеров. Для количественной характеристики ухудшения качества речи применяют единицы QDU. Величина 1QDU соответствует ухудшению качества при цифровом преобразовании речи с использованием стандартной процедуры ИКМ. Дополнительная обработка речи ведёт к дальнейшей потере её качества. Так, алгоритмы, обеспечивающий скорость 32Кбит/сек, могут «испортить» качество речи на 3.5 QDU, а алгоритмы, работающий со скоростью 24Кбит/сек – на 7 QDU.
Довольно большое распространение получил артикуляционный метод —
критерий разборчивости речи. В его основе лежит измерений разборчивости
S%, которая определяется процентом правильно принятых элементов речи —
звуков, слогов, слов или целых фраз. При некоторых типах искажений разборчивость функционально связана с другими показателями качества речи, например, отношением сигнал/шум, и достаточно хорошо характеризует качество речи в целом.
Самым популярным и широко используемым тестом на разборчивость является диагностический тест на рифмы (Diagnostic Rhyme Test — DRT). В этом тесте представлено одно слово из каждой группы рифмованных слов, и слушателя просят определить, какое слово было произнесено. Затем представляется оценка этого теста в процентном отношении правильно произнесённых слов S%. Обычно оценка этого теста колеблется от 75% до 95%. Для определения смысла полученных результатов с оценками разборчивости обычно связывают категории характеристик.
Для большинства стандартных кодеров речи, работающих на скоростях выше 4Кбит/сек оценка DRT выше 90%. Это в частности не позволяет выделить различия одного кодера от другого по их характеристикам.
К недостаткам субъективных методов оценки качества воспроизведения речи следует отнести низкую оперативность и сложность получения результатов. Поэтому чаще всего предпочитают использовать объективные (формализованные) показатели качества.
Объективные измерения эффективны с точки зрения цены и повторяемости результатов, однако большое внимание должно быть уделено выбору правильного метода измерения для данных типов кодеров. Наиболее широко используемым примером объективных измерений речи является отношение сигнал/шум (ОСШ). Величина ОСШ определяется как отношение дисперсии сообщения (мощность сигнала) к мощности шумов на выходе декодера. При объективных методах оценки для анализа качества систем передачи речи необходимо оценивать отношение мощности сигнала к суммарной мощности шумов ![]()
![]() , которое называют суммарным. Известно, что значения ОСШ имеют устойчивую связь с субъективными оценками качества восприятия речи. Однако, исследования цифровых методов передачи с помощью адаптивных методов кодирования выявили серьёзные расхождения субъективных оценок при одинаковых значениях
, которое называют суммарным. Известно, что значения ОСШ имеют устойчивую связь с субъективными оценками качества восприятия речи. Однако, исследования цифровых методов передачи с помощью адаптивных методов кодирования выявили серьёзные расхождения субъективных оценок при одинаковых значениях ![]()
![]() . В результате предложена более корректная оценка, получившая название сегментного ОСШсег. Это ОСШсег определяется как среднее значение логарифмов отношения суммарной мощности сигнала и шума к мощности шума в отдельных сегментах заданной длительности Т. Известны аналитические выражения, позволяющие вычислить среднюю экспертную оценку MOS и разборчивость S% по значениям
. В результате предложена более корректная оценка, получившая название сегментного ОСШсег. Это ОСШсег определяется как среднее значение логарифмов отношения суммарной мощности сигнала и шума к мощности шума в отдельных сегментах заданной длительности Т. Известны аналитические выражения, позволяющие вычислить среднюю экспертную оценку MOS и разборчивость S% по значениям ![]()
![]() и ОСШсег. Таким образом, можно приближённо оценивать субъективное качество по известным значениям ОСШ — суммарному ОСШ? и сегментному ОСШсег.
и ОСШсег. Таким образом, можно приближённо оценивать субъективное качество по известным значениям ОСШ — суммарному ОСШ? и сегментному ОСШсег.
Кроме субъективных и объективных критериев качества воспроизводимой речи, алгоритмы кодирования-декодирования речи характеризуются степенью сложности их реализации. Для измерения уровня алгоритмической
сложности предлагается параметр MIPS, который определяет требуемую производительность сигнального процессора в миллионах операций в секунду.
Если существенным требованием к кодеру является низкая скорость передачи речевого сигнала и нет существенных ограничений на сложность реализации алгоритмов кодирования и декодирования, то на основе изложенных показателей качества речи, перспективным представляется формантный вокодер. Формантный вокодер обеспечивает низкую скорость передачи за счёт кодирования только наиболее важных мгновенных компонент спектра речи. Основное требование к формантному вокодеру состоит в точном отслеживании изменений в формантах. Если оно выполнено, то формантные вокодеры могут обеспечить разборчивую речь на скоростях менее 1000бит/сек.
Необходимая пропускная способность для формантного вокодера определяется исходя из ширины полосы формантных огибающих и их динамического диапазона. По теории восприятия, допустимое отклонение формантной частоты составляет около 3%, из которых 2% должно выделяться на ограничение полосы частот временной огибающей формантной частоты. Этот предел определяет допустимую флуктуацию частоты форманты в канале связи. Она не должна быть более 1%, что соответствует требуемому динамическому диапазону 40дБ.
Для формант требуются разные значения динамического диапазона и, соответственно, разные пропускные способности канала связи. В таблице приведены эти величины для трёх формант:
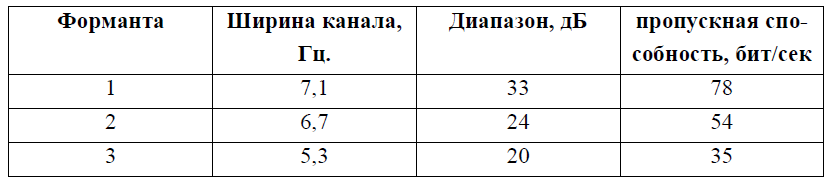
Суммируя пропускные способности, получаем общую пропускную способность для всех формантных частот, равную 170 бит/сек. При полосе частот 20Гц требуемый динамический диапазон составит 25,5 дБ. если же вести передачу в предельно сжатом диапазоне, для этого потребуется 85 Гц, к которой следует добавить около 15 Гц на расфильтровку каналов и 150 Гц на передачу других параметров или 500 бит/сек. Следовательно, предельное значение коэффициента компрессии сигнала в формантном вокодере достигает 60. В зависимости от метода, применяемого в вокодере, этот коэффициент может несколько измениться, но и в самом худшем варианте вокодера не снижается ниже 20. Таким образом, коэффициент компрессии формантного вокодера не менее чем вдвое выше, чем полосного.
По известным данным каждый из параметров формантного вокодера следует передавать тремя-четырьмя битами, что соответствует 8-16 уровням с частотой отсчётов 40-50 раз в секунду. Следовательно, с учётом основного тона потребуется не менее 1200 бит/сек для передачи верхних пределов и 640
бит/сек — для нижних. В последнем случае вводится дополнительное условие, что основной тон передаётся только одним битом и 40 отсчётов в секунду, т. е. 40 бит/сек, но в этом случае передача звучит монотонно. Артикуляционные испытания показали, что в лучшем случае словесная разборчивость получается равной 67% на сбалансированных односложных словах. Эти данные уступают данным, достигнутым для полосных вокодеров при скорости передачи 1500 бит/сек. Вокодер нуждается в дальнейшем усовершенствовании и нет сомнений в том, что его разборчивость будет не ниже, чем для полосных вокодеров и липредеров при вдвое меньшей скорости передачи. При оценке точности выделения формантных параметров и синтезе речи по ним следует иметь в виду, что для вокодеров не всегда необходимо точное выделение этих параметров. В первую очередь необходимо обеспечить точную передачу максимумов спектра, даже если они не относятся к формантам. Например, если в спектре речи конкретного человека есть ложные форманты, их тоже целесообразно передавать, иначе будут потери в узнаваемости голоса.
Проведённые исследования возможностей формантного вокодера показали, что в синтезаторе можно получить достаточно высококачественный синтез речи как по разборчивости, так и по натуральности звучания даже для скорости 1200 бит/сек. и несколько менее. Как уже упоминалось, это не всегда определяется точностью анализа параметров речи и в частности точность изменения формантных частот, а преимущественно скоростью передачи. Например, один из формантных вокодеров при скорости 1000 бит/сек давал разборчивость односложных слов до 72%, а при скорости 1200 бит/сек получили слоговую разборчивость 80-82% и это ещё не предел. Исследования показывают, что у формантных вокодеров есть ещё резервы для повышения натуральности звучания речи. При этом, конечно на качестве речи сказывается и то, что в действительности речеобразующий тракт не является системой из трёх-четырёх резонаторов, а представляет собой более сложную систему. Вследствие этого ряд характеристик тракта не учитывается при анализе и не восстанавливается при синтезе.
Для приблизительно одного и того же качества передачи речевого сигнала
требуемая пропускная способность канала связи для полосового вокодера, ортогонального вокодера, липредера составляет 2400 бит/сек, а для формантного вокодера — всего лишь 1200 бит/сек. Причём при скорости передачи 1200 бит/сек наилучшим по разборчивости и качеству звучания является формантный вокодер. Существует возможность перевести формантный вокодер на скорость 600 бит/сек с использованием корреляционных связей между формантами (например, передаётся, как правило, главная форманта, определяющая звук речи и лишь для некоторых звуков передаются две форманты). Таким образом в качестве перспективных могут разрабатываться формантные вокодеры, так как они моделируют речевой аппарат человека и могут создавать естественное звучание.
Перспективность формантных вокодеров обосновывается вышеизложенным и подтверждается следующим:
Формантный вокодер в наибольшей степени по сравнению с другими вокодерами учитывает специфику и свойства речевого сигнала. Это позволяет минимизировать количество параметров, описывающих речевой сигнал, что приводит в принципе к снижению скорости передачи речевого сигнала. В научной литературе описан ряд методов измерения параметров формант, включая кепстральный анализ. С целью повышения помехоустойчивости и эффективности формантного вокодера целесообразно для измерения параметров формант использовать методы теории статистических решений, в частности оптимальные алгоритмы оценки параметров. Повышение качества передачи речевого сигнала с помощью формантного вокодера возможно в результате уточнения формы спектров формант и учёта неинформативных (непередаваемых) параметров, описывающих форму спектра форманты. Для возможного уменьшения скорости передачи речевого сигнала с помощью формантного вокодера целесообразно, как это делается в некоторых липредерах, использовать векторное квантование. Для этого необходимо создать кодовые книги возможного набора значений параметров формант и передавать лишь идентификатор вектора значений параметров формант, восстанавливая его на приёмном конце как вектор из соответствующей кодовой книги. Снижение скорости передачи речевого сигнала с помощью формантного вокодера возможно также за счёт использования корреляционных связей между формантами — передавать лишь параметры главной форманты, определяющей данный звук речи и только для некоторых звуков — две форманты. Если допустима задержка передаваемого речевого сигнала, то для снижения скорости можно использовать повторную (двойную) параметризацию. Предлагается, рассматривая измеренные формантные параметры как дискретную функцию времени, аппроксимировать эту функцию отрезком ряда по ортогональным функциям и передавать в декодер только коэффициенты этого разложения. При правильном выборе можно число передаваемых значений уменьшить в 2-4 раза.Среди разработанных к настоящему времени алгоритмов кодирования и декодирования заметно выделяются липредеры — вокодеры, основанные на
методах адаптивного кодирования с линейным предсказанием. В отличие от
формантных вокодеров зависимость этих методов от данных о механизмах речеобразования отступает на второй план. Липредеры находят широкое применение и уже разработано большое количество их вариантов. Некоторые липредеры, например, с многополосным возбуждением, позволяют снизить скорость передачи речи до 1200 бит/сек при хороших (с субъективной точки зрения) характеристиках переданного речевого сигнала.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
