


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Можно ли отсутствие связей рассматривать как значимый результат? Чем слабее зависимость между переменными, тем большего объема требуется выборка, чтобы значимо ее обнаружить. Представьте, как много бросков монеты необходимо сделать, чтобы доказать, что отклонение от равной вероятности выпадения орла и решки составляет только.000001%! Необходимый минимальный размер выборки возрастает, когда степень эффекта, который нужно доказать, убывает. Когда эффект близок к 0, необходимый объем выборки для его отчетливого доказательства приближается к бесконечности. Другими словами, если зависимость между переменными почти отсутствует, объем выборки, необходимый для значимого обнаружения зависимости, почти равен объему всей популяции, который предполагается бесконечным. Статистическая значимость представляет вероятность того, что подобный результат был бы получен при проверке всей популяции в целом. Таким образом, все, что получено после тестирования всей популяции было бы, по определению, значимым на наивысшем, возможном уровне и это относится ко всем результатам типа "нет зависимости".
Как измерить величину зависимости между переменными? Статистиками разработано много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от числа переменных, используемых шкал измерения, природы зависимостей и т. д. Большинство этих мер, тем не менее, подчиняются общему принципу: они пытаются оценить наблюдаемую зависимость, сравнивая ее с "максимальной мыслимой зависимостью" между рассматриваемыми переменными. Говоря технически, обычный способ выполнить такие оценки заключается в том, чтобы посмотреть как варьируются значения переменных и затем подсчитать, какую часть всей имеющейся вариации можно объяснить наличием "общей" ("совместной") вариации двух (или более) переменных. Говоря менее техническим языком, вы сравниваете то "что есть общего в этих переменных", с тем "что потенциально было бы у них общего, если бы переменные были абсолютно зависимы". Рассмотрим простой пример. Пусть в вашей выборке, средний показатель (число лейкоцитов) WCC равен 100 для мужчин и 102 для женщин. Следовательно, вы могли бы сказать, что отклонение каждого индивидуального значения от общего среднего (101) содержит компоненту связанную с полом субъекта и средняя величина ее равна 1. Это значение, таким образом, представляет некоторую меру связи между переменными Пол и WCC. Конечно, это очень бедная мера зависимости, так как она не дает никакой информации о том, насколько велика эта связь, скажем относительно общего изменения значений WCC. Рассмотрим крайние возможности:
a. Если все значения WCC у мужчин были бы точно равны 100, а у женщин 102, то все отклонения значений от общего среднего в выборке всецело объяснялись бы полом индивидуума. Поэтому вы могли бы сказать, что пол абсолютно коррелирован (связан) с WCC, иными словами, 100% наблюдаемых различий между субъектами в значениях WCC объясняются полом субъектов.
b. Если же значения WCC лежат в пределах 0-1000, то та же разность (2) между средними значениями WCC мужчин и женщин, обнаруженная в эксперименте, составляла бы столь малую долю общей вариации, что полученное различие (2) считалось бы пренебрежимо малым. Рассмотрение еще одного субъекта могло бы изменить разность или даже изменить ее знак. Поэтому всякая хорошая мера зависимости должна принимать во внимание полную изменчивость индивидуальных значений в выборке и оценивать зависимость по тому, насколько эта изменчивость объясняется изучаемой зависимостью.
Общая конструкция большинства статистических критериев. Так как конечная цель большинства статистических критериев (тестов) состоит в оценивании зависимости между переменными, большинство статистических тестов следуют общему принципу, объясненному в предыдущем разделе. Говоря техническим языком, эти тесты представляют собой отношение изменчивости, общей для рассматриваемых переменных, к полной изменчивости. Например, такой тест может представлять собой отношение той части изменчивости WCC, которая определяется полом, к полной изменчивости WCC (вычисленной для объединенной выборки мужчин и женщин). Это отношение обычно называется отношением объясненной вариации к полной вариации. В статистике термин объясненная вариация не обязательно означает, что вы даете ей "теоретическое объяснение". Он используется только для обозначения общей вариации рассматриваемых переменных, иными словами, для указания на то, что часть вариации одной переменной "объясняется" определенными значениями другой переменной и наоборот.
Как вычисляется уровень статистической значимости? Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: "насколько значима эта зависимость?" Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? Ответ: "в зависимости от обстоятельств". Именно, значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными. Таким образом, для того чтобы определить уровень статистической значимости, вам нужна функция, которая представляла бы зависимость между "величиной" и "значимостью" зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно "насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет". Другими словами, эта функция давала бы уровень значимости (p - уровень), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции. Эта "альтернативная" гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом распределений, называемым нормальным.
Почему важно Нормальное распределение? Нормальное распределение важно по многим причинам. В большинстве случаев оно является хорошим приближением функций, определенных в предыдущем разделе (более подробное описание см. в разделе «Все ли статистики критериев нормально распределены?»). Распределение многих статистик является нормальным или может быть получено из нормальных с помощью некоторых преобразований. Рассуждая философски, можно сказать, что нормальное распределение представляет собой одну из эмпирически проверенных истин относительно общей природы действительности и его положение может рассматриваться как один из фундаментальных законов природы. Точная форма нормального распределения (характерная "колоколообразная кривая") определяется только двумя параметрами: средним и стандартным отклонением.
Характерное свойство нормального распределения состоит в том, что 68% всех его наблюдений лежат в диапазоне ±1 стандартное отклонение от среднего, а диапазон ±2 стандартных отклонения содержит 95% значений. Другими словами, при нормальном распределении, стандартизованные наблюдения, меньшие -2 или большие +2, имеют относительную частоту менее 5% (Стандартизованное наблюдение означает, что из исходного значения вычтено среднее и результат поделен на стандартное отклонение (корень из дисперсии)). Если у вас имеется доступ к пакету STATISTICA, Вы можете вычислить точные значения вероятностей, связанных с различными значениями нормального распределения. используя вероятностный калькулятор, например, если задать z-значение (т. е. значение случайной величины, имеющей стандартное нормальное распределение) равным 4, соответствующий вероятностный уровень, вычисленный STATISTICA будет меньше.0001, поскольку при нормальном распределении практически все наблюдения (т. е. более 99.99%) попадут в диапазон ±4 стандартных отклонения.
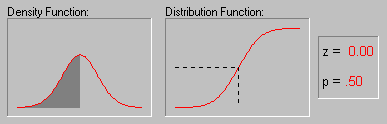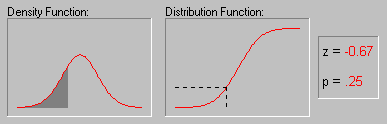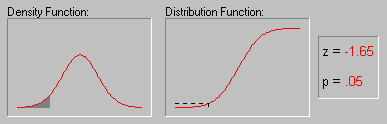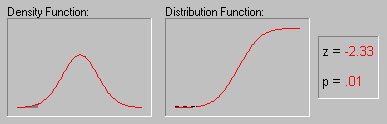
Иллюстрация того, как нормальное распределение используется в статистических рассуждениях (индукция). Напомним пример, обсуждавшийся выше, когда пары выборок мужчин и женщин выбирались из совокупности, в которой среднее значение WCC для мужчин и женщин было в точности одно и то же. Хотя наиболее вероятный результат таких экспериментов (одна пара выборок на эксперимент) состоит в том, что разность между средними WCC для мужчин и женщин для каждой пары близка к 0, время от время появляются пары выборок, в которых эта разность существенно отличается от 0. Как часто это происходит? Если объем выборок достаточно большой, то разности "нормально распределены" и зная форму нормальной кривой, вы можете точно рассчитать вероятность случайного получения результатов, представляющих различные уровни отклонения среднего от 0 - значения гипотетического для всей популяции. Если вычисленная вероятность настолько мала, что удовлетворяет принятому заранее уровню значимости, то можно сделать лишь один вывод: ваш результат лучше описывает свойства популяции, чем "нулевая гипотеза". Следует помнить, что нулевая гипотеза рассматривается только по техническим соображениям как начальная точка, с которой сопоставляются эмпирические результаты. Отметим, что все это рассуждение основано на предположении о нормальности распределения этих повторных выборок (т. е. нормальности выборочного распределения). Это предположение обсуждается в следующем разделе.
Все ли статистики критериев нормально распределены? Не все, но большинство из них либо имеют нормальное распределение, либо имеют распределение, связанное с нормальным и вычисляемое на основе нормального, такое как t, F или хи-квадрат. Обычно эти критериальные статистики требуют, чтобы анализируемые переменные сами были нормально распределены в совокупности. Многие наблюдаемые переменные действительно нормально распределены, что является еще одним аргументом в пользу того, что нормальное распределение представляет "фундаментальный закон". Проблема может возникнуть, когда пытаются применить тесты, основанные на предположении нормальности, к данным, не являющимся нормальными (смотри критерии нормальности в разделах Непараметрическая статистика и распределения или Дисперсионный анализ). В этих случаях вы можете выбрать одно из двух. Во-первых, вы можете использовать альтернативные "непараметрические" тесты (так называемые "свободно распределенные критерии", см. раздел Непараметрическая статистика и распределения). Однако это часто неудобно, потому что обычно эти критерии имеют меньшую мощность и обладают меньшей гибкостью. Как альтернативу, во многих случаях вы можете все же использовать тесты, основанные на предположении нормальности, если уверены, что объем выборки достаточно велик. Последняя возможность основана на чрезвычайно важном принципе, позволяющем понять популярность тестов, основанных на нормальности. А именно, при возрастании объема выборки, форма выборочного распределения (т. е. распределение выборочной статистики критерия, этот термин был впервые использован в работе Фишера, Fisher 1928a) приближается к нормальной, даже если распределение исследуемых переменных не является нормальным. Этот принцип иллюстрируется следующим анимационным роликом, показывающим последовательность выборочных распределений (полученных для последовательности выборок возрастающего размера: 2, 5, 10, 15 и 30), соответствующих переменным с явно выраженным отклонением от нормальности, т. е. имеющих заметную асимметричность распределения.
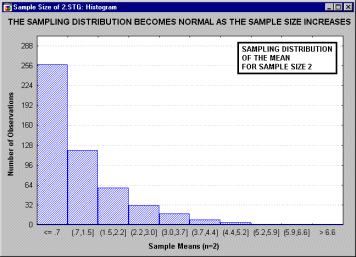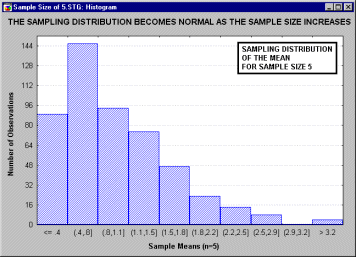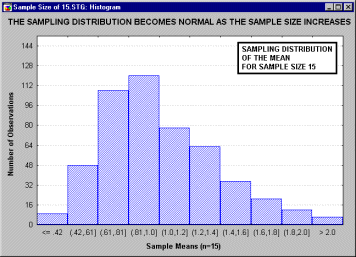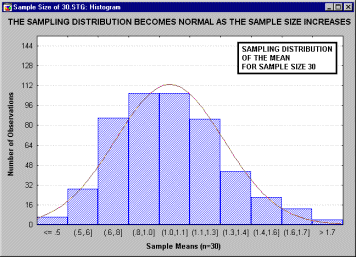
Однако по мере увеличения размера выборки, используемой для получения распределения выборочного среднего, это распределение приближается к нормальному. Отметим, что при размере выборки n=30, выборочное распределение "почти" нормально (см. на близость линии подгонки). Этот принцип называется центральной предельной теоремой (впервые этот термин был использован в работе Polya, 1920; по-немецки "Zentraler Grenzwertsatz").
Как узнать последствия нарушений предположений нормальности? Хотя многие утверждения других разделов Элементарных понятий статистики можно доказать математически, некоторые из них не имеют теоретического обоснования и могут быть продемонстрированы только эмпирически, с помощью так называемых экспериментов Moнте-Кaрло. В этих экспериментах большое число выборок генерируется на компьютере, а результаты, полученные из этих выборок, анализируются с помощью различных тестов. Этим способом можно эмпирически оценить тип и величину ошибок или смещений, которые вы получаете, когда нарушаются определенные теоретические предположения тестов, используемых вами. Исследования с помощью методов Монте-Карло интенсивно использовались для того, чтобы оценить, насколько тесты, основанные на предположении нормальности, чувствительны к различным нарушениям предположений нормальности. Общий вывод этих исследований состоит в том, что последствия нарушения предположения нормальности менее фатальны, чем первоначально предполагалось. Хотя эти выводы не означают, что предположения нормальности можно игнорировать, они увеличили общую популярность тестов, основанных на нормальном распределении.
Основная часть УМК
1 РАБОЧАЯ ПРОГРАММА учебной дисциплины
1.1 Пояснительная записка
Дисциплина «Теория вероятностей и математическая статистика» для студентов специальности «Прикладная информатика в экономике» (080801) входит в состав Государственного Образовательного Стандарта Высшего Профессионального Образования (ГОС ВПО).
Изучение дисциплины «Теория вероятностей и математическая статистика» проводится на втором курсе и нацелено на формирование у будущих специалистов навыков применения статистических методов при решении различных научно-технических задач.
Выписка из ГОС ВПО специальности
«Прикладная информатика в экономике»
ЕН. Ф.04 | Теория вероятностей и математическая статистикаАксиоматика теории вероятностей; случайные величины, их распределение и числовые характеристики; предельные теоремы теории вероятностей; случайные процессы; точечное и интервальное оценивание; проверка статистических гипотез; линейные статистические модели. | 190 |
Основная цель курса – подготовить студентов к использованию практических способов статистического анализа данных.
Задачи учебной дисциплины: обеспечить уровень подготовки студентов по дисциплине таким, чтобы они умели:
- математически ставить общие задачи и предлагать адекватные методы их решения;
- конструировать математические модели процессов и явлений;
- рассчитывать параметры конструкций и систем, обеспечивающих безопасность жизнедеятельности;
- решать конкретные задачи предприятий с применением статистических методов;
- давать статистически обоснованные прогнозы;
- статистически обобщать и давать критический анализ результатов работы учреждений по повышению эффективности их деятельности.
Для этого студенты должны знать:
– случайные величины и их распределения. Числовые характеристики распределений;
– предельные теоремы теории вероятностей;
– случайные процессы;
- «разведочный» анализ данных;
- элементы дисперсионного анализа;
- элементы теории вероятностей;
- математическую статистику;
- статистические методы обработки экспериментальных данных;
- непараметрические методы;
- задачи классификации и компьютерное обеспечение задач статистики.
В результате изучения курса "Теория вероятностей и математическая статистика" специалист должен:
- усвоить фундаментальные понятия теории вероятностей;
- овладеть основными методами постановки и решения задач математической статистики;
- знать методы и средства предварительного анализа данных, установления статистических связей; внутригрупповые и межгрупповые статистики; ранговые распределения; неколичественные оценки;
- уметь практически использовать методы математической статистики и программные средства для решения прикладных задач анализа данных.
Методы обучения включают в себя:
- лекции, на которых закладываются теоретическая база знаний по дисциплине «Прикладные задачи математической статистики»;
- практические занятия, где студенты приобретают навыки в решении задач по отдельным разделам статистики;
- самостоятельная работа студентов, которая осуществляется в двух формах: индивидуального выполнения заданий и индивидуально-аудиторного – с частичной консультацией у преподавателя;
- разбор сложных задач на плановых консультациях.
Семестр | Виды учебных занятий ДО | Форма контроля | |||||
Аудиторные | Внеаудиторные | ||||||
Лекции | Практические | Лабораторные | Контрольная | Курсовая | Самостоя-тельная работа | ||
3 | 36 | 18 | - | - | - | 41 | экзамен |
4 | 16 | 34 | - | - | - | 45 | зачет |
Всего | 52 | 52 | - | - | - | 86 |
Учебная программа дисциплины сохраняется на ЗО для специальности АЗС в четвертом семестре. Промежуточный контроль при защите контрольной работы по дисциплине.
Семестр | Виды учебных занятий ЗО | Форма контроля | |||||
Аудиторные | Внеаудиторные | ||||||
Лекции | Практические | Лабораторные | Контрольная | Курсовая | Самостоя-тельная работа | ||
4 | 6 | 4 | - | - | - | 90 | экзамен |
Всего | 6 | 4 | - | - | - | 90 |
1.2 инновационные образовательные технологии
1.2.1 Рейтинговая система оценки знаний
Уровень математической подготовки студентов в силу известных причин разнороден. Эту ситуацию необходимо учитывать при проведении практических занятий. Очень велика роль преподавателя как организатора самостоятельной познавательной деятельности студентов. Для управления этой деятельностью и эффективного отслеживания работоспособности студентов важно использовать индивидуальный подход, учитывающий уровень подготовки каждого студента.
При проведении практических занятий по дисциплине ЕН. Ф «Теория вероятностей и математическая статистика» используется рейтинговая система оценки знаний. Занятия проводятся с использованием практикума «Элементы комбинаторики, теории вероятностей и прикладные задачи математической статистики».
Каждый студент, получив задания в начале семестра, должен к очередному занятию проработать соответствующий лекционный материал, подготовить ответы на вопросы по теме занятия, разобрать приведенные на лекции примеры и попытаться решить одну из задач. На занятиях после планового контроля теоретических знаний студенты самостоятельно решают задачи, а преподаватель консультирует их, указывая, в случае необходимости, идею решения, и поэтапно проверяет работу студентов, выясняя в ходе проверки степень их теоретической подготовки. В случае возникновения общих затруднений или однотипных ошибок преподаватель дает общие указания и разъяснения. В конце занятия преподаватель оценивает работу каждого студента в зависимости от степени его теоретической подготовки и количества решенных задач.
Самостоятельная работа студентов оценивается на основе балльной системы. За правильный ответ на один теоретический вопрос, а также за правильно решенную задачу студент получает определенное количество баллов. Аналогично оцениваются решения заданий при проведении контрольных и семестровых работ, а также ответы на вопросы экзаменационных билетов. Нерешенные на занятии задачи остаются в качестве домашних заданий. Однако студент в течение занятия должен решить определенный минимум задач. Студенты, не выполнившие на занятии установленный объем работы или пропустившие занятия, обязаны явиться в указанное время для дополнительной работы.
Индивидуальные задания разработаны по всем темам курса «Теории вероятностей и математической статистики». При разработке заданий автор руководствовался следующими соображениями. Задачи в задании расположены в порядке возрастания сложности, включая задачи, решаемые по образцу, данному преподавателем на лекции, или по обобщенному алгоритму, реконструктивно-вариативные, частично-поисковые, а также задачи исследовательского характера. Как показывает опыт, шок от неудачи при решении первой же задачи редко оказывается полезным. Поэтому первые две задачи должны быть по силам каждому студенту. Помимо этого задания должны включать задачи, способствующие приобретению исследовательских навыков или задачи, требующие анализа полученных результатов. При этом преподаватель на каждом занятии должен обеспечивать всем студентам возможность преодоления трудностей, возникающих при решении задач. Чтобы студенты могли работать интенсивно, в посильном для них темпе, задания должны быть разработаны с учетом времени их выполнения как хорошо подготовленными, так и слабыми студентами.
Варианты заданий требуют различного уровня мышления – от простого решения по образцу или алгоритму до уровня самостоятельного построения некоторых логических схем с элементами исследовательского характера. Индивидуальные задания, построенные таким образом, позволяют работать самостоятельно всем студентам с учетом различного уровня их подготовки. При этом возможна самооценка понимания предмета. Вместе с тем преподаватель имеет возможность оценить индивидуальные способности и знания студентов и оперативно корректировать задания, учитывая его сложность и объем, то есть целенаправленно управлять познавательной деятельностью.
К концу семестра каждый студент набирает определенную сумму баллов, которая красноречиво говорит о его успехах в изучении дисциплины. При получении более 70% от максимально возможной суммы баллов (без учета экзамена) студент освобождается от экзамена и получает оценку «отлично». При получении от 50 до 70% - получает оценку «хорошо» при согласии студента. Студенты, набравшие менее 50% от максимальной суммы баллов, сдают экзамен.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
