

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Процесс сегментации состоит из двух стадий:
1. Определение принципов сегментирования (формирование признаков сегментирования, выбор метода) и осуществление сегментирования рынка.
2. Характеристика выявленных сегментов (интерпретация полученных сегментов).
Определение принципов сегментирования начинается с выбора признаков сегментации. Для сегментирования рынка предлагается использовать большой спектр признаков, обычно группируемых в географические, демографические, психологические, поведенческие и т. д. признаки. Подробный перечень и характеристика переменных сегментирования даны Ф. Котлером [7] и часто используются другими авторами [8].
Следующий шаг определения принципов сегментирования — выбор метода сегментации. Остановимся на методе кластерного анализа, который рекомендуется применить при проведении маркетингового исследования в рамках данной курсовой работы. Кластерный анализ — один из базовых методов, используемый в мировой практике многомерной классификации. В отечественной и зарубежной литературе можно встретить и другие названия этого метода: «post hoc», «cluster-based», метод таксономии, метод «К-сегментирование».
Данный метод используется при условии неопределенности признаков сегментирования и сущности самих сегментов. Исследователь предварительно выбирает ряд интерактивных по отношению к респонденту (метод подразумевает проведение опроса) переменных и далее в зависимости от высказанного отношения к определенной группе переменных, респондентов относит к соответствующему сегменту.
Метод кластерного анализа направлен на поиск признаков сегментирования с последующим отбором сегментов. Сегментирование производится в отношении определенного товара (услуги), при этом предполагается, что существует потребительский рынок, структура которого неизвестна и не может быть определена заранее по задаваемым признакам.
Условия успешности реализации метода:
§ наличие у фирмы минимум 100 клиентов (покупателей или лиц, которым реализуется товар) в месяц;
§ возможность проведения опроса клиентов фирмы.
Обычно выделяют 4—6 устойчивых сегментных групп, в отношении которых и производится товарная дифференциация. Если в результате выделения сегментов их количество слишком велико, то рассчитывается процент респондентов, оказавшихся в той или иной сегментной группе, полагая, что этот процент можно распространить на всех клиентов. Группы с наиболее высоким процентом и выделяются как сегменты рынка.
На последнем шаге выделенные сегменты описывают и присваивают им специальные маркетинговые «прозвища» для удобства последующей работы. Таким образом, получаем выделенные признаки сегментирования и сегменты, в отношении которых может проводиться проектирование, модернизация или позиционирование товара.
Результаты кластерного анализа фактически описывают портрет потребителя с рациональной (свойства товара) и эмоциональной (оценка степени согласия с утверждениями) точки зрения. На их основании можно определить целевой рынок фирмы, расставить акценты в рекламном сообщении и рекламной кампании в целом. Можно избавиться от иллюзий относительно исключительности своего товара по какому-либо определенному свойству, если вдруг выясниться, что практически все потребители ставят его на последнее место по важности или вообще игнорируют данный признак.
Использование результатов сегментирования на основании кластерного анализа дает любой компании реальный шанс глубже понять своих потребителей. Это, в свою очередь, позволит свести к минимуму разницу между представлениями продавцов и покупателей, т. е. карта восприятия товара или услуги для них будет практически идентичной.
3. Проведение маркетинговых исследований
3.1 Метод формирования выборки и определение ее объема
При проведении маркетинговых исследований возникает необходимость получить информацию о параметрах «группы», среди членов которой будет проводиться маркетинговое исследование. Такая «группа» в статистике называется генеральной совокупностью. Иногда совокупность является достаточно малой по своей численности, и можно изучить всех ее членов. Обычно же это сделать невозможно, следовательно, проводится изучение только части совокупности, называемой выборкой. Поскольку выборка является частью изучаемой совокупности, полученные от выборки данные не будут в точности соответствовать данным, которые можно было бы получить от всех единиц совокупности. Различие между данными, полученными от выборки, и истинными данными называется ошибкой выборки. Ошибка выборки обусловлена двумя факторами: методом формирования выборки и размером выборки.
При формировании выборки в рамках курсовой работы рекомендуется использовать метод отбора на основе принципа удобства [3]. Смысл этого метода заключается в том, что формирование выборки осуществляется самым удобным с позиций исследования образом, например, с позиций минимальных затрат времени и усилий, с позиции доступности респондентов.
Объем выборки проводится на основе расчета доверительного интервала. Исходной информацией, необходимой для реализации данного подхода, является:
1) Величина вариации, которой, как считается, обладает совокупность.
2) Желаемая точность.
3) Уровень доверительности, которому должны удовлетворять результаты проводимого исследования.
Когда на заданный вопрос существует только два варианта ответа, объем выборки определяется по следующей формуле [3]:
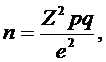 (1)
(1)
где n – объем выборки;
Z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности (табл.2);
р – найденная вариация для выборки;
q = (100 – р);
е – допустимая ошибка.
Например, фирмой, выпускающей шампуни, проводится опрос респондентов. На вопрос: «Используете ли вы данный шампунь при мытье головы?» возможно только два ответа: «Да» или «Нет». Если совокупность опрошенных респондентов обладает низким показателем вариации, то это означает, что почти каждый опрошенный использует данную марку шампуня. В этом случае может быть сформирована выборка достаточно малых размеров. В формуле (1) произведение pq выражает вариацию, свойственную совокупности. Предположим, что 90% единиц совокупности используют данную марку. Это означает, что pq = 900. Наибольшая вариация достигается в случае, когда половина совокупности (50%) использует данную марку шампуня, а другая (50%) – не использует. В этом случае произведение pq достигает наибольшего значения, равного 2500.
Таблица 2
Значение нормированного отклонения оценки (Z) от среднего значения в зависимости
от доверительной вероятности (α) полученного результата
α, % | 60 | 70 | 80 | 85 | 90 | 95 | 97 | 99 | 99,7 |
Z | 0,84 | 1,03 | 1,29 | 1,44 | 1,65 | 1,96 | 2,18 | 2,58 | 3,0 |
Что касается уровня доверительности, то при проведении маркетинговых исследований обычно рассматриваются только два его значения: 95% или 99% [3]. Первому значению соответствует Z = 1,96, второму – Z = 2,58. Если выбирается уровень доверительности, равный 99%, то это говорит о том, что мы уверены на 99% в том, что процент членов совокупности, попавших в диапазон ± е%, равен проценту членов выборки, попавших в тот же диапазон ошибки. Принимая вариацию, равную 50%, точность, равную ± 10%, при 95%-ном уровне доверительности, рассчитаем размер выборки:
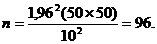 (2)
(2)
Студентам для проведения маркетингового исследования рекомендуется использовать выборку численностью не менее 96 респондентов в соответствии с формулой (2). Больший размер выборки только приветствуется.
3.2 Разработка анкеты для проведения опроса
Для проведения опроса студентам необходимо разработать опросный лист или анкету. В анкетах используют закрытые и открытые вопросы.
Закрытые вопросы - это вопросы, ответы на которые заключаются в выборе приведенных вариантов. Вопросы подразделяются следующим образом:
а) «Да – Нет» вопросы
б) Альтернативные вопросы, в которых нужно выбрать из ряда возможных ответов один или несколько
в) Вопросы со шкалой Лейкерта - это вопросы с предложением указать степень согласия или несогласия с сутью сделанного заявления.
Например: “Реклама сигарет вредна”
□ - полностью согласен
□ - согласен
□ - не знаю
□ - не согласен
□ - решительно не согласен
г) Шкалирующие вопросы дают дифференцированную оценку похожести или различия исследуемых объектов. Различают шкалу важности - это шкала с ранжированием любой характеристики по степени важности для клиента.
Например: “Трудоустройство для меня после окончания бизнес-школы”
□ - исключительно важно
□ - очень важно
□ - довольно важно
□ - не очень важно
□ - совсем не важно
д) Семантический дифференциал - это шкала разрядов между двумя биполярными понятиями, в которой опрашиваемый человек выбирает точку, соответствующую направленности и интенсивности его чувств. Семантический дифференциал имеет модификации. Одна из них – школа Степпела. В этом случае респондентом выставляется оценка соответствующей характеристики товара либо по 7- балльной шкале со значениями от +3 до -3 баллов (от «превосходно» до «безобразно») либо по 5-балльной шкале со значениями от +2 до -2 баллов (от «очень хорошо» до «очень плохо»).
Открытый вопрос дает возможность опрашиваемому человеку отвечать своими словами. Открытые вопросы часто дают гораздо больше информации, поскольку опрашиваемые ничем не связаны в своих ответах. Особенно полезны открытые вопросы на поисковом этапе исследования, когда необходимо установить, что люди думают, не замеряя, какое количество из них думает тем или иным способом. С другой стороны, закрытые вопросы легче интерпретировать и сводить в таблицы.
Анкета для курсовой работы должна содержать 14-16 вопросов разного типа. Начинаться анкета должна с вопроса «Да» - «Нет», сформулированного в деликатной форме. Далее идет дихотомический вопрос, в котором вы предлагаете клиенту выбрать марку употребляемого им товара из предложенных альтернатив. Обязательно надо оставить окошко «Другое», так как все товарные марки перечислить просто невозможно. Напротив каждого вопроса должны быть проставлены полученные в ходе обработки данных числовые показатели в процентах, натуральном выражении (штуки), в денежном выражении (рубли). Если в окошке «Другое» поставили галочку более 30% опрошенных респондентов, то считается, что анкета не проработана. Обобщенные свойства у тестируемого товара необходимо представить в виде шкалы Степпела, используя разброс чувств респондента от «-2» до «+2». В приложении Б приведен образец обработанной анкеты, полученной в ходе проведения исследований на рынке шампуней.
3.3 Отношение потребителей к выбранному товару (услуге) с помощью многофакторной модели Фишбейна
Для изучения отношений потребителей к выбранному товару (услуге) рекомендуется использовать многофакторную модель Фишбейна, подробно описанную в работе [10]. Формула Фишбейна имеет следующий вид:
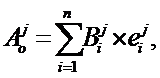 (3)
(3)
где Аоj – отношение респондента j к тестируемому товару или услуге;
Вij – сила мнения респондента j, что тестируемый товар (услуга) имеют характеристику i;
е ij – оценка значимости характеристики i для респондента;
i = 1, …, n, n – число значимых характеристик;
j = 1, …, m, m – количество респондентов.
Рассмотрим, как работает формула Фишбейна на примере результатов опроса клиентов на рынке шампуней. Как видно из Приложения Б, шампунь тестировался по 6 обобщенным свойствам:
1) состав/ наполнители;
2) лечебные свойства;
3) многофункциональность;
4) ассортимент;
5) цена;
6) упаковка.
Из данных таблицы 3 следует, что, к примеру, 3-й опрошенный респондент, покупающий шампунь марки «Чистая линия» считает, что
1) состав данного шампуня его устраивает, т. е. 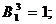
2) клиенту все равно, какими лечебными свойствами обладает данный шампунь, т. е. ![]()
3) многофункциональность данного шампуня хорошая, т. е. 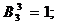
4) ассортимент продукции тестируемой торговой марки плохой, т. е. 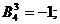
5) цена данной марки шампуня приемлемая, т. е. ![]()
6) наконец, упаковка также устраивает клиента, т. е. ![]()
В то же время оценка значимости этих характеристик идеальной марки шампуня для данного респондента такова: 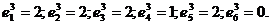
Подсчитаем отношение респондента к шампуню марки «Чистая линия» по формуле (3):
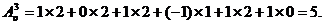
Подобные расчеты проводятся для всех 96 или более опрошенных респондентов в электронных таблицах Microsoft Excel и представляются в виде сводной таблицы 3. Обязательно в таблице тестируемую марку заливать другим цветом для проверки правильности обработанных данных.
Таблица 3
Данные расчетов отношений респондентов к тестируемому товару
по формуле Фишбейна
Номер респондента | Сила мнения респондента j, что тестируемый товар имеет характеристику i (i = 1, …, n) | Оценка значимости характеристики i для респондента j | Отношение респондента j к тестируемому товару | Торговые марки | ||||||||||
B1j | B2j | B3j | B4j | B5j | B6j | е1j | е2j | е3j | е4j | е5j | е6j | |||
1 | 0 | 1 | 0 | 2 | -1 | 0 | 1 | 2 | 0 | 2 | 2 | 0 | 4 | К10 |
2 | 2 | 2 | 2 | 0 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 0 | 14 | К13 |
3 | 1 | 0 | 1 | -1 | 1 | 1 | 2 | 2 | 2 | 1 | 2 | 0 | 5 | ! |
4 | 1 | 1 | 0 | 0 | 1 | 0 | 2 | 2 | 2 | 2 | 2 | 2 | 6 | К5 |
5 | 1 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 16 | К4 |
6 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | К12 |
7 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | -1 | 0 | -1 | 1 | -1 | К7 |
8 | 0 | 1 | 1 | 0 | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 9 | К12 |
9 | 1 | 1 | 1 | 0 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 12 | К5 |
10 | 1 | 2 | -2 | 2 | 2 | 2 | 1 | 2 | 1 | -1 | 1 | 2 | 7 | К11 |
11 | 0 | 2 | 1 | 1 | 0 | 1 | 0 | 2 | 2 | 2 | 0 | 0 | 8 | К10 |
12 | 0 | 1 | 2 | 2 | 1 | 1 | 0 | 1 | 2 | 1 | 0 | 1 | 8 | К10 |
13 | 0 | -1 | -2 | 1 | 1 | 2 | 0 | 2 | 1 | 2 | 2 | 2 | 4 | К12 |
14 | 2 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 18 | К6 |
15 | 0 | 2 | 2 | 2 | 0 | 2 | 2 | 2 | 2 | 0 | 2 | 0 | 8 | К10 |
16 | 2 | 2 | -2 | -1 | 2 | 2 | 2 | 2 | -1 | -1 | 2 | -1 | 13 | К1 |
17 | 1 | 1 | -2 | -2 | 2 | 2 | 2 | 2 | -2 | -2 | 2 | 0 | 16 | К1 |
18 | 1 | 1 | 2 | 2 | 1 | 0 | 2 | 1 | 2 | 1 | -1 | 0 | 8 | К14 |
19 | 1 | 1 | 0 | 0 | 1 | 1 | 2 | 1 | 0 | 2 | 2 | 1 | 6 | ! |
20 | 1 | 2 | 2 | -2 | 1 | 2 | 2 | 2 | 2 | 2 | 0 | 0 | 6 | К12 |
21 | 2 | 2 | 1 | 0 | 1 | 2 | 2 | 2 | -1 | 2 | 0 | -1 | 5 | К9 |
22 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 1 | 16 | К13 |
23 | 1 | 1 | 0 | 2 | 0 | 2 | 1 | 2 | 1 | 2 | 1 | 0 | 7 | К7 |
24 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 7 | К11 |
25 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 2 | 0 | 4 | К11 |
26 | 1 | 1 | 0 | 1 | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 9 | К11 |
27 | -1 | 1 | -1 | 0 | 1 | 2 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | ! |
28 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 12 | К13 |
29 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 24 | К8 |
30 | 2 | 2 | -1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 16 | ! |
31 | 1 | 1 | 1 | 0 | 0 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 8 | К9 |
32 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 24 | К16 |
Продолжение таблицы 3

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
