
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Группировкой называется процесс упорядочения и систематизации данных, полученных в ходе проведения эксперимента, направленный на извлечение содержащейся в них информации. В процессе группировки осуществляется распределение вариант выборки по группам или интервалам группировки, каждый из которых содержит некоторый диапазон значений изучаемого признака. Процесс группировки начинается с разбиения всего диапазона варьирования признака на интервалы группировки.
Для каждой конкретной цели статистического исследования, объема рассматриваемой выборки и степени варьирования признака в ней существует оптимальное значение числа интервалов и ширины каждого из них. Ориентировочное значение оптимального числа интервалов k может быть определено, исходя из объема выборки п либо с помощью данных, приведенных в таблице 3., либо с помощью формулы Стэрджесса:
k = 1 + 3,322 lgn.
Таблица 3
Определение числа интервалов группировки
Объем выборки n | 10-30 | 30-60 | 60-100 | 100-300 | 300-400 |
Число интервалов k | 4-5 | 5-6 | 7 | 8 | 9 |
Получаемое по формуле значение k почти всегда оказывается дробной величиной, которую необходимо округлить до целого числа, поскольку количество интервалов не может быть дробным. Практика показывает, что, как правило, лучше округлять в меньшую сторону, ибо формула дает хорошие результаты при больших значениях n, а при малых - несколько завышенные.
Рассмотрим группировку вариант выборки на конкретном примере. Для этого обратимся к примеру с толкателями ядра (см. таблицы 1, 2). Определение числа интервалов группировки будем производить на основе данных, приведенных в таблице 3. При объеме выборки n=29 число интервалов целесообразно выбрать равным k =5 (формула Стэрджесса дает значение k =5,9).
Условимся использовать в рассматриваемом примере интервалы равной ширины. В этом случае после того, как число интервалов группировки определено, следует вычислить ширину каждого из них с помощью соотношения:
![]() .
.
Здесь h - ширина интервалов, а хmax и хmin - соответственно максимальное и минимальное значение признака в выборке. Величины хmax и хmin определяются непосредственно по таблице исходных данных (см. таблицу 2). В рассматриваемом случае:
![]() (м).
(м).
Здесь необходимо остановиться на точности определения ширины интервала. Возможны две ситуации: точность вычисленного значения h совпадает с точностью проведения эксперимента или превышает ее. В последнем случае возможно использование двух подходов для определения границ интервалов. С теоретической точки зрения наиболее правильно использовать полученное значение h для построения интервалов. Такой подход не внесет дополнительных искажений, связанных с обработкой экспериментальных данных. Однако для практических целей в статистических исследованиях, относящихся к физической культуре и спорту, принято округлять полученное значение h до точности измерения данных. Связано это с тем, что для наглядного представления получаемых результатов удобно, чтобы границами интервалов являлись возможные значения признака. Таким образом, полученное значение ширины интервалов следует округлить с учетом точности проводимого эксперимента. Особо отметим, что округление необходимо производить не в общепринятом математическом смысле, а в сторону увеличения, т. е. с избытком, чтобы не уменьшить общий диапазон варьирования признака - сумма ширины всех интервалов не должна быть меньше разности между максимальным и минимальным значениями признака. В рассматриваемом примере экспериментальные данные определены с точностью до сотых (0,01 м), поэтому полученное выше значение ширины интервалов следует округлить с избытком с точностью до сотых. В результате получаем:
h= 0,67 (м).
После определения ширины интервалов группировки следует определить их границы. Нижнюю границу первого интервала целесообразно принять равной минимальному значению признака в выборке xmin:
xН1= xmin.
В рассматриваемом примере xН1 = 13,04 (м).
Для получения верхней границы первого интервала (xВ1) следует к значению нижней границы первого интервала прибавить значение ширины интервала:
xВ1= хН1+h.
Заметим, что верхняя граница каждого интервала (здесь – первого) будет являться одновременно и нижней границей следующего (в данном случае второго) интервала: xН2= xВ1.
Подобным образом определяются значения нижних и верхних границ всех оставшихся интервалов:
xВi =xНi+1= xНi+h.
В рассматриваемом примере:
xВ1= xН2= xН1+h=13,04+0,67=13,71 (м),
xВ2= xН3= xН2+h=13,71+0,67=14,38 (м),
xВ3= xН4= xН3+h=14,38+0,67=15,05 (м),
xВ4= xН5= xН4+h=15,05+0,67=15,72 (м),
xВ5= xН5+h=15,72+0,67=16,39 (м).
Перед группировкой вариант введем понятие срединного значения интервала xi, равного значению признака, равноудаленного от концов этого интервала. Учитывая, что оно отстоит от нижней границы на величину, равную половине ширины интервала, для его определения удобно воспользоваться соотношением:
xi= xНi+ h/2,
где xНi - нижняя граница i-ro интервала, а h - его ширина. Срединные значения интервалов будут использоваться в дальнейшем при обработке сгруппированных данных.
После определения границ всех интервалов следует распределить выборочные варианты по этим интервалам. Но предварительно следует решить вопрос о том, к какому интервалу отнести значение, находящееся в точности на границе двух интервалов, т. е. когда значение варианты совпадает с верхней границей одного и нижней границей соседнего с ним интервала. В таком случае варианта может быть отнесена к любому из двух соседних интервалов и, для исключения неоднозначности при группировке, условимся в таких случаях относить варианты к верхнему интервалу. В пользу такого подхода можно привести следующий довод. Поскольку минимальное значение признака совпадает с нижней границей первого интервала и входит в этот интервал, то варианту, попадающую на границу двух интервалов, следует отнести к тому из них, значение нижней границы которого равно рассматриваемой варианте.
Перейдем к рассмотрению статистической таблицы - см. таблицу 4, которая состоит из семи столбцов.
Таблица 4
Табличное представление результатов в толкании ядра
1 | 2 | 3 | 4 | 5 | 6 | 7 |
Номер интервала | Границы интервала | Срединное значение интервала | Частота | Накопленная частота | Частость | Накопленная частость |
i | xНi – xВi | xi | ni | Ni | fi | Fi |
1 2 3 4 5 | 13,04 – 13,71 13,71 – 14,38 14,38 – 15,05 15,05 – 15,72 15,72 – 16,39 | 13,375 14,045 14,715 15,385 16,055 | 4 8 10 5 2 | 4 12 22 27 29 | 0,138 0,276 0,345 0,172 0,069 | 0,138 0,414 0,759 0,931 1 |
Сумма | 29 | 1 |
В первых трех столбцах статистической таблицы содержатся соответственно номера интервалов группировки i, их границы xНi - xВi и срединные значения интервалов xi.
В четвертом столбце располагаются частоты интервалов. Частотой интервала называется число, показывающее сколько вариант, т. е. результатов измерений попало в данный интервал. Для обозначения этой величины принято использовать символ ni. Сумма всех частот всех интервалов всегда равна объему выборки п, что можно использовать для проверки правильности проведенной группировки.
Пятый столбец таблицы 4 предназначен для занесения в него накопленной частоты интервала - числа, полученного суммированием частоты текущего интервала с частотами всех предыдущих интервалов. Накопленную частоту принято обозначать латинской буквой Ni. Накопленная частота показывает, сколько вариант имеют значения не больше, чем верхняя граница интервала.
В шестой столбец таблицы помещается частость. Частостью называется частота, представленная в относительном выражении, т. е. отношение частоты к объему выборки. Сумма всех частостей всегда равна 1. Для обозначения частости используется символ fi:
fi=ni/n.
Частость интервала связана с вероятностью попадания случайной величины в этот интервал. Согласно теореме Бернулли, при неограниченном увеличении числа опытов частость события сходится по вероятности к его вероятности. Если понимать под событием попадание значения исследуемой величины в определенный интервал, то становится ясно, что при большом числе опытов частость интервала приближается к вероятности попадания измеряемой случайной величины в этот интервал.
И частота, и частость характеризуют повторяемость результатов в выборке. Сравнивая их статистическое значение, следует отметить, что информативность частости существенно выше, чем у частоты. Действительно, если, как, например, в таблице 4 частота второго интервала равна 8 и, значит, 8 результатов попало в этот интервал, то трудно понять - мало это или много; если в выборке 1000 вариант, то такая частота мала, а если 20, то велика. В таком случае для объективной оценки необходимо сопоставить значение частоты с объемом выборки. Если же воспользоваться частостью, то сразу можно сказать, какая доля результатов попала в рассматриваемый интервал (примерно 28% в приведенном примере). Поэтому частость дает более наглядное представление о повторяемости признака в выборке. Особо следует отметить другое важное достоинство частости. Ее использование позволяет сопоставлять выборки различного объема. Частота для таких целей не применима.
В седьмом столбце таблицы расположена накопленная частость. Накопленной частостью является отношение накопленной частоты к объему выборки. Накопленная частость обозначается буквой Fi:
.
Накопленная частость показывает, какая доля вариант выборки имеет значения, не превосходящие значения верхней границы интервала.
Последняя строка статистической таблицы используется для контроля над проведением группировки.
После заполнения таблицы вернемся к определению статистического ряда. Как правило, статистический ряд оформляется в виде таблицы, в первой строке которой перечислены интервалы, а во второй – соответствующие им частости или частоты. Таким образом, статистическим рядом называется двойной числовой ряд, устанавливающий связь между численным значением исследуемого признака и его повторяемостью в выборке. Существенным достоинством статистических рядов является то, что они, в отличие от статистических совокупностей, дают наглядное представление о характерных особенностях варьирования признаков.
1.2.2 Графическое представление статистических рядов
В целях упрощения анализа статистических рядов и придания им большей наглядности используют графические представления. Основными видами графического представления статистических рядов являются гистограмма, полигон частостей и полигон накопленных частостей. Для визуального представления можно использовать как частости, так и частоты. Ограничимся рассмотрением частости, поскольку этот параметр более информативен.
Наиболее часто для анализа статистического ряда используется гистограмма, представляющая собой совокупность примыкающих друг к другу прямоугольников, основание каждого из которых равно ширине интервала группировки, а площадь - частости этого интервала.
Гистограмма строится в декартовой (прямоугольной) системе координат следующим образом. По оси абсцисс откладываются отрезки, отображающие интервалы группировки, а затем на каждом из них строится прямоугольник, площадь которого равна частости данного интервала. Для удовлетворения этому требованию высота прямоугольника выбирается равной частному от деления частости интервала на его ширину Hi=fi/hi. В случае, если все интервалы группировки имеют одинаковую ширину, высоты прямоугольников пропорциональны соответствующим частостям. Полная площадь гистограммы равна единице, что следует из способа ее построения. Действительно, площадь каждого из прямоугольников равна частости, а сумма всех частостей - единица.
 |
В качестве примера на рис. 1 приведена гистограмма распределения результатов, показанных на соревновании в толкании ядра, и построенная для статистического ряда, образованного по данным столбцов 2 и 6 таблицы 4.
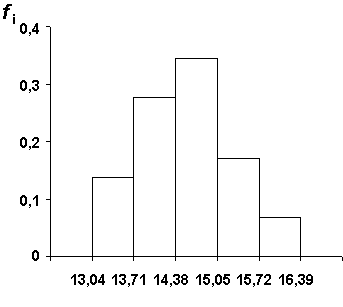 |
Рис. 1. Гистограмма
С увеличением числа экспериментальных данных можно использовать большее количество интервалов, имеющих меньшие ширины. Гистограмма при этом будет все более и более приближаться к некоторой кривой, ограничивающей площадь, равную единице. Эта кривая представляет собой не что иное как график плотности распределения (или, по-другому, плотности вероятности) исследуемой случайной величины. Таким образом, гистограмма является экспериментальным аналогом плотности распределения.
Другим распространенным способом графического представления статистических рядов является полигон частостей. Полигон частостей отображает зависимость частости от срединных значений интервалов. Полигон частостей строится в декартовой системе координат путем соединения прямыми линиями точек, абсциссы которых равны срединным значениям интервалов, а ординаты - частостям этих интервалов. Эти данные располагаются в третьем и шестом столбцах таблицы 4.
Полигон частостей может быть получен из гистограммы путем соединения середин верхних сторон прямоугольников гистограммы отрезками прямых. Полигон частостей для рассматриваемого примера изображен на рис. 2.
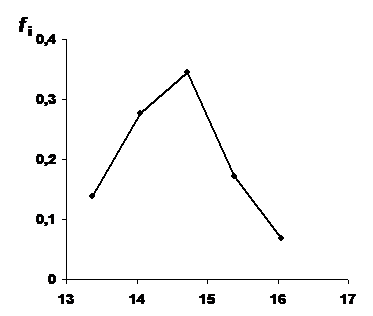
Рис. 2. Полигон частостей
Полигон частостей может оказаться более удобным и наглядным способом графического представления, чем гистограмма, в том случае, когда признак является непрерывным и его распределение описывается плавной зависимостью.
Полигон накопленных частостей представляет собой зависимость накопленных частостей от значений верхних границ интервалов. Полигон накопленных частостей строится в декартовой системе координат посредством соединения прямыми линиями точек, абсциссы которых равны значениям верхних границ интервалов, а ординаты - накопленным частостям этих интервалов. Эти данные располагаются во втором и седьмом столбцах таблицы 4. Полигон накопленных частостей для рассматриваемых экспериментальных данных приведен на рис. 3.
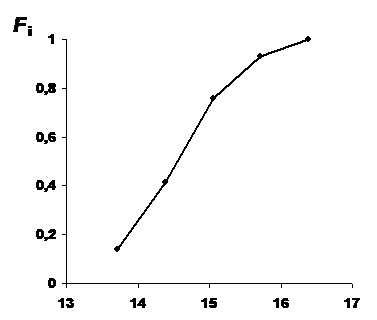
Рис. 3. Полигон накопленных частостей
Полигон накопленных частостей имеет более плавную форму, чем гистограмма или полигон частостей.
С увеличением числа опытных данных в выборке и соответственно увеличением числа используемых интервалов полигон накопленных частостей будет приближаться к кривой, являющейся графиком функции распределения исследуемой случайной величины. Таким образом, он является экспериментальным аналогом функции распределения.
1.3 Числовые характеристики выборки
Рассмотренные выше статистические ряды дают наиболее полную информацию о поведении признака. Однако в практических целях часто бывает достаточно указать только отдельные числовые параметры, до некоторой степени характеризующие существенные черты распределения. Использование таких характеристик позволяет компактно выразить все существенные сведения с помощью минимального количества числовых параметров. Такие характеристики, назначение которых - выразить в сжатой форме наиболее существенные особенности распределения, называются числовыми характеристиками.
Суть выборочного метода заключается в том, что на основании исследования ограниченного числа элементов генеральной совокупности судят об особенностях всей генеральной совокупности. Любое значение параметра распределения, вычисленное на основе ограниченного числа опытов, т. е. выборки, всегда содержит элемент случайности. Такое приближенное, случайное значение называется оценкой параметра. Значение оценки должно быть максимально близко к значению соответствующего параметра генеральной совокупности, которое является истинным значением оцениваемого параметра. Исходя из этого, к оценке предъявляется ряд требований.
При увеличении числа опытов (объема выборки) значение оценки должно приближаться (сходиться по вероятности) к истинному значению параметра. Это свойство оценки называется состоятельностью.
Оценка не должна содержать систематической ошибки в сторону завышения или занижения. Иными словами, среднее значение оценки, вычисленное по данным различных выборок из одной и той же генеральной совокупности, должно сходиться к истинному значению параметра. Оценка, удовлетворяющая этому требованию, называется несмещенной.
Желательно, чтобы выбранная несмещенная оценка обладала бы по сравнению с другими наименьшим разбросом - дисперсией. Оценка, удовлетворяющая этому требованию, называется эффективной.
На практике не всегда удается удовлетворить этим требованиям. Среди числовых характеристик наибольшее практическое значение имеют характеристики положения, рассеяния и формы распределений.
1.3.1 Характеристики положения
Рассмотрение числовых характеристик выборки необходимо начать с тех из них, которые характеризуют положение значений исследуемого признака на числовой оси, т. е. указывают некоторое среднее, ориентировочное значение, около которого группируются экспериментальные данные. К ним относятся среднее арифметическое, мода и медиана.
Среднее арифметическое равно сумме значений всех вариант выборки, деленное на объем выборки:
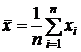 .
.
Здесь п - объем выборки, а xi - варианты выборки.
Среднее арифметическое является наиболее важной характеристикой положения, поскольку при его определении используется вся имеющаяся информация о выборке. Для обозначения среднего арифметического используется та же буква, что и для вариант выборки, с той лишь разницей, что над буквой ставится черта - символ усреднения. В рассматриваемом случае исследуемый признак обозначен через X, его числовые значения - через хi, а среднее арифметическое имеет обозначение ![]() .
.
Из определения среднего арифметического следует, что сумма отклонений выборочных значений признака от него равна нулю.
Вычислять среднее арифметическое исходя из его определения при большом объеме выборки становится затруднительным и можно применить следующий прием: воспользоваться результатами группировки и считать приближенно значения вариант в каждом интервале постоянными и равными срединному значению, которое выступает в роли «представителя» интервала. Число вариант в интервале равно частоте интервала, поэтому среднее арифметическое для сгруппированных данных будет выражаться следующей приближенной формулой:
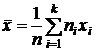 ,
,
где п - объем выборки;
k - число интервалов группировки;
ni - частоты интервалов;
xi - срединные значения интервалов.
Отметим, что платой за упрощение процесса вычислений является уменьшение их точности - точность вычислений по необработанным данным всегда выше, чем по обработанным. Исходя из этого, вычисление оценочных характеристик по первичным экспериментальным данным является предпочтительным.
Среднее арифметическое, вычисленное по результатам группировки, иногда называют взвешенным средним. Смысл такой формулировки заключается в том, что в формуле срединные значения суммируются с весами (коэффициентами), равными частотам попадания вариант в соответствующие интервалы группировки.
В качестве примера определим среднее арифметическое результатов в толкании ядра для экспериментальных данных из таблицы 1 и сгруппированных в таблице 4. Среднее арифметическое, определенное по необработанным экспериментальным данным, равно:
![]() 14,5331 (м).
14,5331 (м).
При использовании для упрощения вычислений результатов проведенной группировки получаем:
![]() (4*13,375+8*14,045+10*14,715+5*15,385+2*16,055)/29=14,55328 (м).
(4*13,375+8*14,045+10*14,715+5*15,385+2*16,055)/29=14,55328 (м).
Полученные двумя способами средние арифметические различаются на две сотых, что превышает точность измерений экспериментальных данных.
Среди других характеристик положения наиболее важны мода и медиана. Они характеризуют величину варианты, занимающей определенное положение в статистической совокупности.
Модой случайной величины называется значение признака, встречающееся в выборке наиболее часто. Условимся использовать для обозначения моды символы Mo. Геометрически мода соответствует максимуму кривой эмпирического распределения (см. рис. 4).
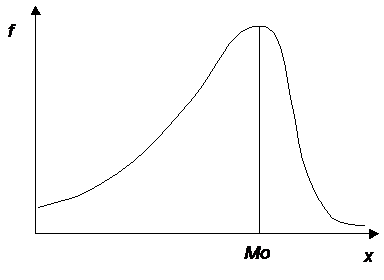
Рис. 4. Мода
С точки зрения теории вероятностей модой случайной величины является ее наиболее вероятное значение.
Если распределение случайной величины имеет более одного максимума, то распределение называется “полимодальным” (см. рис. 5).
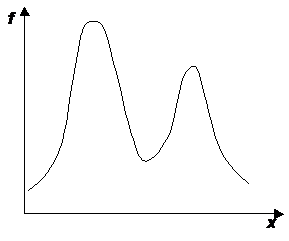
Рис. 5. Полимодальное распределение
На практике встречаются распределения, имеющие посередине не максимум, а минимум. Такие распределения принято называть “антимодальными” (см. рис. 6).

Рис. 6. Антимодальное распределение
Прежде чем приступить к вычислению значения моды в случае сгруппированных данных, необходимо определить модальный интервал. Модальным называется интервал группировки, содержащий наибольшее число вариант, т. е. имеющий максимальную частоту (частость).
Значение моды определяется по результатам группировки с помощью следующего соотношения:
,
где xMoH - нижняя граница модального интервала;
h - ширина интервала группировки;
пMo - частота модального интервала;
пМо-1 - частота интервала, предшествующего модальному;
пмо+1 - частота интервала, следующего за модальным.
При проведении исследования может оказаться, что модальным оказывается первый или последний интервал группировки. В этом случае предыдущий или последующий интервал не существует и возникает вопрос о пути применения последней формулы. Если один из интервалов не существует, то при проведении вычисления моды значение частоты, соответствующее этому интервалу, следует принять равным нулю. Это интуитивно очевидно - раз нет интервала, то нет и вариант, относящихся к нему, потому и частота должна обращаться в нуль.
В рассматриваемом примере модальным является третий интервал, а значение моды равно:
(м).
Часто для характеристики распределения применяется еще одна характеристика положения - медиана. Медианой называется такое значение признака, при котором половина значений экспериментальных данных оказывается меньше его, а вторая половина — больше. Для обозначения медианы принято использовать символы Me. Геометрический смысл медианы – это абсцисса точки, в которой площадь, ограниченная кривой распределения, делится пополам (см. рис. 7).

Рис. 7. Медиана
В случае несгруппированных данных для нахождения медианы необходимо ранжировать выборку, т. е. расположить данные в порядке их возрастания или убывания. Медианой будет являться значение признака, находящееся в середине ранжированного ряда. В ранжированной выборке, содержащей п членов, ранг RMe, т. е. порядковый номер, медианы равен:
![]() ,
,
а сама медиана совпадает с членом выборки, имеющим номер RMe. Описанное правило дает однозначный результат, если выборка содержит нечетное число членов.
Если же выборка содержит четное число членов, то медиана не может быть определена столь однозначно. Действительно, RMe оказывается дробным. В этом случае берут два члена выборки с номерами большим и меньшим RMe и считают медиану, равной их среднему значению.
Для определения медианы в случае сгруппированных данных необходимо найти медианный интервал. Интервал группировки, содержащий медиану, называется медианным. Медианным является интервал, в котором накопленная частота впервые окажется больше половины объема выборки (либо накопленная частость - больше 0,5). Значение медианы определяется по следующей формуле:
,
где хМеH - нижняя граница медианного интервала;
n - объем выборки;
h - ширина интервалов группировки;
NMe-1 - накопленная частота интервала, предшествующего медианному;
пMe - частота медианного интервала.
В рассматриваемом примере накопленная частота впервые превышает половину объема выборки (накопленная частость 0,5) в третьем интервале (см. таблицу 4), поэтому он и будет являться медианным. Само значение медианы равно:
(м).
В рассматриваемом примере все характеристики положения различаются между собой. Это свидетельствует об асимметрии эмпирического распределения.
Значения среднего арифметического, моды и медианы совпадают только для симметричных одномодальных распределений. Напомним, что распределение является симметричным, если частости двух любых вариант, равно отстоящих в обе стороны от центра распределения, равны между собой. В таких случаях все характеристики положения равноправны, но предпочтение принято отдавать среднему арифметическому, поскольку оно опирается на всю имеющуюся информацию об изучаемой выборке. Чем сильнее форма распределения отклоняется от симметричной, тем большее различие наблюдается между значениями характеристик положения.
Значение медианы наиболее важно при исследовании сильно асимметричных эмпирических распределений. В этих случаях значительная часть значений признака оказывается больше, либо меньше среднего арифметического и последнее оказывается мало пригодным для описания положения центра распределения. Использование медианы, занимающей промежуточное значение между средней арифметической и модой, для характеристики центра распределения в описанной ситуации оказывается наиболее рациональным.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
