
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
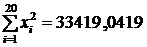 ;
;
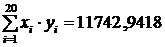 .
.
Вычислим коэффициент регрессии:
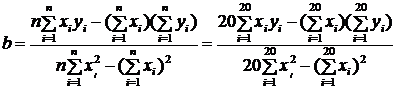 ;
;
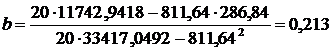 .
.
Рассчитаем значение свободного члена уравнения регрессии
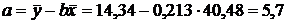 .
.
Таким образом, уравнение регрессии имеет вид:
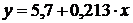 .
.
Определим стандартную ошибку предсказания. Для этого в столбце 6 таблицы 3 вычислим квадраты значений результатов толкания ядра ![]() и занесем их сумму в последнюю строку:
и занесем их сумму в последнюю строку:
 .
.
Используя полученные результаты, вычислим стандартную ошибку предсказания:
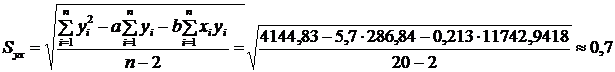 .
.
Стандартная ошибка предсказания является характеристикой точности предсказания значений случайной величины y по известным значениям случайной величины x. Зона, ограниченная двумя прямыми, отстоящими от регрессионной прямой на расстояние ±0.7, является областью, в которую с вероятностью 0,7 попадают экспериментальные значения yi. Это означает, что приблизительно 70% всех значений yi находятся в этой области.
Проверим статистическую значимость полученного коэффициента регрессии. Сформулируем статистические гипотезы. Н0 – для рассматриваемой генеральной совокупности нет статистически значимого коэффициента регрессии. Н1 – полученный коэффициента регрессии является статистически значимым. Нулевая гипотеза проверяется с помощью t-критерия Стьюдента, эмпирическое значение которого вычисляется с помощью соотношения
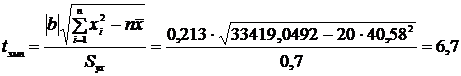
Зададимся уровнем статистической значимости α=0,05. Соответствующее ему критическое значение для объема выборки n=20 и числа степеней ν=n-2=20-2=18 равно tкр=2,101 (см. таблицу 1 Приложения). Сравним эмпирическое значение t-критерия с критическим для выбранного уровня значимости. tэмп > tкр (tэмп > 2,101), поэтому коэффициент регрессии b=0,213 является статистически значимым на уровне статистической значимости α=0,05.
Рассмотрим исследование взаимосвязи признаков с помощью коэффициента ранговой корреляции Спирмена.
Пример. В ходе тренировок группа спортсменов из 20 человек выполняют упражнения «подъем-разгибом» и «отмах в стойку». Результаты, зафиксированные при выполнении этих упражнений, приведены в таблице 8. Число выполнений упражнения «подъем-разгибом» каждым спортсменом приведено во второй колонке таблицы 8 обозначено x. Число выполнений упражнения «отмах в стойку» приведено в третьей колонке таблицы 8 и обозначено y. Исследовать зависимость между результатами выполнения упражнения «отмах в стойку» и результатами выполнения упражнения «подъем-разгибом».
Таблица 8
Вычисление коэффициента ранговой корреляции Спирмена.
1 | 2 | 3 | 4 | 5 | 6 | 7 |
i | xi | yi | RXi | RYi | di | di2 |
1 | 20 | 10 | 19,5 | 19 | 0,5 | 0,25 |
2 | 15 | 7 | 10 | 12,5 | -2,5 | 6,25 |
3 | 18 | 9 | 16 | 17,5 | -1,5 | 2,25 |
4 | 19 | 8 | 18 | 15,5 | 2,5 | 6,25 |
5 | 17 | 5 | 14 | 7,5 | 6,5 | 42,25 |
6 | 10 | 3 | 1,5 | 3,5 | -2 | 4 |
7 | 15 | 7 | 10 | 12,5 | -2,5 | 6,25 |
8 | 13 | 5 | 7 | 7,5 | -0,5 | 0,25 |
9 | 11 | 3 | 3,5 | 3,5 | 0 | 0 |
10 | 10 | 3 | 1,5 | 3,5 | -2 | 4 |
11 | 13 | 6 | 7 | 9,5 | -2,5 | 6,25 |
12 | 18 | 8 | 16 | 15,5 | 0,5 | 0,25 |
13 | 11 | 3 | 3,5 | 3,5 | 0 | 0 |
14 | 12 | 4 | 5 | 6 | -1 | 1 |
15 | 16 | 6 | 12,5 | 9,5 | 3 | 9 |
16 | 16 | 7 | 12,5 | 12,5 | 0 | 0 |
17 | 20 | 11 | 19,5 | 20 | -0,5 | 0,25 |
18 | 13 | 2 | 7 | 1 | 6 | 36 |
19 | 15 | 7 | 10 | 12,5 | -2,5 | 6,25 |
20 | 18 | 9 | 16 | 17,5 | -1,5 | 2,25 |
Сумма | 210 | 210 | 0 | 133 |
Построим корреляционное поле, откладывая по оси X декартовой системы координат результаты выполнения упражнения «подъем-разгибом», а по оси Y – соответствующие им результаты выполнения упражнения «отмах в стойку» (см. рис. 17).
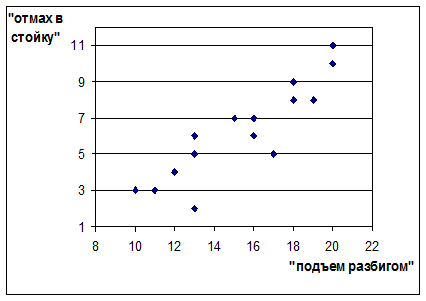
Рис. 17. Корреляционное поле
Как видно из рассмотрения рисунка, увеличение значения одного признака, приводит к увеличению значения второго. Это позволяет предположить, что два набора данных связаны положительной связью. Поскольку предполагаемая связь является монотонной, то для оценки ее силы можно воспользоваться коэффициентом ранговой корреляции Спирмена.
Вычислим ранги RXi и RYi значений исследуемых данных и занесем полученные результаты в 4 и 5 колонки таблицы 5.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
